Cross-validation 1 Cross-validation
introduce
Cross Validation in Sklearn is very helpful in choosing the right Model and Model parameters. With its help, we can visually see the impact of different models or parameters on structural accuracy.
Usage method:
from sklearn.cross_validation import cross_val_score # K-fold cross-validation moduleExample 1 - How to select the correct Model base validation method
from sklearn.datasets import load_iris # iris dataset
from sklearn.model_selection import train_test_split # Split Data Module
from sklearn.neighbors import KNeighborsClassifier # K-Nearest Neighbor classification algorithm
#Loading iris datasets
iris = load_iris()
X = iris.data
y = iris.target
#Split data and
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
#Modeling
knn = KNeighborsClassifier()
#Training model
knn.fit(X_train, y_train)
#Print out accuracy
print(knn.score(X_test, y_test))
# 0.973684210526You can see that the accuracy of the basic validation is 0.973684210526
Example 2 - How to choose the correct Cross Validation for Model s
from sklearn.cross_validation import cross_val_score # K-fold cross-validation module
#Use K-fold cross validation module
#Here: KNN parameters can be transformed to compare different models; cv=5 can be transformed to divide the data into more parts
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
#Print out 5 times prediction accuracy
print(scores)
# [ 0.96666667 1. 0.93333333 0.96666667 1. ]
#Print out the average prediction accuracy for five times, which is more convincing than score once
print(scores.mean())
# 0.973333333333Example 3 - How to select model parameters? Judging by accuracy
Generally speaking, accuracy is used to judge whether a classification model is good or bad.
import matplotlib.pyplot as plt #Visualization module
#Set up test parameters
k_range = range(1, 31)
k_scores = []
#Calculates the impact of different parameters on the model iteratively and returns the average accuracy after cross-validation
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy')
k_scores.append(scores.mean())
#Visualizing data
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()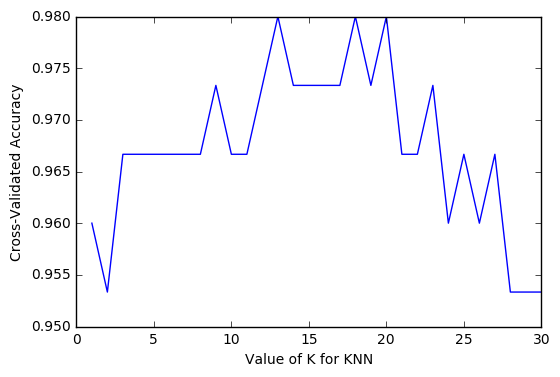
As you can see from the graph, the k value of 12-18 is the best choice.After 18, the accuracy begins to decline because of the problem of over fitting.
Example 4 - How do you choose model parameters? Judged by Mean squared error
Generally speaking, mean squared error is used to judge whether a regression model is good or bad.
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error')
k_scores.append(loss.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated MSE')
plt.show()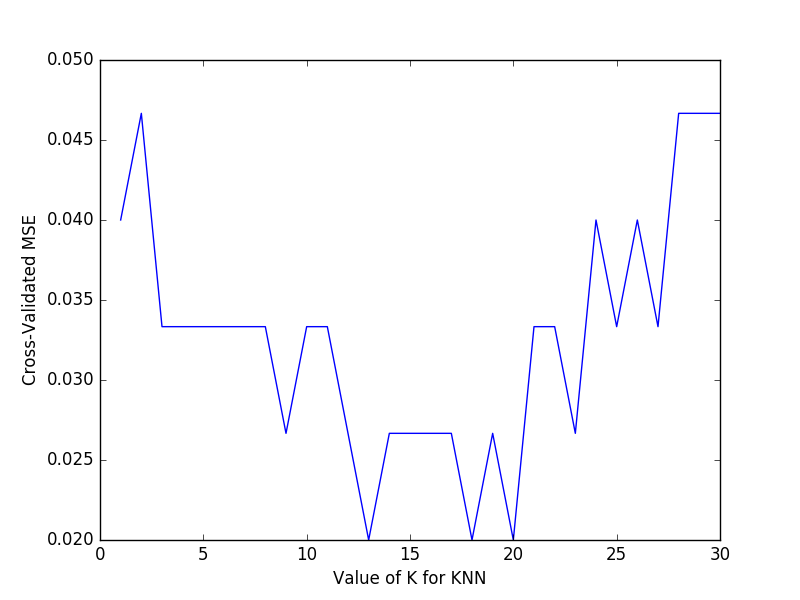
As you can see from the graph, the lower the mean variance, the better, so choosing a K value of around 13-18 is the best.