C++ STL container classification
Use the following table to list the commonly used C++STL containers (including the newly introduced containers of C++11):
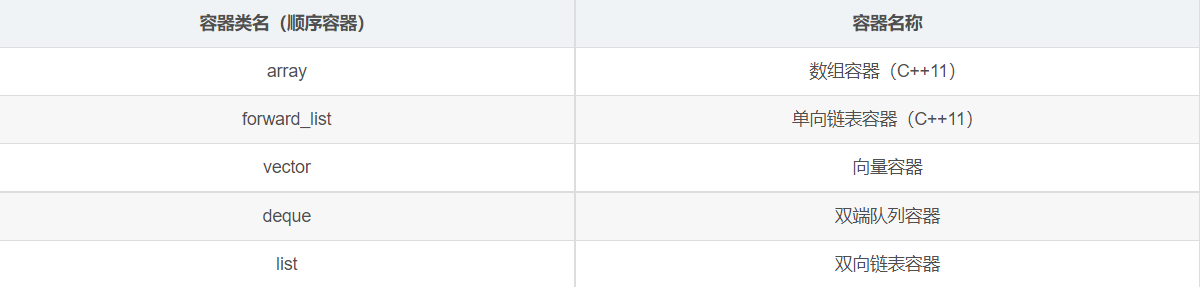

Sequential container
This section summarizes the contents of sequential containers.
vector container content sorting
Underlying data structure: an array whose memory can be expanded twice. By default, there is no allocated space at the bottom of the vec object. The capacity is expanded from 0-1-2-4-8-16-32 with the addition of elements. Therefore, the initial memory use efficiency of the vec container is relatively low, and the reserve method can be used for optimization.
Data addition, deletion and query interface:
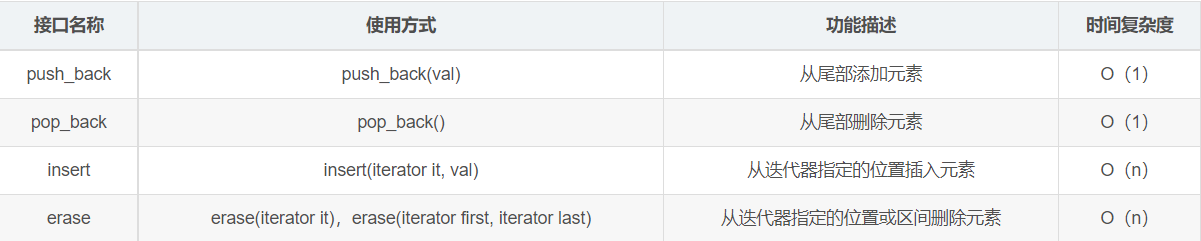
reserve/resize member method: reserve is to reserve space for the vector container without increasing the number of elements. It is mainly used to solve the problem of low initial memory utilization efficiency of the vector container; Resize not only opens up space for the underlying layer of the vector, but also adds a corresponding number of elements.
Traverse the search container:
1. You can traverse or search containers through iterators. Code example:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
//Example of using vector container
vector<int> vec;
for (int i = 0; i < 20; ++i)
{
vec.push_back(rand() % 100);
}
//find demonstrates whether the search 20 exists in the vector. If so, delete the first 20
auto it1 = find(vec.begin(), vec.end(), 20);
if (it1 != vec.end())
{
vec.erase(it1);
}
//Print vector container
for_each(vec.begin(),
vec.end(),
[](int val)->void
{
cout << val << " ";
});
//Find the first number greater than 50 and print it out
auto it2 = find_if(vec.begin(), vec.end(),
[](int val)->bool {return val > 50; });
if (it2 != vec.end())
{
cout << "The first number greater than 50 is:" << *it2 << endl;
}
return 0;
}
2. You can search the vector container through a generic algorithm. Code example:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
//Example of using vector container
vector<int> vec;
for (int i = 0; i < 20; ++i)
{
vec.push_back(rand() % 100);
}
//find demonstrates whether the search 20 exists in the vector. If so, delete the first 20
auto it1 = find(vec.begin(), vec.end(), 20);
if (it1 != vec.end())
{
vec.erase(it1);
}
//Print vector container
for_each(vec.begin(),
vec.end(),
[](int val)->void
{
cout << val << " ";
});
//Find the first number greater than 50 and print it out
auto it2 = find_if(vec.begin(), vec.end(),
[](int val)->bool {return val > 50; });
if (it2 != vec.end())
{
cout << "The first number greater than 50 is:" << *it2 << endl;
}
return 0;
}
deque container content sorting
Underlying data structure: the dynamic development of the two-dimensional array is different from the underlying data structure of the vector. The second dimension of deque is developed according to a fixed size. During memory expansion, the array space of the first dimension is expanded by twice the original space each time, and then all the arrays of the second dimension are adjusted to the middle of the first dimension array for arrangement, and the position space is reserved up and down, Because deque supports the addition and deletion of head and tail, this adjustment is more convenient for the addition and deletion of head and tail data.
Data addition, deletion and query interface:
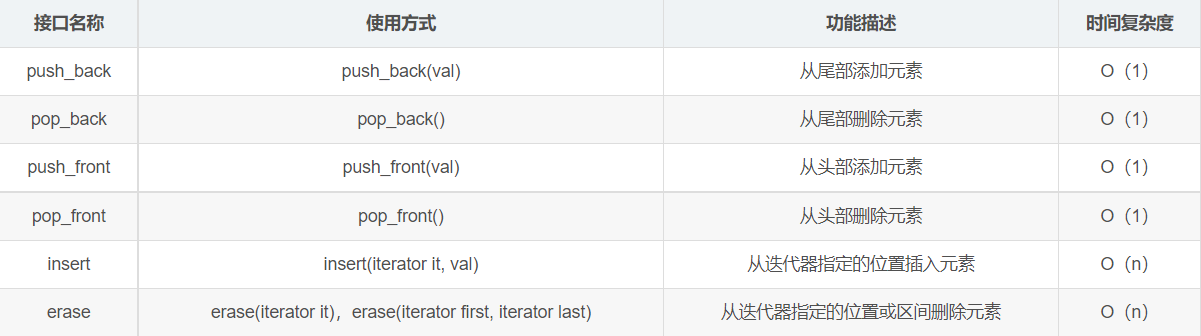
list container content sorting
Underlying data structure: the underlying layer is a two-way linked list of leading nodes. The node memory is discontinuous. Capacity expansion is to generate new linked list nodes.
Data addition, deletion and query interface:
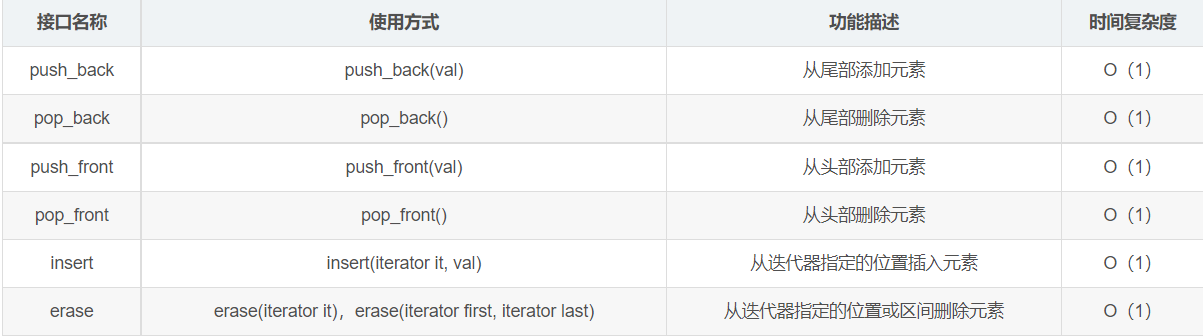
It can be seen from the method interface supported by the list above that the cost of list is constant time for adding and deleting operations, but its search is relatively slow. It always starts from the node, and the time complexity is O(n).
splice member method: each node of the linked list is opened up separately, so when the linked list moves data or between two linked lists, it is OK to directly remove the node and access it to a new location, which is more efficient. The example code is as follows:
#include <iostream>
#include <list>
#include <algorithm>
using namespace std;
int main()
{
//Define two list containers
list<int> l1;
list<int> l2;
for (int i = 0; i < 10; ++i)
{
l1.push_back(i);
}
for (int i = 10; i < 20; ++i)
{
l2.push_back(i);
}
//Print the element values of the two list containers
for_each(l1.begin(), l1.end(), [](int val) {cout << val << " "; });
cout << endl;
for_each(l2.begin(), l2.end(), [](int val) {cout << val << " "; });
cout << endl;
//Moving the first element 0 of the list1 container to the end only involves the change of the pointer field without any memory and data copy operations
l1.splice(l1.end(), l1, l1.begin());
for_each(l1.begin(), l1.end(), [](int val) {cout << val << " "; });
cout << endl;
//Move the first element of the l1 container to the end of the l2 container
l2.splice(l2.end(), l1, l1.begin());
for_each(l2.begin(), l2.end(), [](int val) {cout << val << " "; });
cout << endl;
//Move all elements of the l1 container to the end of the l2 container
l2.splice(l2.end(), l1, l1.begin(), l1.end());
for_each(l2.begin(), l2.end(), [](int val) {cout << val << " "; });
cout << endl;
return 0;
}
The traversal of deque and list containers is similar to that of vector container. Refer to the traversal code of vector container for self-test. The container method basically provides corresponding overloaded functions with right value reference parameters in C++11 to automatically match the right value parameters, reduce the overhead of temporary quantity in the code and improve the resource utilization.
There are other related general methods for each container, such as front, back, at, size, empty, etc. Let's summarize them by ourselves. Starting with C++11, each container is provided with empty, empty_ front,emplace_back and other related functions. The functions of empty and insert methods are the same. They are used to add elements. The difference is that empty is implemented as a template member method with right-value reference parameters. One method is used to uniformly process left-value parameters and right-value parameters (by referring to the folding principle). However, after C++11, in addition to the original version of left-value reference parameters, each container insert method, The version of the right value reference parameter is also provided, so the insert method is preferred in practical use.
In addition, in C++11, the sequential container also provides array (array container with non expandable memory) and forward_list one-way linked list container. The operation is relatively simple. It can contain the header file of the corresponding class name. Be proficient in their use.
Take a look at common problems with sequential containers
1. Is the bottom space of deque continuous?
The bottom layer of deque container is a dynamic two-dimensional array, so the space is not completely continuous, and the second two-dimensional array of each small segment is continuous.
2. Who is more efficient in inserting and deleting vectors and deque?
The bottom layer of vector is an array with continuous memory. The insertion and deletion time complexity of the tail is O(1), but the insertion and deletion time complexity of other positions is O(n). Another advantage of vector is that the random access is O(1). Given a subscript index, the value of the element can be accessed within O(1) time through vector[index] (because it is an array); The insertion and deletion of the head and tail of deque are O(1), but the insertion and deletion of other positions are O(n). Because the underlying memory of deque is not completely continuous, the efficiency of insertion and deletion in the middle is not as high as that of vector (the underlying space of vector is completely continuous, and the efficiency of data movement is higher).
3. How to select vector and list?
How to select vector and list is also the specific application of array and linked list. Array random access is fast and insertion and deletion is slow; The linked list is fast to insert and delete, and random access is not supported. Because the memory of the node is discontinuous, each search starts from the node.
4. The problem of iterator failure?
The iterator is not allowed to modify the elements of the container in the process of traversing the container. If the elements are added or deleted, the original iterator can no longer be used. The iterator must be updated, otherwise there will be problems in operation. We have also given a detailed case in class. Pay more attention to it when you use it. (it can also be understood that a container cannot be traversed by an iterator in one thread, and another thread can add or delete container elements. In addition, iterators of different containers cannot be compared. The implementation of the source code believes that iterators do not iterate over the same container, and the comparison between them is meaningless).
Container Adapters
stack,queue,priority_ The reason why queues are called adapters is that they do not have their own underlying data structure and rely on other containers to realize their functions. Their methods are also implemented through the corresponding methods of the containers they depend on.
Stack: by default, it relies on deque implementation and provides several common stack methods such as push, pop, top, size and empty. Reasons for relying on deque containers:
1. The second dimension of deque is developed according to a fixed size. Compared with vector, the initial memory utilization efficiency is high
2.deque's memory is segmented, while vector needs a large continuous space, with high memory utilization
queue: by default, it depends on the deque implementation and provides push, pop, front, back, size and empty, which are common methods for one-way queues. The reasons for relying on the deque container are as follows:
1. The second dimension of deque is developed according to a fixed size. Compared with vector, the initial memory utilization efficiency is high
2.deque's memory is segmented, while vector needs a large continuous space, with high memory utilization
3.deque itself supports adding and deleting elements at the beginning and end of O(1) time complexity, which is suitable for realizing queue structure
priority_queue: by default, it depends on the vector implementation and provides several common methods for priority queues, such as push, pop, top, size and empty. The reason for relying on the vector container is priority_queue needs to build a large root heap in an array with continuous memory by default, so it is most appropriate to use vector (the bottom layer is an array, and the heap structure needs to calculate the positions of root nodes and left and right child nodes in the array according to subscripts). Priority can be changed_ The function object type defined in queue gets a small root heap, such as:
//The default is large root heap priority_queue<int> maxHeap; //Small root pile priority_queue<int, vector<int>, greater<int>> minHeap;
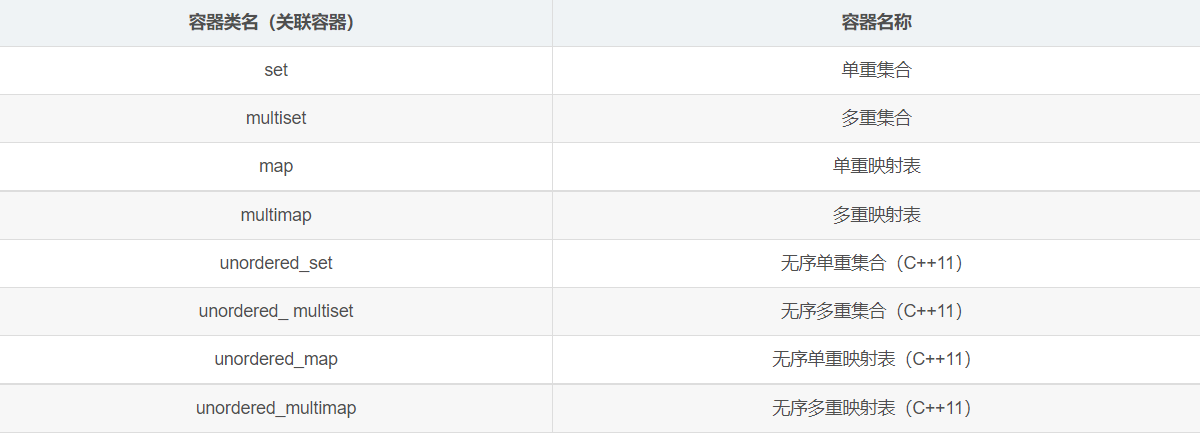
Associated container
In the actual problem scenario, in addition to our common linear table structure, string and sorting operations, hash tables and red black trees are also very common, and they are used in many application scenarios.
Although the hash table occupies more space, its addition, deletion and query are fast, approaching O(1); The red black tree is also a binary sort tree, so the data entered into the red black tree is sorted. Its addition, deletion and query time complexity is O(log 2 n), and its logarithmic time is slower than that of the hash table,
However, if the problem scenario requires the order of data, and there are many operations of adding, deleting and querying, then the red black tree structure is suitable, and the data in the hash table is disordered.
Unordered Association containers with linked hash table as the underlying data structure include:
unordered_set,unordered_multiset,unordered_map,unordered_multimap, the comparison is as follows:
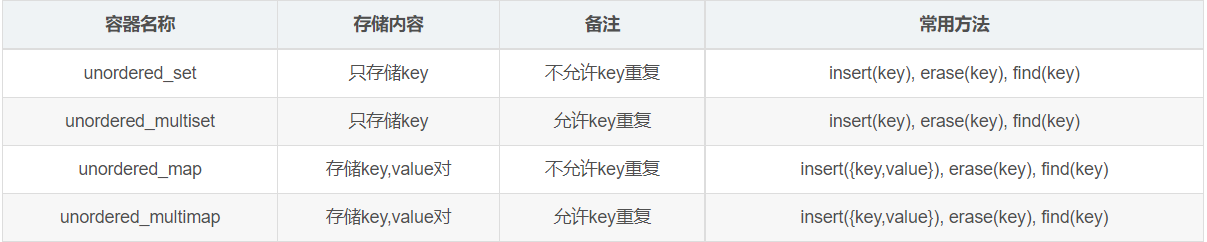
set only stores keys, and the bottom layer is a hash table, which is often used to check duplicate values or de duplicate values for big data; map stores key and value pairs, which are often used for hash statistics to count the number of data repetitions in big data. Of course, they are widely used, not only in massive data processing problem scenarios.
Code example for adding, deleting and querying unordered containers:
#include <iostream>
#include <unordered_set>
#include <string>
using namespace std;
int main()
{
//key cannot be changed to unordered repeatedly_ Multiset self test
unordered_set<int> set1;
for (int i = 0; i < 100; ++i)
{
set1.insert(rand() % 100 + 1);
}
cout << set1.size() << endl;
//Find out if 20 exists and delete it
auto it1 = set1.find(20);
if (it1 != set1.end())
{
set1.erase(it1);
}
//count returns the number of 50 = "in the set, up to 1
cout << set1.count(50) << endl;
return 0;
}
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
int main()
{
//Define an unordered mapping table
unordered_map<int, string> map;
//There are three ways to add [key,value] to the unordered mapping table
map.insert({ 1000, "aaa" });
map.insert(make_pair(1001, "bbb"));
map[1002] = "ccc";
//Traverse map table 1
auto it = map.begin();
for (; it != map.end(); ++it)
{
cout << "key:" << it->first << " value:" << it->second << endl;
}
//Traverse map table 2
for (pair<int, string>& pair : map)
{
cout << "key:" << pair.first << " value:" << pair.second << endl;
}
//Find the key value pair with key 1000 and delete it
auto it1 = map.find(1000);
if (it1 != map.end())
{
map.erase(it1);
}
return 0;
}
The unordered mapping table can also be traversed one by one by hash bucket. The code example is as follows:
#include <iostream>
#include <string>
#include <unordered_map>
int main()
{
std::unordered_map<std::string, std::string> mymap =
{
{ "house", "maison" },
{ "apple", "pomme" },
{ "tree", "arbre" },
{ "book", "livre" },
{ "door", "porte" },
{ "grapefruit", "pamplemousse" }
};
unsigned n = mymap.bucket_count();//Gets the number of hash buckets
std::cout << "mymap has " << n << " buckets.\n";
for (unsigned i = 0; i < n; ++i) //Traverse the linked list in the hash bucket one by one
{
std::cout << "bucket #" << i << " contains: ";
for (auto it = mymap.begin(i); it != mymap.end(i); ++it)
std::cout << "[" << it->first << ":" << it->second << "] ";
std::cout << "\n";
}
return 0;
}
The ordered Association containers with red black tree as the underlying data structure include:
Compared with the above unordered containers, set, multiset, map and multimap, except for the different underlying data structure, other operations are almost the same. The demonstration code of the above unordered container can also be executed normally by replacing it with an ordered container. Generally, if there is no requirement for data ordering, unordered containers are basically selected for use; If the application scenario requires the order of data, you have to select the ordered Association container.
Near container
The sequential container described above is a standard container for configuration and association containers belonging to C++STL. The near container refers to array type, string string type and bitset bitmap container (it is an object-oriented bit group, which can be used in big data duplication checking, Bloom Filter implementation, Huffman coding for file compression, etc, There are also some containers cited in mathematical operations, which are summarized into the category of near containers.
Thread safety features of C++STL container
The containers in C++STL mentioned above do not consider multi-threaded access, that is, the above containers can not be used directly in multi-threaded environment. If you want to use it, remember to do mutual exclusion between threads for container operations to ensure the atomic characteristics of container operations.
Answers to questions related to C++ STL container
Question 1: what is the use of the container space configurator?
The function of the container's space configurator is to separate the memory development and construction process of the object, and the object deconstruction and memory release. Then why separate the memory development and construction of objects (the two functions of new) and the deconstruction and memory release of objects (the two functions of delete)?
1) Because in the process of using a container, when constructing a container, we only want the memory space of the container and do not need to construct a pile of useless objects in memory (there is no way to avoid this problem by directly using new); When deleting an element from a container, we need to destruct the deleted object, but the container memory space occupied by it cannot be released because the container still needs to be used; For another example, when we need to release a container, we need to destruct the effective object elements in the container first, rather than all the elements of the container (this problem can not be avoided by delete). Therefore, in the process of operating the container, we need to selectively open up memory, construct objects and destruct objects respectively, So this is the meaning of the existence of spatial configurator.
2) The allocator space configurator provided in the C + + standard STL relies on malloc and free to allocate and release memory by default. SGI STL provides two versions of space configurator, primary space configurator and secondary space configurator. The memory management of the primary space configurator is also realized through malloc and free, but the secondary space configurator of SGI STL provides the implementation of a memory pool. The design idea of the second level configurator is:
1. If the configuration block exceeds 128 bytes, it shall be handed over to the first level configurator for processing;
2. If the configuration block is less than 128 bytes, memory pool management is adopted. Each time a large block of memory is configured, the corresponding free list is maintained. Next time, if there is a memory demand of the same size, it is directly allocated from the free list (if there is no memory, continue to configure the memory, which will be described later). If the client interprets a small block, the configurator will recycle it into the free list.
Question 2: how do map and set containers work?
The bottom layers of the set and map containers of C++ STL are implemented by the red black tree. Therefore, the implementation principle of map and set is the implementation principle of the red black tree. Map is used to store key value mapping pairs. It packages [key, value] into pair objects and stores them in the red black tree structure. The elements are sorted, so they can be stored in O(log 2 n) It is very efficient to add, delete and query set and map within the time complexity of. For the description of red black tree, some basic information is listed below. For more detailed understanding of red black tree, please refer to the link address given in the extension.
The red black tree is a non strict balanced binary tree. The height difference between the left and right subtrees cannot exceed twice the height of the shorter subtree. The data addition, deletion and query efficiency is relatively high, and the average time complexity is O(log 2 n). The definition of red black tree is given here:
1) Each node is either red or black.
2) The root node is black.
3) Each leaf node, the empty node (NIL), is black.
4) If a node is red, its two sons are black.
5) For each node, all paths from the node to its descendants contain the same number of black nodes.
The red black tree does not maintain the height balance of the binary tree like the AVL (balanced binary tree) tree (the height difference between the left and right subtrees cannot exceed 1). Therefore, when inserting and deleting data, the rotation operation is much less than that of the red black tree, so its efficiency is also higher than that of the AVL tree; The red black tree inserts a new node and rotates it up to 2 times, and deletes a node and rotates it up to 3 times.
In C++STL, the bottom layers of map and multimap, set and multiset are implemented by red black tree. Therefore, if you want to take the user-defined class type as the element type of set and map, you must provide the overloaded function of operator > or operator < comparison operator for the user-defined type, because the red black tree is a binary sort tree, The elements entered into set and map should be sorted. Please note!