1, Why use distributed ID S?
Before talking about the specific implementation of distributed ID, let's briefly analyze why we use distributed ID? What characteristics should distributed IDS meet?
1. What is distributed ID?
Take MySQL database as an example:
When our business data volume is small, single database and single table can fully support the existing business. No matter how large the data is, MySQL master-slave synchronous read-write separation can also deal with it.
However, with the increasing data, the master-slave synchronization can not be carried out, so it is necessary to divide the database into databases and tables. However, a unique ID is required to identify a piece of data after the database is divided into databases and tables. Obviously, the self increasing ID of the database can not meet the demand; In particular, orders and coupons also need to be identified with a unique ID. At this time, a system that can generate globally unique IDs is very necessary. The globally unique ID is called the distributed ID.
2. So what conditions do distributed ID S need to meet?
-
Globally unique: ID must be globally unique. Basic requirements
-
High performance: high availability, low latency, ID generation response block, otherwise it will become a business bottleneck
-
High availability: 100% availability is deceptive, but it should be infinitely close to 100% availability
-
Good access: we should adhere to the design principle of use and use, and make the system design and implementation as simple as possible
-
Increasing trend: it is better to increase the trend. This requirement depends on the specific business scenario. Generally, it is not strict
2, What are the generation methods of Distributed ID S?
Today, we will mainly analyze the following 9 methods of distributed ID generator and their advantages and disadvantages:
-
UUID
-
Database self increment ID
-
Database multi master mode
-
Segment mode
-
Redis
-
Snow flake algorithm (SnowFlake)
-
Didi products (TinyID)
-
Baidu (Uidgenerator)
-
Leaf
So how are they implemented? And what are their advantages and disadvantages? Let's look down

Pictures from the Internet
The above pictures are from the Internet. If there is any infringement, please contact us and delete them
1. Based on UUID
In the world of Java, if you want to get a unique ID, the first thought may be UUID. After all, it has the unique characteristics in the world. Can UUIDs be distributed IDS? The answer is yes, but not recommended!
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid);
}The generation of UUID is as simple as only one line of code, and the output result is c2b8c2b9e46c47e3b30dca3b0d447718, but UUID is not suitable for actual business requirements. Strings such as UUID used as the order number have no meaning at all, and there is no useful information related to the order; For the database, it is not only too long, but also a string. The storage performance is poor and the query is time-consuming. Therefore, it is not recommended to be used as a distributed ID.
advantage:
-
The generation is simple enough, local generation has no network consumption and is unique
Disadvantages:
-
Unordered strings do not have trend self increasing characteristics
-
There is no specific business meaning
-
A string with a length of 16 bytes, 128 bits and 36 bits is too long. Storage and query consume a lot of MySQL performance. MySQL officials clearly suggest that the shorter the primary key is, the better. As a database primary key, the disorder of "UUID" will lead to frequent changes in data location and seriously affect performance.
2. Self increment ID based on Database
Database based auto_increment self incrementing ID can be used as a distributed ID. specific implementation: a separate MySQL instance is required to generate ID. the table creation structure is as follows:
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
) ENGINE=MyISAM;
insert into SEQUENCE_ID(value) VALUES ('values');When we need an ID, we insert a record into the table to return the primary key ID, but this method has a fatal disadvantage. MySQL itself is the bottleneck of the system when the traffic surges. It is risky to use it to realize distributed services. It is not recommended!
advantage:
-
The implementation is simple, the ID is monotonous and self increasing, and the query speed of numerical type is fast
Disadvantages:
-
There is a risk of downtime in a single point of DB, which cannot withstand high concurrency scenarios
3. Based on database cluster mode
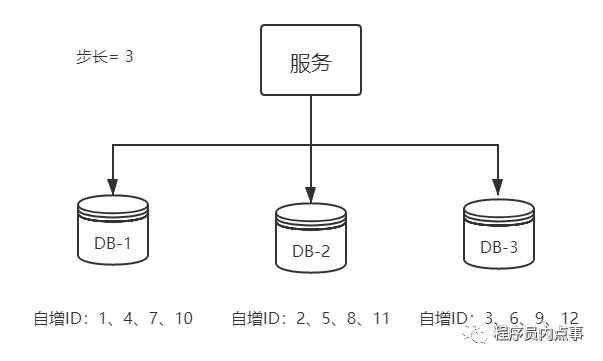
As mentioned earlier, the single point database method is not desirable. Then, do some high availability optimization for the above method and replace it with the master-slave mode cluster. If you are afraid that one primary node will fail to work, then make a dual primary mode cluster, that is, two Mysql instances can produce self incrementing ID S separately.
There will also be a problem. The self increasing IDs of two MySQL instances start from 1. What should I do if duplicate IDs are generated?
Solution: set the starting value and self increasing step size
MySQL_1 configuration:
set @@auto_increment_offset = 1; -- Starting value set @@auto_increment_increment = 2; -- step
MySQL_2 configuration:
set @@auto_increment_offset = 2; -- Starting value set @@auto_increment_increment = 2; -- step
The self incrementing ID s of the two MySQL instances are:
1,3,5,7,9
2,4,6,8,10
What if the performance after the cluster still can't bear the high concurrency? It is necessary to expand the capacity of MySQL and add nodes, which is a troublesome thing.
Insert picture description here
It can be seen from the above figure that the horizontally expanded database cluster is conducive to solving the problem of single point pressure of the database. At the same time, in order to generate ID, the self increasing step size is set according to the number of machines.
To add the third MySQL instance, you need to manually modify the starting value and step size of the first and second MySQL instances, and set the starting generation position of the ID of the third machine to be a little farther than the existing maximum self incrementing ID, but it must be when the ID of the first and second MySQL instances has not increased to the starting ID value of the third MySQL instance, otherwise the self incrementing ID will be repeated, If necessary, shutdown modification may be required.
advantage:
-
Solve DB single point problem
Disadvantages:
-
It is not conducive to subsequent capacity expansion, and in fact, the pressure of a single database is still high, and it still can not meet the high concurrency scenario.
4. Segment pattern based on Database
The number segment mode is one of the mainstream implementations of the current distributed ID generator. The number segment mode can be understood as obtaining self incrementing IDs from the database in batches and taking out a number segment range from the database each time. For example, (11000] represents 1000 IDs. The specific business service generates 1 ~ 1000 self incrementing IDs from this number segment and loads them into memory. The table structure is as follows:
CREATE TABLE id_generator ( id int(10) NOT NULL, max_id bigint(20) NOT NULL COMMENT 'Current maximum id', step int(20) NOT NULL COMMENT 'Cloth length of section', biz_type int(20) NOT NULL COMMENT 'Business type', version int(20) NOT NULL COMMENT 'Version number', PRIMARY KEY (`id`) )
biz_type: represents different business types
max_id: the current maximum available id
step: represents the length of the number segment
Version: it is an optimistic lock. The version is updated every time to ensure the correctness of data during concurrency
id
biz_type
max_id
step
version
| 1 | 101 | 1000 | 2000 | 0 |
When the ID of this batch number segment is used up, apply for a new batch number segment from the database again, right_ Update the ID field once, update max_id= max_id + step, if the update is successful, the new number segment is successful. The range of the new number segment is (max_id, max_id + step].
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXXSince multiple business terminals may operate at the same time, the version number version optimistic locking method is adopted for updating. This distributed ID generation method does not rely strongly on the database, does not frequently access the database, and has much less pressure on the database.
5. Redis based mode
Redis can also be implemented. The principle is to use the # incr command of redis to realize the atomic self increment of ID.
127.0.0.1:6379> set seq_id 1 //Initialization auto increment ID is 1 OK 127.0.0.1:6379> incr seq_id //Increases by 1 and returns the incremented value (integer) 2
One thing to pay attention to when implementing with redis is the persistence of redis. Redis has two persistence modes: RDB and AOF
-
RDB will periodically take a snapshot for persistence. If redis fails to persist in time after continuous self growth, redis will hang up and duplicate ID S will occur after redis is restarted.
-
AOF will persist each write command. Even if Redis hangs up, there will be no ID duplication. However, due to the particularity of incr command, it will take too long for Redis to restart and recover data.
6. Based on Snowflake pattern
Snowflake algorithm is an ID generation algorithm used in twitter's internal distributed project. After being open-source, it has been widely praised by large domestic manufacturers. Under the influence of this algorithm, major companies have developed their own unique distributed generators.
Insert picture description here
The above pictures are from the Internet. If there is any infringement, please contact us and delete them
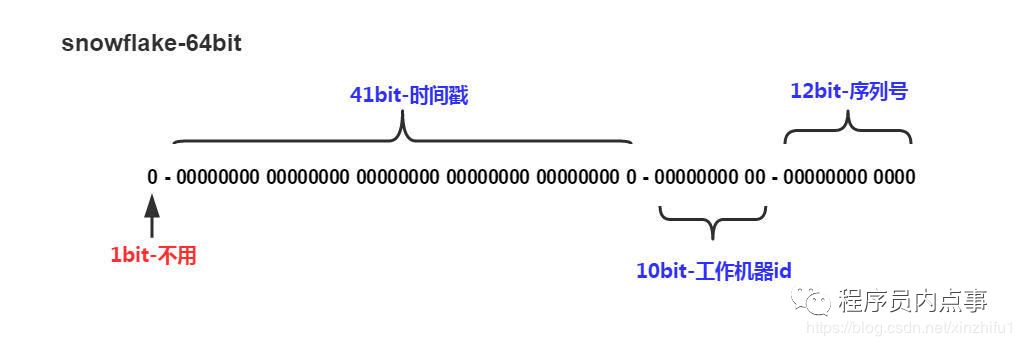
Snowflake generates the ID of Long type. A Long type takes up 8 bytes, and each byte takes up 8 bits, that is, a Long type takes up 64 bits.
Snowflake ID composition structure: a Long type composed of positive digits (1 bit) + timestamp (41 bits) + machine ID (5 bits) + Data Center (5 bits) + self increment (12 bits), a total of 64 bits.
-
The first bit (1bit): the highest bit of long in Java is the sign bit, representing positive and negative, positive number is 0 and negative number is 1. Generally, the generated ID is positive, so it is 0 by default.
-
Timestamp part (41bit): the time in milliseconds. It is not recommended to save the current timestamp, but use the difference (current timestamp - fixed start timestamp) to make the generated ID start from a smaller value; The 41 bit timestamp can be used for 69 years, (1L < < 41) / (1000L * 60 * 60 * 24 * 365) = 69 years
-
Working machine id (10bit): also known as workId, which can be configured flexibly, including machine room or machine number combination.
-
The serial number part (12bit) supports self increment, and 4096 ID S can be generated by the same node in the same millisecond
According to the logic of the algorithm, only the algorithm needs to be implemented in Java language and encapsulated into a tool method, then each business application can directly use the tool method to obtain the distributed ID, just ensure that each business application has its own working machine ID, and there is no need to build an application to obtain the distributed ID separately.
Implementation of Snowflake algorithm in Java version:
/**
* Twitter The SnowFlake algorithm uses the SnowFlake algorithm to generate an integer, which is then converted into 62 hexadecimal into a short address URL
*
* https://github.com/beyondfengyu/SnowFlake
*/
public class SnowFlakeShortUrl {
/**
* Starting timestamp
*/
private final static long START_TIMESTAMP = 1480166465631L;
/**
* Number of bits occupied by each part
*/
private final static long SEQUENCE_BIT = 12; //Number of digits occupied by serial number
private final static long MACHINE_BIT = 5; //Number of digits occupied by machine identification
private final static long DATA_CENTER_BIT = 5; //Number of bits occupied by data center
/**
* Maximum value of each part
*/
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);
/**
* Displacement of each part to the left
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
private long dataCenterId; //Data center
private long machineId; //Machine identification
private long sequence = 0L; //serial number
private long lastTimeStamp = -1L; //Last timestamp
private long getNextMill() {
long mill = getNewTimeStamp();
while (mill <= lastTimeStamp) {
mill = getNewTimeStamp();
}
return mill;
}
private long getNewTimeStamp() {
return System.currentTimeMillis();
}
/**
* Generates the specified serial number based on the specified data center ID and machine flag ID
*
* @param dataCenterId Data center ID
* @param machineId Machine flag ID
*/
public SnowFlakeShortUrl(long dataCenterId, long machineId) {
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("DtaCenterId can't be greater than MAX_DATA_CENTER_NUM or less than 0!");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("MachineId can't be greater than MAX_MACHINE_NUM or less than 0!");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* Generate next ID
*
* @return
*/
public synchronized long nextId() {
long currTimeStamp = getNewTimeStamp();
if (currTimeStamp < lastTimeStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currTimeStamp == lastTimeStamp) {
//Within the same milliseconds, the serial number increases automatically
sequence = (sequence + 1) & MAX_SEQUENCE;
//The number of sequences in the same millisecond has reached the maximum
if (sequence == 0L) {
currTimeStamp = getNextMill();
}
} else {
//Within different milliseconds, the serial number is set to 0
sequence = 0L;
}
lastTimeStamp = currTimeStamp;
return (currTimeStamp - START_TIMESTAMP) << TIMESTAMP_LEFT //Timestamp part
| dataCenterId << DATA_CENTER_LEFT //Data center part
| machineId << MACHINE_LEFT //Machine identification part
| sequence; //Serial number part
}
public static void main(String[] args) {
SnowFlakeShortUrl snowFlake = new SnowFlakeShortUrl(2, 3);
for (int i = 0; i < (1 << 4); i++) {
//Decimal
System.out.println(snowFlake.nextId());
}
}
}
7. Baidu (uid generator)
Uid generator is developed by Baidu technology department. The project GitHub address is https://github.com/baidu/uid-generator
Uid generator is implemented based on snowflake algorithm. Different from the original snowflake algorithm, uid generator supports the number of bits of user-defined timestamp, work machine ID and {serial number}, and the generation strategy of user-defined workId is adopted in uid generator.
Uid generator needs to be used with the database, and a worker needs to be added_ Node table. When the application starts, it will insert a piece of data into the database table. The self incrementing ID returned after successful insertion is the workId of the machine. The data is composed of host and port.
For uid generator ID composition structure:
workId takes up 22 bits, time 28 bits, and serialization 13 bits. It should be noted that, unlike the original snowflake, the unit of time is seconds, not milliseconds, and the workId is also different. In addition, the same application will consume a workId every time it is restarted.
reference
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
8. Leaf
Leaf is developed by meituan, GitHub address: https://github.com/Meituan-Dianping/Leaf
Leaf supports both segment mode and snowflake algorithm mode, which can be switched.
Segment mode
Import the source code first https://github.com/Meituan-Dianping/Leaf , creating a table leaf_alloc
DROP TABLE IF EXISTS `leaf_alloc`; CREATE TABLE `leaf_alloc` ( `biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT 'business key', `max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT 'Currently assigned maximum id', `step` int(11) NOT NULL COMMENT 'The initial step size is also the minimum step size for dynamic adjustment', `description` varchar(256) DEFAULT NULL COMMENT 'business key Description of', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Update time of database maintenance', PRIMARY KEY (`biz_tag`) ) ENGINE=InnoDB;
Then turn on the number segment mode in the project, configure the corresponding database information, and turn off the snowflake mode
leaf.name=com.sankuai.leaf.opensource.test leaf.segment.enable=true leaf.jdbc.url=jdbc:mysql://localhost:3306/leaf_test?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8 leaf.jdbc.username=root leaf.jdbc.password=root leaf.snowflake.enable=false #leaf.snowflake.zk.address= #leaf.snowflake.port=
Start the leaf server application project of the leaf server module and run
Test url for obtaining distributed self increment ID in segment mode: http: / / localhost: 8080 / API / segment / get / leaf segment test
Monitoring segment mode: http://localhost:8080/cache
snowflake mode
The snowflake mode of Leaf depends on zookeeper. Different from the original snowflake algorithm, it is mainly in the generation of workId. The workId in Leaf is generated based on the sequential Id of zookeeper. When each application uses Leaf snowflake, it will generate a sequential Id in zookeeper at startup, which is equivalent to a sequential node corresponding to a machine, that is, a workId.
leaf.snowflake.enable=true leaf.snowflake.zk.address=127.0.0.1 leaf.snowflake.port=2181
Obtain the test url of distributed self incrementing ID in snowflake mode: http://localhost:8080/api/snowflake/get/test
9. Tinyid
Tinyid was developed by Didi, Github address: https://github.com/didi/tinyid .
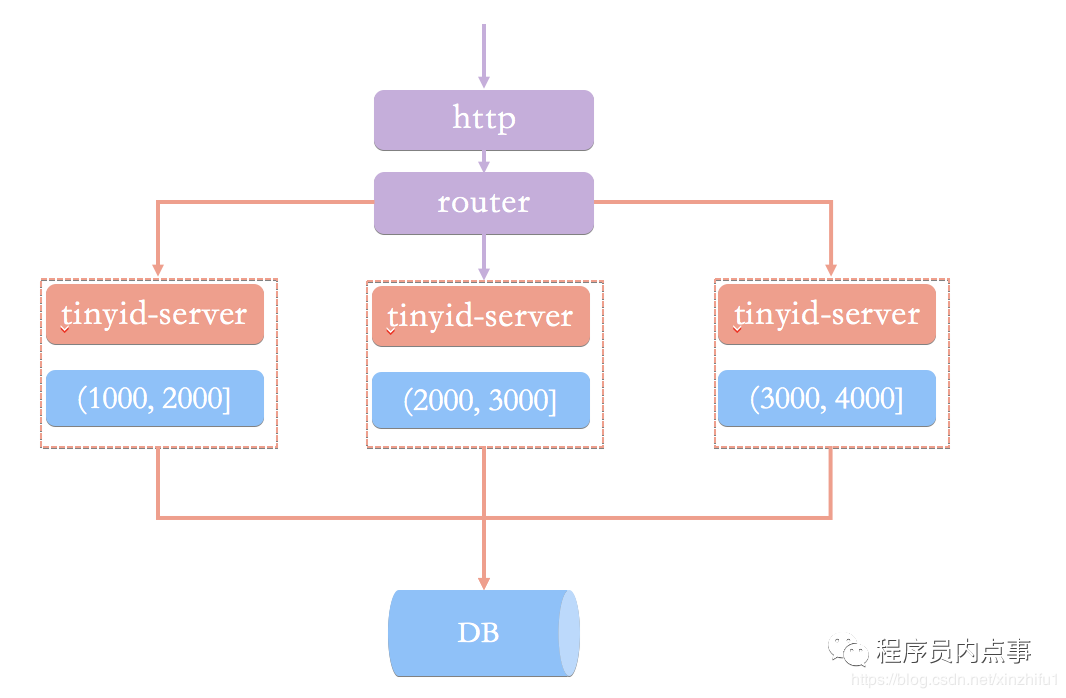
Tinyid is implemented based on the principle of number segment mode, which is the same as Leaf. Each service obtains a number segment (10002000], (20003000], (30004000)
Insert picture description here
Tinyid provides http and tinyid client access
Http access
(1) Import Tinyid source code:
git clone https://github.com/didi/tinyid.git
(2) Create data table:
CREATE TABLE `tiny_id_info` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Auto increment primary key', `biz_type` varchar(63) NOT NULL DEFAULT '' COMMENT 'Business type, unique', `begin_id` bigint(20) NOT NULL DEFAULT '0' COMMENT 'start id,Only the initial value is recorded and has no other meaning. During initialization begin_id and max_id Should be the same', `max_id` bigint(20) NOT NULL DEFAULT '0' COMMENT 'Current maximum id', `step` int(11) DEFAULT '0' COMMENT 'step', `delta` int(11) NOT NULL DEFAULT '1' COMMENT 'every time id increment', `remainder` int(11) NOT NULL DEFAULT '0' COMMENT 'remainder', `create_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT 'Creation time', `update_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT 'Update time', `version` bigint(20) NOT NULL DEFAULT '0' COMMENT 'Version number', PRIMARY KEY (`id`), UNIQUE KEY `uniq_biz_type` (`biz_type`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT 'id Information table'; CREATE TABLE `tiny_id_token` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Self increasing id', `token` varchar(255) NOT NULL DEFAULT '' COMMENT 'token', `biz_type` varchar(63) NOT NULL DEFAULT '' COMMENT 'this token Accessible business type identification', `remark` varchar(255) NOT NULL DEFAULT '' COMMENT 'remarks', `create_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT 'Creation time', `update_time` timestamp NOT NULL DEFAULT '2010-01-01 00:00:00' COMMENT 'Update time', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT 'token Information table'; INSERT INTO `tiny_id_info` (`id`, `biz_type`, `begin_id`, `max_id`, `step`, `delta`, `remainder`, `create_time`, `update_time`, `version`) VALUES (1, 'test', 1, 1, 100000, 1, 0, '2018-07-21 23:52:58', '2018-07-22 23:19:27', 1); INSERT INTO `tiny_id_info` (`id`, `biz_type`, `begin_id`, `max_id`, `step`, `delta`, `remainder`, `create_time`, `update_time`, `version`) VALUES (2, 'test_odd', 1, 1, 100000, 2, 1, '2018-07-21 23:52:58', '2018-07-23 00:39:24', 3); INSERT INTO `tiny_id_token` (`id`, `token`, `biz_type`, `remark`, `create_time`, `update_time`) VALUES (1, '0f673adf80504e2eaa552f5d791b644c', 'test', '1', '2017-12-14 16:36:46', '2017-12-14 16:36:48'); INSERT INTO `tiny_id_token` (`id`, `token`, `biz_type`, `remark`, `create_time`, `update_time`) VALUES (2, '0f673adf80504e2eaa552f5d791b644c', 'test_odd', '1', '2017-12-14 16:36:46', '2017-12-14 16:36:48');
(3) Configuration database:
datasource.tinyid.names=primary datasource.tinyid.primary.driver-class-name=com.mysql.jdbc.Driver datasource.tinyid.primary.url=jdbc:mysql://ip:port/databaseName?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8 datasource.tinyid.primary.username=root datasource.tinyid.primary.password=123456
(4) Test after starting tinyid server
Get distributed auto increment ID: http://localhost:9999/tinyid/id/nextIdSimple?bizType=test&token=0f673adf80504e2eaa552f5d791b644c' Return results: 3 Batch acquisition distributed auto increment ID: http://localhost:9999/tinyid/id/nextIdSimple?bizType=test&token=0f673adf80504e2eaa552f5d791b644c&batchSize=10' Return results: 4,5,6,7,8,9,10,11,12,13
Java client access
Repeat (2) and (3) of Http mode
Introduce dependency
<dependency>
<groupId>com.xiaoju.uemc.tinyid</groupId>
<artifactId>tinyid-client</artifactId>
<version>${tinyid.version}</version>
</dependency>configuration file
tinyid.server =localhost:9999 tinyid.token =0f673adf80504e2eaa552f5d791b644c
test ,tinyid.token is the data pre inserted in the database table. Test ¢ is the specific business type, tinyid Token indicates the accessible business type
//Get a single distributed self increment ID Long id = TinyId . nextId( " test " ); //On demand batch distributed self increment ID List< Long > ids = TinyId . nextId( " test " , 10 );
summary
This article just briefly introduces each distributed ID generator to give you a detailed learning direction. Each generation method has its own advantages and disadvantages. How to use it depends on the specific business requirements.