Looking at the various frameworks of downconversion PDF, we found that most of them are charged. Find a free iTextSharp and just want to play
Just do a simple HTML to PDF without too deep exploration.
First of all, I will introduce iTextSharp or the old method in the project, either download it from NuGet or command it directly
And then I built an HTML in the project, which contains some simple tags and some placeholders
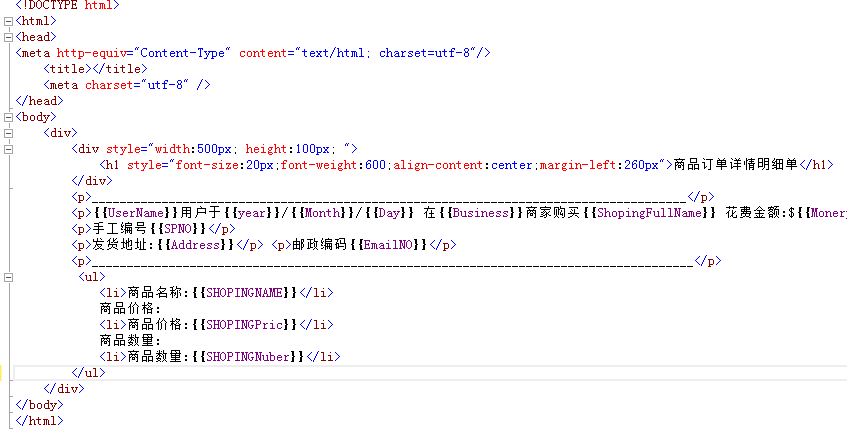
Then a PDF help class is built to implement the specific conversion method
public class PDFHelp { public byte[] ConvertHtmlTextToPDF(string htmltext) { if (string.IsNullOrEmpty(htmltext)) { return null; } //avoid htmlText Not any html tag When the label is plain text, turn to PDF It's going to hang up, so add<p>Label //htmlText = "<p>" + htmltext + "</p>"; MemoryStream stream = new MemoryStream(); byte[] data = Encoding.UTF8.GetBytes(htmltext); MemoryStream msInput = new MemoryStream(data); Document doc = new Document(); PdfWriter writer = PdfWriter.GetInstance(doc, stream); //Specify file default zoom Standard 100% PdfDestination pdfDest = new PdfDestination(PdfDestination.XYZ, 0, doc.PageSize.Height, 1f); doc.Open(); //Use XMLWorkerHelper hold Html parse reach PDF XMLWorkerHelper .GetInstance().ParseXHtml(writer, doc, msInput, null, Encoding.UTF8, new UnicodeFontFactory()); //Will pdfDest Write to PDF PdfAction action = PdfAction.GotoLocalPage(1, pdfDest, writer); writer.SetOpenAction(action); doc.Close(); msInput.Close(); stream.Close(); //Return PDF return stream.ToArray(); } }
Placeholders under the simple replacement test. Just three examples
public string Placeholderfill(string htmlContext) { var entity = _shopingRepository.FindAll().FirstOrDefault(); htmlContext = htmlContext.Replace("{{SHOPINGNAME}}", entity.ShopingName); htmlContext = htmlContext.Replace("{{SHOPINGPric}}", entity.ShopingPric.ToString()); htmlContext = htmlContext.Replace("{{SHOPINGNuber}}", entity.ShopingCount.ToString()); return htmlContext; }
Next is the call of the controller
public FileResult ExportPDF() { string htmlContext = System.IO.File.ReadAllText(Server.MapPath("~/HTMLTemplate/ShopingBuy.html")); var context= _iShopingServer.Placeholderfill(htmlContext); PDFHelp pf = new PDFHelp(); var ms= pf.ConvertHtmlTextToPDF(context); return File(ms,"application/pdf", "shoping"+ DateTime.Now+ ".pdf"); }
Write a PDF download button on the page, Ajax calls this method, and then the final effect is achieved. It's very rough. But the implementation process is relatively easy.
The general business is to transfer PDF and add email attachment to send email.
This is just a simple implementation. We have time for further study
