This article is shared from Huawei cloud community< [Kafka notes] Kafka API analyzes the Java version in detail (Producer API, Consumer API, interceptor, etc.) >, author: Copy engineer.
brief introduction
Kafka's APIs include Producer API, Consumer API, user-defined Interceptor (user-defined Interceptor), Streams API for processing streams and Kafka Connect API for building connectors.
Producer API
Kafka's Producer sends messages asynchronously. In the process of message sending, two threads are involved: the main thread and the Sender thread, and one thread shares the variable RecordAccumulator. The main thread sends messages to the RecordAccumulator, and the Sender thread constantly pulls messages from the RecordAccumulator and sends them to Kafka broker.
The ACK mechanism here is not that the producer starts sending after receiving the ACK return information. The ACK ensures that the producer does not lose data. For example:
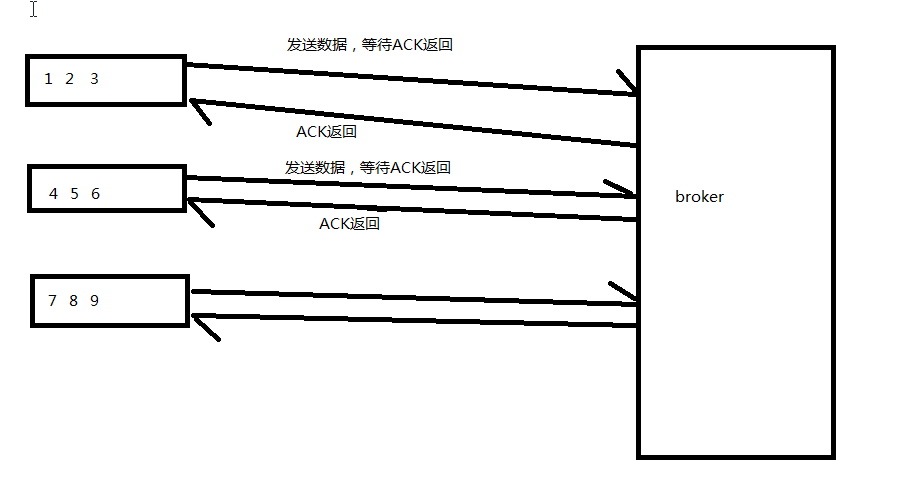
Instead, as long as there is message data, it will be sent to the broker.
Message sending process
The producer uses the send method, passes through the interceptor, then the serializer, and then the partition. Then send the data to the PecordAccumulator in batches. The main thread ends the process, and then executes send after returning.
The Sender thread continuously obtains the data of the RecordAccumulator and sends it to the topic.
The message sending process is sent asynchronously, and the order is a certain interceptor - "serializer" - partitioner
Asynchronous sending API
Required classes:
KafkaProducer: You need to create a producer object to send data ProducerConfig: Obtain a series of configuration parameters required ProducerRecord: Each data should be encapsulated into a ProducerRecord object
example:
public class KafkaProducerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXXXXXX:9093");//kafka cluster, broker list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator buffer size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create KafkaProducer client
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10 ; i++) {
producer.send(new ProducerRecord<>("my-topic","ImKey-"+i,"ImValue-"+i));
}
// close resource
producer.close();
}
}Description of configuration parameters:
send(): the method is asynchronous. Add a message to the buffer to wait for sending and return immediately. Producers send individual messages together in batches to improve efficiency.
ACK: it is the condition to judge whether the request is complete (it will judge whether it has been successfully sent, that is, the ACK mechanism mentioned last time). Specifying all will block the message, with low performance but the most reliable.
retries: if the request fails, the producer will retry automatically. We specify one time, but there may be duplicate data when starting the retry.
batch.size: Specifies the size of the cache, and the producer caches the unsent messages of each partition. A higher value will result in a larger batch and require more memory (because each active partition has a cache).
linger.ms: instructs the producer to wait for a period of time before sending the request. The waiting time is set to want more messages to be filled into the batch that is not full. The default buffer can be sent immediately, even if the buffer space is not full, but if you want to reduce the number of requests, you can set linker MS is greater than 0. It should be noted that under high load, batches will be formed at similar times, even if it is equal to 0.
buffer.memory: controls the total amount of cache available to the producer. If the message is sent faster than it is transmitted to the server, this cache space will be exhausted. When the cache space is exhausted, other sending calls will be blocked, and the threshold of blocking time passes max.block After MS is set, a TimeoutException will be thrown
key.serializer and value Serializer converts the user provided key and value objects ProducerRecord into bytes. You can use the attached bytearrayserializer or StringSerializer to handle simple string or byte types.
Run log:
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.clients.producer.ProducerConfig[main] - ProducerConfig values:
acks = all
batch.size = 16384
bootstrap.servers = [XXXXXX:9093]
buffer.memory = 33554432
client.id =
compression.type = none
connections.max.idle.ms = 540000
enable.idempotence = false
interceptor.classes = null
key.serializer = class org.apache.kafka.common.serialization.StringSerializer
linger.ms = 1
max.block.ms = 60000
max.in.flight.requests.per.connection = 5
max.request.size = 1048576
metadata.max.age.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytes = 32768
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 30000
retries = 1
retry.backoff.ms = 100
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.mechanism = GSSAPI
security.protocol = PLAINTEXT
send.buffer.bytes = 131072
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
ssl.endpoint.identification.algorithm = null
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLS
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
transaction.timeout.ms = 60000
transactional.id = null
value.serializer = class org.apache.kafka.common.serialization.StringSerializer
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.common.utils.AppInfoParser[main] - Kafka version : 0.11.0.3
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.common.utils.AppInfoParser[main] - Kafka commitId : 26ddb9e3197be39a
[Godway] WARN 2019-11-14 14:46 - org.apache.kafka.clients.NetworkClient[kafka-producer-network-thread | producer-1] - Error while fetching metadata with correlation id 1 : {my-topic=LEADER_NOT_AVAILABLE}
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.clients.producer.KafkaProducer[main] - Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
Process finished with exit code 0A warning {my topic = leader_not_available} indicates that the topic does not exist, but it doesn't matter. kafka will automatically create a topic for you, but the created topic has a partition and a copy:

Check the message of this topic:

The message is already in topic
The above example does not have a callback function. The send method has a callback function:
public class KafkaProducerCallbackDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXX:9093");//kafka cluster, broker list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator buffer size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create KafkaProducer client
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 10; i < 20 ; i++) {
producer.send(new ProducerRecord<String, String>("my-topic", "ImKey-" + i, "ImValue-" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null){
System.out.println("Message sent successfully!"+recordMetadata.offset());
}else {
System.err.println("Message sending failed!");
}
}
});
}
producer.close();
}
}The callback function is called asynchronously when the producer receives an ack. The method has two parameters, RecordMetadata and Exception. If the Exception is null, the message is sent successfully. If the Exception is not null, the message is sent failed.
Note: if the message fails to be sent, it will be retried automatically. We don't need to retry manually in the callback function. Using the callback is also non blocking. Moreover, callback is usually executed in the IO thread of the producer, so it is very fast. Otherwise, it will delay the sending of messages from other threads. If you need to execute a blocking or calculated callback (which takes a long time), it is recommended to use your own Executor in the callback body for parallel processing!
Synchronous sending API
Synchronous sending means that after a message is sent, the current thread will be blocked until an ACK is returned (this ack is not the same as the asynchronous ack mechanism).
This ack is the main thread blocked by Future. When the sending is completed, an ACK is returned to inform the main thread that the sending has been completed and continue
public Future<RecordMetadata> send(ProducerRecord<K,V> record,Callback callback)
send is asynchronous, and this method returns as soon as the message is saved in the message cache waiting to be sent. In this way, multiple messages are sent in parallel without blocking to wait for the response of each message.
The result of sending is a RecordMetadata, which specifies the partition for sending the message, the allocated offset and the timestamp of the message. If topic uses CreateTime, the timestamp provided by the user or the time sent (if the user does not specify the timestamp of the specified message) is used. If topic uses LogAppendTime, the timestamp is the local time of the broker when the message is appended.
Since the send call is asynchronous, it will return a future for the RecordMetadata of this message that allocates the message. If future calls get(), it will block until the relevant request is completed and the metadata of the message is returned, or a send exception is thrown.
Throws:
InterruptException - if the thread is blocking, interrupt.
SerializationException - if key or value is not a serializer for a given valid configuration.
TimeoutException - if the time for obtaining metadata or allocating memory for messages exceeds max.block ms.
KafkaException - Kafka related error (exception not belonging to public API).
public class KafkaProducerDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXX:9093");//kafka cluster, broker list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator buffer size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create KafkaProducer client
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 20; i < 30 ; i++) {
RecordMetadata metadata = producer.send(new ProducerRecord<>("my-topic", "ImKey-" + i, "ImValue-" + i)).get();
System.out.println(metadata.offset());
}
producer.close();
}
}API producer custom partition policy
Partition rules for producers when sending messages to topic:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) public ProducerRecord(String topic, Integer partition, K key, V value) public ProducerRecord(String topic, K key, V value) public ProducerRecord(String topic, V value)
According to the construction method of the parameters of the send method,
- The specified partition is sent to the specified partition
- If no partition is specified and there is a key value, the partition is allocated according to the Hash value of the key value
- No partition is specified, and no key value is specified. The partition allocation is polled (only once, and it will be in the order of the first partition in the future)
Custom partition
The custom partition needs to implement org apache. kafka. clients. producer. Partitioner interface. And implement three methods
public class KafkaMyPartitions implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}Custom partition instance:
KafkaMyPartitions:
public class KafkaMyPartitions implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
// Write your own partition policy here
// I specify 1 here
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}KafkaProducerCallbackDemo:
public class KafkaProducerCallbackDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXX:9093");//kafka cluster, broker list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator buffer size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Specify custom partition
props.put("partitioner.class","com.firehome.newkafka.KafkaMyPartitions");
// Create KafkaProducer client
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 20; i < 25 ; i++) {
producer.send(new ProducerRecord<String, String>("th-topic", "ImKey-" + i, "ImValue-" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null){
System.out.printf("Message sent successfully! topic=%s,partition=%s,offset=%d \n",recordMetadata.topic(),recordMetadata.partition(),recordMetadata.offset());
}else {
System.err.println("Message sending failed!");
}
}
});
}
producer.close();
}
}Return log:
Message sent successfully! topic=th-topic,partition=1,offset=27 Message sent successfully! topic=th-topic,partition=1,offset=28 Message sent successfully! topic=th-topic,partition=1,offset=29 Message sent successfully! topic=th-topic,partition=1,offset=30 Message sent successfully! topic=th-topic,partition=1,offset=31
You can see that it has been sent directly to partition 1.
Send messages through multiple threads
The Producer API is thread safe. You can directly send messages using multiple threads. Examples:
public class KafkaProducerThread implements Runnable {
private KafkaProducer<String,String> kafkaProducer;
public KafkaProducerThread(){
}
public KafkaProducerThread(KafkaProducer kafkaProducer){
this.kafkaProducer = kafkaProducer;
}
@Override
public void run() {
for (int i = 0; i < 20 ; i++) {
String key = "ImKey-" + i+"-"+Thread.currentThread().getName();
String value = "ImValue-" + i+"-"+Thread.currentThread().getName();
kafkaProducer.send(new ProducerRecord<>("th-topic", key, value));
System.out.printf("Thread-name = %s, key = %s, value = %s",Thread.currentThread().getName(),key,value);
}
}
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXXXXX:9093");//kafka cluster, broker list
props.put("acks", "all");
props.put("retries", 1);//retry count
props.put("batch.size", 16384);//Batch size
props.put("linger.ms", 1);//waiting time
props.put("buffer.memory", 33554432);//RecordAccumulator buffer size
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Create KafkaProducer client
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
KafkaProducerThread producerThread1 = new KafkaProducerThread(producer);
//KafkaProducerThread producerThread2 = new KafkaProducerThread(producer);
Thread one = new Thread(producerThread1, "one");
Thread two = new Thread(producerThread1, "two");
System.out.println("Thread start");
one.start();
two.start();
}
}Here is just a simple example.
Consumer API
kafka client consumes messages from the cluster through TCP long connection, transparently handles the failed server in kafka cluster, and transparently adjusts the data partition to adapt to the changes in the cluster. Also interact with servers to balance consumers.
Offset and consumer location
kafka saves an offset for each message in the partition, which is the unique identifier of a message in the partition. It also indicates the location of consumers in the zone. For example, a consumer whose location is 5 (indicating that they have consumed messages from 0 to 4) will receive a message with an offset of 5. In fact, there are two "location" concepts related to consumers:
The consumer's location gives the offset of the next record. It is one larger than the maximum offset the consumer sees in the partition. It grows automatically every time a consumer receives a message in a call to poll(long).
The "submitted" location is the last offset that has been safely saved. If the process fails or restarts, the consumer will revert to this offset. Consumers can choose to submit the offset automatically on a regular basis, or they can choose to control it manually by calling the commit API (such as commitSync and commitAsync).
This difference is that consumers control when a message is considered to have been consumed, and the control is vested in consumers.
Consumer groups and topic subscriptions
Kafka's consumer group concept divides messages and processes them through the process pool. These processes can be run on the same machine or distributed to multiple machines to increase scalability and fault tolerance Consumers with ID will be regarded as the same consumer group.
Each consumer in the group dynamically subscribes to a topic list through the subscribe API. kafka sends the subscribed topic message to each consumer group. And achieve the average among all members of the consumer group by balancing the partition. Therefore, each partition is allocated exactly one consumer (in a consumer group). All if a topic has 4 partitions and a consumer group has only 2 consumers. Then each consumer will consume 2 partitions.
Members of the consumer group are dynamically maintained: if a consumer fails. The partition assigned to it will be reassigned to other consumers in the same group. Similarly, if a new consumer is added to the group, one of the existing consumers will be moved to it. This is called rebalancing grouping. Rebalancing will also occur when a new partition is added to the subscribed topic, or when a new topic matching the subscribed regular expression is created. New partitions are automatically discovered and assigned to the members of the group through scheduled refreshes.
Conceptually, you can think of consumer groups as a single logical subscriber composed of multiple processes. As a multi subscription system, Kafka supports any number of consumer groups for a given topic without duplication.
This is a slight summary of the functions common in messaging systems. All processes will be part of a single consumer group (similar to the semantics of queues in traditional messaging systems), so messaging is balanced in groups like queues. Unlike traditional messaging systems, though, you can have multiple such groups. However, each process has its own consumer group (similar to the semantics of pub sub in the traditional message system), so each process will subscribe to all messages of the topic.
In addition, when packet reallocation occurs automatically, consumers can be notified through the ConsumerRebalanceListener, which allows them to complete the necessary application level logic, such as status clearing, manual offset submission, etc
It also allows consumers to manually assign specified partitions by using assign(Collection). If manually assign partitions, dynamic partition allocation and coordination of consumer groups will fail.
Consumer fault found
Subscribe to a group of topic s. When poll(long) is called, consumers will automatically join the consumer group. As long as the poll is continuously invoked, the consumer will remain available and continue to receive data from the allocated partition. In addition, consumers regularly send heartbeat to the server. If the consumer crashes or can no longer session timeout. If the heartbeat is sent within the time configured by MS, the consumer is considered dead and its partition will be reassigned.
There is also a possibility that consumers may encounter a live lock, which continuously sends a heartbeat but does not process it. To prevent consumers from having partitions all the time, we use max.poll interval. MS active monitoring mechanism. On this basis, if you call the poll more frequently than the maximum interval, the client will actively leave the group so that other consumers can take over the partition. When this happens, you will see that the offset submission fails (CommitFailedException caused by calling commitSync()). This is a security mechanism that ensures that only active members can submit offsets. So to stay in the group, you must keep calling poll.
The consumer provides two configuration settings to control the poll cycle:
- max.poll.interval.ms: increasing the poll interval can provide consumers with more time to process the returned messages (the messages returned by calling poll (long) are usually a batch). The disadvantage is that the larger this value will delay the group rebalancing.
- max.poll.records: this setting limits the number of messages returned per poll call, which makes it easier to predict the maximum value to be processed per poll interval. By adjusting this value, you can reduce the poll interval and reduce the number of rebalancing packets
For unpredictable message processing times, these options are not enough. The recommended way to handle this situation is to move the message processing to another thread and let the consumer continue to call poll. However, care must be taken to ensure that the submitted offset does not exceed the actual position. In addition, you must disable automatic submission and manually submit offsets for records only after the thread completes processing. Also note that you need to pause the partition. You won't receive new messages from poll and let the thread process the messages returned before (if your processing capacity is slower than pulling messages, creating a new thread will lead to machine memory overflow).
example:
Auto commit offset
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","xxxxxxxxxx:9093");
props.put("group.id","test-6");//Consumer group, as long as group If the ID is the same, they belong to the same consumer group
props.put("enable.auto.commit","true");//Auto submit offset
props.put("auto.commit.interval.ms","1000"); // Auto submit interval
props.put("max.poll.records","5"); // Number of data pieces pulled
props.put("session.timeout.ms","10000"); // The duration of the session. If there is no heartbeat after this time, the consumer group will be excluded
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// You can write multiple topic s
consumer.subscribe(Arrays.asList("my-topic"));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
System.out.println("Processed a batch of data!");
}
}Configuration Description:
bootstrap.servers: the cluster is configured by bootstrap Servers specifies one or more brokers. Instead of specifying all brokers, it will automatically discover the remaining brokers in the cluster (it is better to specify multiple in case of server failure)
enable.auto.commit: Auto submit offset. If Auto submit offset is set, the following settings must be used.
auto.commit.interval.ms: Auto submit interval, used in conjunction with auto submit offset
max.poll.records: controls the number of messages pulled from the broker
poll(long time): this parameter will be used when the consumer cannot get the message. In order to reduce the invalid circular request message, the consumer will request the message every long time, in milliseconds.
session.timeout.ms: the broker automatically detects the failed process in the consumer group through the heartbeat machine. The consumer will automatically ping the cluster and tell the incoming group that it is still alive. As long as the consumer can do this, it is considered alive and reserves the right to allocate partitions to it if it stops beating for more than session timeout. MS, then it will be considered as a failure, and its partition will be allocated to other processes.
auto.offset.reset: this attribute is very important. I'll explain it in detail later
Here is an explanation of auto commit. interval. MS and when to submit the consumer offset, tested:
- Set props put("auto.commit.interval.ms","60000");
The automatic submission time is one minute, which means that any number of messages you pull within this minute will not be submitted for consumption. If you close the consumer at this time (within one minute), the next consumption will be the same as the first consumption data. Even if you consume all messages within one minute, as long as you close the program within one minute, If the offset cannot be submitted, the data can be consumed repeatedly all the time.
- Set props put("auto.commit.interval.ms","3000");
However, sleep is set during consumption.
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","xxxxxxxxxxxx:9093");
props.put("group.id","test-6");//Consumer group, as long as group If the ID is the same, they belong to the same consumer group
props.put("enable.auto.commit","true");//Auto submit offset
props.put("auto.commit.interval.ms","100000"); // Auto submit interval
props.put("max.poll.records","5"); // Number of data pieces pulled
props.put("session.timeout.ms","10000"); // The duration of the session. If there is no heartbeat after this time, the consumer group will be excluded
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest"); //
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// You can write multiple topic s
consumer.subscribe(Arrays.asList("my-topic"));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
try {
Thread.sleep(5000L);
System.out.println("Waiting for 5 seconds!!!!!!!!!!!! It's been 15 seconds");
Thread.sleep(5000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Processed a batch of data!");
}
}Here, if you consume the first batch of data, the closing program will not submit the offset when executing the second poll. Only when executing the second poll will you submit the last offset of the previous one.
auto.offset.reset explanation:
auto. offset. There are three values of reset: early, late and none, which represent different meanings
earliest: When there are submitted under each partition offset From submitted offset Start consumption; No submitted offset When consuming from scratch, the most commonly used value latest: When there are submitted under each partition offset From submitted offset Start consumption; No submitted offset Consume the newly generated data under the partition none: topic There are submitted for each partition offset When, from offset After consumption, as long as there is no committed partition offset,An exception is thrown
!! Note: when latest is used and the partition has no committed offset, consuming the newly generated data under the partition is actually setting the offset value directly to the location of the last message. For example, there is a topic in the demo of 30 pieces of data. Each partition does not submit offset. If you use latest, you will find that the offset is already at 30, so you can only consume the newly generated data!!!!
Manually submit offset
There is no need to submit the offset on a regular basis. You can control the offset yourself. After the messages have been consumed by us, you can manually submit their offset. This is very suitable for some of our processing logic.
There are two methods to manually submit offsets: commitSync (synchronous submission) and commitAsync (asynchronous submission). The same points of both will submit the highest offset of a batch of data in this poll; The difference is that commitSync will fail to retry until the submission is successful (if there is an unrecoverable reason, the submission will also fail), and then pull new data. commitAsync does not have a retry mechanism (pull new data after submitting, regardless of whether the submission is successful or not), so the submission may fail.
example:
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","XXXXXC:9093");
props.put("group.id","test-11");//Consumer group, as long as group If the ID is the same, they belong to the same consumer group
props.put("enable.auto.commit","false");//Auto submit offset
props.put("auto.commit.interval.ms","1000"); // Auto submit interval
props.put("max.poll.records","20"); // Number of data pieces pulled
props.put("session.timeout.ms","10000"); // The duration of the session. If there is no heartbeat after this time, the consumer group will be excluded
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
int i= 0;
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
i++;
}
if (i == 20){
System.out.println("i_num:"+i);
// Synchronous submission
consumer.commitSync();
// Asynchronous commit
// consumer.commitAsync();
}else {
System.out.println("Less than 20, not submitted"+i);
}
i=0;
}
}These are all submission offsets. If we want to more carefully control the submission of offset, we can customize the submission offset:
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","XXXXXXXXXX:9093");
props.put("group.id","test-18");//Consumer group, as long as group If the ID is the same, they belong to the same consumer group
props.put("enable.auto.commit","false");//Auto submit offset
props.put("auto.commit.interval.ms","1000000"); // Auto submit interval
props.put("max.poll.records","5"); // Number of data pieces pulled
props.put("session.timeout.ms","10000"); // The duration of the session. If there is no heartbeat after this time, the consumer group will be excluded
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitAsync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
for (Map.Entry<TopicPartition,OffsetAndMetadata> entry : map.entrySet()){
System.out.println("Submitted partition:"+entry.getKey().partition()+",Submitted offset:"+entry.getValue().offset());
}
}
});
}
}
}The specified partition of the subscription
Through the consumer, Kafka will allocate a partition to the consumer through the partition, but we can also specify the partition consumption message. To use the specified partition, we only need to call assign(Collection) to consume the specified partition:
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","XXXXXXXXX:9093");
props.put("group.id","test-19");//Consumer group, as long as group If the ID is the same, they belong to the same consumer group
props.put("enable.auto.commit","false");//Auto submit offset
props.put("auto.commit.interval.ms","1000000"); // Auto submit interval
props.put("max.poll.records","5"); // Number of data pieces pulled
props.put("session.timeout.ms","10000"); // The duration of the session. If there is no heartbeat after this time, the consumer group will be excluded
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
// You can specify multiple partitions with different topics or partitions with the same topic. I only specify one partition here
TopicPartition topicPartition = new TopicPartition("my-topic", 0);
// assign is used for calling the specified partition, and subscribe is used for consuming topic
consumer.assign(Arrays.asList(topicPartition));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitAsync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
for (Map.Entry<TopicPartition,OffsetAndMetadata> entry : map.entrySet()){
System.out.println("Submitted partition:"+entry.getKey().partition()+",Submitted offset:"+entry.getValue().offset());
}
}
});
}
}
}Once the partition is manually allocated, you can call poll in the loop. The consumer partition still needs to submit offset, but now the partition settings can only be modified by calling assign, because manual allocation will not carry out grouping coordination. Therefore, consumer failure or change in the number of consumers will not cause partition rebalancing. Each consumer works independently (even if they share groupid with other consumers). In order to avoid offset submission conflict, you usually need to confirm that the groupid of each consumer instance is unique.
be careful:
The subscription topic mode (subcribe) of manual partition allocation and dynamic partition allocation cannot be mixed.
Click follow to learn about Huawei's new cloud technology for the first time~