In the previous article on linked lists, I wrote the LRU cache elimination algorithm based on linked lists,
This is a link https://mp.csdn.net/mp_blog/creation/editor/120435048
Let's take a look at how the hash table and linked list in LinkedHashMap combine to implement the LRU cache elimination algorithm.
LRU cache elimination algorithm
Let's review the implementation based on linked list
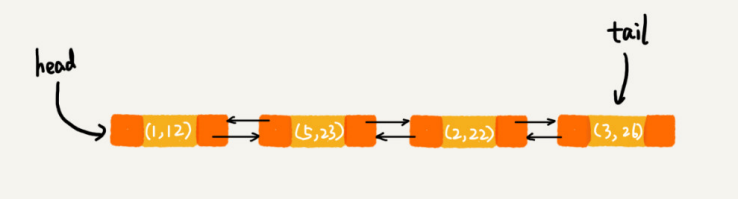
We maintain an ordered linked list. The nodes closer to the tail of the linked list store the earlier accessed data (the head node stores the latest accessed data, and the tail node stores the earliest accessed data), and record the head pointer and tail pointer, pointing to the head node and tail node of the linked list respectively. Because the cache size is limited, when the cache space is insufficient and the data needs to be eliminated, we will directly delete the nodes at the end of the linked list.
When you want to cache some data, look up this element in the linked list. If it is not found, put the data directly into the head of the linked list. If found, put it directly at the head of the linked list. At this time, because you want to traverse the search data, the time complexity will be O(n).
Generally speaking, a cache system mainly includes the following operations
Add a data to the cache
Delete a data in the cache
Find a data in the cache
These three operations involve searching data in the linked list, but if the linked list is applicable, the time complexity will be O(n). Can we assume that a hash table is used as an index on the basis of the original linked list, and each node in the hash table stores an additional pointer to the ordered linked list. Through the hash table, we can quickly find the nodes of the ordered linked list that need to be deleted. As shown in the figure.

Let's see how to find, delete and add a data in the cache through the code.
package com.example.demo;
import java.util.HashMap;
import java.util.Map;
public class LRUCache {
private class DLinkedNode{
public int key;
public int value;
public DLinkedNode pre;
public DLinkedNode next;
public DLinkedNode(int key,int value){
this.key = key;
this.value = value;
}
}
private Map<Integer,DLinkedNode> cache = new HashMap<>();
private int size;
private int capacity;
private DLinkedNode head;
private DLinkedNode tail;
public LRUCache(int capacity){
this.size = 0;
this.capacity = capacity;
this.head = new DLinkedNode(-1,-1);
this.tail = new DLinkedNode(-1,-1);
this.head.next = tail;
this.tail.pre = head;
this.head.pre = null;
this.tail.next = null;
}
private void removeNode(DLinkedNode node){
node.next.pre = node.pre;
node.pre.next = node.next;
}
private void addNodeAtHead(DLinkedNode node){
node.next = head.next;
tail.pre = node;
head.next = node;
node.pre = head;
}
//Find data and move to header
public int get(int key){
if(size == 0){
return -1;//No data in cache
}
//To find a node
DLinkedNode dLinkedNode = cache.get(key);
if(dLinkedNode == null){
return -1;
}
removeNode(dLinkedNode);
addNodeAtHead(dLinkedNode);
return dLinkedNode.value;
}
//delete
public void remove(int key){
DLinkedNode dLinkedNode = cache.get(key);
if(dLinkedNode != null){
removeNode(dLinkedNode);
cache.remove(key);
return;
}
}
//insert
public void put(int key,int value){
DLinkedNode dLinkedNode = cache.get(key);
//If the data already exists, move it directly to the header
if(dLinkedNode != null){
dLinkedNode.value = value;
removeNode(dLinkedNode);
addNodeAtHead(dLinkedNode);
return;
}
//When the size is equal to the capacity of the hash table, the tail node is deleted
if(size == capacity){
cache.remove(tail.pre.key);
removeNode(tail.pre);
size--;
}
DLinkedNode dLinkedNode1 = cache.get(key);
addNodeAtHead(dLinkedNode1);
cache.put(key,dLinkedNode1);
size++;
}
}
Java LinkedHashMap
1 HashMap<Integer, Integer> m = new LinkedHashMap<>();
2 m.put(3, 11);
3 m.put(1, 12);
4 m.put(5, 23);
5 m.put(2, 22);
6
7 for (Map.Entry e : m.entrySet()) {
8 System.out.println(e.getKey());
9 }// 10 is the initial size, 0.75 is the loading factor, and true means sorting by access time
2 HashMap<Integer, Integer> m = new LinkedHashMap<>(10, 0.75f, true);
3 m.put(3, 11);
4 m.put(1, 12);
5 m.put(5, 23);
6 m.put(2, 22);
7
8 m.put(3, 26);
9 m.get(5);
10
11 for (Map.Entry e : m.entrySet()) {
12 System.out.println(e.getKey());
13 }