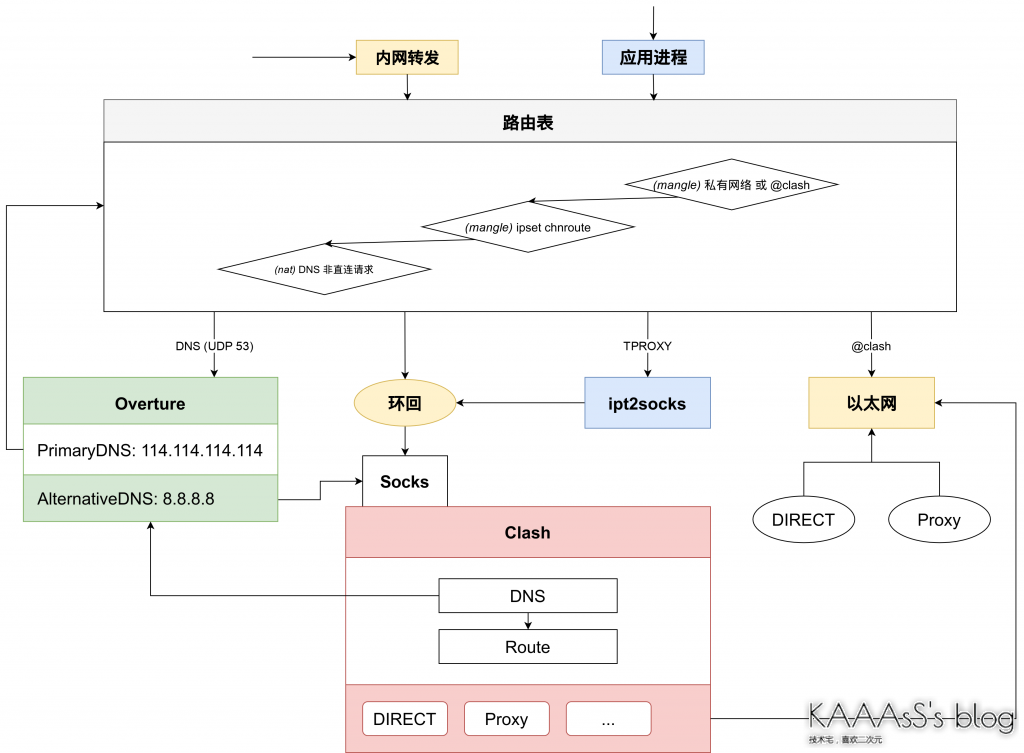
Recently, due to the approaching exam week, the blog has not been updated much. This time, I caught the opportunity to write more. In fact, I always have a need to seamlessly access the home network and NAS devices at school, so I always want to set up a transparent agent. So I studied it intermittently for several days recently, and finally found out a transparent agency scheme that I was relatively satisfied with. Therefore, I took the time to write a blog and have the right to be a record. Note in advance: this blog only describes a transparent proxy scheme and does not contain any content of proxy server construction. The general structure of the scheme is shown in the figure below, and the specific details and configuration will be described in detail later.
cause
For me, the most important advantages of transparent agent are LAN device access and cli program. I originally used proxychain, or hook, for the CLI program. However, this method can not implement the requested go program for myself, and there are also problems in the processing of the lower layer graftcp upstream of DNS, so I finally chose to use a transparent proxy to solve it. I used New vernacular TPROXY configuration, which can solve almost all my network pain points.
However, there are still some problems with this scheme (mainly v2ray). The first is that the configuration switching is very complex, which can only be achieved by restarting the v2ray process. Secondly, it is impossible to achieve Fullcone NAT, which is limited by the function of v2ray itself. Later, I changed clash and kept v2ray as the front agent of the transparent agent. The RESTful API provided by clash really solves my problem about configuration switching, but I find that I still can't achieve Fullcone. In the follow-up investigation, I found that this is not only the limitation of vmess protocol itself, but also the behavior of v2ray, which is doomed to fail to achieve Fullcone. Moreover, it is unacceptable for me to only use a complex program such as v2ray as the preamble of clash, so I intend to explore a new transparent proxy scheme.
requirement
Fullcone NAT is required. The second is IPv6 support, but this is relatively empty, because it is very complicated to set v6 gateway for LAN devices. The last is performance. Because my goal is to deploy the agent on the side route (raspberry pie), the performance of the agent is better and the occupation can not be too large. In addition, it is necessary to reduce the number of packet routing as much as possible, put the routing work in the kernel space (netfilter) as much as possible, and reduce the overhead of user space switching.
As for why not deploy on the primary route, the reason is very simple: the performance of the primary route is poor. Moreover, if the side route agent is set, you can set DHCP through the main route to control whether the device enables the agent. In addition, there is the advantage that Manjaro can be deployed in my laptop for portable use.
Back end agent
The backend agent uses clash. Although v2ray is more flexible in configuration, clash is more flexible in running state. The RESTful API is more important to me because it allows me to quickly switch between configurations using web apps such as yacd.
Midrange agent
Midrange agent I use a small tool ipt2socks . Through this tool, you can receive TPROXY traffic from iptables and go to the Socks entry of clash.
Friends who know about clash may know that in fact, clash itself provides TUN function to handle traffic from iptables. Why do you still choose ipt2socks and TPROXY? Indeed, TUN has little impact on iptables configuration, and its compatibility is actually higher than TPROXY (some distributions do not come with it). Most importantly, it also saves a process of packaging data packets into Socks protocol.
My reason for this is decoupling. Regardless of whether the implementation of clash is stable or not, it is certain that almost no agent software does not support Socks protocol, while few support TUN. In addition, using Socks also means supporting network applications using Socks interfaces such as MITMProxy. As for performance, in the final configuration, most requests will not actually pass through the Socks interface. In addition, the implementation of ipt2socks is quite pure and lightweight (less than 100K after compilation), so the performance overhead is completely worth it.
The configuration of ipt2socks is so simple that there is no configuration at all. All configurations are completed through command line parameters. You can use systemd to run as a daemon. The configuration is as follows
[Unit] Description=utility for converting iptables(redirect/tproxy) to socks5 After=network.target [Service] User=nobody EnvironmentFile=/etc/ipt2socks/ipt2socks.conf CapabilityBoundingSet=CAP_NET_ADMIN CAP_NET_BIND_SERVICE AmbientCapabilities=CAP_NET_ADMIN CAP_NET_BIND_SERVICE NoNewPrivileges=true ExecStart=/usr/bin/ipt2socks -s $server_addr -p $server_port -l $listen_port -j $thread_nums $extra_args Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
The configuration file / etc / ipt2socks / ipt2socks. Is manually added here Conf, if you miss the simplicity of the command line parameters, you can also directly modify ExecStart. The configuration file format is as follows
# ipt2socks configure file # # detailed helps could be found at: https://github.com/zfl9/ipt2socks # Socks5 server ip server_addr=127.0.0.1 # Socks5 server port server_port=1080 # Listen port number listen_port=60080 # Number of the worker threads thread_nums=1 # Extra arguments extra_args=
Related configuration and compilation processes have been added to AUR . Archlinux users can directly use programs such as yay for installation.
DNS
My final choice is overture.
When it comes to featured DNS resolution, most people probably think of chinadns at the first time. Indeed, chinadns is a fairly complete and reliable program, but chinadns is obviously not suitable for directly serving as a local DNS server - it does not have a good cache and does not support complex routing rules. Therefore, the usual approach is to set a dnsmasq in front for caching and shunting, and then take chinadns as the upstream. However, dnsmasq itself does not support proxy access, so you also need to divert requests from dnsmasq and chinadns at the iptables layer. This is not over. If your back-end agent does not support UDP, you also need to convert the UDP requested by DNS into TCP request (dns2tcp tool). So finally, you got the world famous painting chinadns+dnsmasq+dns2tcp. For the time being, the number of trips in and out of iptables has far exceeded the number of works in half life. I think this complex configuration alone is stupid enough.
In addition, another possible option is clash's built-in DNS. Moreover, clash also has a make IP extension to reduce the need for local DNS resolution. However, there are two problems. One is consistent with the previous reason for not choosing TUN; The other is that other schemes can actually achieve similar results, and the use of fake IP is at the cost of lack of DNS cache and possible wrong resolution content.
So I found overture. It supports IPv6, can easily replace the Upstream of DNS, supports proxy requests through Socks, supports EDNS, and has a relatively perfect Dispatcher. It can be said that it basically meets all my requirements. Moreover, it additionally supports RESTful API (although it can only check cache at present), which makes it possible for further configuration management.
Refer to the official configuration for configuration, and the default configuration of AUR package is OK. Note that you need to change WhenPrimaryDNSAnswerNoneUse to alternative DNS.
Routing diversion
With all the pieces together, the next step is to sew them together. Of course, the props used for stitching are iptables (IPv6 is ipt6ables, and the configuration is almost identical).
The diversion strategy is very simple, that is, DNS is handed over to overture, the private address is directly connected to the target IP segment, and the rest is handed over to ipt2socks. However, in order to realize the direct connection of the target IP segment, it is also necessary to set relevant rule sets (because there may be too many rules. Taking the mainland IP segment as an example, the effect of using iptables is terrible). Therefore, first introduce the configuration related to ipset.
ipset
The set module of iptables can realize routing by rule set, and the addition of rule set is completed through ipset. stay apnic.net You can query the IP addresses assigned to the Chinese mainland, so you can add them to the rule set when parsing. The script is as follows
# Download and parse route
wget --no-check-certificate -O- 'http://ftp.apnic.net/apnic/stats/apnic/delegated-apnic-latest' | grep CN > tmp_ips
cat tmp_ips | grep ipv4 | awk -F\| '{ printf("%s/%d\n", $4, 32-log($5)/log(2)) }' > chnroute.set
cat tmp_ips | grep ipv6 | awk -F\| '{ printf("%s/%d\n", $4, 32-log($5)/log(2)) }' > chnroute6.set
rm -rf tmp_ips
# Import ipset table
sudo ipset -X chnroute &>/dev/null
sudo ipset -X chnroute6 &>/dev/null
sudo ipset create chnroute hash:net family inet
sudo ipset create chnroute6 hash:net family inet6
cat chnroute.set | sudo xargs -I ip ipset add chnroute ip
cat chnroute6.set | sudo xargs -I ip ipset add chnroute6 ipAfter running, you can get the rule sets applicable to IPv4 and IPv6 (chnroute and chnroute 6).
iptables
It's really starting to sew this time. The overall idea is the same as the configuration of the new vernacular. Route the packets of the OUTPUT chain to the preouting chain, and then forward them with the TPROXY module. As for why we should go around such a big circle, it is related to the implementation of TPROXY itself. You can refer to @ yesterday's TProxy Quest.
Therefore, rules can be roughly divided into three parts: policy routing, preouting chain and OUTPUT chain. The summary is as follows:
# The packet matched by fwmark enters the local loopback ip -4 rule add fwmark $lo_fwmark table 100 ip -4 route add local default dev lo table 100 ########## PREROUTING Chain configuration ########## iptables -t mangle -N TRANS_PREROUTING iptables -t mangle -A TRANS_PREROUTING -i lo -m mark ! --mark $lo_fwmark -j RETURN # Rule routing iptables -t mangle -A TRANS_PREROUTING -p tcp -m addrtype ! --src-type LOCAL ! --dst-type LOCAL -j TRANS_RULE iptables -t mangle -A TRANS_PREROUTING -p udp -m addrtype ! --src-type LOCAL ! --dst-type LOCAL -j TRANS_RULE # TPROXY routing iptables -t mangle -A TRANS_PREROUTING -p tcp -m mark --mark $lo_fwmark -j TPROXY --on-port $tproxy_port --on-ip $loopback_addr --tproxy-mark $tproxy_mark iptables -t mangle -A TRANS_PREROUTING -p udp -m mark --mark $lo_fwmark -j TPROXY --on-port $tproxy_port --on-ip $loopback_addr --tproxy-mark $tproxy_mark # Application rules iptables -t mangle -A PREROUTING -j TRANS_PREROUTING ########## OUTPUT Chain configuration ########## iptables -t mangle -N TRANS_OUTPUT # Direct @ clash iptables -t mangle -A TRANS_OUTPUT -j RETURN -m owner --uid-owner $direct_user iptables -t mangle -A TRANS_OUTPUT -j RETURN -m mark --mark 0xff # (compatible configuration) direct so_ Flow with mark of 0xff # Rule routing iptables -t mangle -A TRANS_OUTPUT -p tcp -m addrtype --src-type LOCAL ! --dst-type LOCAL -j TRANS_RULE iptables -t mangle -A TRANS_OUTPUT -p udp -m addrtype --src-type LOCAL ! --dst-type LOCAL -j TRANS_RULE # Application rules iptables -t mangle -A OUTPUT -j TRANS_OUTPUT
Note here that since the traffic of clash and overture needs to be directly connected, I choose to use the owner extension to directly connect all the traffic of user clash. Then run the clash and overture processes in the user clash. In addition, because the routing rules of the two chains are common (fwmark can also be used to route the preceding chain), trans is independent_ Rule is used to handle the routing of the common part (mainly mark fwmark).
########## Agent rule configuration ##########
iptables -t mangle -N TRANS_RULE
iptables -t mangle -A TRANS_RULE -j CONNMARK --restore-mark
iptables -t mangle -A TRANS_RULE -m mark --mark $lo_fwmark -j RETURN # Avoid loopback
# Private address
for addr in "${privaddr_array[@]}"; do
iptables -t mangle -A TRANS_RULE -d $addr -j RETURN
done
# ipset routing
iptables -t mangle -A TRANS_RULE -m set --match-set $chnroute_name dst -j RETURN
# TCP/UDP rerouting
iptables -t mangle -A TRANS_RULE -p tcp --syn -j MARK --set-mark $lo_fwmark
iptables -t mangle -A TRANS_RULE -p udp -m conntrack --ctstate NEW -j MARK --set-mark $lo_fwmark
iptables -t mangle -A TRANS_RULE -j CONNMARK --save-markThe rule is very simple. Basically, packets matching private addresses and rule set chnroute are not marked. CONNMARK is used to mark the entire connected packet to reduce the number of matches. In addition, the packets of the OUTPUT chain will be routed back to the prior chain, resulting in the second matching of TRANS_RULE, so there is no need to match packets with fwmark (packets without fwmark cannot be matched twice).
Then there is the interception of DNS traffic. Because I need to intercept all DNS traffic (UDP53) in the network (no matter which address is requested, so there is no need to manually change the DNS configuration), it is inevitable to need a DNAT to forward the traffic to overlay, so we also need to create the forwarding rules of the nat table. However, since the nat table is located in the back, you need to match trans_ RETURN all DNS traffic before rule (located in mangle table), so that the traffic can enter the forwarding rules of nat table.
# LAN DNS routing
iptables -t mangle -A TRANS_PREROUTING -p udp -m addrtype ! --src-type LOCAL -m udp --dport 53 -j RETURN
iptables -t nat -A TRANS_PREROUTING -p udp -m addrtype ! --src-type LOCAL -m udp --dport 53 -j REDIRECT --to-ports $dns_port
# This is followed by the trans of the preouting chain_ RULE
# ...
# Local DNS routing
iptables -t mangle -A TRANS_OUTPUT -p udp -m udp --dport 53 -j RETURN
for addr in "${dns_direct_array[@]}"; do
iptables -t nat -A TRANS_OUTPUT -d $addr -p udp -m udp --dport 53 -j RETURN
done
iptables -t nat -A TRANS_OUTPUT -p udp -m udp --dport 53 -j DNAT --to-destination $local_dns
# This is followed by the trans of the OUTPUT chain_ RULEThere is also a hole here, that is, the owner extension can not well identify the sender of UDP traffic. Therefore, it is also necessary to add matching rules to the directly connected DNS server (I am not satisfied with this! But there is no way...). But fortunately, it only needs to be added to the OUTPUT chain, because LAN devices do not have to be connected directly.
As for the effect... BOOM ignores the moving network speed. In fact, it has just tried to reach about 40Mbps, but it is too lazy to update the map (escape)

Sum up
Finally, three scripts are written:
- transparent_proxy.sh: transparent proxy rule setting, which needs to be started and run
- import_chnroute.sh: Download and configure the chnroute rule, which needs to be run at least once, and the rule set file should be consistent with the transparent_proxy.sh same directory (of course, you can also modify the configuration)
- flush_iptables.sh: clean up all added rules (except ipset)
These codes can be found in My GitHub Found. I made a lot of references when writing ss-tproxy Project related code, thank you very much for this repo.
To deploy this configuration, you need to install in addition to the three shell s ipt2socks,overture (AUR has corresponding packages: ipt2socks,overture ). In addition, you also need a proxy that supports the Socks protocol (I use clash, of course, others can). After configuring according to the document, modify the transparent_ proxy. The beginning of SH is the relevant content configured for you.
defect
Unfortunately, there are still some imperfections in this configuration. But fortunately, it's not a big problem. You can also save the country with a curve.
- For proxy servers in the form of domain names, DNS must be configured for the proxy. Because the real IP of the proxy server needs to be resolved when the agent starts, it needs to request overture. There is no problem with this, but for performance, alternative dnsconcurrent is usually turned on. At this time, Overture will request clash to access the standby DNS, but clash has not been started. In fact, there was no problem, but the mistake was that Overture would crash when it couldn't connect to clash! Then, because the clash cannot resolve the real IP, it also crashes together, and then Overture crashes, Overture crashes, and clash crashes... There are two solutions. One is to carefully adjust the startup sequence - iptables rules should be requested after the clash is resolved; The other is to configure the DNS of the clash itself so that the request does not go overture. The former is a little troublesome, while the latter actually adds a set of DNS configuration different from overture. However, fortunately, DNS resolution has been completed when ordinary traffic reaches clash. Except for the Socks directly connected to clash, built-in DNS will not be used, so I chose the latter. The essence is an overture problem, so it can be solved if it is repaired.
- Local direct DNS. As mentioned earlier in DNS configuration, direct connection rules must be set for local direct DNS. This causes the local machine to be unable to intercept DNS requests to the direct DNS server. The solution is very simple, that is, do not set the local DNS to connect directly to the DNS servers.
- overture does not support UDP via Socks. It doesn't matter. TCP query is OK, and the impact on performance can be ignored.
Brother, why is it all DNS
Reference
- [v1.0] Tun+MITMProxy( https://blog.yesterday17.cn/post/transparent-proxy-with-mitmproxy/)
- zfl9/ss-tproxy(https://github.com/zfl9/ss-tproxy/)