1. Project Background
Traditional data warehouse organization structure is designed for OLAP (Online Transaction Analysis) requirements of offline data. The common way to import data is to use sqoop or spark timer jobs to import business database data into warehouses one by one.With the increasing requirement of real-time in data analysis, hourly or even minute data synchronization is becoming more and more common.Thus, the development of spark/flink Streaming-based (quasi) real-time synchronization system is expanded.
However, real-time synchronization warehouses face several challenges from the beginning:
- Small file problem.Whether it's spark's microbatch mode or flink's step-by-step processing mode, several M KB or even dozens of KB of files are written to HDFS each time.A large number of small files generated over a long period of time will exert enormous pressure on the HDFS namenode.
- Support for update operations.The HDFS system itself does not support data modification and cannot modify records during synchronization.
- Transactional.How to ensure Transactionality whether you append or modify data.That is, data is written to HDFS only once during the stream handler commit operation, and when the program rollback, the written or partially written data can be deleted accordingly.
Hudi is one of the solutions to these problems.Following is a brief introduction to Hudi, translated from the official website.
2. Introduction to Hudi
2.1 Timeline
Inside Hudi, a timeline is maintained for all operations on the table at the instant of operation, which provides a view of the table at a given time and allows efficient extraction of delayed arrival data.Each moment contains:
- Moment behavior: The type of table operation that contains:
commit: submit, write batch data atomically to a table;
clean: clean, background jobs, constantly cleaning up old versions of data that you don't need;
delta_commit:delta submission writes batch records of atomicity to the MergeOnRead table, and the data is written to the delta log file;
compacttion: Compress, background jobs, merge data of different structures, such as log files that record row storage for update operations, into columns.Compression itself is a special commit operation;
Rollback: rollback, delete all partially written files if some failures occur;
Savepoint: A savepoint that marks certain filegroups as "saved" so that cleaner does not delete them;
- Moment time: The timestamp at which the operation begins;
- Status: The current state of the moment, which contains:
requested An operation was scheduled but not initialized
inflight an operation is in progress
Completed An operation has been completed on the timeline
Hudi guarantees atomicity and timeline consistency of operations performed along timelines.
2.2 File Management
Hudi tables exist in the DFS system's base path (customized when users write to Hudi) directory, where they are divided into different partitions.Each partition is uniquely identified by partition path and organized in the same way as Hive.
Within each partition, files are divided into FileGroup filegroups by a unique FileId file id.Each FileGroup contains multiple FileSlice file slices, each containing a base file base file (parquet file) formed by a commit or compaction operation, and a log file (log file) containing an inserts/update operation on the base file.Hudi is designed with MVCC, the compaction operation combines log files and corresponding base files into new file slices, and the clean operation deletes invalid or older files.
2.3 Index
Hudi provides efficient upsert operations by mapping the Hoodie key (record key + partition path) to the file id.When the first version of a record is written to a file, the mapping relationship between the record key value and the file does not change.In other words, a mapped filegroup always contains all versions of a set of records.
2.4 Table Type & Query
The Hudi table type defines how the data is indexed, distributed to the DFS system, and how these basic attributes and timeline events are applied to the organization.Query types define how underlying data is exposed to queries.
| Table type | Supported Query Types |
|---|---|
| Copy On Write Write Copy | Snapshot Query + Incremental Query |
| Merge On Read Merge | Snapshot Query+Incremental Query+Read Optimization |
2.4.1 Table Type
Copy On Write: Only parquet s are used to store files.When updating data, merge files are synchronized while writing, only modifying the file version and rewriting.
Merge On Read: Store data using parquet + avro.When the data is updated, the new data is written to a delta file and subsequently merged into a new version of the column storage file asynchronously or synchronously.
| Choice | CopyOnWrite | MergeOnRead |
|---|---|---|
| Data Delay | high | low |
| Update cost (I/O) Update operation overhead (I/O) | High (overrides the entire parquet) | Low (append to delta record) |
| Parquet file size | Small (high update (I/O) overhead) | Large (low update overhead) |
| Write frequency | high | Low (depending on merge strategy) |
2.4.2 Query Type
- Snapshot query: The query will see the latest table snapshots of subsequent commit and merge operations.For the merge on read table, the latest base and delta files are merged to see near real-time data (a few minutes delay).For copy on write tables, existing parquet tables are directly replaced by update/delete operations or other write operations.
- Incremental Query: Queries only see newly written data after a given submit/merge operation.This effectively provides a flow of change, enabling incremental data pipelines.
- Read Optimized Query: The query will see the latest snapshot of the table after a given commit/merge operation.Only the underlying/column storage files in the latest file slices are viewed, and query efficiency is guaranteed to be the same as non-hudi column storage tables.
| Choice | snapshot | Read optimization |
|---|---|---|
| Data Delay | low | high |
| Query Delay | High (merge base/column storage files + row storage delta/log files) | Low (original underlying/column storage file query performance) |
3. Spark structured stream writing to Hudi
The following is a sample code that integrates spark structured streaming with hudi. Since Hudi OutputFormat currently only supports calls in spark rdd objects, the forEachBatch operator of spark structured streaming is used for writing HDFS operations.See notes for details.
package pers.machi.sparkhudi import org.apache.log4j.Logger import org.apache.spark.sql.catalyst.encoders.RowEncoder import org.apache.spark.sql.{DataFrame, Row, SaveMode} import org.apache.spark.sql.functions._ import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType} object SparkHudi { val logger = Logger.getLogger(SparkHudi.getClass) def main(args: Array[String]): Unit = { val spark = SparkSession .builder .appName("SparkHudi") //.master("local[*]") .config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") .config("spark.default.parallelism", 9) .config("spark.sql.shuffle.partitions", 9) .enableHiveSupport() .getOrCreate() // Add listeners, complete each batch, print information about the batch, such as start offset, grab the number of records, and process time to the console spark.streams.addListener(new StreamingQueryListener() { override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = { println("Query started: " + queryStarted.id) } override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = { println("Query terminated: " + queryTerminated.id) } override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = { println("Query made progress: " + queryProgress.progress) } }) // Define kafka flow val dataStreamReader = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "testTopic") .option("startingOffsets", "latest") .option("maxOffsetsPerTrigger", 100000) .option("failOnDataLoss", false) // Loading stream data, because it is only for testing purposes, reading kafka messages directly without any other processing, is that spark structured streams automatically generate kafka metadata for each set of messages, such as the subject of the message, partition, offset, and so on. val df = dataStreamReader.load() .selectExpr( "topic as kafka_topic" "CAST(partition AS STRING) kafka_partition", "cast(timestamp as String) kafka_timestamp", "CAST(offset AS STRING) kafka_offset", "CAST(key AS STRING) kafka_key", "CAST(value AS STRING) kafka_value", "current_timestamp() current_time", ) .selectExpr( "kafka_topic" "concat(kafka_partition,'-',kafka_offset) kafka_partition_offset", "kafka_offset", "kafka_timestamp", "kafka_key", "kafka_value", "substr(current_time,1,10) partition_date") // Create and start query val query = df .writeStream .queryName("demo"). .foreachBatch { (batchDF: DataFrame, _: Long) => { batchDF.persist() println(LocalDateTime.now() + "start writing cow table") batchDF.write.format("org.apache.hudi") .option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE") .option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp") // Use kafka partition and offset as combined primary key .option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset") // Partition with current date .option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date") .option(TABLE_NAME, "copy_on_write_table") .option(HIVE_STYLE_PARTITIONING_OPT_KEY, true) .mode(SaveMode.Append) .save("/tmp/sparkHudi/COPY_ON_WRITE") println(LocalDateTime.now() + "start writing mor table") batchDF.write.format("org.apache.hudi") .option(TABLE_TYPE_OPT_KEY, "MERGE_ON_READ") .option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE") .option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp") .option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset") .option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date") .option(TABLE_NAME, "merge_on_read_table") .option(HIVE_STYLE_PARTITIONING_OPT_KEY, true) .mode(SaveMode.Append) .save("/tmp/sparkHudi/MERGE_ON_READ") println(LocalDateTime.now() + "finish") batchDF.unpersist() } } .option("checkpointLocation", "/tmp/sparkHudi/checkpoint/") .start() query.awaitTermination() } }
4. Test results
Limited by the test conditions, this test did not consider the update operation, but only the performance of hudi to append new data.
The data program runs for a total of 5 days, during which no errors occurred causing the program to exit.
kafka reads about 15 million data a day and consumes nine topic s.
A few points are described below
1 Is there data loss and duplication
Since the partition + offset for each record is unique, by checking for duplicate and discontinuous offsets in the same partition, you can determine that there is no loss of data and duplicate consumption.
2 Minimum number of supported single-day write data bars
Data writing efficiency is similar when no update operation exists for cow and mor tables.In this test, spark processed about 170 records per second.15 million records can be processed in a single day.
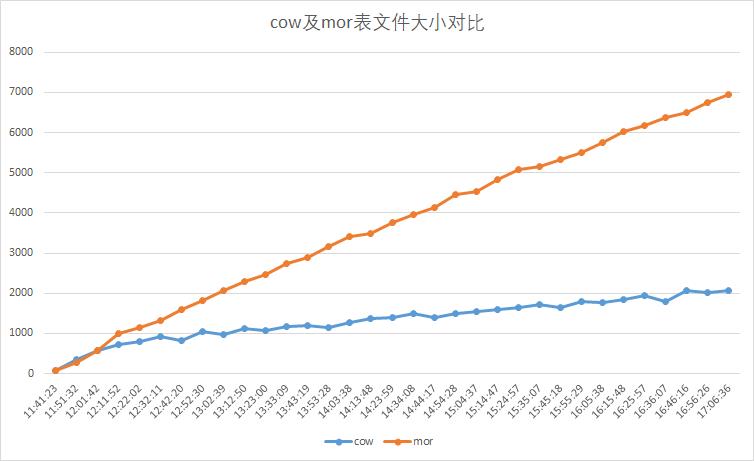
3 cow and mor table file size comparison
Read two tables every ten minutes in the same partition small file size, in M.As a result, the size of the mor table file increases considerably and it consumes a lot of disk resources.When no update operation exists, use the cow table whenever possible.