Advanced chapter of Lesson 8_ Indexes
I MySQL Linux Installation
1. Prepare Linux server
CentOS 7.0
Final shell connection server
2. Download MySQL installation package for Linux
www.mysql.com
Download Community Edition (free)
3. Upload MySQL installation package
4. Create a directory and unzip it
mkdir mysql tar -xvf mysql-8.0.rpm-bundle.tar -c mysql
5. Install mysql package

6. Start MySQL service
systemctl start mysqld systemctl restart mysqld systemctl stop mysqld
7. Query the generated root user password
grep 'temporary password' /var/log/mysqld.log cat /var/log/mysqld.log
8. Modify the root user password
① Log in to MySQl server
mysql -u root -p
② Set MySQL password level 0 and password length 4
set global validate-password.policy =0; set global validate_password.length =4;
③ Change password 1234
alter user 'root@localhost' identified by '1234';
9. Create users for remote access
create user 'root'@''%' identified with mysql_native_passwore by '1234';
10. Assign permissions to root user
grant all on *.* to 'root'@'%';
11. Reconnect MySQL
① Click Add server in DataGrid:
Data Source→MySQL
② Configure MySQL server information
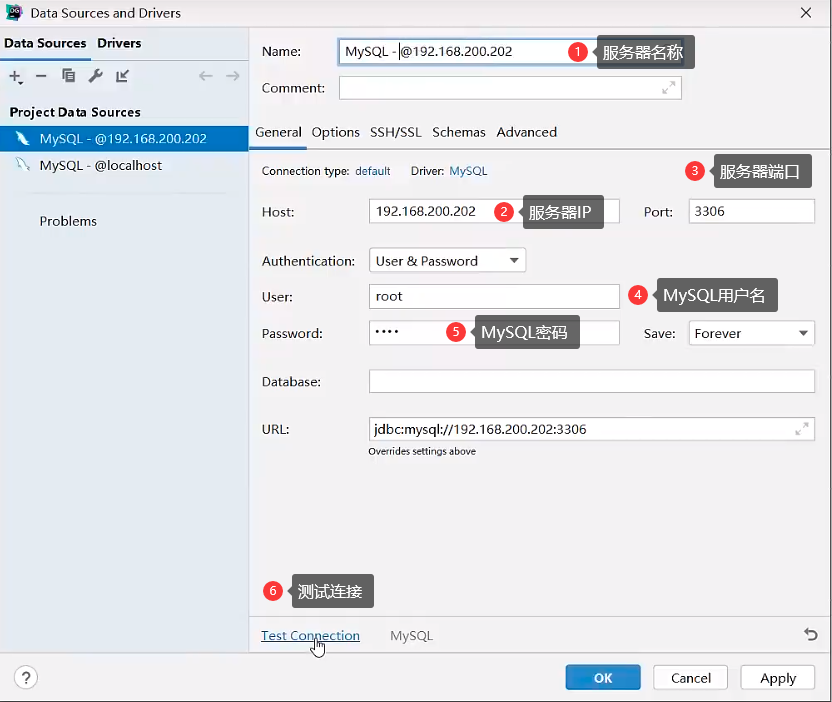
12. Connect MySQL remotely through DataGrid
If the connection fails, check the Linux firewall or MySQL port 3306
II Index overview
1. Concept
Index is an ordered data structure that helps MySQL get funny data In addition to data, the database system also maintains data structures that meet specific search algorithms. These data structures refer to (point to) data in some way to realize advanced search algorithms
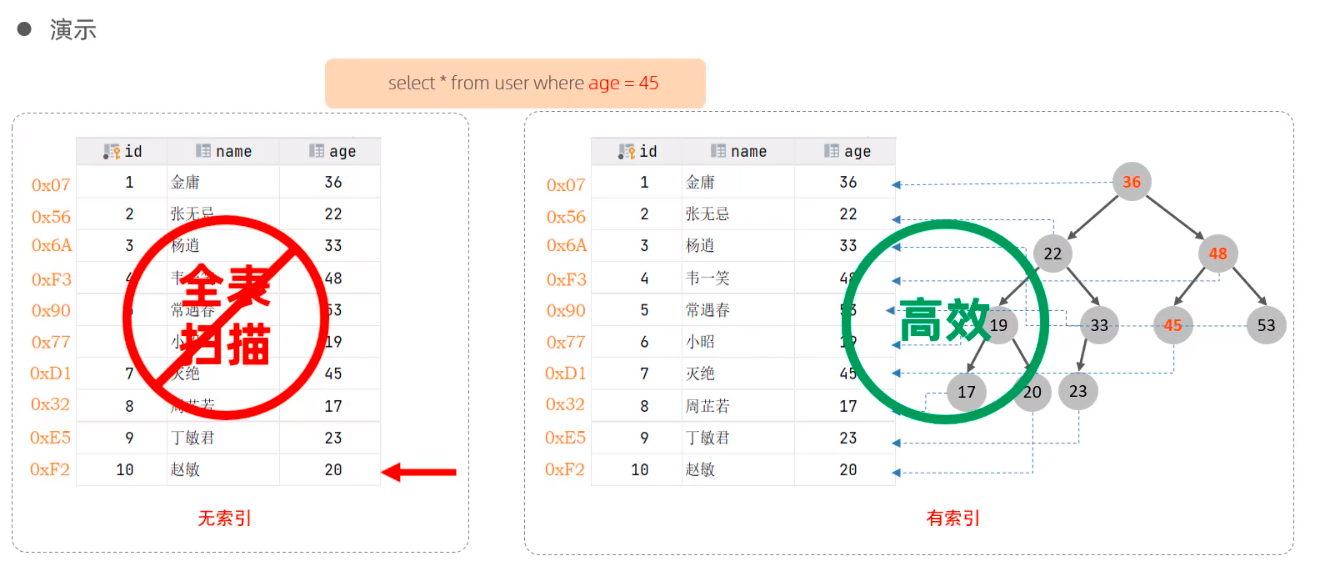
2. Advantages and disadvantages
| advantage | shortcoming |
|---|---|
| Improve the efficiency of data retrieval and reduce the IO cost of data | Index columns also take up space |
| Sort the data through the index to reduce the cost of data sorting and CPU consumption | The index greatly improves the query efficiency, but also reduces the speed of updating the table. If you insert, update and delete the table, the efficiency will be reduced |
III index structure
The index of MySQL is actually implemented in the engine layer. Different engine layers have different structures
1. Common structures
| index structure | describe |
|---|---|
| B+Tree index | Most data engines support common index types |
| Hash index | The underlying data organization is realized by hash table. Only the query that accurately matches the index column is effective, and the range query is not supported |
| R-tree (spatial index) | Spatial index is a special index type of MyISAM engine, which is mainly used for geospatial data types |
| Full text (full text index) | A way to quickly match documents by establishing inverted index Similar to Lucene,Solr,ES |
2. Engine support
| Indexes | InnoDB | MySAM | Memory |
|---|---|---|---|
| B+tree | support | support | support |
| Hash | I won't support it | I won't support it | support |
| R-tree | I won't support it | support | I won't support it |
| Full-text | Support after version 5.6 | support | I won't support it |
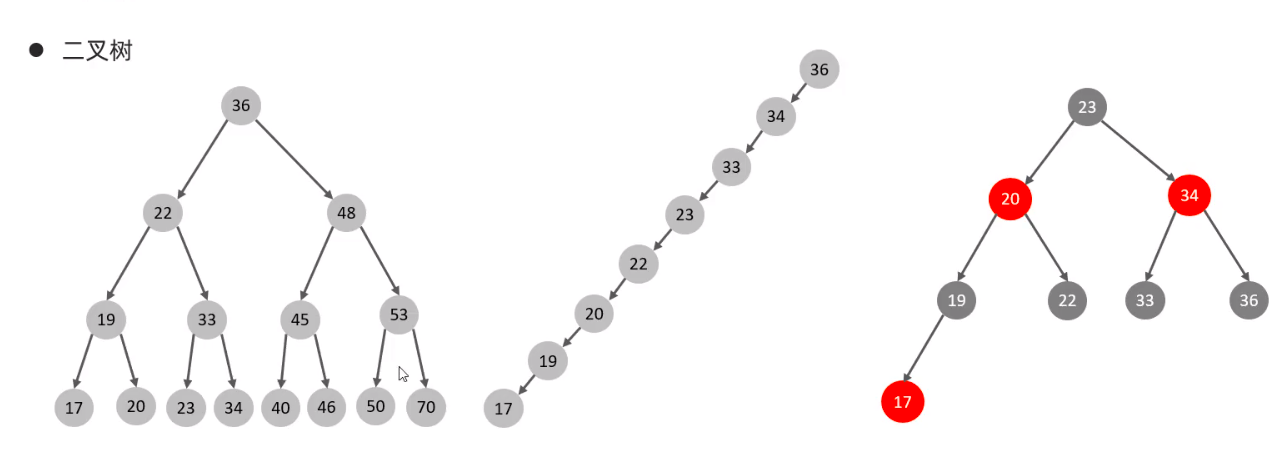
3. Binary tree
Disadvantages of binary tree: a linked list will be formed during sequential insertion, which greatly reduces the query performance In the case of large amount of data, the level is deep and the retrieval is slow
Red black tree: large amount of data, deep level and slow retrieval
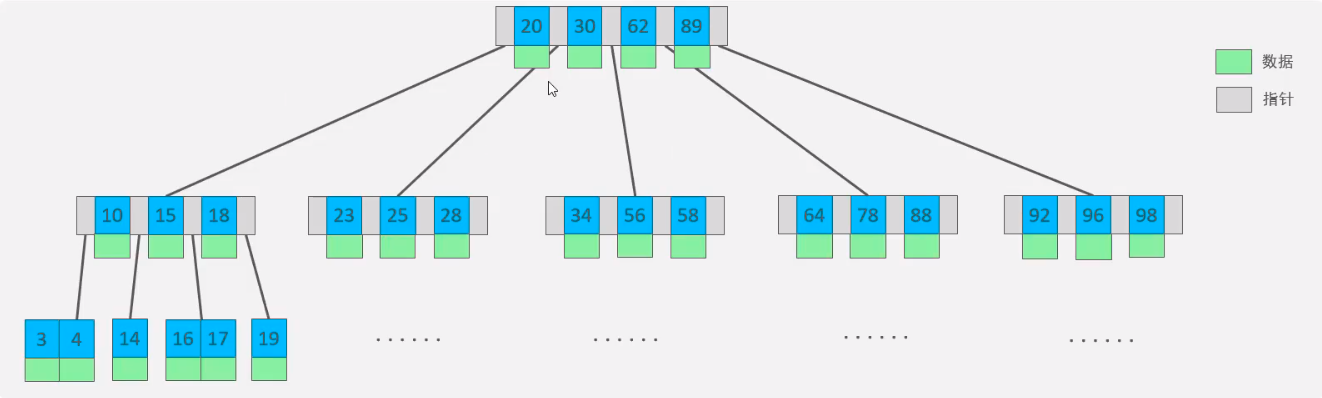
4. B-tree (multiple balanced lookup tree)
Take a B-tree with a maximum degree of 5 (order 5) as an example (each node can store up to 4 keys and 5 pointers)
Max degree: the number of child nodes of a node
Dynamic demonstration network: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
5.B+tree
Take a b+tree with a maximum degree of 4 (order 4) as an example:
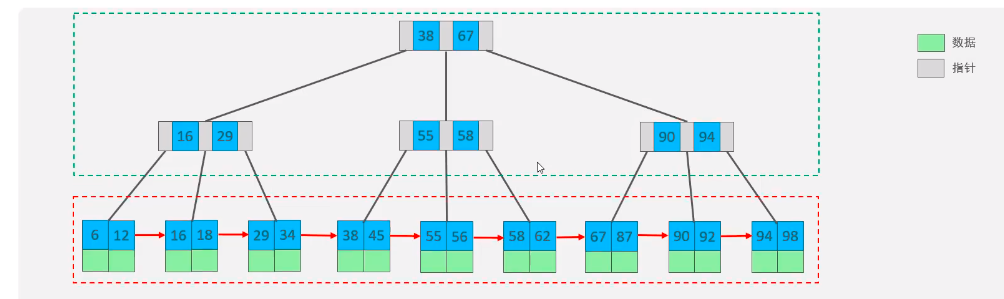
Difference from B-tree:
① All data will appear in the leaf node
② Leaf nodes form a one-way linked list
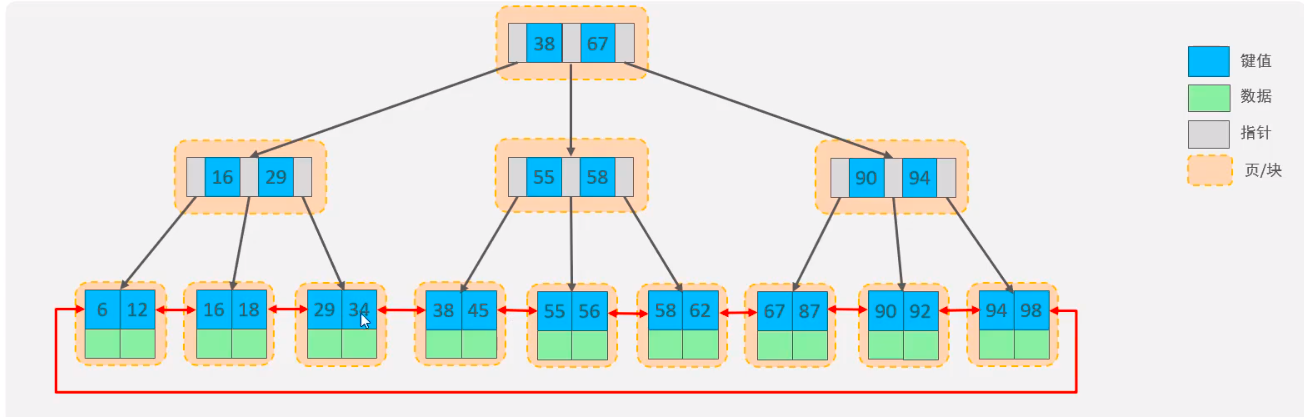
The MySQL index data structure optimizes the B+tree. On the basis of the original B+tree, a linked list pointer pointing to the nodes of adjacent leaves is added to form a B+tree with sequential pointer to improve the performance of interval access
6.Hash
Use a certain hash algorithm to convert the key value into hash value, map it to the corresponding slot, and then store it in the hash table summary
If two (or more 0 key values are mapped to the same slot, they will produce hash conflict (also known as hash collision 0), which can be solved through linked list
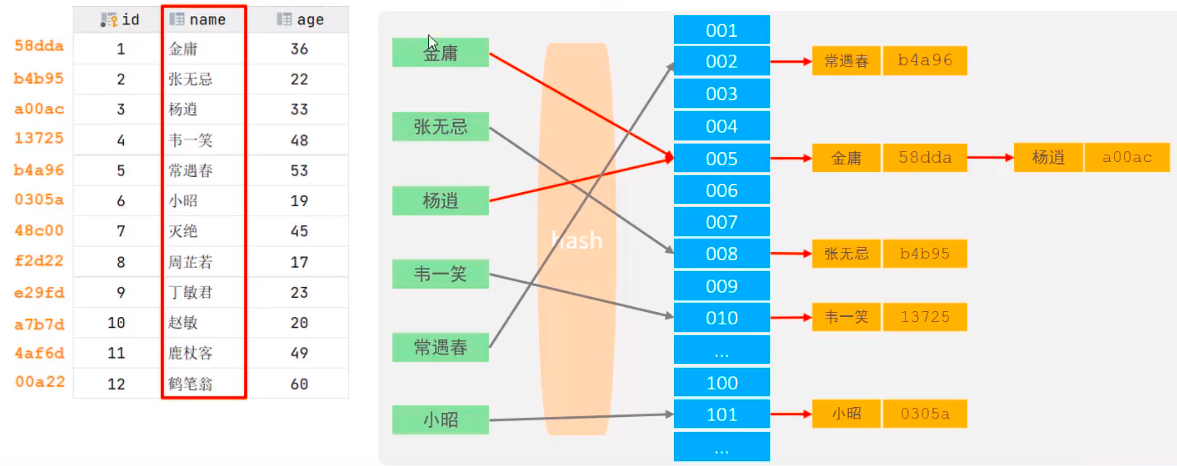
characteristic:
① It can only be used for peer-to-peer comparison (=, in), and does not support range query (between, >, <
② Unable to complete sort operation with index
③ The query efficiency is high. It usually only needs one search, and the efficiency is usually higher than that of B+tree index
Engine support:
In MySQL, the Memory engine supports hash index, while InnoDb has adaptive hash function. The hash index is automatically built by the storage engine according to the B+tree index under specified conditions
IV Index classification
1. Classification 1
| classification | meaning | characteristic | keyword |
|---|---|---|---|
| primary key | An index created for a primary key in a table | By default, there can only be one automatic creation | PRIMARY |
| unique index | Avoid duplicate values in a data column in the same table | There can be more than one | UNIQUE |
| General index | Quickly locate specific data | There can be more than one | |
| Full text index | Instead of comparing the values in the index, you are looking for keywords in the text | There can be more than one | FULLTEXT |
2. Classification 2
In the InnoDB storage engine, according to the storage form of the index, it can be divided into:
| classification | meaning | characteristic |
|---|---|---|
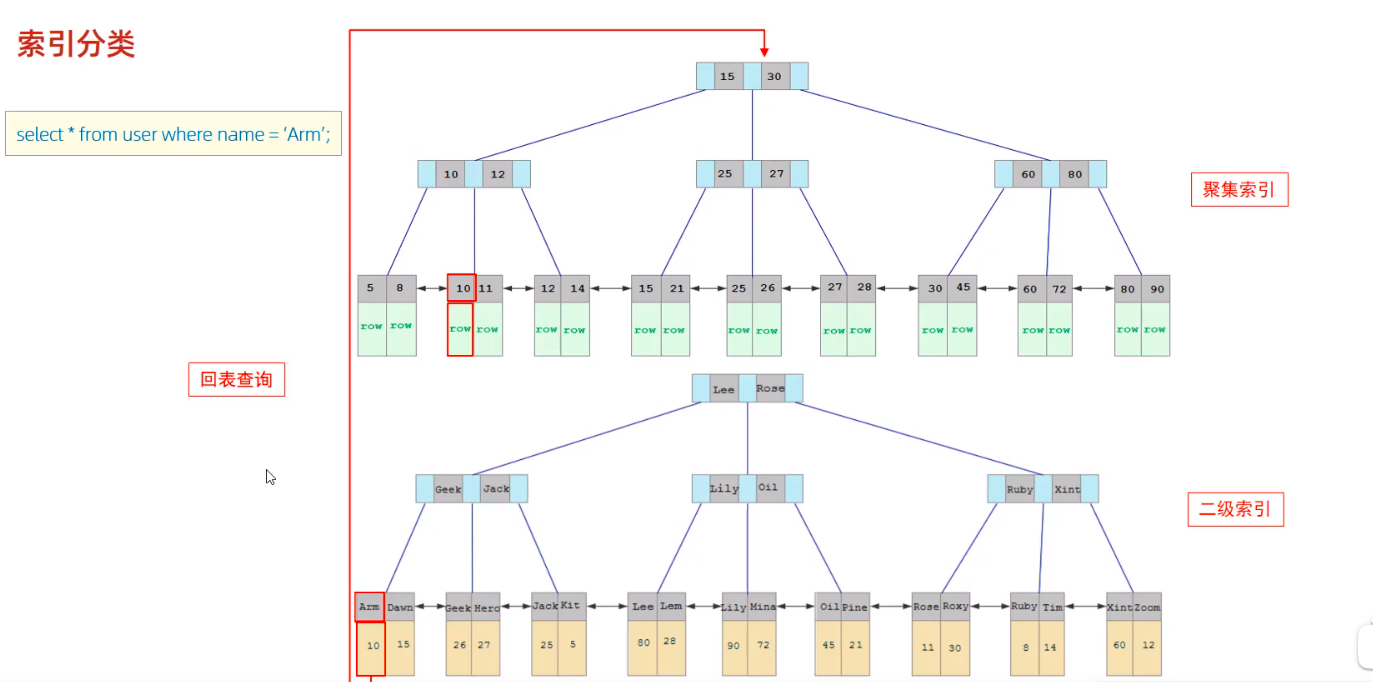
| Clustered index | Put the data storage and index together, and the leaf node of the index structure saves the row data | There must be and only one |
| Secondary index | The data is stored separately from the index. The leaf node of the index structure is associated with the corresponding primary key | Can have more than one |
Clustered index selection rule:
① A clustered index is a primary key if one exists
② If there is no primary key, the first unique index is used as the clustered index
③ If the table does not have a primary key or an appropriate unique index, InnoDB will automatically generate a rowid as a hidden clustered index
3. Return table query
First find the corresponding primary key value from the secondary index, and then find the corresponding row data in the clustered index
4. How high is the B+tree height of InnoDB primary key index?
Suppose: one row of data is 1k, and 16 rows of such data can be stored in one page The pointer of InnoDB occupies 6 bytes. Even if the primary key is bigint, the number of bytes occupied is 8
InnoDB's default page / block size is 16K Each node is stored in a page / block
Height 2:
//Set n as the number of key s stored in the current node and the number of pointers in the current node as n+1 n*8+(n+1)*6=16k*1024bytes //n is about 1170 1171*16=18736
Height 3:
1171*1171*16=21939856
V Index syntax
1. Create index
CREATE [UNIQUE][FULLTEXT] INDEX index_name ON table_name(index_col_name,...);
2. View index
SHOW INDEX FROM table_name;
3. Delete index
DROP INDEX index_name ON table_name;
4. Cases
① Index on demand
a. The name field is a name field. The value of this field may be repeated. Create an index for this field
b. If the value of the phone number field is non empty and unique, a unique index will be created for this field
c. Create a federated index for professional, age, and status
d. Create an appropriate index for email to improve query efficiency
② Data preparation
-- Index syntax
-- 1.Create table
create table tb_user(
id int auto_increment primary key comment 'Primary key ID',
name varchar(10) comment 'full name',
phone varchar(11) unique comment 'Telephone',
email varchar(20) comment 'mail',
profession varchar(10) comment 'major',
age int comment 'Age',
gender varchar(1) comment 'Gender',
status int comment 'state',
createtime datetime comment 'Creation time'
)comment 'User table';
-- 2.insert data
insert into tb_user(id,name,phone,email,profession,age,gender,status,createtime) values
(1,'Lv Bu','17799990000','lvbu666@163.com','software engineering',23,'1',6,'2001-02-12 00:00:00'),
(2,'Cao Cao','17799990001','kcaocao66@qq.com','Communication Engineering',33,'1',0,'2001-03-05 00:00:00'),
(3,'Zhao Yun','17799990002','1799993@139.com','English',34,'1',2,'2002-03-18 00:00:00'),
(4,'Sun WuKong','17799990003','wukongyou@sina.com','engineering cost',23,'1',0,'2004-02-17 00:00:00'),
(5,'Magnolia','17799990004','mulan6@163.com','software engineering',22,'2',1,'2009-010-10 00:00:00'),
(6,'Big Joe','17799990005','daqiao222@163.com','dance',24,'2',0,'2004-09-29 00:00:00'),
(7,'Luna','17799990006','luna_love6@sina.com','applied mathematics',38,'2',0,'2002-03-09 00:00:00'),
(8,'Cheng Yaojin','17799990007','chengyaojin@163.com','chemical industry',43,'1',5,'2009-02-22 00:00:00'),
(9,'Xiang Yu','17799990008','xiangyu66@qq.com','Metallic materials',27,'1',0,'2003-05-08 00:00:00'),
(10,'Bai Qi','17799990009','baiqi12@sina.com','Mechanical engineering and automation',27,'1',2,'2001-05-18 00:00:00'),
(11,'Han Xin','17799990010','hanxin520@163.com','Inorganic nonmetallic material engineering',29,'1',0,'2004-09-10 00:00:00'),
(12,'Jing Ke','17799990011','jingke123@163.com','accounting',44,'1',0,'2001-04-01 00:00:00'),
(13,'King Lanling','17799990012','lanlingwang@126.com','engineering cost',43,'1',1,'2007-12-26 00:00:00'),
(14,'Crazy iron','17799990013','kuangite6@163.com','applied mathematics',43,'1',2,'2005-11-13 00:00:00'),
(15,'army officer's hat ornaments','17799990014','diaochan66@sina.com','software engineering',40,'2',3,'2010-01-30 00:00:00'),
(16,'Daji','17799990015','daji998@163.com','city planning',46,'2',0,'2002-10-02 00:00:00'),
(17,'Mi Yue','17799990016','xiaomi2002@sina.com','software engineering',40,'2',0,'2001-01-30 00:00:00'),
(18,'Ying Zheng','17799990017','8899022@qq.com','software engineering',40,'1',1,'2001-01-30 00:00:00'),
(19,'Di Renjie','17799990018','direnjie1@sina.com','software engineering',40,'1',0,'2001-10-30 00:00:00'),
(20,'Angela','17799990019','anqila33@126.com','software engineering',40,'2',0,'2004-01-30 00:00:00'),
(21,'Dianwei','17799990020','diaochan66@sina.com','software engineering',40,'1',2,'2001-01-30 00:00:00'),
(22,'Lian Po','17799990021','lianpo777@163.com','Civil siege',35,'1',3,'2007-11-02 00:00:00'),
(23,'Hou Yi','17799990022','houyi555@163.com','Urban gardens',18,'1',0,'2006-02-15 00:00:00'),
(24,'Jiang Ziya','17799990023','jiangziya@qq.com','engineering cost',29,'1',4,'2004-02-26 00:00:00');
③ View create index
a. View tb_user's index
show index from tb_user; show index from tb_user\G;
b. Create tb_user's index
-- a. name The field is the name field,This field may have duplicate values,Create an index for this field. create index idx_user_name on tb_user(name); -- b. phone Value of mobile number field,Yes no empty,And unique,Create a unique index for this field. create unique index idx_user_phone on tb_user(phone); -- c. by profession,age,status Create federated index. create index idx_user_pro_age_sta on tb_user(profession,age,status); -- d. by email Create an appropriate index to improve query efficiency. create index idx_user_email on tb_user(email); -- e.delete email Indexes create index idx_user_email on tb_user(email); -- f.display tb_user Index of drop index idx_user_email on tb_user; -- g.Display results: +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | tb_user | 0 | PRIMARY | 1 | id | A | 24 | NULL | NULL | | BTREE | | | | tb_user | 0 | idx_user_phone | 1 | phone | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_name | 1 | name | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_pro_age_sta | 1 | profession | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_pro_age_sta | 2 | age | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_pro_age_sta | 3 | status | A | 24 | NULL | NULL | YES | BTREE | | | +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 6 rows in set (0.01 sec)
Vi SQL Performance Analyzer
1.SQL execution frequency
After the MySQL client is successfully connected, the server status information can be provided through the show[session|global]status command, and the access frequency of insert, update, delete and select of the current database can be viewed:
-- View server execution frequency information SHOW GLOBAL STATUS LIKE 'Com_______';
2. Slow query log
The default execution time of all SQL statements is longer than. U seconds. The default unit of all SQL statements is. U # MySQL's slow query log is not enabled by default, so you need to configure information in MySQL's configuration file (etc/my.cnf)
-- Check whether the slow query log is enabled show variables like 'slow_query_log';
① finalshell double window, edit / etc / my CNF file
vi /etc/my.cnf
② Press the i key in the vi editor to enter the insert mode
③ In my Add at the end of CNF file
#Turn on MySQL slow query log switch slow_query_log=1 #Set the time of slow query log to 2 seconds. If the execution time of SQL statement exceeds 2 seconds, it will be regarded as slow query and recorded in the log long_query_time=2
④ Press ESC to exit the insert mode and enter: wq! Save changes (without saving: q!), Enter cat my CNF view the modification results
⑤ After the configuration is completed, restart the MySQL server through the command to test and check the information in the slow query log / var / lib / MySQL / localhost slow log
systemctl restart mysqld
⑥ Go to the MySQL window again to check whether the slow log is enabled
show variables like 'slow_query_log';
⑦ Linux window view and dynamic view MySQL slow Log tail file change
# View MySQL slow Log file cat mysql-log # Dynamically view MySQL slow log tail -f mysql-slow.log
⑧ The MySQL window opens 10 million rows of database tb_sku to query and observe MySQL slow in the linux window Log file changes
select count(*) from tb_sku;
3.profile details
show profiles can help us understand where time is spent when doing SQL optimization
① Through have_ The profiling parameter checks whether the profile operation is supported
-- View system variables have_profiling,confirm MySQL Support show profiles SELECT @@have_profiling;
② By default, profiling is turned off and enabled at the session/global level through the set statement
-- see profiling Is the switch on,0 close,1 open. select @@profiling; -- open profiling SET PROFILING = 1;
③ Time consuming for viewing instructions after executing SQL operations
-- View each SQL Basic information of show profiles; -- View assignments query_id of SQL Time consumption of each stage of the statement show profile for query query_id; -- View assignments query_id of SQL sentence CPU Usage of show profile cpu for query query_id;
④ Case
a. Create tens of millions of data tables
-- Ten million level test data
-- 1.establish MYISAM
CREATE TABLE tb_sku(
id serial,
uname varchar(20) ,
sn varchar(20),
ucreatetime datetime ,
age int(11))
ENGINE=MYISAM
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
AUTO_INCREMENT=1
ROW_FORMAT=COMPACT;
-- 2.Create insert data stored procedure
delimiter $$
SET AUTOCOMMIT = 0$$
create procedure test1()
begin
declare v_cnt decimal (10) default 0 ;
dd:loop
insert into tb_sku values
(null,'User 1','1000201001','2010-01-01 00:00:00',20),
(null,'User 2','1000201002','2010-01-01 00:00:00',20),
(null,'User 3','1000201003','2010-01-01 00:00:00',20),
(null,'User 4','1000201004','2010-01-01 00:00:00',20),
(null,'User 5','1000201005','2011-01-01 00:00:00',20),
(null,'User 6','1000201006','2011-01-01 00:00:00',20),
(null,'User 7','1000201007','2011-01-01 00:00:00',20),
(null,'User 8','1000201008','2012-01-01 00:00:00',20),
(null,'User 9','1000201009','2012-01-01 00:00:00',20),
(null,'User 0','1000201010','2012-01-01 00:00:00',20)
;
commit;
set v_cnt = v_cnt+10 ;
if v_cnt = 10000000 then leave dd;
end if;
end loop dd ;
end;$$
delimiter ;
-- 3. Execute stored procedure(Alibaba cloud Query OK, 0 rows affected (1 min 18.99 sec))
call test1;
-- 4. Modify as needed engineer (Non essential steps (no operation if conversion is not required)
alter table tb_sku engine=innodb;
-- 5. Modify some test data values
update tb_sku set sn='9008007001' where id=13426;
b. Analysis
-- SQL performance analysis _profile -- 1.Different execution SQL Query statement select * from tb_user; select * from tb_user where id=1; select * from tb_user where name='Bai Qi'; select count(*) from tb_sku; -- 2.see profiles show profiles; -- 3.Display results +----------+------------+-------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------+ | 1 | 0.00009800 | select @@profiling | | 2 | 0.00004200 | select * from tb_user | | 3 | 0.00003975 | select * from tb_user where id=1 | | 4 | 0.00002150 | select * from tb_user where name='Bai Qi' | | 5 | 0.00003950 | select count(*) from tb_user | +----------+------------+-------------------------------------------+ -- 4.View the fifth statement show profile for query 5; -- 5.Display results +--------------------------------+----------+ | Status | Duration | +--------------------------------+----------+ | starting | 0.000006 | | Waiting for query cache lock | 0.000003 | | checking query cache for query | 0.000004 | | checking privileges on cached | 0.000002 | | checking permissions | 0.000003 | | sending cached result to clien | 0.000014 | | logging slow query | 0.000002 | | cleaning up | 0.000002 | +--------------------------------+----------+ -- 6.View the fifth statement cpu Usage mysql> show profile cpu for query 5; +--------------------------------+----------+----------+------------+ | Status | Duration | CPU_user | CPU_system | +--------------------------------+----------+----------+------------+ | starting | 0.000006 | 0.000004 | 0.000002 | | Waiting for query cache lock | 0.000003 | 0.000001 | 0.000001 | | checking query cache for query | 0.000004 | 0.000002 | 0.000001 | | checking privileges on cached | 0.000002 | 0.000002 | 0.000001 | | checking permissions | 0.000003 | 0.000002 | 0.000001 | | sending cached result to clien | 0.000014 | 0.000008 | 0.000005 | | logging slow query | 0.000002 | 0.000002 | 0.000001 | | cleaning up | 0.000002 | 0.000001 | 0.000001 | +--------------------------------+----------+----------+------------+ 8 rows in set (0.00 sec)
4.explain execution plan
The EXPLAIN or DESC command obtains information about how MySQL executes the SELECT statement, including how tables are connected and the order of connection during the execution of the SELECT statement
① Syntax: which keyword is explain or desc directly before the select statement
EXPLAIN SECECT field list FROM table name WHERE condition;
② EXPLAIN the meaning of each field in the execution plan
id: the serial number of the select query, indicating the order in which the select clause or operation table is executed in the query (the same id, the execution order from top to bottom; different IDS, the larger the value, the first execution)
select_type: indicates the type of select. Common ones include simple (simple table, i.e. not applicable to table join or subquery), primary (primary query, i.e. external query), Union (the second or subsequent query statement in Union), subquery (subquery included after select / where), etc
Type: the connection type of the table. The performance from good to bad is: NULL,system,const,eq_ref,ref,range,index,all.
a. access the table according to the primary key or unique index. The connection type is const
b. access the table according to the non unique index, and the connection type is ref
c. the performance of full meter scanning is the worst
possible_key: one or more possible indexes in the table
key: the index actually used. NULL is the index not used
key_len: the number of bytes used by the index in the table. This value is the maximum possible length of the index field, not the actual length. The shorter the better without losing accuracy
Rows: the InnoDB engine estimates the number of rows to be queried by MySQL
filtered: indicates the percentage of the number of rows of the returned result in the number of rows to be read. The larger the value, the better
Extra: information not displayed in the above fields will be displayed in the extra field
③ Case
-- SQL performance analysis -- explain Implementation plan -- Correlation table:student,course,student_course(Lesson 5 Fundamentals_multi-table query→one.Multi table relation→22.Many to many→①case) -- 1.Execute multi table query mysql> select s.*,c.* from student s,course c,student_course sc where s.id=sc.studentid and c.id = sc.courseid; +----+--------------+------------+----+-------+ | id | name | no | id | name | +----+--------------+------------+----+-------+ | 1 | Delireba | 2000100101 | 1 | Java | | 1 | Delireba | 2000100101 | 2 | MySQL | | 2 | Li Qin | 2000100102 | 2 | MySQL | | 1 | Delireba | 2000100101 | 3 | Cocos | | 2 | Li Qin | 2000100102 | 3 | Cocos | | 3 | Korea Europa | 2000100103 | 4 | Html | +----+--------------+------------+----+-------+ 6 rows in set (0.01 sec) -- 2.see id Same execution plan mysql> explain select s.*,c.* from student s,course c,student_course sc where s.id=sc.studentid and c.id = sc.courseid; +----+-------------+-------+------+--------------------------+--------------+---------+-------------+------+--------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+--------------------------+--------------+---------+-------------+------+--------------------------------+ | 1 | SIMPLE | s | ALL | PRIMARY | NULL | NULL | NULL | 4 | | | 1 | SIMPLE | sc | ref | fk_courseid,fk_studentid | fk_studentid | 4 | test01.s.id | 1 | | | 1 | SIMPLE | c | ALL | PRIMARY | NULL | NULL | NULL | 4 | Using where; Using join buffer | +----+-------------+-------+------+--------------------------+--------------+---------+-------------+------+--------------------------------+ 3 rows in set (0.00 sec) -- 3.Query elective MySQL Students mysql> select * from student s where s.id in (select studentid from student_course sc where sc.courseid = (select id from course c where c.name='MySQL')); +----+--------------+------------+ | id | name | no | +----+--------------+------------+ | 1 | Delireba | 2000100101 | | 2 | Li Qin | 2000100102 | +----+--------------+------------+ -- query id Different execution plans mysql> explain select * from student s where s.id in (select studentid from student_course sc where sc.courseid = (select id from course c where c.name='MySQL')); +----+--------------------+-------+----------------+--------------------------+--------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+--------------------+-------+----------------+--------------------------+--------------+---------+------+------+-------------+ | 1 | PRIMARY | s | ALL | NULL | NULL | NULL | NULL | 4 | Using where | | 2 | DEPENDENT SUBQUERY | sc | index_subquery | fk_courseid,fk_studentid | fk_studentid | 4 | func | 1 | Using where | | 3 | SUBQUERY | c | ALL | NULL | NULL | NULL | NULL | 4 | Using where | +----+--------------------+-------+----------------+--------------------------+--------------+---------+------+------+-------------+ 3 rows in set (0.00 sec)
VII Index usage
1. Verify index efficiency
-- Query before indexing mysql> select * from tb_sku where sn='9008007001'; +--------+---------+------------+---------------------+------+ | id | uname | sn | ucreatetime | age | +--------+---------+------------+---------------------+------+ | 500000 | User 0 | 9008007001 | 2012-01-01 00:00:00 | 20 | +--------+---------+------------+---------------------+------+ 1 row in set (2.12 sec) -- Query time 2.12 second -- with sn Create index for field mysql> create index idx_sku_sn on tb_sku(sn); Query OK, 0 rows affected (51.30 sec) -- When creating a cable reference 51.3 second Records: 0 Duplicates: 0 Warnings: 0 -- Query after index creation mysql> select * from tb_sku where sn='9008007001'; +--------+---------+------------+---------------------+------+ | id | uname | sn | ucreatetime | age | +--------+---------+------------+---------------------+------+ | 500000 | User 0 | 9008007001 | 2012-01-01 00:00:00 | 20 | +--------+---------+------------+---------------------+------+ 1 row in set (0.00 sec) -- The query took less than 0 after index creation.01 second -- View the execution plan and find that the idx_sku_sn Indexes mysql> explain select * from tb_sku where sn='90080070091'; +----+-------------+--------+------+---------------+------------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------------+---------+-------+------+-------------+ | 1 | SIMPLE | tb_sku | ref | idx_sku_sn | idx_sku_sn | 63 | const | 1 | Using where | +----+-------------+--------+------+---------------+------------+---------+-------+------+-------------+ 1 row in set (0.00 sec)
2. Leftmost prefix rule
When querying, if multiple columns (joint index) are indexed, the leftmost prefix rule should be observed The query starts from the leftmost column of the index and does not skip the column of the index summary If a column is skipped, the index will be partially invalidated (the subsequent field index fails)
3. Range query
In the joint index, if the range query (>, <) is violated, the column index on the right side of the range query becomes invalid. You can change the range query to (> =, < =) to avoid index invalidation
4. Index column operation
The index is invalid when the operation is performed on the index column
-- 1.Index segment not calculated,Can go idx_user_phone Indexes. mysql> explain select * from tb_user where phone = '17799990015'; +----+-------------+---------+-------+-----------------+-----------------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+-------+-----------------+-----------------+---------+-------+------+-------+ | 1 | SIMPLE | tb_user | const | idx_user_phone | idx_user_phone | 47 | const | 1 | | +----+-------------+---------+-------+-----------------+-----------------+---------+-------+------+-------+ -- 2.Index segment for calculation,Not used idx_user_phone Indexes,Can use all Full table scan mysql> explain select * from tb_user where substring(phone,10,2) = '15'; +----+-------------+---------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | tb_user | ALL | NULL | NULL | NULL | NULL | 24 | Using where | +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
5. String without quotation marks
The string type field is used without quotation marks, and the index is invalid
6. Fuzzy query
Tail fuzzy matching, index not invalid, head fuzzy matching, index invalid
7. Connection conditions
If the field before or has an index and the field after or has no index, the indexes involved will not be used
8. Data distribution impact
If MySQL evaluation uses indexes slower than the whole table, indexes will not be used
9.SQL prompt
Add some hints in SQL statement to achieve the purpose of Lake operation
-- 1.Prompt system usage idx_user_pro Indexes explain select * from tb_user use index(idx_user_pro) where profession='software engineering'; -- 2.Prompt the system not to use idx_user_pro Indexes explain select * from tb_user use index(idx_user_pro) where profession='software engineering'; -- 3.Prompt system must use idx_user_pro Indexes explain select * from tb_user use index(idx_user_pro) where profession='software engineering';
10. Overlay index
Try to use the overlay index (the query uses the index, and all the returned columns can be found in the index), and reduce the SELECT *
When the content of the EXTRA field of the execution plan is:
using index condition: the query uses an index, but the data needs to be queried back to the table Low efficiency
using where;using index: the query uses an index, but the required data can be found in the index, so there is no need to query back to the table efficient.
11. Prefix index
When the field type is string (varchar,text, etc.), sometimes a very long string needs to be indexed, which will make the index very large, waste a lot of disk IO during query, and affect the query efficiency At this time, only a part of the prefix of the string can be indexed to save index space and improve efficiency
Syntax:
create index idx_xxx on table_name(column(n));
Prefix Length
It can be determined according to the selectivity of the index, and selectivity refers to the ratio of the non repeated index value (cardinality) to the total number of records in the data table. The higher the index selectivity, the selectivity of the unique index is 1, which is the best index selectivity and the best
-- Prefix index -- by tb_user surface email Prefix index for field -- 1.obtain tb_user Total data for table(24) mysql> select count(*) from tb_user; +----------+ | count(*) | +----------+ | 24 | +----------+ -- 2.use distinct Keyword search email The field does not duplicate the number of value records(24) mysql> select count(distinct email) from tb_user; +-----------------------+ | count(distinct email) | +-----------------------+ | 24 | +-----------------------+ -- 3.seek email The selectivity of the field is 1,(1 Best performance,0 Lowest performance) mysql> select count(distinct email)/count(*) from tb_user; +--------------------------------+ | count(distinct email)/count(*) | +--------------------------------+ | 1.0000 | +--------------------------------+ -- 4.Seek interception email The index selectivity of the first 10 bits of the field is 1 mysql> select count(distinct substring(email,1,10))/count(*) from tb_user; +------------------------------------------------+ | count(distinct substring(email,1,10))/count(*) | +------------------------------------------------+ | 1.0000 | +------------------------------------------------+ -- 5 Seek interception email The selectivity for indexing the first four bits of the field is also 1 mysql> select count(distinct substring(email,1,4))/count(*) from tb_user; +-----------------------------------------------+ | count(distinct substring(email,1,4))/count(*) | +-----------------------------------------------+ | 1.0000 | +-----------------------------------------------+ -- 6.Seek interception email The selectivity for indexing the first 3 bits of the field is 0.9583 mysql> select count(distinct substring(email,1,3))/count(*) from tb_user; +-----------------------------------------------+ | count(distinct substring(email,1,3))/count(*) | +-----------------------------------------------+ | 0.9583 | +-----------------------------------------------+ -- 7.Seek interception email The selectivity for indexing the first 2 bits of the field is 0.9167 mysql> select count(distinct substring(email,1,2))/count(*) from tb_user; +-----------------------------------------------+ | count(distinct substring(email,1,2))/count(*) | +-----------------------------------------------+ | 0.9167 | +-----------------------------------------------+ -- 8.intercept email The first 4 digits of the field are established idx_email_4 Indexes. mysql> create index idx_email_4 on tb_user(email(4)); -- 9.View index information,Sub_part Is the intercepted part,idx_email_4 The value of the index is 4. mysql> show index from tb_user; +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | tb_user | 0 | PRIMARY | 1 | id | A | 24 | NULL | NULL | | BTREE | | | | tb_user | 0 | idx_user_phone | 1 | phone | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_name | 1 | name | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_pro_age_sta | 1 | profession | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_pro_age_sta | 2 | age | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_user_pro_age_sta | 3 | status | A | 24 | NULL | NULL | YES | BTREE | | | | tb_user | 1 | idx_email_4 | 1 | email | A | 24 | 4 | NULL | YES | BTREE | | | +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ -- 10.see email='diaochan66@sina.com'Data,Already used idx_email_4 Index of. mysql> explain select * from tb_user where email='diaochan66@sina.com'; +----+-------------+---------+------+---------------+-------------+---------+-------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+-------------+---------+-------+------+-------------+ | 1 | SIMPLE | tb_user | ref | idx_email_4 | idx_email_4 | 19 | const | 1 | Using where | +----+-------------+---------+------+---------------+-------------+---------+-------+------+-------------+
12. Single column index and joint index
Single column index: an index contains only a single column
Federated index: an index contains multiple columns
Note: try to use joint index to improve query efficiency
VIII Index design principles
1. Build indexes for tables with large amount of data and frequent queries (if the data volume exceeds 1 million, it is recommended to establish an index)
2. Index fields that are often used as query criteria (where), order by, and group by
3. Try to select the column with high de fit as the index, and try to establish a unique index to improve the index efficiency
4. If the field is of string type and the length of the field is long, a prefix index can be established according to the characteristics of the field
5. Try to use the joint index and less single column index. When querying, the joint index can cover the index many times, save storage space, avoid returning to the table and improve query efficiency
6. The number of indexes should be controlled. The more indexes, the greater the cost of maintaining the index structure, which will affect the efficiency of addition, deletion and modification
7. If the index column cannot store null value, use the NOT NULL constraint when creating the table When the optimizer knows whether each column contains null value, it can better determine which index is most effective for query