Storage engine
1. Overview
MySQL's storage engine is plug-in. Users can choose the best storage engine according to the actual application scenario. MySQL supports multiple storage engines by default to meet different application requirements.
MySQL 5.7 supports storage engines such as InnoDB, MyISAM, MEMORY, CSV, MERGE, FEDERATED, etc. Since version 5.5.5, InnoDB has become the default storage engine of MySQL and the most commonly used storage engine at present. Before version 5.5.5, the default engine was MyISAM. When creating a new table, if you do not specify a storage engine, MySQL will use the default storage engine.
View the current default engine of the database:
mysql> show variables like 'default_storage_engine'; +------------------------+--------+ | Variable_name | Value | +------------------------+--------+ | default_storage_engine | InnoDB | +------------------------+--------+ 1 row in set (0.00 sec)
To view the storage engines currently supported by the database:
mysql> show engines\G
*************************** 1. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 2. row ***************************
Engine: CSV
Support: YES
Comment: CSV storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 3. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 4. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
*************************** 6. row ***************************
Engine: PERFORMANCE_SCHEMA
Support: YES
Comment: Performance Schema
Transactions: NO
XA: NO
Savepoints: NO
*************************** 7. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 8. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 9. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
9 rows in set (0.00 sec)
The meaning of each line is roughly as follows:
- Engine: storage engine name;
- Support: different values mean:
·DEFAULT: indicates that it is supported and enabled. It is the DEFAULT engine;
·YES: indicates that it is supported and enabled;
·NO: not supported;
·DISABLED: indicates support, but is DISABLED by the database. - Comment: store engine comments;
- Transactions: whether transactions are supported;
- Xa: whether XA distributed transaction is supported;
- Savepoints: whether savepoints are supported.
When creating a table, the ENGINE keyword sets the storage ENGINE of the table
mysql> create table a (id int) ENGINE = InnoDB; Query OK, 0 rows affected (0.01 sec) mysql> create table b (id int) ENGINE = MyISAM; Query OK, 0 rows affected (0.01 sec) ## The storage engine of table a is InnoDB, and the storage engine of table b is MyISAM.
View information about the table
Use the show table status command to view information about a table.
mysql> show table status like 'a'\G
*************************** 1. row ***************************
Name: a
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 1
Avg_row_length: 16384
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2020-04-21 02:29:06
Update_time: 2020-04-29 00:24:17
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
The meaning of each line is roughly as follows:
- Name: table name;
- Engine: storage engine type of the table;
- Version: version number;
- Row_format: the format of the line;
- Rows: number of rows in the table;
- Avg_row_length: average number of bytes per line;
- Data_length: the size of the table data (in bytes);
- Max_data_length: maximum capacity of table data;
- Index_length: the size of the index (in bytes);
- Data_free: space allocated but not used at present, which can be understood as fragment space (unit byte);
- Auto_increment: next Auto_increment value;
- Create_time: the creation time of the table;
- Update_time: the last modification time of table data;
- Check_time: using the check table command, the time of the last check table;
- Collation: the default character set and character column collation of the table;
- Checksum: if enabled, the real-time checksum of the whole table is saved;
- Create_options: other options specified when creating the table;
- Comment: some additional information about the table.
2. Comparison of common storage engines

3. InnoDB storage engine
Starting from version 5.5, InnoDB is the default transactional engine of MySQL and the most important and widely used storage engine. InnoDB has transaction security guarantee of commit, rollback and automatic crash recovery, independent cache and log, and provides row level lock granularity and strong concurrency.
In most usage scenarios, including transactional and non transactional storage requirements, InnoDB is a better choice, unless there are very special reasons to use other storage engines.
Auto growth column
In the automatic growth column of InnoDB table, the inserted value can be empty or manually inserted. If the inserted value is empty, the actual inserted value is the value after automatic growth.
Next, define table t1 and field c1 as automatic growth column. insert the table. It can be found that when the inserted value is empty, the actual inserted value is the value after automatic growth.
mysql> create table t1(
-> c1 int not null auto_increment,
-> c2 varchar(10) default null,
-> primary key(c1)
-> ) engine = innodb;
Query OK, 0 rows affected (0.05 sec)
mysql> insert into t1(c1,c2) values(null,'1'),(2,'2');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from t1;
+----+------+
| c1 | c2 |
+----+------+
| 1 | 1 |
| 2 | 2 |
+----+------+
2 rows in set (0.00 sec)
In InnoDB, the self growing column must be an index and the first column of the index. If it is not the first column, the database will report an exception
mysql> create table t2(
-> c1 int not null auto_increment,
-> c2 varchar(10) default null,
-> key(c2,c1)
-> ) engine = innodb;
ERROR 1075 (42000): Incorrect table definition; there can be only one auto column and it must be defined as a key
mysql> create table t2(
-> c1 int not null auto_increment,
-> c2 varchar(10) default null,
-> key(c1,c2)
-> ) engine = innodb;
Query OK, 0 rows affected (0.05 sec)
Primary keys and indexes
The InnoDB table is built based on the cluster index. The cluster index is also called the primary index, which is also the primary key of the table. Each row of data in the InnoDB table is saved on the leaf node of the primary index. The InnoDB table must contain a primary key. If the primary key is not explicitly specified when creating the table, InnoDB will automatically create a long hidden field with a length of 6 bytes as the primary key. All InnoDB tables should explicitly specify the primary key.
Indexes other than the primary key in the InnoDB table are called secondary indexes. Secondary indexes must contain primary key columns. If the primary key column is large, all other indexes will be large. Therefore, whether the primary key is designed reasonably will have an impact on all indexes.
The design principles of primary keys are as follows:
- Satisfy unique and non null constraints;
- The primary key field should be as small as possible;
- The primary key field value will not be modified;
- Priority should be given to self adding fields or fields with the most frequent queries.
Storage mode
InnoDB can store tables and indexes in the following two ways:
- Storage method of exclusive table space: the table structure is saved in In the frm file, the data and index of each table are saved separately In ibd file;
- Storage method of shared table space: the table structure is saved in In the frm file, the data and indexes are saved in the table space ibdata file.
When using shared tablespaces, with the continuous growth of data, the maintenance of tablespaces will become more and more difficult. Generally, it is recommended to use exclusive tablespaces. You can configure the parameter innodb_file_per_table to open the exclusive table space.
innodb_file_per_table = 1 #1 is to open the exclusive table space
When using the exclusive table space, you can easily backup and restore a single table, but copy it directly The ibd file cannot be used because it lacks the data dictionary information of the shared table space, but it can be realized through the following command ibd files and frm files can be correctly identified and restored.
alter table xxx discard tablespace; alter table xxx import tablespace;
4,MyISAM
4.1 characteristics
- Locking and concurrency
MyISAM can lock the whole table instead of rows. A shared lock will be added to the meter when reading, and an exclusive lock will be added to the meter when writing. While the table has read query, you can also insert data into the table.
- Delayed update index key
When creating the MyISAM table, you can specify DELAY_KEY_WRITE option: when each update is completed, the updated index data will not be written to the disk immediately, but will be written to the key buffer in memory first. When the key buffer is cleaned up or the table is closed, the corresponding index block will be written to the disk. This method can greatly improve write performance.
- compress
You can use the myisampack tool to compress the MyISAM table. Compressed tables can greatly reduce the use of disk space, thus reducing disk IO and improving query performance. Data cannot be modified when compressing a table. The records in the table are compressed independently. When reading a single row, there is no need to decompress the whole table.
Generally speaking, if the data is not modified after insertion, this kind of table is more suitable for compression, such as log record table and flow record table.
- repair
For MyISAM tables, MySQL can manually or automatically perform check and repair operations. Performing table repair may result in some data loss, and the whole process is very slow.
You can check the errors of the table through check table xxx. If there are errors, you can repair them through repair table xxx.
When the MySQL server is shut down, you can also check and repair through the myisamchk command line tool.
mysql> create table t1(
-> c1 int not null,
-> c2 varchar(10) default null
-> ) engine = myisam;
Query OK, 0 rows affected (0.06 sec)
mysql> check table t1;
+-----------+-------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------+-------+----------+----------+
| tempdb.t1 | check | status | OK |
+-----------+-------+----------+----------+
1 row in set (0.00 sec)
mysql> repair table t1;
+-----------+--------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------+--------+----------+----------+
| tempdb.t1 | repair | status | OK |
+-----------+--------+----------+----------+
1 row in set (0.00 sec)
4.2 storage mode
MyISAM is stored in three files on disk with the same file name and table name
- . frm - storage table definition;
- . MYD - store data;
- . MYI - store index.
The following is the creation statement of MyISAM table and the corresponding data file:
mysql> create table a (id int) ENGINE = MyISAM; Query OK, 0 rows affected (0.01 sec) [root@mysql-test-1 tempdb]# ls -lrt a.* -rw-r----- 1 mysql mysql 8556 Apr 13 02:01 a.frm -rw-r----- 1 mysql mysql 1024 Apr 13 02:01 a.MYI -rw-r----- 1 mysql mysql 0 Apr 13 02:01 a.MYD
5,Memory
Memory uses the contents of memory to create tables. There is only one memory table frm file. If you need to access data quickly, and the data will not be modified and lost, it doesn't matter. Using memory is very suitable. Moreover, the memory table supports Hash index, and the lookup operation is very fast.
Memory table cannot replace disk based table:
- Memory table is a table level lock, and the performance of concurrent writing is poor;
- BLOB or TEXT type columns are not supported, and the length of each row is fixed. Even if varchar column is specified, char column will be used in actual storage.
The Memory table is suitable for the following scenarios:
- It is used to find or map tables, such as tables with infrequent changes in zip codes, provinces and cities;
- A table for caching periodic aggregate data;
- Intermediate result table for statistical operation.
Indexes
1. What is an index
Index is also called "Key" in MySQL. It is a data structure used by the storage engine to quickly find records, which is also the basic function of index.
The working principle of MySQL index is similar to the directory of a book. If you want to find specific knowledge points in a book, first find the corresponding page number through the directory. In mysql, the storage engine uses the index in a similar way. First find the corresponding value in the index, and then find the corresponding data row according to the index record. To sum up, the index is to improve the efficiency of data query, just like the directory of a book.
The following query assumes that there is an index on field c2, and the storage engine will find the row with c2 equal to test 01 through the index. In other words, the storage engine first searches by value in the index, and then returns all data rows containing the value.
mysql> select * from t1 where c2='Test 01'\G *************************** 1. row *************************** c1: 1 c2: Test 01 1 row in set (0.00 sec)
From the perspective of execution plan, you can also see the index idx_c2 used:
mysql> create table t1(
-> c1 int not null auto_increment,
-> c2 varchar(10) default null,
-> primary key(c1)
-> ) engine = innodb;
Query OK, 0 rows affected (0.05 sec)
mysql> insert into t1() values(1,'Test 01');
Query OK, 1 row affected (0.00 sec)
mysql> create index idx_c2 on t1(c2);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select * from t1 where c2='Test 01'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ref
possible_keys: idx_c2
key: idx_c2
key_len: 33
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
Common index types mainly include B-Tree index, hash index, spatial data index (R-Tree) and full-text index.
- InnoDB and MyISAM storage engines can create B-Tree indexes, and indexes can be created for single column or multiple columns;
- The Memory storage engine can create hash indexes and also support B-Tree indexes;
- From mysql5 Starting from 7, InnoDB and MyISAM storage engines can support spatial type indexes;
- InnoDB and MyISAM storage can support full-TEXT index, which can be used for full-TEXT search and is limited to CHAR, VARCHAR and TEXT columns.
2. Advantages
The biggest function of index is to quickly find data. In addition, index has other additional functions.
B-Tree is the most common index. It stores data in order. It can be used for order by and group by operations. Because B-trees are ordered, the relevant values are stored together. Because the index stores the actual column values, some queries can complete the query only through the index, such as overwrite query.
In general, indexing has three advantages:
- Indexing can greatly reduce the amount of data that MySQL needs to scan;
- Indexes can help MySQL avoid sorting and temporary tables;
- Index can change random IO to sequential io.
Indexing is not always the best optimization tool:
- For very small tables, full table scanning is more efficient in most cases;
- For medium and large tables, indexes are very effective;
- For large tables, the cost of building and using indexes is increasing. At this time, it may need to be combined with other technologies, such as partitioned tables.
3. B-Tree index
3.1 storage structure
B-Tree stores the values of index columns in order, and the distance from each leaf page to the root is the same.
B-Tree index can accelerate the speed of data search, because the storage engine does not need full table scanning to obtain data, just start the search from the root node of the index.
Taking the table customer as an example, let's see how the index organizes the storage of data.
mysql> create table customer(
id int,
last_name varchar(30),
first_name varchar(30),
birth_date date,
gender char(1),
key idx1_customer(last_name,first_name,birth_date)
);
Each row of the index contains the data in the last table_ name,first_name and birth_ The value of date.
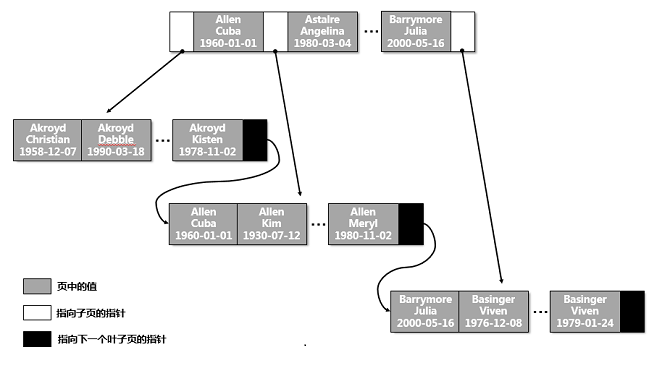
3.2 query types suitable for B-Tree index
- Full value matching:
Match all columns in the index, such as finding customers whose name is George Bush and born on August 8, 1960.
mysql> explain select * from customer where first_name='George' and last_name='Bush' and birth_date='1960-08-08'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx1_customer
key: idx1_customer
key_len: 190
ref: const,const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
- Match leftmost prefix:
Use only the first column of the index, such as finding all customers with last name Bush:
mysql> explain select * from customer where last_name='Bush'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx1_customer
key: idx1_customer
key_len: 93
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
- Match column prefix:
Only match the beginning of the value of a certain column. For example, find all customers with surnames starting with B. here, the first column of the index is used:
mysql> explain select * from customer where last_name like 'B%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: range
possible_keys: idx1_customer
key: idx1_customer
key_len: 93
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
- Matching range value:
Find all customers whose last names are between Allen and Bush. The first column of the index is used here:
mysql> explain select * from customer where last_name between 'Allen' and 'Bush'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: range
possible_keys: idx1_customer
key: idx1_customer
key_len: 93
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
- Exactly match one column and range match another:
The first column matches all, and the second column matches the range. For example, find customers whose last name is Bush and whose first name begins with G:
mysql> explain select * from customer where last_name='Bush' and first_name like 'G'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: range
possible_keys: idx1_customer
key: idx1_customer
key_len: 186
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
- Index only queries:
You only need to access the index to obtain data, and you don't need to access data rows back to the table. This kind of query is also called overlay index:
mysql> explain select last_name from customer where last_name='Bush'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx1_customer
key: idx1_customer
key_len: 93
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
- The index can also be used for order by sort operations because the nodes in the index are ordered. If B-Tree can find data in some way, it can also sort in this way.
3.3 limitations of b-tree index
- An index cannot be used if it does not start looking for data in the leftmost column of the index.
- Cannot skip indexed columns.
- There is a range query of a column in the query, and the columns on the right cannot use the index to find data.
4. Hash index
The hash index is implemented based on the hash table and only supports queries that accurately match all columns of the index.
For each row of data, the storage engine will calculate a hash code for all index columns.
Hash index stores all hash codes in the index and saves pointers to each data row.
4.1 storage structure
In common storage engines, the MEMORY storage engine explicitly supports hash indexing.
If the hash values of multiple columns are the same, the hash index will store multiple record pointers into the same hash entry in the form of linked list.
Take the customer table as an example. How do indexes organize data storage
mysql> create table customer(
id int,
last_name varchar(30),
first_name varchar(30),
birth_date date,
key idx1_customer(first_name) using hash
) ENGINE=MEMORY;
mysql> select * from customer;
+------+-----------+------------+------------+
| id | last_name | first_name | birth_date |
+------+-----------+------------+------------+
| 1 | Allen | Cuba | 1960-01-01 |
| 2 | Barrymore | Julia | 2000-05-06 |
| 3 | Basinger | Viven | 1979-01-24 |
+------+-----------+------------+------------+
3 rows in set (0.00 sec)
Suppose the hash index uses a hash function f(),The returned values are as follows:
f('Cuba')=1212
f('Julia')=5656
f('Viven')=2323
The data structure of hash index is as follows:
+-----------+-----------------------+
| groove(Slot) | value(Value) |
+-----------+-----------------------+
| 1212 | Pointer to line 1 |
| 2323 | Pointer to line 3 |
| 5656 | Pointer to line 2 |
+-----------+-----------------------+
The InnoDB storage engine can also support hash indexes, but the hash indexes it supports are adaptive. The InnoDB storage engine will create a hash index based on the B-Tree index in memory according to the usage of the table. This behavior is automatic and internal. It is not allowed to interfere with whether to generate a hash index in a table.
4.2 query types suitable for hash index
- Exactly match all columns
And all columns in the index, such as finding a customer named Julia.
The database will calculate first first first_ The hash value of name ='julia 'is 5656, and then find 5656 in the index. The corresponding pointer is: the pointer to row 2. Finally, get the specific value from the original table according to the pointer and compare whether it is Julia
mysql> explain select * from customer where first_name='Julia'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx1_customer
key: idx1_customer
key_len: 93
ref: const
rows: 2
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
4.3 restrictions on hash index
- Hash index only supports equivalent queries, including =, IN, < = >;
- The hash index does not store field values, but only contains hash values and row pointers. The values in the index cannot be used to avoid reading rows;
- The hash index is not stored in the order of index values and cannot be used for sorting;
- The hash index does not support the matching search of some index columns. For example, if you create a hash index in a field (last_name,first_name), you need to find last_ The hash index cannot be used for this kind of query;
- Hash index does not support range query, such as finding all customers with last names between Allen and Bush. Hash index cannot be used for such query;
- If there are many hash conflicts (different index column values have the same hash value), the maintenance cost of the index is very high. Try to avoid creating hash indexes on fields with low selectivity.
5. Spatial data index R-Tree
Among the common storage engines, MyISAM storage engine supports spatial index and is mainly used for geographic data storage. Spatial index will index data from all dimensions. When querying, you can use any dimension to combine queries. This is different from B-Tree index. Spatial index does not need prefix query. In fact, the GIS support of MySQL is not perfect. Generally, it is not recommended to use spatial index in MySQL.
6. Full text index
Full text index looks up the keywords in the text, not directly compare the values in the index. It is a special type of index. The matching method of full-text index is completely different from that of other indexes. It is more similar to search engine, not a simple where condition matching.
Full text index and B-Tree index can be created on the same column at the same time. Full text index is applicable to match against operation, not a simple where condition operation.
7. How to select MySQL index with high efficiency and high performance?
7.1 independent columns
Independent column refers to that the index column cannot be part of an expression or a parameter of a function. If the columns in the SQL query are not independent, MySQL cannot use the index.
For the following two queries, MySQL cannot use id column and birth_ Index of the date column. Developers should always get into the habit of putting SQL symbols on the left side of the index.
mysql> select * from customer where id + 1 = 2;
mysql> select * from customer where to_days(birth_date) - to_days('2020-06-07') <= 10;
7.2 prefix index
Sometimes it is necessary to create an index on a very long character column, which will make the index occupy a lot of space and inefficient. In this case, you can generally use some characters at the beginning of the index, which can save the space generated by the index, but also reduce the selectivity of the index.
It is necessary to select a prefix long enough to ensure high selectivity, but in order to save space, the prefix cannot be too long, as long as the cardinality of the prefix is close to that of the complete column.
Tips: index selectivity refers to the ratio of the non duplicate index value (also known as cardinality) to the total number of records in the data table. The higher the index selectivity, the higher the query efficiency.
Selectivity of complete columns:
mysql> select count(distinct left(last_name,3))/count(*) left_3, count(distinct left(last_name,4))/count(*) left_4, count(distinct left(last_name,5))/count(*) left_5, count(distinct left(last_name,6))/count(*) left_6 from customer; +--------+--------+--------+--------+ | left_3 | left_4 | left_5 | left_6 | +--------+--------+--------+--------+ | 0.043| 0.046| 0.050| 0.051| +--------+--------+--------+--------+
In the above query, when the current prefix length is 6, the selectivity of the prefix is close to the selectivity of the complete column of 0.053. By increasing the prefix length, the selectivity can be improved very little.
Create an index with a prefix length of 6:
mysql> alter table customer add index idx_last_name(last_name(6));
Prefix index can make the index smaller and faster, but it also has disadvantages: it cannot be used for order by and group by, and it cannot be used for overlay scanning.
7.3 proper index column order
In a multi column B-Tree index, the order of index columns means that the index should first be sorted according to the leftmost column, followed by the second column, the third column, etc. The index can be scanned in ascending or descending order to meet the query requirements of order by, group by and distinct that accurately conform to the column order.
The column order of the index is very important. Without considering sorting and grouping, the column with the highest selectivity is usually placed at the top of the index.
For the following query, should an index of (last_name,first_name) or (first_name,last_name) be created?
mysql> select * from customer where last_name = 'Allen' and first_name = 'Cuba'
First, calculate the selectivity of these two columns to see which column is higher.
mysql> select count(distinct last_name)/count(*) last_name_selectivity, count(distinct first_name)/count(*) first_name_selectivity from customer; +-----------------------+------------------------+ | last_name_selectivity | first_name_selectivity | +-----------------------+------------------------+ | 0.053 | 0.372 | +-----------------------+------------------------+
Obviously, column first_name is more selective, so choose first_name as the first column of index column:
mysql> alter table customer add index idx1_customer(first_name,last_name);
7.4 overlay index
If an index contains all the fields that need to be queried, it is called an overlay index.
Because the overlay index does not need to return to the table, all the values can be obtained by scanning the index, which can greatly improve the query efficiency: the index entries are generally much smaller than the data rows. Only scanning the index can meet the query requirements, and MySQL can greatly reduce the amount of data access.
The table customer has a multi column index (first_name,last_name). The following queries only need to access first_ Name and last_ Name, you can overwrite the index through this index.
mysql> explain select last_name, first_name from customer\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: index
possible_keys: NULL
key: idx1_customer
key_len: 186
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
When the query is an overlay index query, you can see Using index in the extra column of explain.
7.5 sorting using index
MySQL can generate ordered results through sorting operation or scanning according to index order. If the value of the type column of explain is index, it indicates that the query uses index scanning for sorting.
The restrictions of order by and query are the same. You need to meet the leftmost prefix requirements of the index, otherwise you cannot use the index for sorting. Only when the column order of the index is exactly the same as that of the order by clause, and the sorting direction (positive or reverse) of all columns is the same, can MySQL use the index for sorting. If the query is multi table Association, the index can be used for sorting only when all the fields referenced by the order by clause are the first table.
Taking the table customer as an example, which queries can be sorted by index:
mysql> create table customer(
id int,
last_name varchar(30),
first_name varchar(30),
birth_date date,
gender char(1),
key idx_customer(last_name,first_name,birth_date)
);
- Queries that can be sorted by index
The column order of the index is exactly the same as that of the order by clause:
mysql> explain select last_name,first_name from customer order by last_name, first_name, birth_date\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: index
possible_keys: NULL
key: idx_customer
key_len: 190
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
The first column of the index is specified as a constant:
From explain, you can see that there is no sort operation (filesort):
mysql> explain select * from customer where last_name = 'Allen' order by first_name, birth_date\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx_customer
key: idx_customer
key_len: 93
ref: const
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
The first column of the index is specified as a constant, and the second column is used for sorting:
mysql> explain select * from customer where last_name = 'Allen' order by first_name desc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx_customer
key: idx_customer
key_len: 93
ref: const
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
The first column of the index is the range query, and the two columns used by order by are the leftmost prefix of the index:
mysql> explain select * from customer where last_name between 'Allen' and 'Bush' order by last_name,first_name\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: range
possible_keys: idx_customer
key: idx_customer
key_len: 93
ref: NULL
rows: 1
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.00 sec)
- Queries that cannot be sorted by index
Two different sort directions are used:
mysql> explain select * from customer where last_name = 'Allen' order by first_name desc, birth_date asc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx_customer
key: idx_customer
key_len: 93
ref: const
rows: 1
filtered: 100.00
Extra: Using index condition; Using filesort
1 row in set, 1 warning (0.00 sec)
The order by clause refers to a column that is not in the index:
mysql> explain select * from customer where last_name = 'Allen' order by first_name, gender\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: customer
partitions: NULL
type: ref
possible_keys: idx_customer
key: idx_customer
key_len: 93
ref: const
rows: 1
filtered: 100.00
Extra: Using index condition; Using filesort
1 row in set, 1 warning (0.00 sec)
The columns of where condition and order by cannot form the leftmost prefix of the index:
mysql> explain select * from customer where last_name = 'Allen' order by birth_date\G
The first column is the range query. The columns of where condition and order by cannot form the leftmost prefix of the index:
mysql> explain select * from customer where last_name between 'Allen' and 'Bush' order by first_name\G
The first column is a constant, and the second column is a range query (multiple equals are also range queries):
mysql> explain select * from customer where last_name = 'Allen' and first_name in ('Cuba','Kim') order by birth_date\G
lock
MySQL has two levels of lock waiting, server level and storage engine level
1. Watch lock
1.1 explicit lock
Explicit locking can be controlled through lock tables and unlock tables.
Execute the lock tables command in the MySQL session to obtain an explicit lock on the table customer.
mysql> lock tables customer read; Query OK, 0 rows affected (0.00 sec)
In another MySQL session, execute the lock tables command on the table customer, and the query will be suspended.
mysql> lock tables customer write;
In the first session, execute show processlist to view the thread status. You can see that the status of thread 13239868 is Waiting for table metadata lock. In MySQL, when one thread holds the lock, other threads can only keep trying to obtain it.
mysql> show processlist\G
*************************** 1. row ***************************
Id: 13239801
User: root
Host: localhost
db: tempdb
Command: Query
Time: 0
State: starting
Info: show processlist
*************************** 2. row ***************************
Id: 13239868
User: root
Host: localhost
db: tempdb
Command: Query
Time: 12
State: Waiting for table metadata lock
Info: lock tables customer write
2 rows in set (0.00 sec)
1.2 implicit lock
In addition to explicit locking blocking such operations, MySQL will also implicitly lock the table during the query process.
A long-time query can be realized through the sleep() function, and then MySQL will generate an implicit lock.
Execute sleep(30) in a MySQL session and get an implicit lock on the table customer.
mysql> select sleep(30) from customer;
In another MySQL session, execute the lock tables command on the table customer, and the query will be suspended.
mysql> lock tables customer write;
In the third session, execute show processlist to view the thread status. You can see that the status of thread 13244135 is Waiting for table metadata lock. The implicit lock of the select query blocks the explicit write lock requested in lock tables.
mysql> show processlist\G
*************************** 1. row ***************************
Id: 13244112
User: root
Host: localhost
db: tempdb
Command: Query
Time: 6
State: User sleep
Info: select sleep(30) from customer
*************************** 2. row ***************************
Id: 13244135
User: root
Host: localhost
db: tempdb
Command: Query
Time: 2
State: Waiting for table metadata lock
Info: lock tables customer write
2. Global lock
Set global lock with read or flush with read_only=1. The global lock conflicts with any table lock.
Execute the flush tables command in the MySQL session to obtain the global read lock.
mysql> flush tables with read lock; Query OK, 0 rows affected (0.00 sec)
In another MySQL session, execute the lock tables command on the table customer, and the query will be suspended.
mysql> lock tables customer write;
In the first session, execute show processlist to view the thread status. You can see that the status of thread 13283816 is Waiting for global read lock. This is a global read lock, not a table level lock.
mysql> show processlist\G
*************************** 1. row ***************************
Id: 13283789
User: root
Host: localhost
db: tempdb
Command: Query
Time: 0
State: starting
Info: show processlist
*************************** 2. row ***************************
Id: 13283816
User: root
Host: localhost
db: tempdb
Command: Query
Time: 10
State: Waiting for global read lock
Info: lock tables customer write
2 rows in set (0.00 sec)
3. Named lock
Named lock is a table level lock created by MySQL server when renaming or deleting a table.
Named locks conflict with ordinary table locks, whether explicit or implicit.
lock table s command to obtain an explicit lock on the table customer.
mysql> lock tables customer read; Query OK, 0 rows affected (0.00 sec)
In another MySQL session, execute the rename table command on the table customer, and the session will be suspended. The session status is Waiting for table metadata lock:
mysql> rename table customer to customer_1;
mysql> show processlist\G
...
*************************** 2. row ***************************
Id: 51
User: root
Host: localhost
db: tempdb
Command: Query
Time: 128
State: Waiting for table metadata lock
Info: rename table customer to customer_1
4. User lock
For user lock, specify the name string and the waiting timeout (in seconds).
Execute get_lock command, successfully execute and hold a lock.
mysql> select get_lock('user_1',20);
+------------------------+
| get_lock('user_1',20) |
+------------------------+
| 1 |
+------------------------+
1 row in set (0.00 sec)
In another MySQL session, get is also performed_ Lock command, try to lock the same string. At this time, the session will be suspended and the session state is User lock.
mysql> select get_lock('user_1',20);
+------------------------+
| get_lock('user_1',20) |
+------------------------+
| 1 |
+------------------------+
mysql> show processlist\G
...
*************************** 2. row ***************************
Id: 51
User: root
Host: localhost
db: tempdb
Command: Query
Time: 3
State: User lock
Info: select get_lock('user_1',20)
5. Lock waiting in InnoDB storage engine
Storage engine level locks are more difficult to debug than server level locks, and the locks of various storage engines are different from each other. Some storage engines do not even provide any method to view locks.
show engine innodb status
The show engine innodb status command contains some lock information of the InnoDB storage engine, but it is difficult to determine which transaction causes the lock problem, because the command will not tell you who owns the lock.
If the TRANSACTION is waiting for a lock, the relevant lock information will be reflected in the TRANSACTION part of the output of show engine innodb status. Execute the following command in the MySQL session to get the write lock of the first row in the table customer.
mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from customer limit 1 for update; +------+-----------+------------+------------+--------+ | id | last_name | first_name | birth_date | gender | +------+-----------+------------+------------+--------+ | NULL | 111 | 222 | NULL | 1 | +------+-----------+------------+------------+--------+ 1 row in set (0.00 sec)
In another MySQL session, execute the same select command on the table customer, and the query will be blocked.
mysql> select * from customer limit 1 for update;
At this time, execute the show engine innodb status command to see the relevant lock information.
1 ---TRANSACTION 124178, ACTIVE 6 sec starting index read 2 mysql tables in use 1, locked 1 3 LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s) 4 MySQL thread id 12570, OS thread handle 139642200024832, query id 48195 localhost root Sending data 5 select * from customer limit 1 for update 6 ------- TRX HAS BEEN WAITING 6 SEC FOR THIS LOCK TO BE GRANTED: 7 RECORD LOCKS space id 829 page no 3 n bits 72 index GEN_CLUST_INDEX of table `tempdb`.`customer` trx id 124178 lock_mode X locks rec but not gap waiting
Line 7 indicates the query thread id 12570, which is waiting for Gen in the customer table_ CLUST_ There is a lock_mode X on page 3 of the index. Finally, the lock wait times out and the query returns an error message.
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
imformation_schema
On mysql5 5, generally through imformation_schema table to query relevant transaction and lock information through imformation_schema is more efficient and comprehensive than the show engine innodb status command.
Execute the following commands in the MySQL session to see who is blocking, who is waiting, and how long to wait.
mysql> SELECT
IFNULL(wt.trx_mysql_thread_id, 1) BLOCKING_THREAD_ID,t.trx_mysql_thread_id WAITING_THREAD_ID, CONCAT(p. USER, '@', p. HOST) USER,
p.info SQL_TEXT, l.lock_table LOCK_TABLE, l.lock_index LOCKED_INDEX, l.lock_type LOCK_TYPE, l.lock_mode LOCK_MODE,
CONCAT(FLOOR(HOUR (TIMEDIFF(now(), t.trx_wait_started)) / 24),'day ',MOD (HOUR (TIMEDIFF(now(), t.trx_wait_started)),24),':',
MINUTE (TIMEDIFF(now(), t.trx_wait_started)),':',SECOND (TIMEDIFF(now(), t.trx_wait_started))) AS WAIT_TIME,
t.trx_started TRX_STARTED, t.trx_isolation_level TRX_ISOLATION_LEVEL, t.trx_rows_locked TRX_ROWS_LOCKED, t.trx_rows_modified TRX_ROWS_MODIFIED
FROM INFORMATION_SCHEMA.INNODB_TRX t
LEFT JOIN information_schema.innodb_lock_waits w ON t.trx_id = w.requesting_trx_id
LEFT JOIN information_schema.innodb_trx wt ON wt.trx_id = w.blocking_trx_id
INNER JOIN information_schema.innodb_locks l ON l.lock_trx_id = t.trx_id
INNER JOIN information_schema. PROCESSLIST p ON t.trx_mysql_thread_id = p.id
ORDER BY 1\G
*************************** 1. row ***************************
BLOCKING_THREAD_ID: 1
WAITING_THREAD_ID: 62751
USER: root@localhost
SQL_TEXT: NULL
LOCK_TABLE: `tempdb`.`customer`
LOCKED_INDEX: GEN_CLUST_INDEX
LOCK_TYPE: RECORD
LOCK_MODE: X
WAIT_TIME: NULL
TRX_STARTED: 2020-06-22 06:52:14
TRX_ISOLATION_LEVEL: READ COMMITTED
TRX_ROWS_LOCKED: 1
TRX_ROWS_MODIFIED: 0
*************************** 2. row ***************************
BLOCKING_THREAD_ID: 62751
WAITING_THREAD_ID: 62483
USER: root@localhost
SQL_TEXT: select * from customer limit 1 for update
LOCK_TABLE: `tempdb`.`customer`
LOCKED_INDEX: GEN_CLUST_INDEX
LOCK_TYPE: RECORD
LOCK_MODE: X
WAIT_TIME: 0day 0:0:5
TRX_STARTED: 2020-06-22 07:01:49
TRX_ISOLATION_LEVEL: READ COMMITTED
TRX_ROWS_LOCKED: 1
TRX_ROWS_MODIFIED: 0
2 rows in set, 2 warnings (0.00 sec)
The result shows that thread 62483 has been waiting for the lock in table customer for 5s, which is blocked by thread 62751.
The following query can tell you how many queries are blocked by which thread locks.
mysql> select concat('thread ', b.trx_mysql_thread_id, ' from ', p.host) as who_blocks,
if(p.command = "Sleep", p.time, 0) as idle_in_trx,
max(timestampdiff(second, r.trx_wait_started, now())) as max_wait_time,
count(*) as num_waiters
from information_schema.innodb_lock_waits as w
inner join information_schema.innodb_trx as b on b.trx_id = w.blocking_trx_id
inner join information_schema.innodb_trx as r on r.trx_id = w.requesting_trx_id
left join information_schema.processlist as p on p.id = b.trx_mysql_thread_id
group by who_blocks order by num_waiters desc\G
*************************** 1. row ***************************
who_blocks: thread 62751 from localhost
idle_in_trx: 1206
max_wait_time: 20
num_waiters: 5
1 row in set, 1 warning (0.00 sec)
The results show that thread 62751 has been idle for a period of time. Five threads are waiting for thread 62751 to complete the submission and release the lock, and one thread has waited for thread 62751 to release the lock for 20 s.
affair
Transactions are implemented at the storage engine layer.
MySQL is a database that supports multiple storage engines, but not all storage engines support transactions. For example, MyISAM does not support transactions
1. ACID
- atomicity: a transaction is regarded as a complete minimum unit of work. All database operations in the transaction are either executed successfully or rolled back when they fail. You can't execute only part of the database operations successfully;
- consistency: the database always transitions from one consistent state to another.
- isolation: Generally speaking, the changes made by one thing are invisible to other transactions before they are committed.
- durability: when the transaction is committed successfully, the changes will be permanently saved to the database. Even if the system crashes, the modified data will not be lost.
2. Isolation level
- Read uncommitted: a transaction has not been committed, and its changes can be seen by other transactions. Transactions can read uncommitted data, which is called dirty read. This isolation level is rarely used in practical applications;
- Read committed: after a transaction is committed, its changes can be seen by other transactions. The default isolation level for most databases is read committed, such as Oracle.
- Repeatable read: the data seen during the execution of a transaction is always consistent with the data seen when the transaction is started. At the repeatable read isolation level, uncommitted changes are also invisible to other transactions. This level ensures that the results of reading the same record multiple times in the same transaction are consistent. The default transaction isolation level of MySQL is repeatable read;
- Serializable: serializable is the highest isolation level. For the same row of data, both reading and writing will be locked. When a lock conflict occurs, the transaction accessed later must wait for the previous transaction to complete before continuing. This isolation level is rarely used in practical application scenarios. It is only used when it is very necessary to ensure data consistency and it is acceptable that there is no concurrency.
| Isolation level | Dirty reading possibility | Non repeatability possibility | Unreal reading possibility | Lock read |
|---|---|---|---|---|
| read uncommitted | yes | yes | yes | no |
| read committed | no | yes | yes | no |
| repeatable read | no | no | yes | no |
| serializable | no | no | no | yes |
3. Transaction control mechanism
- RDBMS = SQL statement + transaction (ACID)
- A transaction is a whole composed of one or more SQL statements. Either all of them are executed successfully or all of them fail.
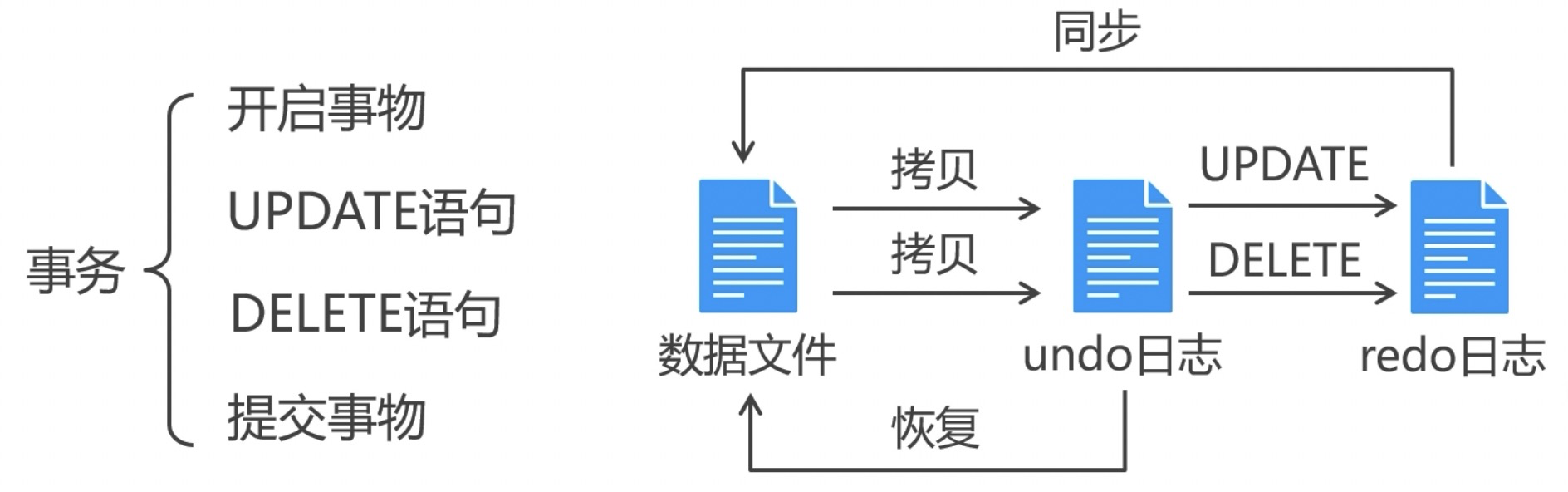
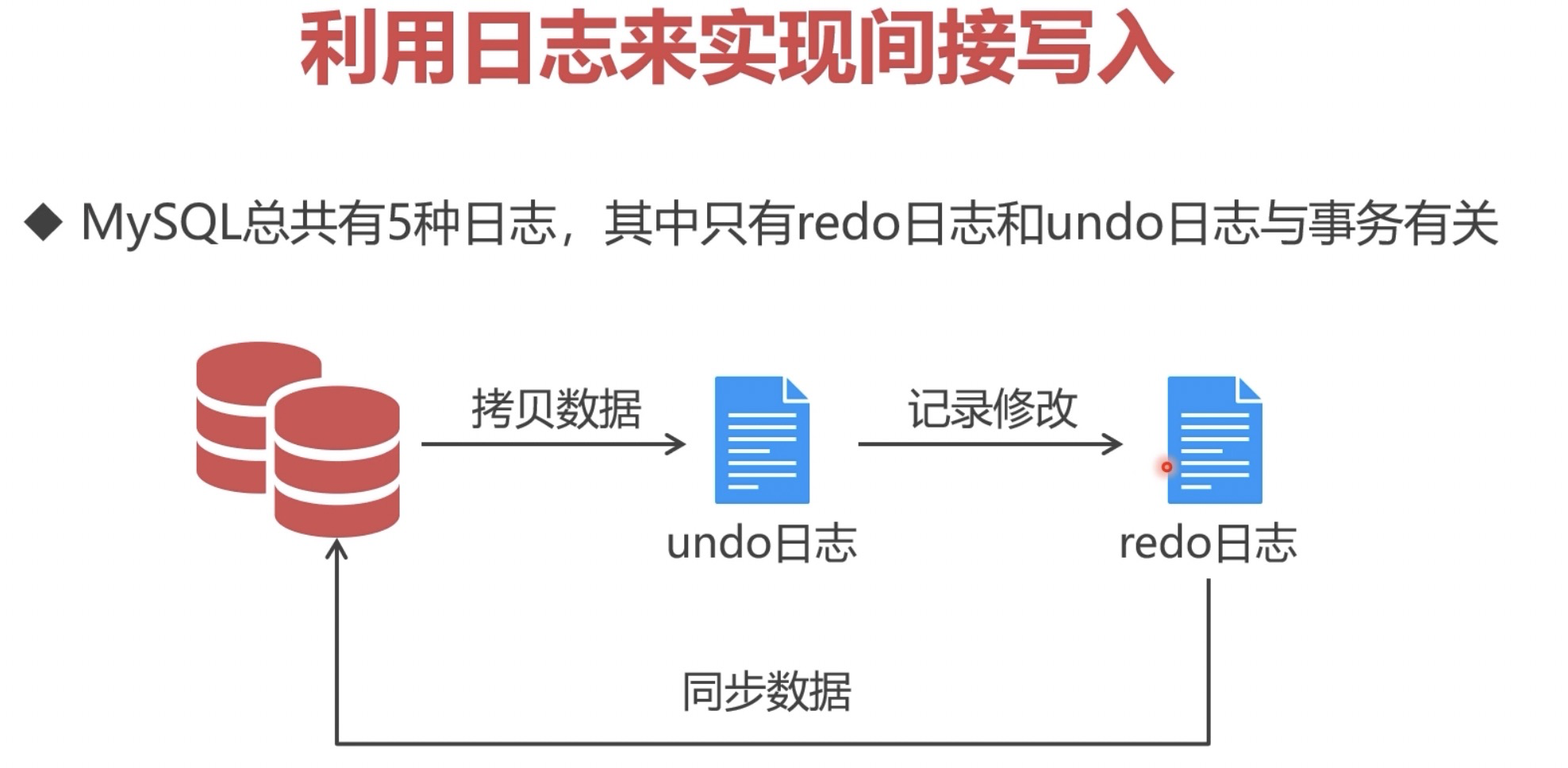
3.1 manage transactions manually
- By default, each SQL statement executed by MySQL will automatically start and commit transactions
- In order to integrate multiple SQL statements into one transaction, you can manually manage the transaction
SET START TRANSACTION;//Open transaction SQL sentence [COMMIT|ROLLBACK];//Commit rollback
3.2 isolation level adjustment
By default, the isolation level of MySQL is repeatable read.
MySQL can use set transaction_ The isolation command is used to adjust the isolation level. The new isolation level will take effect at the beginning of the next transaction.
There are two ways to adjust the isolation level:
- Temporary: execute directly from the command line in MySQL:
mysql> show variables like 'transaction_isolation'; +-----------------------+-----------------+ | Variable_name | Value | +-----------------------+-----------------+ | transaction_isolation | REPEATABLE-READ | +-----------------------+-----------------+ 1 row in set (0.00 sec) mysql> SET transaction_isolation = 'REPEATABLE-READ'; ## SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE_READ; Query OK, 0 rows affected (0.00 sec)
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE_READ;
SET transaction_isolation = 'REPEATABLE-READ';
- Permanent: add the following two parameters to the configuration file my CNF and restart MySQL:
transaction_isolation = 'REPEATABLE-READ'
3.3 automatic submission
By default, MySQL is auto commit. This means that if a transaction is not explicitly started, each query will be committed as a transaction. This is obviously different from Oracle's transaction management. If the application is migrated from Oracle database to MySQL database, you need to ensure whether the transaction is clearly managed in the application.
In the current connection, you can modify the auto submit mode by setting autocommit:
mysql> show variables like 'autocommit'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ 1 row in set (0.00 sec) mysql> set autocommit = 1; Query OK, 0 rows affected (0.00 sec) -- 1 or ON Indicates that auto submit mode is enabled, 0 or OFF Indicates that auto submit mode is disabled
If autocommit=0 is set, all currently connected transactions need to be committed or rolled back through explicit commands.
For non transactional tables such as MyISAM, modifying autocommit will not have any impact, because the non transactional table has no concept of commit or rollback, and it will always be in the state of autocommit enabled.
Some commands are enforced before execution commit Commit the currently connected transaction. such as DDL Medium alter table,as well as lock tables And so on.
3.4 using different storage engines in transactions
The service layer of MySQL is not responsible for transaction processing. Transactions are implemented by the storage engine layer.
In the same transaction, it is unreliable to use multiple storage engines, especially when transactional and non transactional tables are mixed in the transaction. As in the same transaction, InnoDB and MyISAM tables are used:
- If the transaction is submitted normally, there will be no problem;
- If a transaction encounters an exception and needs to be rolled back, non transactional tables cannot be undone, which will directly lead to inconsistent data.
4. Deadlock
Deadlock refers to the phenomenon that two or more transactions wait for each other due to competing for resources during execution,
If there is no external force, they will not be able to push forward.
Deadlock may occur when multiple transactions try to lock resources in different order, or multiple transactions lock the same resource at the same time.
Example:
Two transactions process the customer table at the same time
The two transactions execute the first update statement at the same time to update and lock the data of the row, and then both execute the second update statement. At this time, it is found that the row has been locked by the other party. Then, both transactions wait for the other party to release the lock, and hold the lock required by the other party. They fall into a dead cycle. External force intervention is required to release the deadlock.
mysql> CREATE TABLE `customer` ( `id` int(11) NOT NULL, `last_name` varchar(30) DEFAULT NULL, `first_name` varchar(30) DEFAULT NULL, `birth_date` date DEFAULT NULL, `gender` char(1) DEFAULT NULL, `balance` decimal(10,0) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 Transaction 1: start transaction; update customer set balance = 100 where id = 1; update customer set balance = 200 where id = 2; commit; Transaction 2: start transaction; update customer set balance = 300 where id = 2; update customer set balance = 400 where id = 1; commit;
In order to solve the deadlock problem, the database implements various deadlock detection and deadlock timeout mechanisms.
The more complex the storage engine is, the more it can detect the origin of the deadlock cycle and return an error.
Another way to solve deadlock is to give up the lock request when the lock wait times out.
The InnoDB storage engine can automatically detect the deadlock of transactions and roll back one or more transactions to prevent deadlock. However, in some scenarios, InnoDB cannot detect deadlocks. For example, in the same transaction, use the storage engine other than InnoDB and the statement of lock tables to set the table lock. At this time, set innodb_lock_wait_timeout is a system parameter. It is usually not a good way to solve the deadlock problem through lock waiting timeout, because it is likely to lead to lock waiting of a large number of transactions. When the lock waiting timeout occurs, the database will throw the following error message:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
Adjust InnoDB_ lock_ wait_ There are two methods of timeout:
- Temporary: execute directly from the command line in MySQL:
-- innodb_lock_wait_timeout The default value for is 50 seconds mysql> show variables like 'innodb_lock_wait_timeout'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | innodb_lock_wait_timeout | 50 | +--------------------------+-------+ 1 row in set (0.00 sec) mysql> set innodb_lock_wait_timeout=51; Query OK, 0 rows affected (0.00 sec)
- Permanent: add the following two parameters to the configuration file my CNF and restart MySQL:
innodb_lock_wait_timeout=50
In programming, we should also reduce the probability of deadlock as much as possible. The following are some suggestions for the InnoDB storage engine to reduce the probability of Deadlock:
- Similar business modules should be accessed in the same order as possible to prevent deadlock;
- In the same transaction, try to lock all resources required at one time to reduce the probability of deadlock;
- In the same transaction, do not use tables with different storage engines. For example, MyISAM and InnoDB tables appear in the same transaction;
- Control the size of transactions as much as possible to reduce the amount of locked resources and the length of locked time;
- For business modules prone to deadlock, try to upgrade the lock granularity and reduce the probability of deadlock through table lock.
5. Transaction log
Using transaction logs can improve the security and efficiency of transactions:
- When modifying table data, you only need to modify it in memory and then persist it to the transaction log on disk, instead of persisting the modified data to disk every time. After the transaction log is persistent, the modified data in the memory can be slowly brushed to the disk. This method is called pre write log. The modified data needs to be written to the disk twice;
- The efficiency is much faster, because the transaction log is added, and the log writing operation is only sequential IO in a small area on the disk, unlike random IO, which requires moving heads in multiple places on the disk;
- In case of database crash, the transaction log can be used to recover the data automatically.