thank
Thank you, Mr. Zhou Yang ❤️❤️
Uninstall previous version
View the installed MySQL RPM - qa|grep - I MySQL
Uninstall mysql-community-server-5.6.36-2 one by one using Yum remove el7. x86_ sixty-four
Installation of MySQL for Linux
-
Download MySQL installation package wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
-
Install MySQL source Yum -y localinstall mysql57-community-release-el7-11 noarch. rpm
-
Install MySQL lyum - y install MySQL community server online
-
Start MySQLsystemctl start mysqld
-
Set startup, systemctl enable mysqld, systemctl daemon reload
-
View the default password VIM / var / log / mysqld log
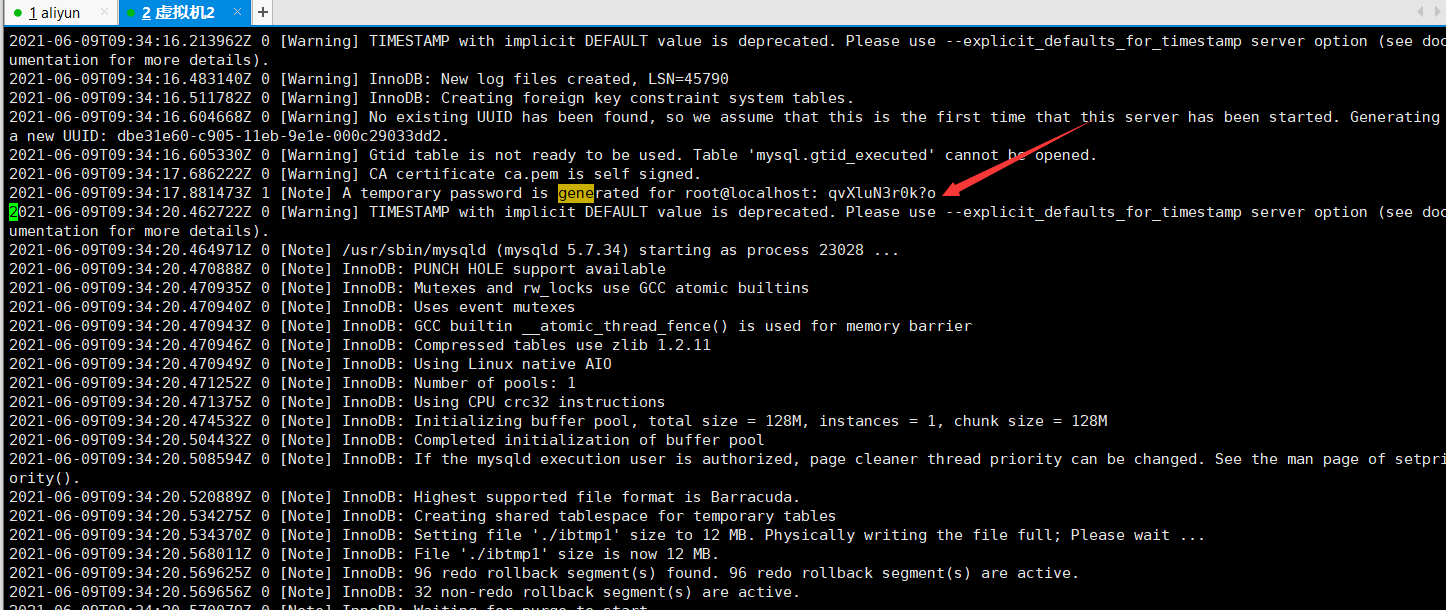
-
Change the password alter user 'root' @'localhost 'identified by' new password ';
-
Set remote login grant all privileges on ** To 'root' @ '%' identified by 'password' WITH GRANT OPTION;
-
Stop the firewall systemctl stop firewalld and release port 3306.
-
Configure the default encoding of MySQL
View the MySQL code show variables like '%char%'; (I have revised it)
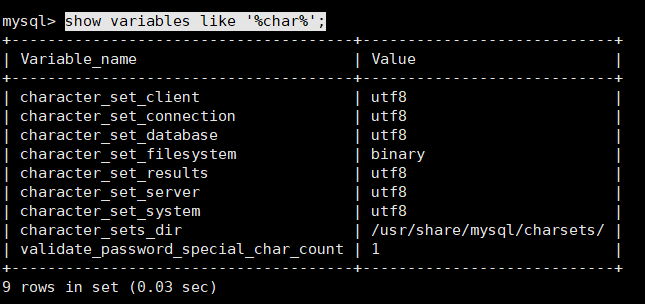
modify
vim /etc/my.cnf # Add the following configuration character_set_server=utf8 init_connect='SET NAMES utf8'
-
Restart MySQLsystemctl restart mysqld
MySQL s Logical Architecture
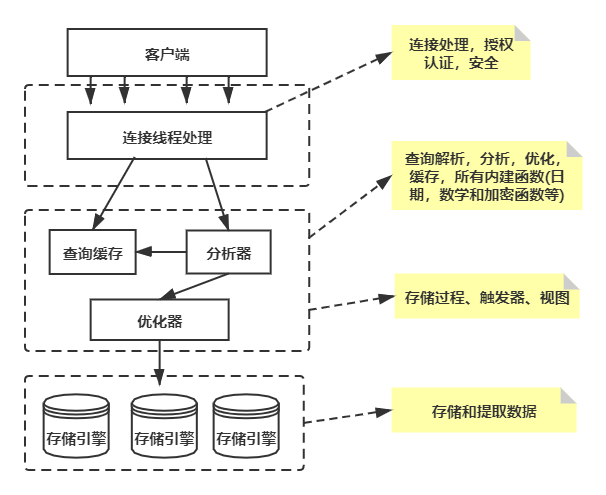
- Layer 1: the services included are not unique to MySQL. They all serve C/S programs or what these programs need: connection processing, authentication, security and so on.
- Layer 2: This is the core part of MySQL, usually called SQL Layer. All work before the MySQL database system processes the underlying data is completed in this layer, including permission judgment, sql parsing, row plan optimization, query cache processing and all built-in functions (such as date, time, mathematical operation, encryption), etc.
- The third layer: usually called StorEngine Layer, that is, the implementation part of the underlying data access operation, which is composed of a variety of storage engines. They are responsible for storing and obtaining all data stored in MySQL. Just like many file systems in Linux.
Each storage engine has its own advantages and disadvantages. Servers interact with them through the storage engine API. This interface hides the differences of each storage engine. The query layer should be as transparent as possible. This API contains many underlying operations. For example, start a transaction or retrieve a row with a specific primary key.
The storage engine cannot parse SQL (except InnoDB, which will parse foreign key definitions because MySQL service itself does not implement this function), nor can it communicate with each other. Simply respond to the server's request.
MySQL storage engine
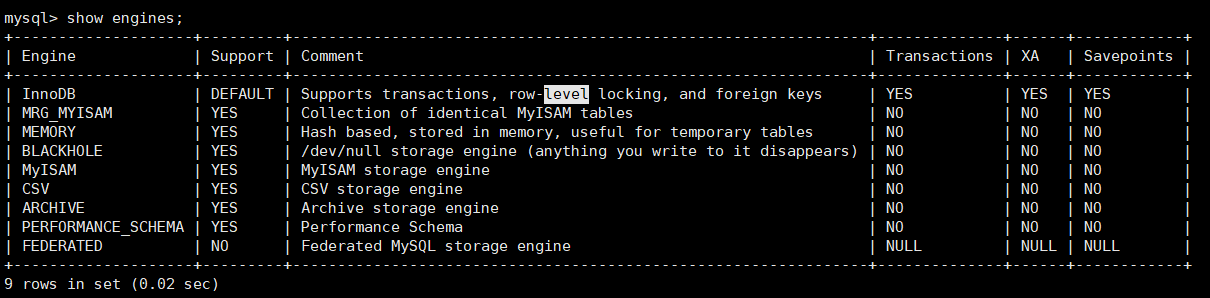
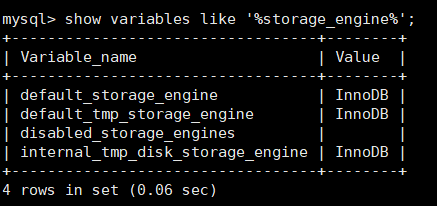
View the storage engine show engines;
View the current storage engine show variables like '% storage'_ engine%';
Comparison between MyISAM and InnoDB
| Comparison item | MyISAM | InnoDB |
|---|---|---|
| Main foreign key | I won't support it | support |
| affair | I won't support it | support |
| Row table lock | Table lock: even if one record is operated, the whole table will be locked, which is not suitable for high concurrency operations. | Row lock: only one row is locked during operation without affecting other rows. |
| cache | Only cache the index, not the real data | It not only caches indexes, but also caches real data, which requires high memory, and the memory size has a decisive impact on performance |
| Tablespace | Small | large |
| Focus | performance | affair |
MySQL execution loading order
sql statement
select distinct <select_list> from left_table <join_type> join right_table on <join_condition> where <where_condition> group by <group_by_list> having <having_condition> order by <order_by_conddition> limit <limit_num>
Order after MySQL server processing
from left_table on join_condition join_type join right_table where where_condition group by group_by_list having having_condition select distinct select_list order by order_by_condition limit limit_num
- First determine the table to query
- Then filter the data according to the where condition
- group by
- The having condition filters the data in each group
- Determine the fields to query
- Sort the found information
- Limit the amount of query data
Seven JOIN theories
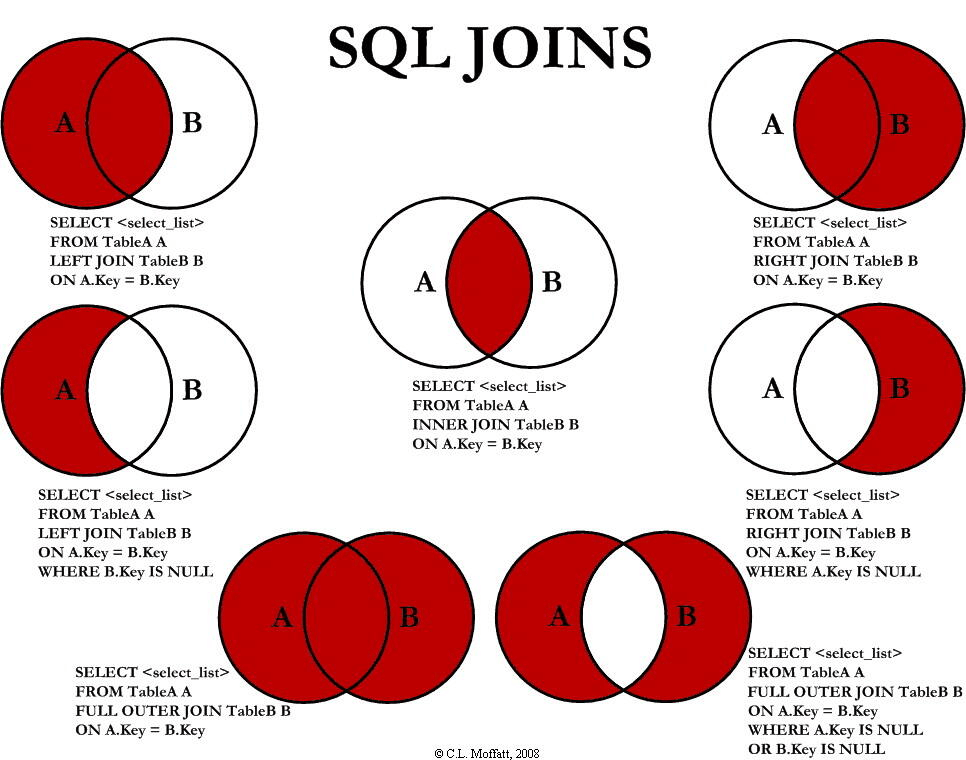
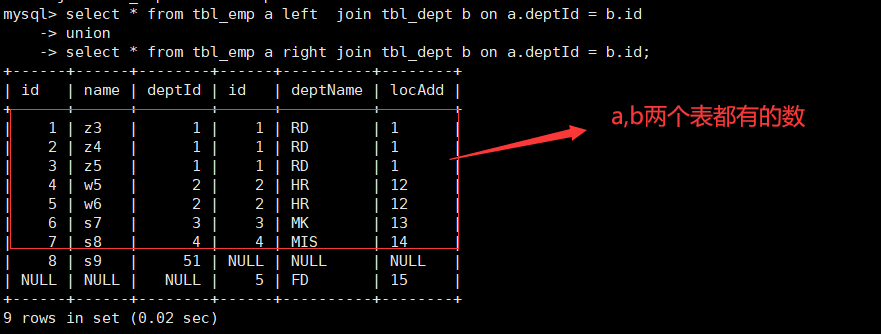
MySQL does not support full outer join. Here we can use union, which is used to merge the result sets of two or more SELECT statements.
The SELECT statement inside the UNION must have the same number of columns. Columns must also have similar data types. At the same time, the order of columns in each SELECT statement must be the same.
Indexes
What is the index
Index is a data structure that helps MySQL get data efficiently.
Sort + find
Objective: to improve the search efficiency, which can be compared with the dictionary.
Pros and cons
Advantages:
- Improve the data retrieval efficiency and reduce the IO cost of the database.
- Sort the data through the index column, reduce the sorting cost of data and reduce the consumption of CPU.
inferiority:
- The actual index is also a table, which saves the primary key and index fields and points to the records of the entity table, so the index also takes up space. Generally speaking, the space occupied by the index table is 1.5 times that of the data table.
- Although the index greatly improves the query speed, it also reduces the speed of updating the table.
classification
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (IMG enqfzwkl-1623663972304)( https://cdn.jsdelivr.net/gh/zhangliyuangit/img/ Index (1)] png)
Basic grammar
-
establish
CREATE [UNIQUE] INDEX indexName ON myTable(columnname(length));
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnname(length))
-
delete
DROP INDEX [indexName] ON myTable;
-
see
SHOW INDEX FROM tableName;
index structure
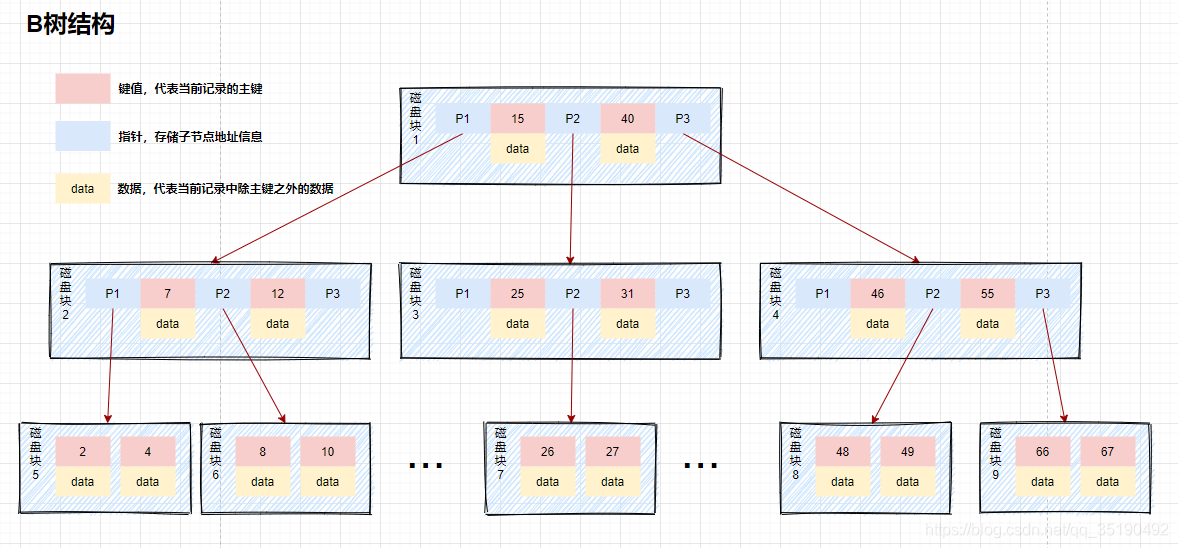
For example, the query data in b tree is as follows
Suppose we query data with a value equal to 10. Query path disk block 1 - > disk block 2 - > disk block 5.
First disk IO: load disk block 1 into memory, traverse and compare from the beginning in memory, 10 < 15, go left, and address disk block 2 to disk.
The second disk IO: load disk block 2 into memory, traverse and compare from scratch in memory, 7 < 10, address in disk and locate disk block 5.
The third disk IO: load the disk block 5 into the memory, traverse and compare from the beginning in the memory, 10 = 10, find 10, take out the data, if the row records stored in data, take out the data, and the query ends. If the disk address is stored, you also need to take the data from the disk according to the disk address, and the query is terminated.
You must think B tree is ideal when you see it here, but predecessors will tell you that there are still places to optimize:
-
B-tree does not support fast search of range query. If we want to find the data between 10 and 35, after finding 15, we need to go back to the root node and traverse the search again. We need to traverse from the root node many times, and the query efficiency needs to be improved.
-
If data stores row records, the size of rows will increase with the number of columns. At this time, the amount of data that can be stored in a page will become less, the tree will become higher, and the disk IO times will become larger.
B + tree: Transform B tree
B + tree, as an upgraded version of B tree, MySQL continues to transform on the basis of B tree and uses B + tree to build index. The main difference between B + tree and B tree is whether non leaf nodes store data
- B tree: both non leaf nodes and leaf nodes store data.
- B + tree: only leaf nodes can store data, and non leaf nodes can store key values. Leaf nodes are connected by two-way pointers, and the bottom leaf nodes form a two-way ordered linked list.
B + tree structure
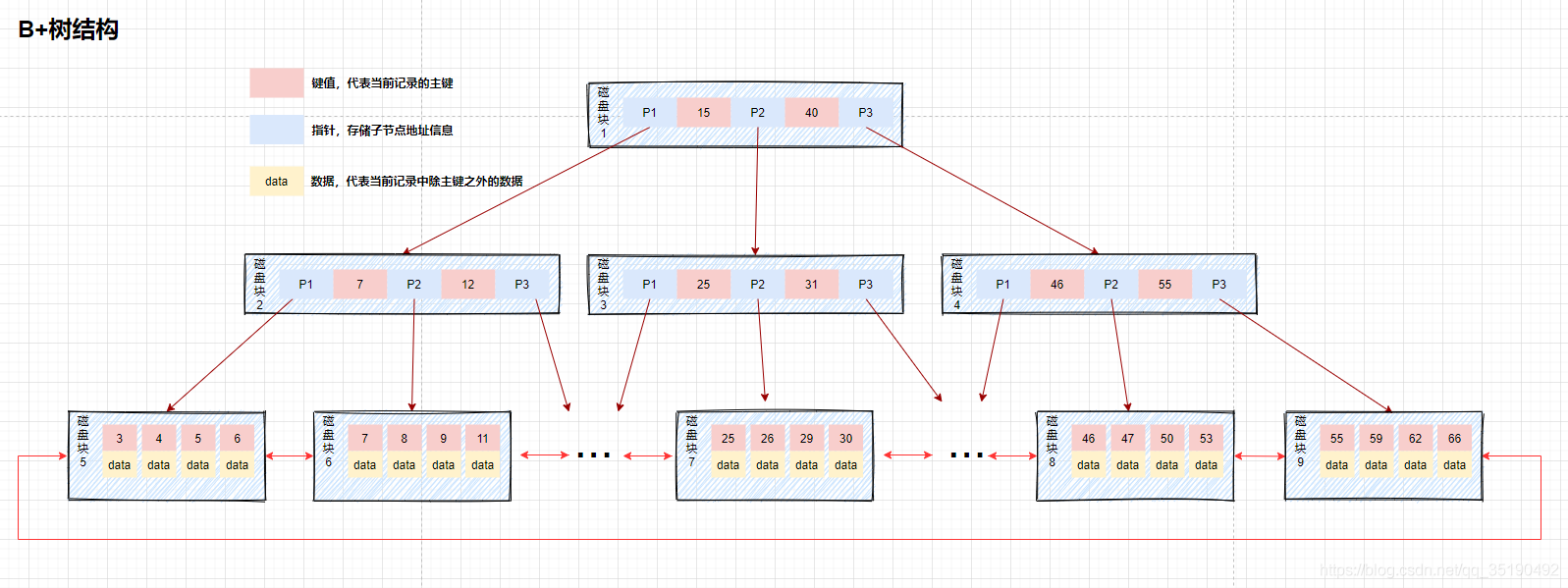
The lowest leaf node of B + tree contains all index entries. As can be seen from the figure, when the B + tree searches for data, because the data is stored on the bottom leaf node, it needs to retrieve the leaf node every time to query the data. Therefore, when the data needs to be queried, the IO of each disk is directly related to the tree height. On the other hand, since the data is placed in the leaf node, the number of indexes stored in the disk block lock of the index will increase with this. Therefore, compared with the B tree, the tree height of the B + tree is theoretically shorter than that of the B tree. There is also the case that the index overrides the query. The data in the index meets all the data required by the current query statement. At this time, you only need to find the index to return immediately without retrieving the lowest leaf node.
for instance:
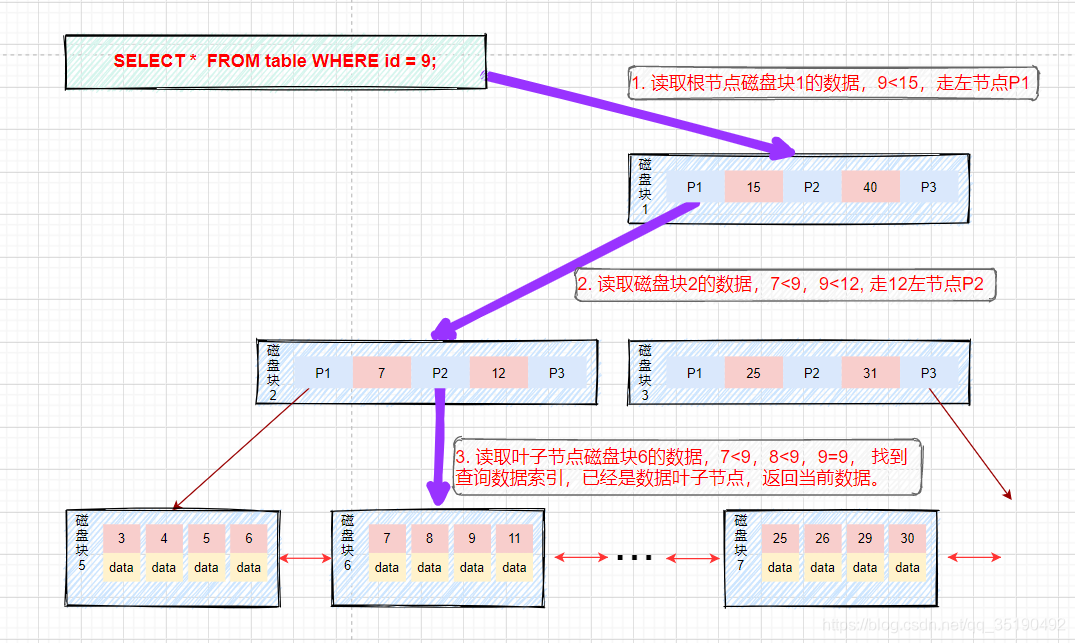
- Equivalent query:
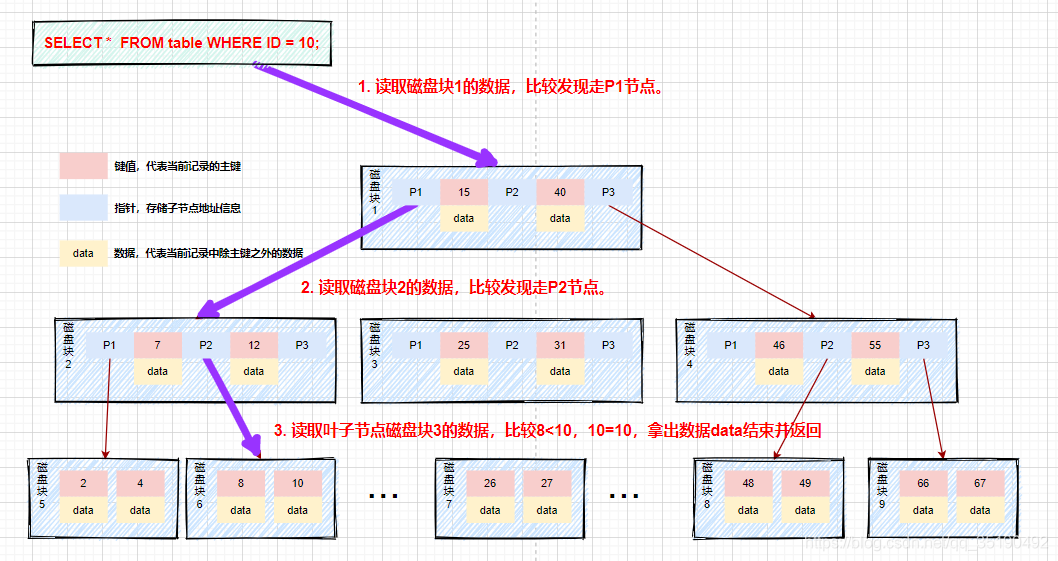
Suppose we query data with a value equal to 9. Query path disk block 1 - > disk block 2 - > disk block 6.
-
First disk IO: load disk block 1 into memory, traverse and compare from the beginning in memory, 9 < 15, go left, and address disk block 2 to disk.
-
The second disk IO: load disk block 2 into memory, traverse and compare from scratch in memory, 7 < 9 < 12, address and locate disk block 6 in disk.
-
The third disk IO: load disk block 6 into memory, traverse and compare from the beginning in memory, find 9 in the third index, and take out data. If the row records stored in data are taken out, take out data, and the query ends. If the disk address is stored, you also need to take the data from the disk according to the disk address, and the query is terminated. (what needs to be distinguished here is that the data stored in InnoDB is row data, while the disk address is stored in MyIsam.)
The process is shown in the figure below:
-
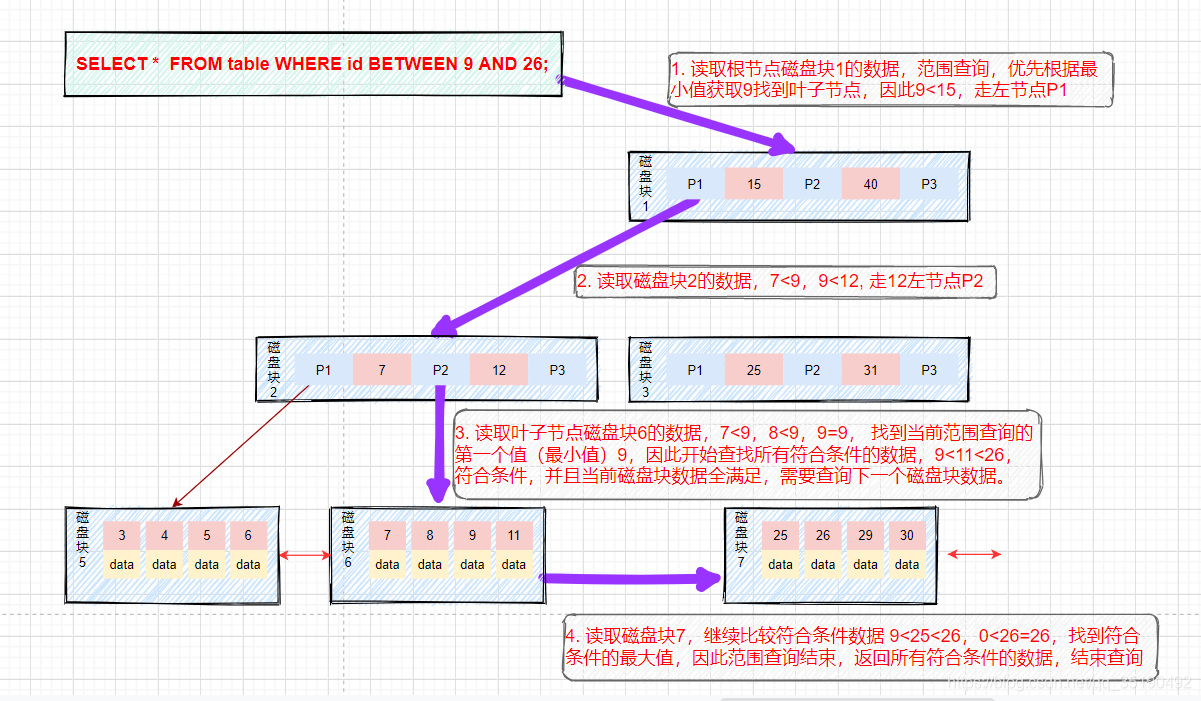
Range query:
Suppose we want to find data between 9 and 26. The lookup path is disk block 1 - > disk block 2 - > disk block 6 - > disk block 7.
-
First, find the data with a value equal to 9 and cache the data with a value equal to 9 into the result set. This is the same as the previous three steps of the IO process.
-
After finding 15, the underlying leaf node is a sequence table. We traverse backward from disk block 6 and key value 9 to filter all data that meet the filtering conditions.
-
The fourth disk IO: address and locate disk block 7 according to the subsequent pointer of disk 6, load disk 7 into memory, traverse and compare from scratch in memory, 9 < 25 < 26, 9 < 26 < = 26, and cache data into the result set.
-
The primary key is unique (there will be no data < = 26 behind it). There is no need to look back and the query is terminated. Returns the result set to the user.
It can be seen that B + tree can ensure the fast search of equivalence and range query. MySQL index adopts the data structure of B + tree.
Index applicability
Under what circumstances do you need to create an index
- The primary key automatically creates a unique index
- Fields frequently used as query criteria should be indexed
- The fields associated with other tables in the query are indexed by foreign key relationships
- Frequently updated fields are not suitable for creating fields
- For the sorted fields in the query, if the sorted fields are accessed through the index, the access and sorting speed will be greatly improved
- Statistics or grouped fields in query
performance analysis
MySQL Query Optimizer
- The optimizer module in MySQL is specially responsible for optimizing the SELECT statement. Its main function is to improve the optimal execution plan for the Query requested by the client by calculating and analyzing the system information collected in the system.
- When the client requests a Query from MySQL and commands the parser module to complete the request classification, distinguish it from SELECT and forward it to MySQL Query Optimizer, MySQL Query Optimizer will first optimize the whole Query and deal with the budget of some constant expressions. Then analyze the Hint information in the Query to see whether displaying the Hint information can completely determine the execution plan of the Query. If there is no Hint information or Hint information is not enough to completely determine the execution plan, the statistical information of the involved objects will be read, the corresponding calculation and analysis will be written according to Query, and then the final execution plan will be obtained.
Explain
What can I do?
- Read order of table
- Operation type of data read operation
- Which indexes can be used
- Which indexes are actually used
- Use between tables
- How many rows per table are queried by the optimizer
Information contained in the execution plan

id
The number of the id column is the serial number of the select. If there are several selections, there are several IDS, and the order of IDS increases in the order in which the select appears.
The larger the id column, the higher the execution priority. If the id is the same, it will be executed from top to bottom. If the id is NULL, it will be executed last
select_type
- Simple: simple query
- primary: if the query contains any complex sub query, the outermost layer is marked as paimary, commonly known as eggshell
- subquery: contains subqueries in the select or where list
- Derived: the sub queries contained in the from list are marked as derived. mysql will recursively execute these sub queries and put the results in the temporary table (the temporary table will increase the system burden, but sometimes it has to be used)
- Union: if the second select appears after union, it will be marked as union; If union is included in subquery of the from clause, outer select will be marked as: derived
- union result: the combination of two union results
type
From the best to the worst
system > const > eq_ Ref > ref > range > index > all (full table scan)
Generally speaking, it is necessary to ensure that the query reaches at least range level, preferably ref.
- System: the table only needs one row of records (equal to the system table). This is a special case of const type. It usually does not appear, and this can also be ignored
- const: it means that it can be found once through the index. const is used to compare the primary key or unique index. Because only one row of data is matched, mysql can quickly convert the query into a constant if the primary key is placed in the where list. explain select * from tbl_emp where id = 1;
- eq_ref: for each index key, only one piece of data in the table matches it. Common in primary key index or unique index.
- ref: non unique index. For the query of each index key, return all matching rows (can be 0, multiple) explain select * from tbl_emp where name = 'z3', there is an index on the name column.
- Range: retrieves the rows in the specified range. Where is a range query explain select * from tbl_emp where id in (1,2,3);
- index: query the data in all indexes. Usually faster than all explain select id from tbl_emp;
- all: full table scan.
possible_keys\key
possible_keys indicates which indexes may be used in the query.
key indicates which indexes are actually used,
Possible appears_ Keys has columns, but the key is NULL. This is because there is not much data in the table. MySQL thinks that the index is not helpful to this query, so it selects the full scan.
If possible_ If keys is NULL, there is no relevant index. In this case, you can improve query performance by checking the where clause to see if an appropriate index can be created.
key_len
Indicates the number of bytes used in the index. The length of the index used in the query can be calculated through this column. Without losing accuracy, the shorter the length, the better.
key_ The value displayed by Len is the maximum possible length of the index field, not the actual length, i.e. key_len is calculated according to the table definition, not retrieved from the table.
ref
This column shows the columns or constants used by the table to find the value in the index of the key record. The common ones are const (constant) and field name (example: t1.id)

rows
According to table statistics and index selection, roughly estimate the number of rows to read to find the required records.
EXtra
Extra column is used to explain some additional information. We can use this additional information to more accurately understand how MySQL executes a given query statement.
- using index: the query column is overwritten by the index, and the where filter condition is the leading column of the index, which is a performance of high performance. Generally, the overwriting index is used (the index contains all the query fields). For innodb, if it is a secondary index, the performance will be greatly improved.
- using where: when we use full scan to execute the query of a table, and there are search conditions for the table in the where clause of the statement.
- using filesort: indicates that MySQL will adapt to an external index sort for data. Instead of reading according to the index in the table, MySQL cannot use the index to complete the sorting operation, which is called "file sorting".
- using temporary: temporary tables are used to save intermediate results. mysql uses temporary tables when sorting query results. It is commonly used in sorting order by and grouping query group by.
- Cache connection: using buffer
- impossible where: the value of the where clause is always false and cannot be used to get any tuples
- select tables optimized away: if there is no group by clause, optimize Min and max operations based on the index or optimize count (*) for MyISAM storage engine. You don't have to wait until the execution stage to calculate. The optimization is completed at the stage of query execution plan generation.
- Distinct: optimize the distinct operation. Stop finding the same value after finding the first matching tuple.
Single table optimization case
Analog data
CREATE TABLE IF NOT EXISTS `article`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `author_id` INT (10) UNSIGNED NOT NULL, `category_id` INT(10) UNSIGNED NOT NULL , `views` INT(10) UNSIGNED NOT NULL , `comments` INT(10) UNSIGNED NOT NULL, `title` VARBINARY(255) NOT NULL, `content` TEXT NOT NULL ); INSERT INTO `article`(`author_id`,`category_id` ,`views` ,`comments` ,`title` ,`content` )VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (3,3,3,3,'3','3');
Query category_ If the ID is 1 and comments > 1, the most watched articles**
explain select id,author_id from article where category_id = 1 and comments > 1 order by views desc limit 1 --analysis sql

- type: all, full table scanning
- using filesort: internal sorting of files
optimization
Because the query uses three fields, we build a composite index on these three fields.
create index idx_article_ccv on article(category_id, comments, views);
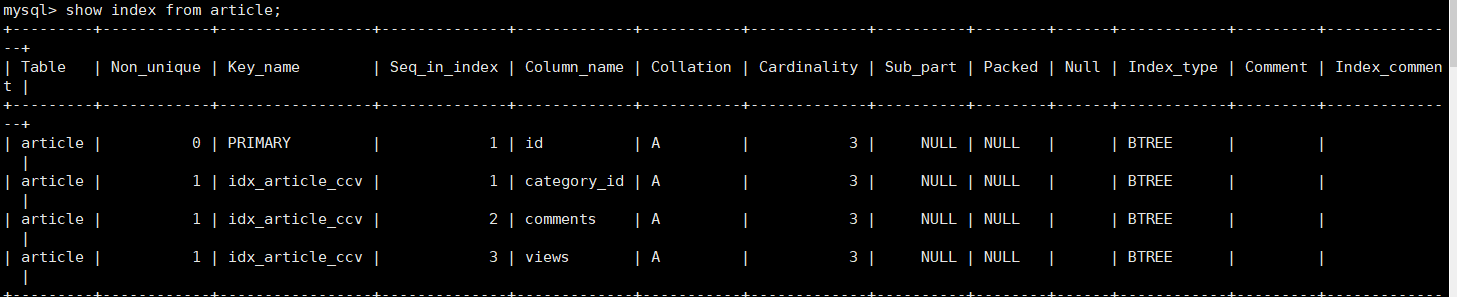
Review the execution plan again

Check if comments=3

type becomes range, which is tolerable. However, the using filesort used in extra is still unacceptable.
We've built an index. Why doesn't it work?
This is because the BTree index works.
Sort category first_ id
If the same category is encountered_ ID, then sort comments. If the same comments are encountered, then sort views,
When the comments field is in the middle of the union index,
Because comments > 1, the condition is a range value (so-called range)
MySQL cannot use the index to retrieve the following view part, that is, the index behind the field of range type is invalid.
Recreate index
create index idx_article_cv on article(category_id,views);
View execution plan

Perfect finish.
Double table optimization case
Analog data
CREATE TABLE IF NOT EXISTS `class`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL ); CREATE TABLE IF NOT EXISTS `book`( `bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL ); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
View execution plan
EXPLAIN SELECT * from class LEFT JOIN book ON class.card = book.card

optimization
-
Since it is a left join and the left table is the main table, the first attempt is to add an index to the left table.
create index idx_class_card on class (card);
Execute the plan again

Conclusion: Although the type changes to index, the number of rows scanned is still full table scanning.
-
Delete the left table index and create an index on the right table.
drop index idx_class_card on class; -- Delete index create index idx_book_card on book (card); -- Create index
Execute the plan again

Result: the type changes to ref, and only one row is scanned by rows.
Conclusion: This is due to the characteristics of LEFT JOIN. Since the left table has all the data, the key is that if you search from the right table, you must add an index to the right table.
Three table optimization case
Create a phone table based on the double table
CREATE TABLE IF NOT EXISTS `phone`( `phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL )ENGINE = INNODB; INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
The three tables are not indexed
EXPLAIN SELECT * from class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card

Conclusion: full table scanning and connection cache are used
Add an index to the phone and book tables
CREATE INDEX idx_phone_card ON phone(card) CREATE INDEX idx_book_card ON book (card) EXPLAIN SELECT * from class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card

summary
- Statement optimization should minimize the total number of NestedLoop loops in the join statement, that is, "always drive a large result set with a small result set".
- Give priority to optimizing the inner loop of NestedLoop.
- Try to ensure that the index is added to the condition field of the driven table in the join statement (that is, LEFT JOIN is added on the right table, and vice versa).
- When the condition field of the driven table cannot be indexed and the memory resources are sufficient, you may wish to adjust the join buffer to achieve the purpose of performance optimization.