Important knowledge points
-
Usage of generating formula (derivation)
prices = { 'AAPL': 191.88, 'GOOG': 1186.96, 'IBM': 149.24, 'ORCL': 48.44, 'ACN': 166.89, 'FB': 208.09, 'SYMC': 21.29 } # Construct a new dictionary with stocks with a stock price greater than 100 yuan prices2 = {key: value for key, value in prices.items() if value > 100} print(prices2)Description: generating formula (derivation) can be used to generate lists, sets and dictionaries.
-
Pit of nested list
names = ['Guan Yu', 'Fei Zhang', 'Zhao Yun', 'ma chao', 'Huang Zhong'] courses = ['language', 'mathematics', 'English'] # Enter the scores of five students in three courses # error - reference resources http://pythontutor.com/visualize.html#mode=edit # scores = [[None] * len(courses)] * len(names) scores = [[None] * len(courses) for _ in range(len(names))] for row, name in enumerate(names): for col, course in enumerate(courses): scores[row][col] = float(input(f'Please enter{name}of{course}achievement: ')) print(scores)Python Tutor - VISUALIZE CODE AND GET LIVE HELP
-
heapq module (heap sort)
""" Find the largest or smallest from the list N Elements Heap structure(Big root pile/Small root pile) """ import heapq list1 = [34, 25, 12, 99, 87, 63, 58, 78, 88, 92] list2 = [ {'name': 'IBM', 'shares': 100, 'price': 91.1}, {'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'FB', 'shares': 200, 'price': 21.09}, {'name': 'HPQ', 'shares': 35, 'price': 31.75}, {'name': 'YHOO', 'shares': 45, 'price': 16.35}, {'name': 'ACME', 'shares': 75, 'price': 115.65} ] print(heapq.nlargest(3, list1)) print(heapq.nsmallest(3, list1)) print(heapq.nlargest(2, list2, key=lambda x: x['price'])) print(heapq.nlargest(2, list2, key=lambda x: x['shares'])) -
itertools module
""" Iteration tool module """ import itertools # Generate full arrangement of ABCD itertools.permutations('ABCD') # Three out of five combinations that produce ABCDE itertools.combinations('ABCDE', 3) # Produces the Cartesian product of ABCD and 123 itertools.product('ABCD', '123') # Infinite cyclic sequence of generating ABC itertools.cycle(('A', 'B', 'C')) -
collections module
Common tools:
- namedtuple: Command tuple, which is a class factory that accepts the name of the type and the list of attributes to create a class.
- Deque: double ended queue, which is an alternative implementation of list. The bottom layer of the list in Python is based on arrays, while the bottom layer of deque is a two-way linked list. Therefore, when you need to add and delete elements at the beginning and end, deque will show better performance, and the asymptotic time complexity is O ( 1 ) O(1) O(1).
- Counter: subclass of dict. The key is the element, the value is the count of the element, and its most_ The common () method can help us get the most frequent elements. I think the inheritance relationship between counter and dict is debatable. According to the principle of car, the relationship between counter and dict should be designed as an association relationship, which is more reasonable.
- OrderedDict: subclass of dict, which records the insertion order of key value pairs. It seems that it has the behavior of both dictionary and linked list.
- defaultdict: similar to the dictionary type, but the default value corresponding to the key can be obtained through the default factory function. This method is more efficient than the setdefault() method in the dictionary.
""" Find the most frequent element in the sequence """ from collections import Counter words = [ 'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes', 'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into', 'my', 'eyes', "you're", 'under' ] counter = Counter(words) print(counter.most_common(3))
Data structure and algorithm
-
Algorithm: methods and steps to solve problems
-
Evaluate the quality of the algorithm: asymptotic time complexity and asymptotic space complexity.
-
Large O-markers for asymptotic time complexity:
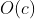 -Constant time complexity - bloom filter / hash storage
-Constant time complexity - bloom filter / hash storage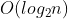 -Logarithmic time complexity - half search (binary search)
-Logarithmic time complexity - half search (binary search)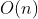 -Linear time complexity - sequential lookup / count sort
-Linear time complexity - sequential lookup / count sort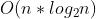 -Log linear time complexity - Advanced sorting algorithm (merge sorting, quick sorting)
-Log linear time complexity - Advanced sorting algorithm (merge sorting, quick sorting)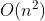 -Square time complexity - simple sorting algorithm (selection sorting, insertion sorting, bubble sorting)
-Square time complexity - simple sorting algorithm (selection sorting, insertion sorting, bubble sorting)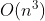 -Cubic time complexity - Floyd algorithm / matrix multiplication
-Cubic time complexity - Floyd algorithm / matrix multiplication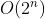 -Geometric series time complexity - Tower of Hanoi
-Geometric series time complexity - Tower of Hanoi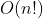 -Factorial time complexity - Travel dealer problem - NPC
-Factorial time complexity - Travel dealer problem - NPC
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-UbQQ6Uy6-1623374776792)(./res/algorithm_complexity_1.png)]
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-qSqVT0zN-1623374776796)(./res/algorithm_complexity_2.png)]
-
Sorting algorithm (selection, bubbling and merging) and search algorithm (order and half)
def select_sort(items, comp=lambda x, y: x < y): """Simple selection sort""" items = items[:] for i in range(len(items) - 1): min_index = i for j in range(i + 1, len(items)): if comp(items[j], items[min_index]): min_index = j items[i], items[min_index] = items[min_index], items[i] return itemsdef bubble_sort(items, comp=lambda x, y: x > y): """Bubble sorting""" items = items[:] for i in range(len(items) - 1): swapped = False for j in range(len(items) - 1 - i): if comp(items[j], items[j + 1]): items[j], items[j + 1] = items[j + 1], items[j] swapped = True if not swapped: break return itemsdef bubble_sort(items, comp=lambda x, y: x > y): """Stirring sequencing(Bubble sort upgrade)""" items = items[:] for i in range(len(items) - 1): swapped = False for j in range(len(items) - 1 - i): if comp(items[j], items[j + 1]): items[j], items[j + 1] = items[j + 1], items[j] swapped = True if swapped: swapped = False for j in range(len(items) - 2 - i, i, -1): if comp(items[j - 1], items[j]): items[j], items[j - 1] = items[j - 1], items[j] swapped = True if not swapped: break return itemsdef merge(items1, items2, comp=lambda x, y: x < y): """merge(Merge two ordered lists into one ordered list)""" items = [] index1, index2 = 0, 0 while index1 < len(items1) and index2 < len(items2): if comp(items1[index1], items2[index2]): items.append(items1[index1]) index1 += 1 else: items.append(items2[index2]) index2 += 1 items += items1[index1:] items += items2[index2:] return items def merge_sort(items, comp=lambda x, y: x < y): return _merge_sort(list(items), comp) def _merge_sort(items, comp): """Merge sort""" if len(items) < 2: return items mid = len(items) // 2 left = _merge_sort(items[:mid], comp) right = _merge_sort(items[mid:], comp) return merge(left, right, comp)def seq_search(items, key): """Sequential search""" for index, item in enumerate(items): if item == key: return index return -1def bin_search(items, key): """Half search""" start, end = 0, len(items) - 1 while start <= end: mid = (start + end) // 2 if key > items[mid]: start = mid + 1 elif key < items[mid]: end = mid - 1 else: return mid return -1 -
Common algorithms:
- Exhaustive method - also known as brute force cracking method, verifies all possibilities until the correct answer is found.
- Greedy method - when solving a problem, always make a decision in the current view
- The best choice is to find a satisfactory solution quickly without pursuing the optimal solution.
- Divide and Conquer - divide a complex problem into two or more identical or similar subproblems, then divide the subproblem into smaller subproblems until it can be solved directly, and finally merge the solutions of the subproblems to obtain the solution of the original problem.
- Backtracking method - backtracking method, also known as heuristic method, searches forward according to the optimization conditions. When it finds that the original selection is not excellent or fails to achieve the goal, it will go back to one step and choose again.
- Dynamic programming - the basic idea is to decompose the problem to be solved into several sub problems, solve and save the solutions of these sub problems first, so as to avoid a large number of repeated operations.
Examples of exhaustive method: 100 yuan, 100 chickens and five people share fish.
# A rooster is 5 yuan, a hen is 3 yuan, a chick is 1 yuan and three # Buy 100 chickens for 100 yuan and ask how many cocks / hens / chicks each for x in range(20): for y in range(33): z = 100 - x - y if 5 * x + 3 * y + z // 3 == 100 and z % 3 == 0: print(x, y, z) # A. B, C, D and E were fishing together one night, and finally they were tired and went to bed # The next day A woke up first. He divided the fish into five parts, threw away the extra one and took one of his own # B the second one wakes up and divides the fish into five parts. Throw away the extra one and take one of his own # Then C, D and E wake up in turn and divide the fish in the same way. Ask them how many fish they have caught at least fish = 6 while True: total = fish enough = True for _ in range(5): if (total - 1) % 5 == 0: total = (total - 1) // 5 * 4 else: enough = False break if enough: print(fish) break fish += 5Example of greedy method: suppose the thief has a backpack that can hold up to 20 kilograms of stolen goods. He breaks into a house and finds the items shown in the table below. Obviously, he can't put all his items in his backpack, so he must determine what items to take away and what items to leave behind.
name Price (USD) Weight (kg) computer 200 20 radio 20 4 clock 175 10 vase 50 2 book 10 1 Oil Painting 90 9 """ Greedy method: when solving problems, we always make the best choice at present, do not pursue the optimal solution, and quickly find a satisfactory solution. Input: 20 6 Computer 200 20 Radio 20 4 Clock 175 10 Vase 50 2 Book 10 1 Oil painting 90 9 """ class Thing(object): """goods""" def __init__(self, name, price, weight): self.name = name self.price = price self.weight = weight @property def value(self): """Price weight ratio""" return self.price / self.weight def input_thing(): """Enter item information""" name_str, price_str, weight_str = input().split() return name_str, int(price_str), int(weight_str) def main(): """Main function""" max_weight, num_of_things = map(int, input().split()) all_things = [] for _ in range(num_of_things): all_things.append(Thing(*input_thing())) all_things.sort(key=lambda x: x.value, reverse=True) total_weight = 0 total_price = 0 for thing in all_things: if total_weight + thing.weight <= max_weight: print(f'The thief took it{thing.name}') total_weight += thing.weight total_price += thing.price print(f'Total value: {total_price}dollar') if __name__ == '__main__': main()Examples of divide and Conquer: Quick sort.
""" Quick sort - Select the pivot to divide the elements. The left is smaller than the pivot and the right is larger than the pivot """ def quick_sort(items, comp=lambda x, y: x <= y): items = list(items)[:] _quick_sort(items, 0, len(items) - 1, comp) return items def _quick_sort(items, start, end, comp): if start < end: pos = _partition(items, start, end, comp) _quick_sort(items, start, pos - 1, comp) _quick_sort(items, pos + 1, end, comp) def _partition(items, start, end, comp): pivot = items[end] i = start - 1 for j in range(start, end): if comp(items[j], pivot): i += 1 items[i], items[j] = items[j], items[i] items[i + 1], items[end] = items[end], items[i + 1] return i + 1Example of backtracking method: Knight patrol.
""" Recursive backtracking method: it is called heuristic method. It searches forward according to the optimization conditions. When it is found that the original selection is not excellent or cannot reach the goal, it will go back and choose again. The more classic problems include Knight patrol, eight queens and maze pathfinding. """ import sys import time SIZE = 5 total = 0 def print_board(board): for row in board: for col in row: print(str(col).center(4), end='') print() def patrol(board, row, col, step=1): if row >= 0 and row < SIZE and \ col >= 0 and col < SIZE and \ board[row][col] == 0: board[row][col] = step if step == SIZE * SIZE: global total total += 1 print(f'The first{total}Walking method: ') print_board(board) patrol(board, row - 2, col - 1, step + 1) patrol(board, row - 1, col - 2, step + 1) patrol(board, row + 1, col - 2, step + 1) patrol(board, row + 2, col - 1, step + 1) patrol(board, row + 2, col + 1, step + 1) patrol(board, row + 1, col + 2, step + 1) patrol(board, row - 1, col + 2, step + 1) patrol(board, row - 2, col + 1, step + 1) board[row][col] = 0 def main(): board = [[0] * SIZE for _ in range(SIZE)] patrol(board, SIZE - 1, SIZE - 1) if __name__ == '__main__': main()Dynamic programming example: the maximum value of the sum of sub list elements.
Note: sublist refers to the list composed of continuous index (subscript) elements in the list; The elements in the list are of type int and may contain positive integers, 0 and negative integers; The program inputs the elements in the list and outputs the maximum sum value of the elements in the sub list, for example:
Input: 1 - 2 3 5 - 3 2
Output: 8
Input: 0 - 2 3 5 - 1 2
Output: 9
Input: - 9 - 2 - 3 - 5 - 3
Output: - 2
def main(): items = list(map(int, input().split())) overall = partial = items[0] for i in range(1, len(items)): partial = max(items[i], partial + items[i]) overall = max(partial, overall) print(overall) if __name__ == '__main__': main()Note: the easiest solution to this problem is to use double loops, but the time performance of the code will become very bad. Using the idea of dynamic programming, only two more variables are used O ( N 2 ) O(N^2) The problem of O(N2) complexity becomes O ( N ) O(N) O(N).
How functions are used
-
Treat functions as "first class citizens"
- Functions can be assigned to variables
- Functions can be used as arguments to functions
- Function can be used as the return value of a function
-
Usage of higher-order functions (filter, map and their substitutes)
items1 = list(map(lambda x: x ** 2, filter(lambda x: x % 2, range(1, 10)))) items2 = [x ** 2 for x in range(1, 10) if x % 2]
-
Location parameter, variable parameter, keyword parameter, named keyword parameter
-
Meta information of parameters (code readability problem)
-
Usage of anonymous and inline functions (lambda function)
-
Closure and scope issues
-
LEGB order of Python search variables (local > > > embedded > > > Global > > > build in)
-
Role of global and nonlocal keywords
Global: declare or define global variables (either directly use the variables of the existing global scope, or define a variable into the global scope).
nonlocal: declare a variable using nested scope (the variable must exist in nested scope, otherwise an error will be reported).
-
-
Decorator function (use decorator and cancel decorator)
Example: decorator that outputs function execution time.
def record_time(func): """Decorator for custom decorating function""" @wraps(func) def wrapper(*args, **kwargs): start = time() result = func(*args, **kwargs) print(f'{func.__name__}: {time() - start}second') return result return wrapperIf the decorator does not want to be coupled with the print function, you can write a decorator that can be parameterized.
from functools import wraps from time import time def record(output): """Decorator that can be parameterized""" def decorate(func): @wraps(func) def wrapper(*args, **kwargs): start = time() result = func(*args, **kwargs) output(func.__name__, time() - start) return result return wrapper return decoratefrom functools import wraps from time import time class Record(): """Define decorators by defining classes""" def __init__(self, output): self.output = output def __call__(self, func): @wraps(func) def wrapper(*args, **kwargs): start = time() result = func(*args, **kwargs) self.output(func.__name__, time() - start) return result return wrapperNote: since the @ wraps decorator is added to the function with decoration function, you can use func__ wrapped__ Method to get the function or class before being decorated to cancel the function of the decorator.
Example: use decorator to implement singleton mode.
from functools import wraps def singleton(cls): """Decorative ornament""" instances = {} @wraps(cls) def wrapper(*args, **kwargs): if cls not in instances: instances[cls] = cls(*args, **kwargs) return instances[cls] return wrapper @singleton class President: """president(Singleton class)""" passTip: the above code uses closure s. I don't know if you have realized it. There is no small problem that the above code does not implement a thread safe singleton. What should I do if I want to implement a thread safe singleton?
Thread safe singleton decorator.
from functools import wraps from threading import RLock def singleton(cls): """Thread safe singleton decorator""" instances = {} locker = RLock() @wraps(cls) def wrapper(*args, **kwargs): if cls not in instances: with locker: if cls not in instances: instances[cls] = cls(*args, **kwargs) return instances[cls] return wrapperTip: the above code uses the with context syntax for lock operation, because the lock object itself is the context manager object (supports _ enter and _ exit magic methods). In the wrapper function, we first check without a lock, and then check with a lock. This is better than the direct lock check. If the object has been created, we don't have to lock it, but just return it directly.
Object oriented knowledge
-
Three pillars: encapsulation, inheritance and polymorphism
Example: salary settlement system.
""" Monthly salary settlement system - Department Manager 15000 programmers per month 200 salesmen per hour 1800 base salary plus sales 5%Commission """ from abc import ABCMeta, abstractmethod class Employee(metaclass=ABCMeta): """staff(abstract class)""" def __init__(self, name): self.name = name @abstractmethod def get_salary(self): """Settle monthly salary(Abstract method)""" pass class Manager(Employee): """division manager""" def get_salary(self): return 15000.0 class Programmer(Employee): """programmer""" def __init__(self, name, working_hour=0): self.working_hour = working_hour super().__init__(name) def get_salary(self): return 200.0 * self.working_hour class Salesman(Employee): """salesperson""" def __init__(self, name, sales=0.0): self.sales = sales super().__init__(name) def get_salary(self): return 1800.0 + self.sales * 0.05 class EmployeeFactory: """Create a factory for employees (factory mode) - Decoupling between object users and objects through factories)""" @staticmethod def create(emp_type, *args, **kwargs): """Create employee""" all_emp_types = {'M': Manager, 'P': Programmer, 'S': Salesman} cls = all_emp_types[emp_type.upper()] return cls(*args, **kwargs) if cls else None def main(): """Main function""" emps = [ EmployeeFactory.create('M', 'Cao Cao'), EmployeeFactory.create('P', 'Xun Yu', 120), EmployeeFactory.create('P', 'Guo Jia', 85), EmployeeFactory.create('S', 'Dianwei', 123000), ] for emp in emps: print(f'{emp.name}: {emp.get_salary():.2f}element') if __name__ == '__main__': main() -
Relationship between classes
- is-a relationship: Inheritance
- has-a relationship: Association / aggregation / composition
- use-a relationship: dependency
Example: poker game.
""" Experience: symbolic constants are always better than literal constants, and enumeration types are the best choice for defining symbolic constants """ from enum import Enum, unique import random @unique class Suite(Enum): """Decor""" SPADE, HEART, CLUB, DIAMOND = range(4) def __lt__(self, other): return self.value < other.value class Card(): """brand""" def __init__(self, suite, face): """Initialization method""" self.suite = suite self.face = face def show(self): """Display board""" suites = ['♠︎', '♥︎', '♣︎', '♦︎'] faces = ['', 'A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K'] return f'{suites[self.suite.value]}{faces[self.face]}' def __repr__(self): return self.show() class Poker(): """poker""" def __init__(self): self.index = 0 self.cards = [Card(suite, face) for suite in Suite for face in range(1, 14)] def shuffle(self): """Shuffle (random disorder)""" random.shuffle(self.cards) self.index = 0 def deal(self): """Licensing""" card = self.cards[self.index] self.index += 1 return card @property def has_more(self): return self.index < len(self.cards) class Player(): """game player""" def __init__(self, name): self.name = name self.cards = [] def get_one(self, card): """Touch a card""" self.cards.append(card) def sort(self, comp=lambda card: (card.suite, card.face)): """Tidy up your cards""" self.cards.sort(key=comp) def main(): """Main function""" poker = Poker() poker.shuffle() players = [Player('East evil'), Player('Western poison'), Player('South Emperor'), Player('Northern beggar')] while poker.has_more: for player in players: player.get_one(poker.deal()) for player in players: player.sort() print(player.name, end=': ') print(player.cards) if __name__ == '__main__': main()Note: Emoji character is used in the above code to represent the four colors of playing cards, which may not be displayed on some systems that do not support Emoji character.
-
Replication of objects (deep copy / deep copy / deep clone and shallow copy / shallow copy / shadow clone)
-
Garbage collection, circular references, and weak references
Python uses automatic memory management. This management mechanism is based on reference counting. At the same time, it also introduces the strategies of mark clear and generational collection.
typedef struct _object { /* Reference count */ int ob_refcnt; /* Object pointer */ struct _typeobject *ob_type; } PyObject;/* Macro definition for increasing reference count */ #define Py_INCREF(op) ((op)->ob_refcnt++) /* Macro definition for reducing reference count */ #define Py_ Decrease (OP) \ / / decrease count if (--(op)->ob_refcnt != 0) \ ; \ else \ __Py_Dealloc((PyObject *)(op))Conditions that result in a reference count of + 1:
- The object is created, for example, a = 23
- Object is referenced, e.g. b = a
- Object is passed as a parameter into a function, such as f(a)
- Object is stored in a container as an element, for example list1 = [a, a]
Condition causing reference count - 1:
- The alias of the object is explicitly destroyed, such as del a
- The alias of the object is given to the new object, for example, a = 24
- An object leaves its scope. For example, when the f function is completed, the local variable (global variable) in the f function will not be changed
- The container in which the object is located is destroyed or the object is deleted from the container
Reference counting can cause circular reference problems, which can lead to memory leaks, as shown in the following code. To solve this problem, Python has introduced "mark clear" and "generational collection". When creating an object, the object is placed in the first generation. If the object survives in the garbage inspection of the first generation, the object will be placed in the second generation. Similarly, if the object survives in the garbage inspection of the second generation, the object will be placed in the third generation.
# Circular references can lead to memory leaks - Python introduces tag cleaning and generational recycling in addition to reference technology # Before Python 3.6, if rewritten__ del__ The magic method will invalidate the circular reference processing # If you don't want to cause circular references, you can use weak references list1 = [] list2 = [] list1.append(list2) list2.append(list1)
The following conditions can lead to garbage collection:
- Call GC collect()
- The counter of gc module has reached the threshold
- Program exit
If both objects in the circular reference are defined__ del__ Method, the gc module will not destroy these unreachable objects, because the gc module does not know which object should be called first__ del__ Method, which is solved in Python 3.6.
You can also solve the problem of circular reference by constructing weak reference in weakref module.
-
Magic attributes and methods (please refer to the Python magic method Guide)
There are a few small questions for you to think about:
- Can a user-defined object be operated with an operator?
- Can custom objects be put into set? Can you remove the weight?
- Can a custom object be used as the key of dict?
- Can custom objects use context syntax?
-
Mix in
Example: user defined dictionary limits that key value pairs can be set in the dictionary only when the specified key does not exist.
class SetOnceMappingMixin: """Custom blend class""" __slots__ = () def __setitem__(self, key, value): if key in self: raise KeyError(str(key) + ' already set') return super().__setitem__(key, value) class SetOnceDict(SetOnceMappingMixin, dict): """Custom dictionary""" pass my_dict= SetOnceDict() try: my_dict['username'] = 'jackfrued' my_dict['username'] = 'hellokitty' except KeyError: pass print(my_dict) -
Metaprogramming and metaclasses
Objects are created through classes, and classes are created through metaclasses, which provide meta information for creating classes. All classes are directly or indirectly inherited from object, and all metaclasses are directly or indirectly inherited from type.
Example: using metaclasses to implement singleton mode.
import threading class SingletonMeta(type): """Custom metaclass""" def __init__(cls, *args, **kwargs): cls.__instance = None cls.__lock = threading.RLock() super().__init__(*args, **kwargs) def __call__(cls, *args, **kwargs): if cls.__instance is None: with cls.__lock: if cls.__instance is None: cls.__instance = super().__call__(*args, **kwargs) return cls.__instance class President(metaclass=SingletonMeta): """president(Singleton class)""" pass -
Object oriented design principles
- Single responsibility principle (SRP) - a class does only what it should do (class design should be highly cohesive)
- Open close principle (OCP) - software entities should turn off extension development and modification
- Dependency Inversion Principle (DIP) - oriented Abstract Programming (weakened in weakly typed languages)
- Richter substitution principle (LSP) - you can replace parent objects with child objects at any time
- Interface isolation principle (ISP) - interfaces should be small but specialized rather than large and complete (there is no concept of interface in Python)
- Composite aggregation Reuse Principle (CARP) - reuse code with strong correlation rather than inheritance
- The principle of least knowledge (Dimitri's law, LoD) - do not send messages to objects that are not necessarily connected
Note: the bold letters above are called the object-oriented SOLID principle.
-
GoF design pattern
- Creation mode: single instance, factory, builder, prototype
- Structural mode: adapter, facade (appearance), agent
- Behavioral patterns: iterators, observers, States, strategies
Example: pluggable hash algorithm (policy mode).
class StreamHasher(): """Hash summarizer""" def __init__(self, alg='md5', size=4096): self.size = size alg = alg.lower() self.hasher = getattr(__import__('hashlib'), alg.lower())() def __call__(self, stream): return self.to_digest(stream) def to_digest(self, stream): """Generate a summary in hexadecimal form""" for buf in iter(lambda: stream.read(self.size), b''): self.hasher.update(buf) return self.hasher.hexdigest() def main(): """Main function""" hasher1 = StreamHasher() with open('Python-3.7.6.tgz', 'rb') as stream: print(hasher1.to_digest(stream)) hasher2 = StreamHasher('sha1') with open('Python-3.7.6.tgz', 'rb') as stream: print(hasher2(stream)) if __name__ == '__main__': main()
Iterators and generators
-
The object iterator implements the protocol iterator.
- There are no keywords in Python that define protocols such as protocol or interface.
- The protocol is represented by magic in Python.
- __ iter__ And__ next__ The magic method is the iterator protocol.
class Fib(object): """iterator """ def __init__(self, num): self.num = num self.a, self.b = 0, 1 self.idx = 0 def __iter__(self): return self def __next__(self): if self.idx < self.num: self.a, self.b = self.b, self.a + self.b self.idx += 1 return self.a raise StopIteration() -
Generators are syntactically simplified versions of iterators.
def fib(num): """generator """ a, b = 0, 1 for _ in range(num): a, b = b, a + b yield a -
Generators evolve into co processes.
The generator object can send data using the send() method, and the sent data will become the value obtained through the yield expression in the generator function. In this way, the generator can be used as a collaborative process, which is simply a subroutine that can cooperate with each other.
def calc_avg(): """Flow calculation average""" total, counter = 0, 0 avg_value = None while True: value = yield avg_value total, counter = total + value, counter + 1 avg_value = total / counter gen = calc_avg() next(gen) print(gen.send(10)) print(gen.send(20)) print(gen.send(30))
Concurrent programming
There are three schemes to realize concurrent programming in Python: multithreading, multi process and asynchronous I/O. The advantage of concurrent programming is that it can improve the execution efficiency of the program and improve the user experience; The disadvantage is that concurrent programs are not easy to develop and debug, and it is not friendly to other programs.
-
Multithreading: Python provides the Thread class, supplemented by Lock, Condition, Event, Semaphore and Barrier. Python has GIL to prevent multiple threads from executing local bytecode at the same time. This Lock is necessary for CPython, because CPython's memory management is not Thread safe, and because of GIL, multithreading cannot give play to the multi-core characteristics of CPU.
""" Interview question: the difference and connection between process and thread? process - The basic unit of memory allocated by the operating system - A process can contain one or more threads thread - Operating system allocation CPU Basic unit of Concurrent programming( concurrent programming) 1. Improve execution performance - So that the non causal part of the program can be executed concurrently 2. Improve user experience - So that the time-consuming operation will not cause the fake death of the program """ import glob import os import threading from PIL import Image PREFIX = 'thumbnails' def generate_thumbnail(infile, size, format='PNG'): """Generates thumbnails of the specified picture file""" file, ext = os.path.splitext(infile) file = file[file.rfind('/') + 1:] outfile = f'{PREFIX}/{file}_{size[0]}_{size[1]}.{ext}' img = Image.open(infile) img.thumbnail(size, Image.ANTIALIAS) img.save(outfile, format) def main(): """Main function""" if not os.path.exists(PREFIX): os.mkdir(PREFIX) for infile in glob.glob('images/*.png'): for size in (32, 64, 128): # Create and start a thread threading.Thread( target=generate_thumbnail, args=(infile, (size, size)) ).start() if __name__ == '__main__': main()Multiple threads compete for resources.
""" Multithreaded programs are usually easier to handle if they do not compete for resources When multiple threads compete for critical resources, the lack of necessary protection measures will lead to data disorder Note: critical resources are resources competed by multiple threads """ import time import threading from concurrent.futures import ThreadPoolExecutor class Account(object): """bank account""" def __init__(self): self.balance = 0.0 self.lock = threading.Lock() def deposit(self, money): # Protect critical resources through locks with self.lock: new_balance = self.balance + money time.sleep(0.001) self.balance = new_balance class AddMoneyThread(threading.Thread): """Custom thread class""" def __init__(self, account, money): self.account = account self.money = money # The initialization method of the parent class must be called in the initialization method of the custom thread super().__init__() def run(self): # Actions to be performed after the thread starts self.account.deposit(self.money) def main(): """Main function""" account = Account() # Create thread pool pool = ThreadPoolExecutor(max_workers=10) futures = [] for _ in range(100): # The first way to create a thread # threading.Thread( # target=account.deposit, args=(1, ) # ).start() # The second way to create a thread # AddMoneyThread(account, 1).start() # The third way to create a thread # Call threads in the thread pool to perform specific tasks future = pool.submit(account.deposit, 1) futures.append(future) # Close thread pool pool.shutdown() for future in futures: future.result() print(account.balance) if __name__ == '__main__': main()Modify the above program, start five threads to deposit money into the account, and five threads withdraw money from the account. When withdrawing money, if the balance is insufficient, pause the thread to wait. In order to achieve the above objectives, it is necessary to schedule the threads of saving and withdrawing money. When the balance is insufficient, the thread of withdrawing money pauses and releases the lock. After the thread of saving money deposits the money, it should notify the thread of withdrawing money to wake it up from the suspended state. The Condition of threading module can be used to realize thread scheduling. The object is also created based on lock. The code is as follows:
""" Multiple threads compete for a resource - Protect critical resources - Lock( Lock/RLock) Multiple threads compete for multiple resources (number of threads)>Number of resources) - Semaphore( Semaphore) Scheduling of multiple threads - Pause thread execution/Wake up waiting threads - Condition """ from concurrent.futures import ThreadPoolExecutor from random import randint from time import sleep import threading class Account: """bank account""" def __init__(self, balance=0): self.balance = balance lock = threading.RLock() self.condition = threading.Condition(lock) def withdraw(self, money): """Withdraw money""" with self.condition: while money > self.balance: self.condition.wait() new_balance = self.balance - money sleep(0.001) self.balance = new_balance def deposit(self, money): """save money""" with self.condition: new_balance = self.balance + money sleep(0.001) self.balance = new_balance self.condition.notify_all() def add_money(account): while True: money = randint(5, 10) account.deposit(money) print(threading.current_thread().name, ':', money, '====>', account.balance) sleep(0.5) def sub_money(account): while True: money = randint(10, 30) account.withdraw(money) print(threading.current_thread().name, ':', money, '<====', account.balance) sleep(1) def main(): account = Account() with ThreadPoolExecutor(max_workers=15) as pool: for _ in range(5): pool.submit(add_money, account) for _ in range(10): pool.submit(sub_money, account) if __name__ == '__main__': main() -
Multi Process: multi Process can effectively solve the problem of GIL. The main class to realize multi Process is Process. Other auxiliary classes are similar to those in threading module. Pipes, sockets, etc. can be used to share data between processes. There is a Queue class in multiprocessing module, which provides a Queue shared by multiple processes based on pipes and locking mechanism. The following is an example of multiple processes and Process pools in the official documentation.
""" Use of multiple processes and process pools Multithreading because GIL The existence of can not play a role CPU Multi-core characteristics of For computationally intensive tasks, you should consider using multiple processes time python3 example22.py real 0m11.512s user 0m39.319s sys 0m0.169s After using multiple processes, the actual execution time is 11.512 Seconds, while user time 39.319 Seconds is about 4 times the actual execution time This proves that our program is used through multiple processes CPU And this computer is configured with a 4-core CPU """ import concurrent.futures import math PRIMES = [ 1116281, 1297337, 104395303, 472882027, 533000389, 817504243, 982451653, 112272535095293, 112582705942171, 112272535095293, 115280095190773, 115797848077099, 1099726899285419 ] * 5 def is_prime(n): """Judgement prime""" if n % 2 == 0: return False sqrt_n = int(math.floor(math.sqrt(n))) for i in range(3, sqrt_n + 1, 2): if n % i == 0: return False return True def main(): """Main function""" with concurrent.futures.ProcessPoolExecutor() as executor: for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)): print('%d is prime: %s' % (number, prime)) if __name__ == '__main__': main()Key points: comparison between multithreading and multiprocessing.
Multithreading is required in the following cases:
- Programs need to maintain many shared states (especially variable states). Lists, dictionaries and collections in Python are thread safe, so the cost of using threads instead of processes to maintain shared states is relatively small.
- The program will spend a lot of time on I/O operation. There is not much need for parallel computing and does not need to occupy too much memory.
Multiple processes are required for the following situations:
- The program performs computing intensive tasks (such as bytecode operation, data processing, scientific computing).
- The input of the program can be divided into blocks in parallel, and the operation results can be combined.
- The program has no restrictions on memory usage and does not rely strongly on I/O operations (such as reading and writing files, sockets, etc.).
-
Asynchronous processing: select tasks from the task queue of the scheduler. The scheduler executes these tasks in a cross form. We cannot guarantee that the tasks will be executed in a certain order, because the execution order depends on whether one task in the queue is willing to give up CPU processing time to another task. Asynchronous tasks are usually implemented through multi task collaborative processing. Due to the uncertainty of execution time and order, it is necessary to obtain the execution results of tasks through callback programming or future objects. Python 3 supports asynchronous processing through the asyncio module and await and async keywords (officially listed as keywords in Python 3.7).
""" asynchronous I/O - async / await """ import asyncio def num_generator(m, n): """Number generator for specified range""" yield from range(m, n + 1) async def prime_filter(m, n): """Prime Number Sieves """ primes = [] for i in num_generator(m, n): flag = True for j in range(2, int(i ** 0.5 + 1)): if i % j == 0: flag = False break if flag: print('Prime =>', i) primes.append(i) await asyncio.sleep(0.001) return tuple(primes) async def square_mapper(m, n): """Square mapper""" squares = [] for i in num_generator(m, n): print('Square =>', i * i) squares.append(i * i) await asyncio.sleep(0.001) return squares def main(): """Main function""" loop = asyncio.get_event_loop() future = asyncio.gather(prime_filter(2, 100), square_mapper(1, 100)) future.add_done_callback(lambda x: print(x.result())) loop.run_until_complete(future) loop.close() if __name__ == '__main__': main()Note: the above code uses get_ event_ The loop function obtains the default event loop of the system. A future object and the add of the future object can be obtained through the gather function_ done_ Callback can add the callback function at the completion of execution, and the run of loop object_ until_ The complete method can wait for the execution result of the collaboration to be obtained through the future object.
Python has a third-party library called aiohttp, which provides asynchronous HTTP client and server. This third-party library can work with asyncio module and provide support for Future objects. async and await are introduced in Python 3.6 to define functions executed asynchronously and create asynchronous context. They have officially become keywords in Python 3.7. The following code asynchronously obtains the page from five URL s and extracts the title of the website through the named capture group of regular expression.
import asyncio import re import aiohttp PATTERN = re.compile(r'\<title\>(?P<title>.*)\<\/title\>') async def fetch_page(session, url): async with session.get(url, ssl=False) as resp: return await resp.text() async def show_title(url): async with aiohttp.ClientSession() as session: html = await fetch_page(session, url) print(PATTERN.search(html).group('title')) def main(): urls = ('https://www.python.org/', 'https://git-scm.com/', 'https://www.jd.com/', 'https://www.taobao.com/', 'https://www.douban.com/') loop = asyncio.get_event_loop() cos = [show_title(url) for url in urls] loop.run_until_complete(asyncio.wait(cos)) loop.close() if __name__ == '__main__': main()Key points: comparison between asynchronous I/O and multi process.
Asyncio is a good choice when programs do not need real concurrency or parallelism, but rely more on asynchronous processing and callback. If there is a lot of waiting and hibernation in the program, you should also consider asyncio, which is very suitable for writing Web application servers without real-time data processing requirements.
Python also has many third-party libraries for processing parallel tasks, such as joblib, PyMP, etc. In actual development, to improve the scalability and concurrency of the system, there are usually two methods: vertical expansion (increasing the processing capacity of a single node) and horizontal expansion (turning a single node into multiple nodes). The decoupling of applications can be realized through message Queue. Message Queue is equivalent to the extended version of multi-threaded synchronous Queue. Applications on different machines are equivalent to threads, and the shared distributed message Queue is the Queue in the original program. The most popular and standardized implementation of message queuing (Message Oriented Middleware) is AMQP (Advanced message queuing protocol). AMQP originates from the financial industry and provides queuing, routing, reliable transmission, security and other functions. The most famous implementations include Apache ActiveMQ, RabbitMQ and so on.
To achieve task asynchronization, you can use a third-party library called celery. Celery is a distributed task queue written in Python. It uses distributed messages to work. It can be used as the back-end message broker based on RabbitMQ or Redis.