XML is a general data exchange format. Its platform independence, language independence and system independence bring great convenience to data integration and interaction. XML parsing is the same in different language environments, but the syntax is different.
There are four parsing methods for XML:
- DOM parsing
- SAX parsing
- JDOM parsing
- DOM4J parsing
The first two are basic methods, which are platform independent parsing methods provided by the official; The latter two belong to extension methods. They are extended from the basic methods and are only applicable to the java platform.
Four methods are described in detail for the following XML files:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book id="1">
<name>Song of ice and fire</name>
<author>George Martin </author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>Andersen's Fairy Tales</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</bookstore>book entity class:
public class Book {
private String id;
private String name;
private String author;
private String year;
private String price;
private String language;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
public String getLanguage() {
return language;
}
public void setLanguage(String language) {
this.language = language;
}
@Override
public String toString() {
return "Book{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", author='" + author + '\'' +
", year='" + year + '\'' +
", price='" + price + '\'' +
", language='" + language + '\'' +
'}';
}
}DOM parsing
The full name of DOM is Document Object Model, that is, Document Object Model. In the application, the XML analyzer based on DOM transforms an XML document into a collection of object models (usually called DOM tree). The application realizes the operation of XML document data through the operation of this object model. Through the DOM interface, applications can access any part of the data in XML documents at any time. Therefore, this mechanism using the DOM interface is also called random access mechanism.
DOM interface provides a way to access XML document information through hierarchical object models, which form a node tree according to the document structure of XML. No matter what type of information is described in XML document, even tabulation data, item list or a document, the model generated by DOM is in the form of node tree. That is, DOM forces the use of a tree model to access information in XML documents. Because XML is essentially a hierarchical structure, this description method is quite effective.
The random access method provided by DOM tree brings great flexibility to the development of applications. It can arbitrarily control the content of the whole XML document. However, because the DOM analyzer converts the entire XML document into a DOM tree and puts it in memory, when the document is large or the structure is complex, the demand for memory is relatively high. Moreover, traversing the tree with complex structure is also a time-consuming operation. Therefore, DOM analyzer has high requirements for machine performance, and the implementation efficiency is not very ideal. However, because the idea of tree structure adopted by Dom analyzer is consistent with the structure of XML document, and in view of the convenience brought by random access, DOM analyzer still has a wide range of use value.
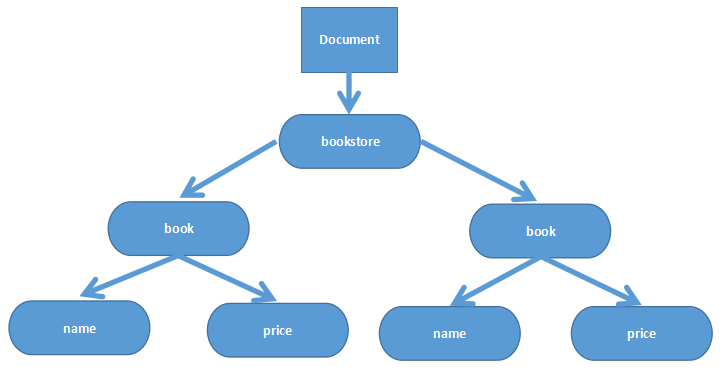
The following is the parsing code:
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.IOException;
/**
* @author linhongwei
* @version 1.0.0
* @ClassName DomXmlParser.java
* @Description Parsing xml using DOM without importing any third-party packages
* @createTime 2021 August 16, 2008 08:39:00
*/
public class DomXmlParser {
/**
* advantage:
* The tree structure is formed, which is helpful for better understanding and mastering, and the code is easy to write.
* During parsing, the tree structure is saved in memory for easy modification.
* Disadvantages:
* Because the file is read at one time, it consumes a lot of memory.
* If the XML file is large, it is easy to affect the parsing performance and may cause memory overflow.
* @param args
*/
public static void main(String[] args) {
//Create an object of DocumentBuilderFactory
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
//Create an object for DocumentBuilder
try {
//Create DocumentBuilder object
DocumentBuilder db = dbf.newDocumentBuilder();
//Load books.xml through the parser method of the DocumentBuilder object XML file to current project
Document document = db.parse(DomXmlParser.class.getResource("/books.xml").getPath());
//Gets a collection of all book nodes
NodeList bookList = document.getElementsByTagName("book");
//The length of bookList can be obtained through the getLength() method of nodelist
System.out.println("Altogether" + bookList.getLength() + "This book");
//Traverse each book node
for (int i = 0; i < bookList.getLength(); i++) {
System.out.println("=================Let's start traversing the second step" + (i + 1) + "Content of this book=================");
//Get a book node through the item(i) method, and the index value of nodelist starts from 0
Node book = bookList.item(i);
//Gets all the attribute collections of the book node
NamedNodeMap attrs = book.getAttributes();
System.out.println("The first " + (i + 1) + "This book has" + attrs.getLength() + "Attributes");
//Traverse the properties of book
for (int j = 0; j < attrs.getLength(); j++) {
//Get an attribute of the book node through the item(index) method
Node attr = attrs.item(j);
//Get property name
System.out.print("Property name:" + attr.getNodeName());
//Get property value
System.out.println("--Attribute value" + attr.getNodeValue());
}
//Resolve child nodes of book node
NodeList childNodes = book.getChildNodes();
//Traverse childNodes to get the node name and node value of each node
System.out.println("The first" + (i + 1) + "This book has" +
childNodes.getLength() + "Child node");
for (int k = 0; k < childNodes.getLength(); k++) {
//Distinguish between nodes of type text and nodes of type element
if (childNodes.item(k).getNodeType() == Node.ELEMENT_NODE) {
//Gets the node name of the element type node
System.out.print("The first" + (k + 1) + "Node names of nodes:"
+ childNodes.item(k).getNodeName());
//Gets the node value of the element type node
System.out.println("--Node values are:" + childNodes.item(k).getFirstChild().getNodeValue());
}
}
System.out.println("======================End traversal" + (i + 1) + "Content of this book=================");
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}advantage:
- The tree structure is formed, which is helpful for better understanding and mastering, and the code is easy to write.
- During parsing, the tree structure is saved in memory for easy modification.
Disadvantages:
- Because the file is read at one time, it consumes a lot of memory.
- If the XML file is large, it is easy to affect the parsing performance and may cause memory overflow.
SAX parsing
The full name of SAX is Simple APIs for XML, that is, XML simple application program interface. Unlike DOM, the access mode provided by SAX is a sequential mode, which is a way to quickly read and write XML data. When using SAX analyzer to analyze XML documents, a series of events will be triggered and the corresponding event handling functions will be activated. Applications can access XML documents through these event handling functions. Therefore, SAX interface is also called event driven interface.
The following parsed code:
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.IOException;
import java.util.ArrayList;
/**
* @author linhongwei
* @version 1.0.0
* @ClassName SaxXmlParser.java
* @Description Parsing xml using SAX without importing any third-party packages
* @createTime 2021 August 16, 2008 08:49:00
*/
public class SaxXmlParser {
/**
* advantage:
* Using event driven mode, the memory consumption is relatively small.
* Applies when only data in an XML file is processed.
* Disadvantages:
* Coding is troublesome.
* It is difficult to access multiple different data in an XML file at the same time.
*
* @param args
*/
public static void main(String[] args) {
//Create SAXParserFactory
SAXParserFactory factory = SAXParserFactory.newInstance();
//Create SAXParser parser from factory
try {
SAXParser parser = factory.newSAXParser();
//Specifies to be resolved by SAXParserHandler
SAXParserHandler handler = new SAXParserHandler();
parser.parse(SaxXmlParser.class.getResource("/books.xml").getPath(), handler);
System.out.println("~!~!~!share" + handler.getBookList().size() + "This book");
for (Book book : handler.getBookList()) {
System.out.println(book);
}
System.out.println("----finish----");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
static class SAXParserHandler extends DefaultHandler {
String value = null;
Book book = null;
private ArrayList<Book> bookList = new ArrayList();
public ArrayList<Book> getBookList() {
return bookList;
}
int bookIndex = 0;
/**
* Used to identify the start of parsing
*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
System.out.println("SAX Parsing start");
}
/**
* Used to identify the end of parsing
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("SAX End of parsing");
}
/**
* Parsing xml elements
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
//Call the startElement method of the DefaultHandler class
super.startElement(uri, localName, qName, attributes);
if (qName.equals("book")) {
bookIndex++;
//Create a book Object
book = new Book();
//Start parsing attributes of book element
System.out.println("======================Start traversing the contents of a book=================");
//I don't know the name and number of attributes under the book element, and how to get the attribute name and attribute value
int num = attributes.getLength();
for (int i = 0; i < num; i++) {
System.out.print("book Element number" + (i + 1) + "The first attribute names are:"
+ attributes.getQName(i));
System.out.println("---The attribute values are:" + attributes.getValue(i));
if (attributes.getQName(i).equals("id")) {
book.setId(attributes.getValue(i));
}
}
} else if (!qName.equals("name") && !qName.equals("bookstore")) {
System.out.print("The node name is:" + qName + "---");
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
//Call the endElement method of the DefaultHandler class
super.endElement(uri, localName, qName);
//Determine whether the traversal of a book has ended
if (qName.equals("book")) {
bookList.add(book);
book = null;
System.out.println("======================End traversing the contents of a Book=================");
} else if (qName.equals("name")) {
book.setName(value);
} else if (qName.equals("author")) {
book.setAuthor(value);
} else if (qName.equals("year")) {
book.setYear(value);
} else if (qName.equals("price")) {
book.setPrice(value);
} else if (qName.equals("language")) {
book.setLanguage(value);
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
super.characters(ch, start, length);
value = new String(ch, start, length);
if (!value.trim().equals("")) {
System.out.println("Node values are:" + value);
}
}
}
}advantage:
- Using event driven mode, the memory consumption is relatively small.
- Applies when only data in an XML file is processed.
Disadvantages:
- Coding is troublesome.
- It is difficult to access multiple different data in an XML file at the same time.
JDOM parsing
features:
- Use only concrete classes, not interfaces.
- The Collections class is heavily used by the API.
Dependency:
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom2</artifactId>
<version>2.0.6</version>
</dependency>The following is the parsing code:
import org.jdom2.Attribute;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.JDOMException;
import org.jdom2.input.SAXBuilder;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author linhongwei
* @version 1.0.0
* @ClassName JDomXmlParser.java
* @Description Using JDOM to parse xml requires the introduction of third-party packages
* @createTime 2021 09:03:00, August 16
*/
public class JDomXmlParser {
private static ArrayList<Book> booksList = new ArrayList<Book>();
/**
* @param args
*/
public static void main(String[] args) {
// For books JDOM parsing of XML file
// preparation
// 1. Create an object of SAXBuilder
SAXBuilder saxBuilder = new SAXBuilder();
InputStream in;
try {
// 2. Create an input stream and load the xml file into the input stream
in = new FileInputStream(JDomXmlParser.class.getResource("/books.xml").getPath());
InputStreamReader isr = new InputStreamReader(in, "UTF-8");
// 3. Load the input stream into saxBuilder through the build method of saxBuilder
Document document = saxBuilder.build(isr);
// 4. Get the root node of the xml file through the document object
Element rootElement = document.getRootElement();
// 5. Get the List set of child nodes under the root node
List<Element> bookList = rootElement.getChildren();
// Continue parsing
for (Element book : bookList) {
Book bookEntity = new Book();
System.out.println("======Start parsing page" + (bookList.indexOf(book) + 1) + "book======");
// Resolve the property collection of book
List<Attribute> attrList = book.getAttributes();
// //Get the node value when you know the attribute name under the node
// book.getAttributeValue("id");
// Traverse attrlist (for unclear name and number of attributes under book node)
for (Attribute attr : attrList) {
// Get property name
String attrName = attr.getName();
// Get property value
String attrValue = attr.getValue();
System.out.println("Property name:" + attrName + "----Attribute value:" + attrValue);
if (attrName.equals("id")) {
bookEntity.setId(attrValue);
}
}
// Traversal of the node name and node value of the child nodes of the book node
List<Element> bookChilds = book.getChildren();
for (Element child : bookChilds) {
System.out.println("Node name:" + child.getName() + "----Node value:"
+ child.getValue());
if (child.getName().equals("name")) {
bookEntity.setName(child.getValue());
} else if (child.getName().equals("author")) {
bookEntity.setAuthor(child.getValue());
} else if (child.getName().equals("year")) {
bookEntity.setYear(child.getValue());
} else if (child.getName().equals("price")) {
bookEntity.setPrice(child.getValue());
} else if (child.getName().equals("language")) {
bookEntity.setLanguage(child.getValue());
}
}
System.out.println("======End parsing section" + (bookList.indexOf(book) + 1) + "book======");
booksList.add(bookEntity);
bookEntity = null;
System.out.println(booksList.size());
System.out.println(booksList.get(0).getId());
System.out.println(booksList.get(0).getName());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}