Background account
The team does CET-4 and CET-6 related services. There is a care service in the business. You can get a full refund after purchasing the care service, but one premise is to complete the tasks of the care service, such as memorizing words for N days and completing the specified test paper.
In this context, after the completion of CET-4 and CET-6 in June 2021, two kinds of user data shall be counted:
- Users who complete the care service
- Users who did not complete care
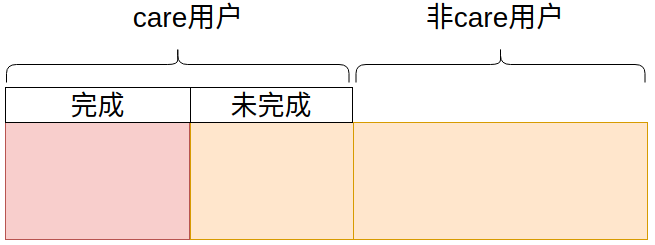
Therefore, the simplified logic is to distinguish between care completed users and care incomplete users among all users.
- Goal 1: complete care services
- Goal 2: incomplete care service
The number of all target users is about 2.7w, and the number of care completion users is about 0.4w. Therefore, what I need to do is to distinguish between care completed users and care incomplete users in another table for all the 2.7w users queried from the database.
first edition
First Edition: pure use of database queries. First, query all targets, then traverse all users, and use user id to query care from another table to complete the user.
The total amount is about 2.7w, so the database has been queried 2.7w times.
Time consuming statistics: 144.7 s
def remind_repurchase():
# Query all users
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
for user in all_users:
# Query whether the user has completed the care from another table
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care complete
if len(user_insurance) == 1:
# Other logic
plan_15_16_can_refund_users.append(user.user_id)
else:
# care incomplete user
plan_15_16_not_refund_users.append(user.user_id)
The main time-consuming operation is to query the database in the for loop. This time-consuming is certainly not allowed, and efficiency needs to be improved.
Second Edition
Optimization point: add transaction
Optimization idea of the Second Edition: for 2.7w database queries, there must be 2.7w connections, transactions, query statements to SQL, etc. The cost of 2.7w times is also a huge number. Naturally, I thought of reducing transaction overhead. All database queries are completed in one transaction, which can effectively reduce the time-consuming caused by queries.
Time consuming statistics: 100.6 s
def remind_repurchase():
# Query all users
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# Add transaction
with pwdb.database.atomic():
for user in all_users:
# Query whether the user has completed the care from another table
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care complete
if len(user_insurance) == 1:
# Other logic
plan_15_16_can_refund_users.append(user.user_id)
else:
# care incomplete user
plan_15_16_not_refund_users.append(user.user_id)
After adding transactions, 44s is reduced, which is equivalent to shortening the time by 30%. It can be seen that querying transactions in the database is a time-consuming operation.
Third Edition
Optimization point: convert 2.7w database queries into in operations for lists.
The third edition proposes an improvement scheme: the original logic is to cycle 2.7w times to query whether the user has completed the care service in the database. 2.7w database queries are the most time-consuming reason, and the way to improve is to query all users who have completed the care service at one time and put them in a list. When traversing all users, you do not check the database, but directly use the in operation to query in the list. This method directly reduces 2.7w times of database traversal to 1 time, which greatly shortens the time-consuming of database query.
Time consuming statistics: 11.5 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# After all care users are completed, query all users and put them in a list
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_list = [user.user_id for user in user_insurance]
for user in all_users:
user_id = user.user_id
# care complete
if user.user_id in user_insurance_list:
# Check score
plan_15_16_can_refund_users.append(user_id)
else:
# Care incomplete user + non care user
plan_15_16_not_refund_users.append(user_id)
The effect of this optimization is very significant. It can be seen that if you want to improve code efficiency, you should try to reduce the number of database queries.
Fourth Edition
Optimization point: 2.7w in operations on the list become in operations on the dictionary
In the third edition, the efficiency has been greatly optimized, but after careful consideration, it is found that there is still room for improvement. In the third version, 2.7w for loops are used, and then the in operation is used to query in the list. As we all know, the in operation on the list in python is traversal, and the time complexity is 0(n), so the efficiency is not high, while the time complexity of the in operation on the dictionary is constant level 0 (1). Therefore, in the fourth edition of optimization, the data queried first is not saved as a list, but as a dictionary. key is the value in the original list. Value can be customized.
Time consuming statistics: 11.42 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# After all care users are completed, query all users and put them in a list
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_dict = {user.user_id:True for user in user_insurance}
for user in all_users:
user_id = user.user_id
# care complete
if user.user_id in user_insurance_dict:
# Check score
plan_15_16_can_refund_users.append(user_id)
else:
# Care incomplete user + non care user
plan_15_16_not_refund_users.append(user_id)
Since the amount of data of the 2.7w in operations is not very large, and the efficiency of optimizing the list in operations in python is also very good, the in operations on the dictionary here do not reduce the time consumption.
Fifth Edition
Optimization point: Convert in operation into set operation.
Under the optimization of the first four versions, the time has been shortened by 133s and nearly 92.1%. I think this data looks good. When I was brushing my teeth the next morning, my mind was full of thoughts, and I thought of it. At this time, it suddenly occurred to me that since I can query all users and query the users who have completed the care user into a list, isn't it equivalent to two sets? Since it is a set, is it faster to use the intersection and difference sets between sets than loop 2.7w? Start to test the idea immediately after work. Sure enough, it can also reduce the time consumption by directly halving 11.42 in the fourth edition to 5.78, a reduction of nearly 50%.
Time consuming statistics: 5.78 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
all_users_set = set([user.user_id for user in all_users])
plan_15_16_can_refund_users = []
received_user_count = 0
# All care completion users
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_set = set([user.user_id for user in user_insurance])
temp_can_refund_users = all_users_set.intersection(user_insurance_set)
summary
Final optimization results:
The first edition took 144.7 s econds
The last version took 5.7 s econds
Optimization time: 109 s
Optimization percentage: 95.0%
The details of optimization in each version are as follows:
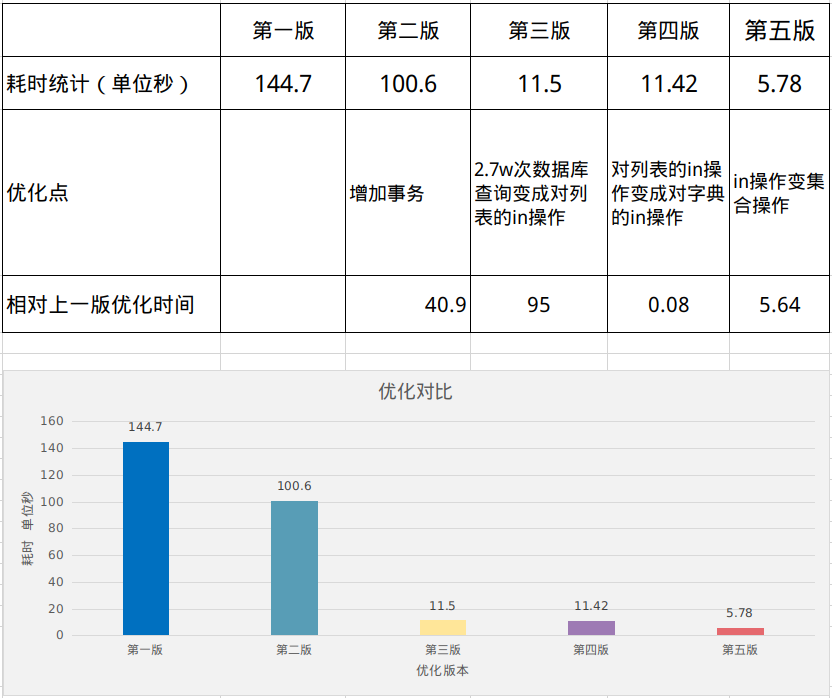
Several conclusions can be drawn to help reduce program time:
Conclusion 1: transaction can not only ensure the atomicity of data, but also effectively reduce the time-consuming of database query
Conclusion 2: the efficiency of set operation is very high. We should be good at using sets to reduce loops
Conclusion 3: the search efficiency of dictionary is higher than that of list, but 10000 times of operation can not experience the advantages
Finally, there is another conclusion: the programmer's inspiration seems to be particularly active when brushing teeth, going to the bathroom, bathing and drinking water, so if you can't write code, you should touch fish.
