Write in front
In today's Internet industry, especially in the current distributed and micro service development environment, in order to improve search efficiency and search accuracy, a large number of NoSQL databases such as Redis and Memcached will be used, as well as a large number of full-text retrieval services such as Solr and Elasticsearch. Then, at this time, there will be a problem we need to think about and solve: that is the problem of data synchronization! How to synchronize the data in the real-time changing database to Redis/Memcached or Solr/Elasticsearch?
Data synchronization requirements in the context of Internet
In today's Internet industry, especially in the current distributed and micro service development environment, in order to improve search efficiency and search accuracy, a large number of NoSQL databases such as Redis and Memcached will be used, as well as a large number of full-text retrieval services such as Solr and Elasticsearch. Then, at this time, there will be a problem we need to think about and solve: that is the problem of data synchronization! How to synchronize the data in the real-time changing database to Redis/Memcached or Solr/Elasticsearch?
For example, we constantly write data to the database in a distributed environment, and we may need to read data from Redis, Memcached, Elasticsearch, Solr and other services. Then, the real-time synchronization of data between database and various services has become an urgent problem to be solved.
Imagine that due to business needs, we have introduced Redis, Memcached, Elasticsearch, Solr and other services. This makes it possible for our application to read data from different services, as shown in the figure below.
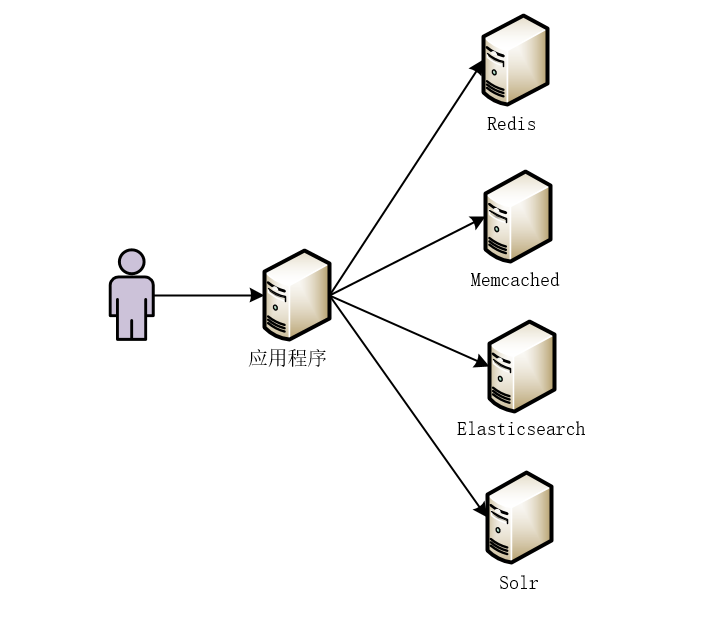
In essence, no matter what kind of service or middleware we introduce, the data is ultimately read from our MySQL database. So, the question is, how to synchronize the data in MySQL to other services or middleware in real time?
Note: in order to better explain the problem, the following contents take the synchronization of data in MySQL database to Solr index library as an example.
Data synchronization solution
1. Synchronize in business code
After adding, modifying and deleting, execute the logic code of Solr index library. For example, the following code snippet.
public ResponseResult updateStatus(Long[] ids, String status){
try{
goodsService.updateStatus(ids, status);
if("status_success".equals(status)){
List<TbItem> itemList = goodsService.getItemList(ids, status);
itemSearchService.importList(itemList);
return new ResponseResult(true, "Status modified successfully")
}
}catch(Exception e){
return new ResponseResult(false, "Failed to modify status");
}
}
advantage:
Easy to operate.
Disadvantages:
High business coupling.
Execution efficiency becomes low.
2. Timed task synchronization
After adding, modifying and deleting operations in the database, the data in the database will be synchronized to the Solr index library regularly through scheduled tasks.
Timed task technologies include: SpringTask, Quartz.
Ha ha, and my open-source mykit delay framework. The open-source address is: https://github.com/sunshinelyz/mykit-delay.
When executing a scheduled task, you should pay attention to the following skills: when executing a scheduled task for the first time, query the corresponding data in reverse order from the time field in the MySQL database, and record the maximum value of the time field of the current query data. Each time you execute a scheduled task to query data in the future, As long as the data whose time field in the data table is greater than the time value recorded last time is queried in the reverse order of time field, and the maximum value of the time field queried in this task is recorded, so there is no need to query all the data in the data table again.
Note: the time field mentioned here refers to the time field identifying the data update, that is, when using a scheduled task to synchronize data, in order to avoid full table scanning every time the task is executed, it is best to add a time field for updating records in the data table.
advantage:
The operation of synchronizing the Solr index library is completely decoupled from the business code.
Disadvantages:
The real-time performance of data is not high.
3. Realize synchronization through MQ
After adding, modifying and deleting operations in the database, send a message to MQ. At this time, the synchronizer, as a consumer in MQ, obtains the message from the message queue, and then executes the logic of synchronizing the Solr index library.
We can use the following figure to simply identify the process of data synchronization through MQ.

We can use the following code to implement this process.
public ResponseResult updateStatus(Long[] ids, String status){
try{
goodsService.updateStatus(ids, status);
if("status_success".equals(status)){
List<TbItem> itemList = goodsService.getItemList(ids, status);
final String jsonString = JSON.toJSONString(itemList);
jmsTemplate.send(queueSolr, new MessageCreator(){
@Override
public Message createMessage(Session session) throws JMSException{
return session.createTextMessage(jsonString);
}
});
}
return new ResponseResult(true, "Status modified successfully");
}catch(Exception e){
return new ResponseResult(false, "Failed to modify status");
}
}
advantage:
Business code is decoupled, and quasi real-time can be achieved.
Disadvantages:
The code for sending messages to MQ needs to be added to the business code, and the data call interface is coupled.
4. Real time synchronization via Canal
Canal is a database log incremental parsing component open source by Alibaba. It parses the log information of the database through canal to detect the changes of table structure and data in the database, so as to update the Solr index library.
Using Canal, business code and API can be completely decoupled, and quasi real-time can be achieved.
Introduction to Canal
Alibaba MySQL database binlog incremental subscription and consumption component provides incremental data subscription and consumption based on database incremental log analysis. At present, it mainly supports mysql.
Canal open source address: GitHub - alibaba/canal: Alibaba MySQL binlog incremental subscription & consumption component.
How Canal works
Implementation of MySQL master-slave replication
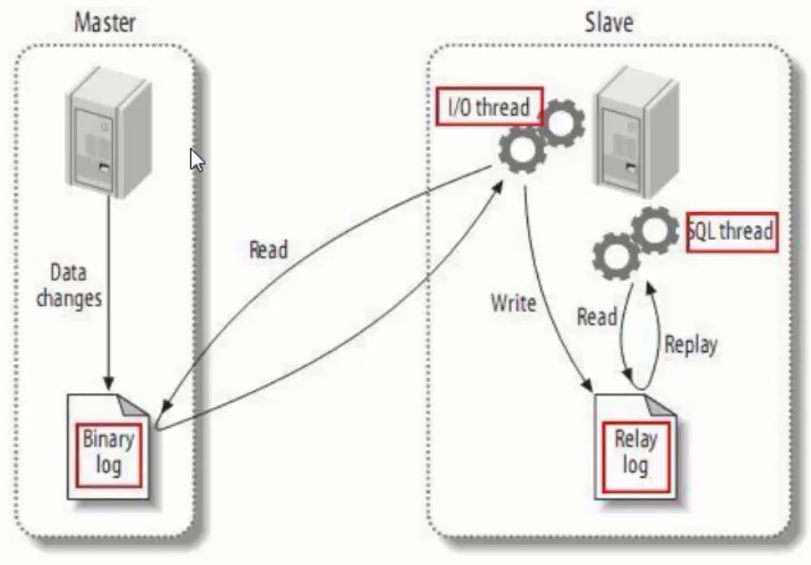
As can be seen from the above figure, master-slave replication is mainly divided into three steps:
- The Master node records the data changes in the binary log (these records are called binary log events, which can be viewed through show binlog events).
- The Slave node copies the binary log events of the Master node to its relay log.
- The events in the Slave node redo relay log will reflect the changes to its own database.
Canal internal principle
First, let's take a look at the schematic diagram of Canal, as shown below.
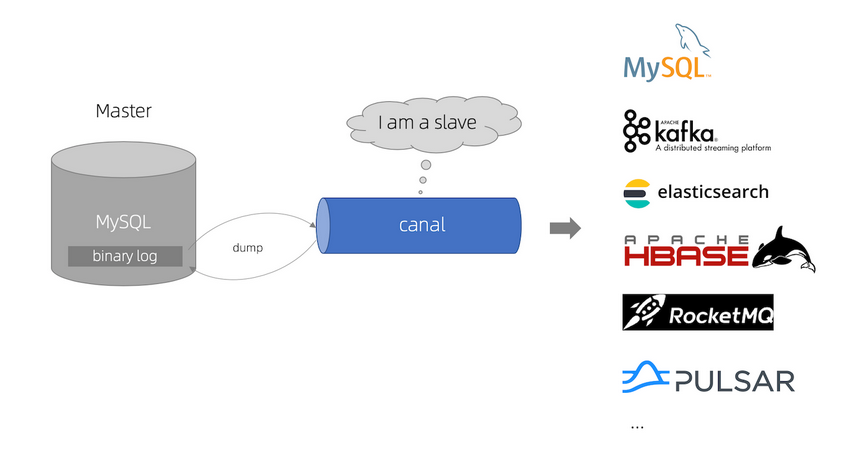
The principle is roughly described as follows:
- Canal simulates the interaction protocol of MySQL slave, disguises itself as MySQL slave, and sends dump protocol to MySQL Master
- MySQL Master receives the dump request and starts pushing binary log to Slave (i.e. Canal)
- Canal parses binary log object (originally byte stream)
Internal structure of Canal
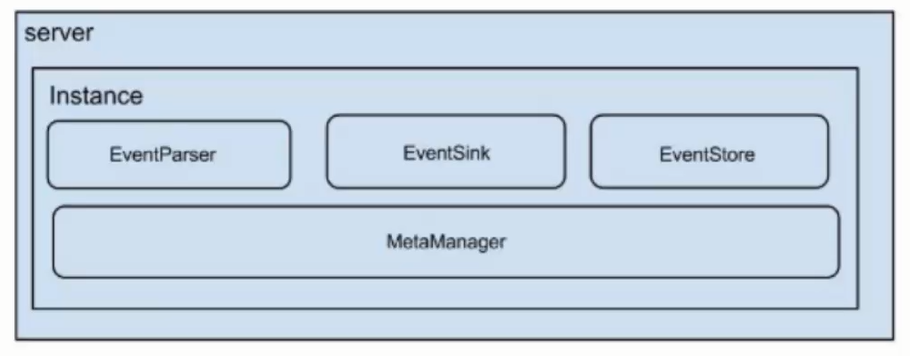
The description is as follows:
- Server: represents a Canal running instance, corresponding to a JVM process.
- Instance: corresponds to a data queue (one Server corresponds to one or more instances).
Next, let's look at the sub modules under Instance, as shown below.
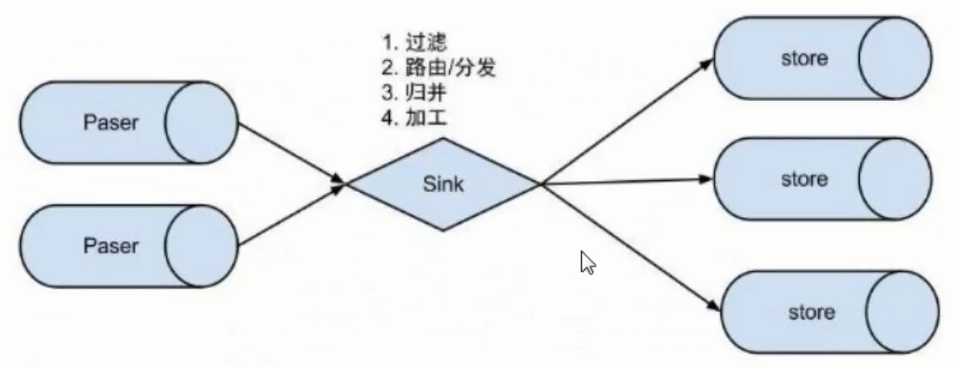
- EventParser: data source access, simulate the Slave protocol, interact with the Master node, and analyze the protocol.
- EventSink: the connector of EventParser and EventStore to filter, process, merge and distribute data.
- Eventsoe: data storage.
- MetaManager: incremental subscription and consumption information management.
Canal environmental preparation
Set up MySQL remote access
grant all privileges on *.* to 'root'@'%' identified by '123456'; flush privileges;
MySQL configuration
Note: MySQL here is described based on version 5.7.
The principle of Canal is based on MySQL binlog technology. Therefore, if you want to use Canal, you need to enable the binlog writing function of MySQL. It is recommended to configure the binlog mode as row.
You can enter the following commands on the MySQL command line to view the binlog mode.
SHOW VARIABLES LIKE 'binlog_format';
The execution effect is as follows.
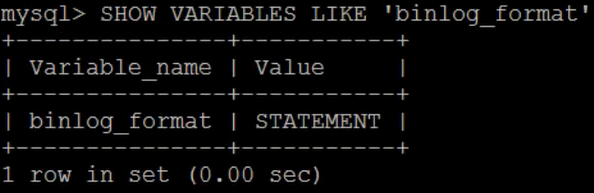
As you can see, the default binlog format in MySQL is state. Here we need to change state to ROW. Modify / etc / my CNF file.
vim /etc/my.cnf
Add the following three configurations under [mysqld].
log-bin=mysql-bin #Enable MySQL binary log binlog_format=ROW #Set the format of binary log to ROW server_id=1 #server_id needs to be unique and cannot be duplicate with the slaveId of Canal
After modifying my After the CNF file, you need to restart the MySQL service.
service mysqld restart
Next, let's look at the binlog mode again.
SHOW VARIABLES LIKE 'binlog_format';
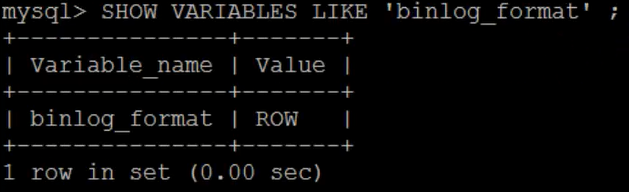
You can see that at this time, the binlog mode of MySQL has been set to ROW.
MySQL create user authorization
The principle of Canal is that the mode itself is MySQL Slave, so you must set the relevant permissions of MySQL Slave. Here, you need to create a master-slave synchronization account and give the account relevant permissions.
CREATE USER canal@'localhost' IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'localhost'; FLUSH PRIVILEGES;
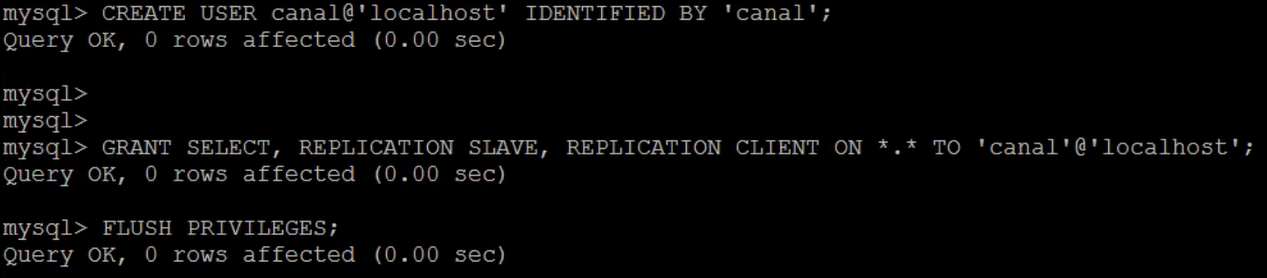
Canal deployment installation
Download Canal
Here, we will explain with the version of Canal 1.1.1, and the friends can go to the link Release v1.1.1 · alibaba/canal · GitHub Download canal Version 1.1.1.
Upload and decompress
Upload the downloaded Canal installation package to the server, and execute the following command to decompress it
mkdir -p /usr/local/canal tar -zxvf canal.deployer-1.1.1.tar.gz -C /usr/local/canal/
The extracted directory is shown below.

The description of each catalogue is as follows:
- bin: stores executable scripts.
- conf: store configuration files.
- lib: store other dependent or third-party libraries.
- logs: stores log files.
Modify profile
In the conf directory of Canal, there is a Canal Properties file, which configures the configuration related to the Canal Server. In this file, there is the following line of configuration.
canal.destinations=example
The example here is equivalent to an Instance of Canal. Multiple instances can be configured here. Multiple instances can be separated by commas. At the same time, the example here also corresponds to a folder under the conf directory of Canal. That is, each Instance in Canal corresponds to a subdirectory under the conf directory.
Next, we need to modify a configuration file instance. In the example directory under the conf directory of Canal properties.
vim instance.properties
Modify the following configuration items.
################################################# ## canal slaveId. Note: do not connect with MySQL server_id duplicate canal.instance.mysql.slaveId = 1234 #position info, which needs to be changed to its own database information canal.instance.master.address = 127.0.0.1:3306 canal.instance.master.journal.name = canal.instance.master.position = canal.instance.master.timestamp = #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #username/password, which needs to be changed to its own database information canal.instance.dbUsername = canal canal.instance.dbPassword = canal canal.instance.defaultDatabaseName =canaldb canal.instance.connectionCharset = UTF-8 #table regex canal.instance.filter.regex = canaldb\\..* #################################################
Meaning of options:
- canal. instance. mysql. Slaveid: the serverId concept in MySQL Cluster configuration, which needs to be unique to the current MySQL Cluster;
- canal.instance.master.address: mysql main database link address;
- canal. instance. Dbusername: MySQL database account;
- canal. instance. Dbpassword: MySQL database password;
- canal. instance. Defaultdatabasename: the default database for MySQL link;
- canal. instance. Connectioncharset: MySQL data parsing code;
- canal. instance. filter. Regex: table concerned by MySQL data parsing, Perl regular expression
Start Canal
After configuring the Canal, you can start the Canal. Enter the bin directory of Canal and enter the following command to start Canal.
./startup.sh
Test Canal
Import and modify the source code
Here, we use the source code of Canal for testing. After downloading the source code of Canal, we import it into IDEA.
Next, we find the SimpleCanalClientTest class under example to test. The source code of this class is as follows.
package com.alibaba.otter.canal.example;
import java.net.InetSocketAddress;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.common.utils.AddressUtils;
/**
* Test example of stand-alone mode
*
* @author jianghang 2013-4-15 04:19:20 PM
* @version 1.0.4
*/
public class SimpleCanalClientTest extends AbstractCanalClientTest {
public SimpleCanalClientTest(String destination){
super(destination);
}
public static void main(String args[]) {
// Create links directly according to ip, without HA function
String destination = "example";
String ip = AddressUtils.getHostIp();
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress(ip, 11111),
destination,
"canal",
"canal");
final SimpleCanalClientTest clientTest = new SimpleCanalClientTest(destination);
clientTest.setConnector(connector);
clientTest.start();
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
try {
logger.info("## stop the canal client");
clientTest.stop();
} catch (Throwable e) {
logger.warn("##something goes wrong when stopping canal:", e);
} finally {
logger.info("## canal client is down.");
}
}
});
}
}
As you can see, the destination used in this class is example. In this class, we only need to change the IP address to the IP of the Canal Server.
Specifically: the following line of code will be.
String ip = AddressUtils.getHostIp();
Amend to read:
String ip = "192.168.175.100"
Since we did not specify the user name and password when configuring Canal, we also need to add the following code.
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress(ip, 11111),
destination,
"canal",
"canal");
Amend to read:
CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress(ip, 11111),
destination,
"",
"");
After the modification, run the main method to start the program.
Test data change
Next, create a canaldb database in MySQL.
create database canaldb;
At this time, relevant log information will be output on the command line of IDEA.
**************************************************** * Batch Id: [7] ,count : [3] , memsize : [149] , Time : 2020-08-05 23:25:35 * Start : [mysql-bin.000007:6180:1540286735000(2020-08-05 23:25:35)] * End : [mysql-bin.000007:6356:1540286735000(2020-08-05 23:25:35)] ****************************************************
Next, I create a data table in the canaldb database and add, delete, modify and check the data in the data table. The log information output by the program is as follows.
#After mysql makes data changes, the bin log of mysql will be displayed here. **************************************************** * Batch Id: [7] ,count : [3] , memsize : [149] , Time : 2020-08-05 23:25:35 * Start : [mysql-bin.000007:6180:1540286735000(2020-08-05 23:25:35)] * End : [mysql-bin.000007:6356:1540286735000(2020-08-05 23:25:35)] **************************************************** ================> binlog[mysql-bin.000007:6180] , executeTime : 1540286735000(2020-08-05 23:25:35) , gtid : () , delay : 393ms BEGIN ----> Thread id: 43 ----------------> binlog[mysql-bin.000007:6311] , name[canal,canal_table] , eventType : DELETE , executeTime : 1540286735000(2020-08-05 23:25:35) , gtid : () , delay : 393 ms id : 8 type=int(10) unsigned name : 512 type=varchar(255) ---------------- END ----> transaction id: 249 ================> binlog[mysql-bin.000007:6356] , executeTime : 1540286735000(2020-08-05 23:25:35) , gtid : () , delay : 394ms **************************************************** * Batch Id: [8] ,count : [3] , memsize : [149] , Time : 2020-08-05 23:25:35 * Start : [mysql-bin.000007:6387:1540286869000(2020-08-05 23:25:49)] * End : [mysql-bin.000007:6563:1540286869000(2020-08-05 23:25:49)] **************************************************** ================> binlog[mysql-bin.000007:6387] , executeTime : 1540286869000(2020-08-05 23:25:49) , gtid : () , delay : 976ms BEGIN ----> Thread id: 43 ----------------> binlog[mysql-bin.000007:6518] , name[canal,canal_table] , eventType : INSERT , executeTime : 1540286869000(2020-08-05 23:25:49) , gtid : () , delay : 976 ms id : 21 type=int(10) unsigned update=true name : aaa type=varchar(255) update=true ---------------- END ----> transaction id: 250 ================> binlog[mysql-bin.000007:6563] , executeTime : 1540286869000(2020-08-05 23:25:49) , gtid : () , delay : 977ms **************************************************** * Batch Id: [9] ,count : [3] , memsize : [161] , Time : 2020-08-05 23:26:22 * Start : [mysql-bin.000007:6594:1540286902000(2020-08-05 23:26:22)] * End : [mysql-bin.000007:6782:1540286902000(2020-08-05 23:26:22)] **************************************************** ================> binlog[mysql-bin.000007:6594] , executeTime : 1540286902000(2020-08-05 23:26:22) , gtid : () , delay : 712ms BEGIN ----> Thread id: 43 ----------------> binlog[mysql-bin.000007:6725] , name[canal,canal_table] , eventType : UPDATE , executeTime : 1540286902000(2020-08-05 23:26:22) , gtid : () , delay : 712 ms id : 21 type=int(10) unsigned name : aaac type=varchar(255) update=true ---------------- END ----> transaction id: 252 ================> binlog[mysql-bin.000007:6782] , executeTime : 1540286902000(2020-08-05 23:26:22) , gtid : () , delay : 713ms
Data synchronization implementation
demand
The changes of database data are parsed into binlog logs through canal and updated into solr's index database in real time.
Concrete implementation
Create project
Create Maven project mykit canal demo and create it in POM Add the following configuration to the XML file.
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.0.24</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.0.24</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.8.9</version>
</dependency>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>4.10.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
</dependencies>
Create log4j profile
Create log4j. In the src/main/resources directory of the project Properties file, as shown below.
log4j.rootCategory=debug, CONSOLE
# CONSOLE is set to be a ConsoleAppender using a PatternLayout.
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
# LOGFILE is set to be a File appender using a PatternLayout.
# log4j.appender.LOGFILE=org.apache.log4j.FileAppender
# log4j.appender.LOGFILE.File=d:\axis.log
# log4j.appender.LOGFILE.Append=true
# log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
# log4j.appender.LOGFILE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
Create entity class
In io mykit. Canal. demo. Create a Book entity class under the bean package to test the data transmission of Canal, as shown below.
package io.mykit.canal.demo.bean;
import org.apache.solr.client.solrj.beans.Field;
import java.util.Date;
public class Book implements Serializable {
private static final long serialVersionUID = -6350345408771427834L;{
@Field("id")
private Integer id;
@Field("book_name")
private String name;
@Field("book_author")
private String author;
@Field("book_publishtime")
private Date publishtime;
@Field("book_price")
private Double price;
@Field("book_publishgroup")
private String publishgroup;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Date getPublishtime() {
return publishtime;
}
public void setPublishtime(Date publishtime) {
this.publishtime = publishtime;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public String getPublishgroup() {
return publishgroup;
}
public void setPublishgroup(String publishgroup) {
this.publishgroup = publishgroup;
}
@Override
public String toString() {
return "Book{" +
"id=" + id +
", name='" + name + '\'' +
", author='" + author + '\'' +
", publishtime=" + publishtime +
", price=" + price +
", publishgroup='" + publishgroup + '\'' +
'}';
}
}
In the Book entity class, we use Solr's annotation @ Field to define the relationship between the entity class Field and Solr domain.
Implementation of various tool classes
Next, we are in io mykit. canal. demo. Create various tool classes under utils package.
- BinlogValue
It is used to store the value value of each row and column of binlog analysis. The code is as follows.
package io.mykit.canal.demo.utils;
import java.io.Serializable;
/**
*
* ClassName: BinlogValue <br/>
*
* binlog The value value of each row and column of the analysis< br>
* New data: beforeValue and value are existing values< br>
* Modify data: beforeValue is the value before modification; Value is the modified value< br>
* Delete data: beforeValue and value are the values before deletion; This is special because it is convenient to obtain the value before deletion when deleting data < br >
*/
public class BinlogValue implements Serializable {
private static final long serialVersionUID = -6350345408773943086L;
private String value;
private String beforeValue;
/**
* binlog The value value of each row and column of the analysis< br>
* New data: Value: existing value< br>
* Modified data: value is the modified value< br>
* Delete data: value is the value before deletion; This is special because it is convenient to obtain the value before deletion when deleting data < br >
*/
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
/**
* binlog beforeValue value of each row and column analyzed< br>
* New data: beforeValue is the existing value< br>
* Modify data: beforeValue is the value before modification< br>
* Delete data: beforeValue is the value before deletion< br>
*/
public String getBeforeValue() {
return beforeValue;
}
public void setBeforeValue(String beforeValue) {
this.beforeValue = beforeValue;
}
}
- CanalDataParser
For parsing data, the code is as follows.
package io.mykit.canal.demo.utils;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang.SystemUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.CollectionUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.CanalEntry.TransactionBegin;
import com.alibaba.otter.canal.protocol.CanalEntry.TransactionEnd;
import com.google.protobuf.InvalidProtocolBufferException;
/**
* Parse data
*/
public class CanalDataParser {
protected static final String DATE_FORMAT = "yyyy-MM-dd HH:mm:ss";
protected static final String yyyyMMddHHmmss = "yyyyMMddHHmmss";
protected static final String yyyyMMdd = "yyyyMMdd";
protected static final String SEP = SystemUtils.LINE_SEPARATOR;
protected static String context_format = null;
protected static String row_format = null;
protected static String transaction_format = null;
protected static String row_log = null;
private static Logger logger = LoggerFactory.getLogger(CanalDataParser.class);
static {
context_format = SEP + "****************************************************" + SEP;
context_format += "* Batch Id: [{}] ,count : [{}] , memsize : [{}] , Time : {}" + SEP;
context_format += "* Start : [{}] " + SEP;
context_format += "* End : [{}] " + SEP;
context_format += "****************************************************" + SEP;
row_format = SEP
+ "----------------> binlog[{}:{}] , name[{},{}] , eventType : {} , executeTime : {} , delay : {}ms"
+ SEP;
transaction_format = SEP + "================> binlog[{}:{}] , executeTime : {} , delay : {}ms" + SEP;
row_log = "schema[{}], table[{}]";
}
public static List<InnerBinlogEntry> convertToInnerBinlogEntry(Message message) {
List<InnerBinlogEntry> innerBinlogEntryList = new ArrayList<InnerBinlogEntry>();
if(message == null) {
logger.info("Empty received message; ignore");
return innerBinlogEntryList;
}
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
logger.info("Empty received message[size=" + size + "]; ignore");
return innerBinlogEntryList;
}
printLog(message, batchId, size);
List<Entry> entrys = message.getEntries();
//Output log
for (Entry entry : entrys) {
long executeTime = entry.getHeader().getExecuteTime();
long delayTime = new Date().getTime() - executeTime;
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN) {
TransactionBegin begin = null;
try {
begin = TransactionBegin.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
// Print the transaction header information, the thread id executed, and the transaction time
logger.info("BEGIN ----> Thread id: {}", begin.getThreadId());
logger.info(transaction_format, new Object[] {entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader().getLogfileOffset()), String.valueOf(entry.getHeader().getExecuteTime()), String.valueOf(delayTime) });
} else if (entry.getEntryType() == EntryType.TRANSACTIONEND) {
TransactionEnd end = null;
try {
end = TransactionEnd.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
// Print transaction submission information, transaction id
logger.info("END ----> transaction id: {}", end.getTransactionId());
logger.info(transaction_format,
new Object[] {entry.getHeader().getLogfileName(), String.valueOf(entry.getHeader().getLogfileOffset()),
String.valueOf(entry.getHeader().getExecuteTime()), String.valueOf(delayTime) });
}
continue;
}
//Analytical results
if (entry.getEntryType() == EntryType.ROWDATA) {
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("parse event has an error , data:" + entry.toString(), e);
}
EventType eventType = rowChage.getEventType();
logger.info(row_format, new Object[] { entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader().getLogfileOffset()), entry.getHeader().getSchemaName(),
entry.getHeader().getTableName(), eventType, String.valueOf(entry.getHeader().getExecuteTime()), String.valueOf(delayTime) });
//Assembly data results
if (eventType == EventType.INSERT || eventType == EventType.DELETE || eventType == EventType.UPDATE) {
String schemaName = entry.getHeader().getSchemaName();
String tableName = entry.getHeader().getTableName();
List<Map<String, BinlogValue>> rows = parseEntry(entry);
InnerBinlogEntry innerBinlogEntry = new InnerBinlogEntry();
innerBinlogEntry.setEntry(entry);
innerBinlogEntry.setEventType(eventType);
innerBinlogEntry.setSchemaName(schemaName);
innerBinlogEntry.setTableName(tableName.toLowerCase());
innerBinlogEntry.setRows(rows);
innerBinlogEntryList.add(innerBinlogEntry);
} else {
logger.info(" existence INSERT INSERT UPDATE Other than operation SQL [" + eventType.toString() + "]");
}
continue;
}
}
return innerBinlogEntryList;
}
private static List<Map<String, BinlogValue>> parseEntry(Entry entry) {
List<Map<String, BinlogValue>> rows = new ArrayList<Map<String, BinlogValue>>();
try {
String schemaName = entry.getHeader().getSchemaName();
String tableName = entry.getHeader().getTableName();
RowChange rowChage = RowChange.parseFrom(entry.getStoreValue());
EventType eventType = rowChage.getEventType();
// Process each row of data in each Entry
for (RowData rowData : rowChage.getRowDatasList()) {
StringBuilder rowlog = new StringBuilder("rowlog schema[" + schemaName + "], table[" + tableName + "], event[" + eventType.toString() + "]");
Map<String, BinlogValue> row = new HashMap<String, BinlogValue>();
List<Column> beforeColumns = rowData.getBeforeColumnsList();
List<Column> afterColumns = rowData.getAfterColumnsList();
beforeColumns = rowData.getBeforeColumnsList();
if (eventType == EventType.DELETE) {//delete
for(Column column : beforeColumns) {
BinlogValue binlogValue = new BinlogValue();
binlogValue.setValue(column.getValue());
binlogValue.setBeforeValue(column.getValue());
row.put(column.getName(), binlogValue);
}
} else if(eventType == EventType.UPDATE) {//update
for(Column column : beforeColumns) {
BinlogValue binlogValue = new BinlogValue();
binlogValue.setBeforeValue(column.getValue());
row.put(column.getName(), binlogValue);
}
for(Column column : afterColumns) {
BinlogValue binlogValue = row.get(column.getName());
if(binlogValue == null) {
binlogValue = new BinlogValue();
}
binlogValue.setValue(column.getValue());
row.put(column.getName(), binlogValue);
}
} else { // insert
for(Column column : afterColumns) {
BinlogValue binlogValue = new BinlogValue();
binlogValue.setValue(column.getValue());
binlogValue.setBeforeValue(column.getValue());
row.put(column.getName(), binlogValue);
}
}
rows.add(row);
String rowjson = JacksonUtil.obj2str(row);
logger.info("########################### Data Parse Result ###########################");
logger.info(rowlog + " , " + rowjson);
logger.info("########################### Data Parse Result ###########################");
logger.info("");
}
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException("parseEntry has an error , data:" + entry.toString(), e);
}
return rows;
}
private static void printLog(Message message, long batchId, int size) {
long memsize = 0;
for (Entry entry : message.getEntries()) {
memsize += entry.getHeader().getEventLength();
}
String startPosition = null;
String endPosition = null;
if (!CollectionUtils.isEmpty(message.getEntries())) {
startPosition = buildPositionForDump(message.getEntries().get(0));
endPosition = buildPositionForDump(message.getEntries().get(message.getEntries().size() - 1));
}
SimpleDateFormat format = new SimpleDateFormat(DATE_FORMAT);
logger.info(context_format, new Object[] {batchId, size, memsize, format.format(new Date()), startPosition, endPosition });
}
private static String buildPositionForDump(Entry entry) {
long time = entry.getHeader().getExecuteTime();
Date date = new Date(time);
SimpleDateFormat format = new SimpleDateFormat(DATE_FORMAT);
return entry.getHeader().getLogfileName() + ":" + entry.getHeader().getLogfileOffset() + ":" + entry.getHeader().getExecuteTime() + "(" + format.format(date) + ")";
}
}
- DateUtils
Time tool class, the code is as follows.
package io.mykit.canal.demo.utils;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUtils {
private static final String FORMAT_PATTERN = "yyyy-MM-dd HH:mm:ss";
private static SimpleDateFormat sdf = new SimpleDateFormat(FORMAT_PATTERN);
public static Date parseDate(String datetime) throws ParseException{
if(datetime != null && !"".equals(datetime)){
return sdf.parse(datetime);
}
return null;
}
public static String formatDate(Date datetime) throws ParseException{
if(datetime != null ){
return sdf.format(datetime);
}
return null;
}
public static Long formatStringDateToLong(String datetime) throws ParseException{
if(datetime != null && !"".equals(datetime)){
Date d = sdf.parse(datetime);
return d.getTime();
}
return null;
}
public static Long formatDateToLong(Date datetime) throws ParseException{
if(datetime != null){
return datetime.getTime();
}
return null;
}
}
- InnerBinlogEntry
Binlog entity class. The code is as follows.
package io.mykit.canal.demo.utils;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
public class InnerBinlogEntry {
/**
* canal Native Entry
*/
private Entry entry;
/**
* The table name to which the Entry belongs
*/
private String tableName;
/**
* The Entry belongs to the database name
*/
private String schemaName;
/**
* The operation type of this Entry corresponds to the native enumeration of canal; EventType.INSERT; EventType.UPDATE; EventType.DELETE;
*/
private EventType eventType;
private List<Map<String, BinlogValue>> rows = new ArrayList<Map<String, BinlogValue>>();
public Entry getEntry() {
return entry;
}
public void setEntry(Entry entry) {
this.entry = entry;
}
public String getTableName() {
return tableName;
}
public void setTableName(String tableName) {
this.tableName = tableName;
}
public EventType getEventType() {
return eventType;
}
public void setEventType(EventType eventType) {
this.eventType = eventType;
}
public String getSchemaName() {
return schemaName;
}
public void setSchemaName(String schemaName) {
this.schemaName = schemaName;
}
public List<Map<String, BinlogValue>> getRows() {
return rows;
}
public void setRows(List<Map<String, BinlogValue>> rows) {
this.rows = rows;
}
}
- JacksonUtil
Json tool class, the code is as follows.
package io.mykit.canal.demo.utils;
import java.io.IOException;
import org.codehaus.jackson.JsonGenerationException;
import org.codehaus.jackson.JsonParseException;
import org.codehaus.jackson.map.JsonMappingException;
import org.codehaus.jackson.map.ObjectMapper;
public class JacksonUtil {
private static ObjectMapper mapper = new ObjectMapper();
public static String obj2str(Object obj) {
String json = null;
try {
json = mapper.writeValueAsString(obj);
} catch (JsonGenerationException e) {
e.printStackTrace();
} catch (JsonMappingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return json;
}
public static <T> T str2obj(String content, Class<T> valueType) {
try {
return mapper.readValue(content, valueType);
} catch (JsonParseException e) {
e.printStackTrace();
} catch (JsonMappingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
Implementation of synchronization program
After the entity class and tool class are ready, we can write a synchronization program to synchronize the data in MySQL database to Solr index library in real time. We are in io mykit. canal. demo. MykitCanalDemoSync class is common in the main package. The code is as follows.
package io.mykit.canal.demo.main;
import io.mykit.canal.demo.bean.Book;
import io.mykit.canal.demo.utils.BinlogValue;
import io.mykit.canal.demo.utils.CanalDataParser;
import io.mykit.canal.demo.utils.DateUtils;
import io.mykit.canal.demo.utils.InnerBinlogEntry;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.net.InetSocketAddress;
import java.text.ParseException;
import java.util.List;
import java.util.Map;
public class SyncDataBootStart {
private static Logger logger = LoggerFactory.getLogger(SyncDataBootStart.class);
public static void main(String[] args) throws Exception {
String hostname = "192.168.175.100";
Integer port = 11111;
String destination = "example";
//Get CanalServer connection
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress(hostname, port), destination, "", "");
//Connecting to CanalServer
canalConnector.connect();
//Subscribe to Destination
canalConnector.subscribe();
//Polling pull data
Integer batchSize = 5*1024;
while (true){
Message message = canalConnector.getWithoutAck(batchSize);
long messageId = message.getId();
int size = message.getEntries().size();
if(messageId == -1 || size == 0){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}else{
//Data synchronization
//1. Parse Message object
List<InnerBinlogEntry> innerBinlogEntries = CanalDataParser.convertToInnerBinlogEntry(message);
//2. Synchronize the parsed data information to Solr's index library
syncDataToSolr(innerBinlogEntries);
}
//Submit for confirmation
canalConnector.ack(messageId);
}
}
private static void syncDataToSolr(List<InnerBinlogEntry> innerBinlogEntries) throws Exception {
//Get the connection of solr
SolrServer solrServer = new HttpSolrServer("http://192.168.175.101:8080/solr");
//Traverse the data set and decide to add, modify and delete according to the data information in the data set
if(innerBinlogEntries != null){
for (InnerBinlogEntry innerBinlogEntry : innerBinlogEntries) {
CanalEntry.EventType eventType = innerBinlogEntry.getEventType();
//If it is insert or update, you need to synchronize the data to the solr index library
if(eventType == CanalEntry.EventType.INSERT || eventType == CanalEntry.EventType.UPDATE){
List<Map<String, BinlogValue>> rows = innerBinlogEntry.getRows();
if(rows != null){
for (Map<String, BinlogValue> row : rows) {
BinlogValue id = row.get("id");
BinlogValue name = row.get("name");
BinlogValue author = row.get("author");
BinlogValue publishtime = row.get("publishtime");
BinlogValue price = row.get("price");
BinlogValue publishgroup = row.get("publishgroup");
Book book = new Book();
book.setId(Integer.parseInt(id.getValue()));
book.setName(name.getValue());
book.setAuthor(author.getValue());
book.setPrice(Double.parseDouble(price.getValue()));
book.setPublishgroup(publishgroup.getValue());
book.setPublishtime(DateUtils.parseDate(publishtime.getValue()));
//Import data to solr index library
solrServer.addBean(book);
solrServer.commit();
}
}
}else if(eventType == CanalEntry.EventType.DELETE){
//If it is a Delete operation, you need to Delete the data in the solr index library
List<Map<String, BinlogValue>> rows = innerBinlogEntry.getRows();
if(rows != null){
for (Map<String, BinlogValue> row : rows) {
BinlogValue id = row.get("id");
//Delete solr's index library by ID
solrServer.deleteById(id.getValue());
solrServer.commit();
}
}
}
}
}
}
}
Next, start the main method of SyncDataBootStart class to listen to the Canal Server, and the Canal Server listens to the log changes of MySQL binlog. Once the log of MySQL binlog changes, SyncDataBootStart will immediately receive the change information, parse the change information into a Book object and update it to the Solr Library in real time. If the data is deleted in MySQL database, the data in Solr database will also be deleted in real time.