
Amazon Aurora # not only has the performance and availability of high-end commercial databases, but also has the simplicity and cost-effectiveness of open source databases. It provides five times higher throughput than standard MySQL, and has higher scalability, persistence and security. Amazon Aurora uses a separate architecture of computing and storage. The database cluster includes one or more database computing instances and a data storage layer across multiple availability zones.
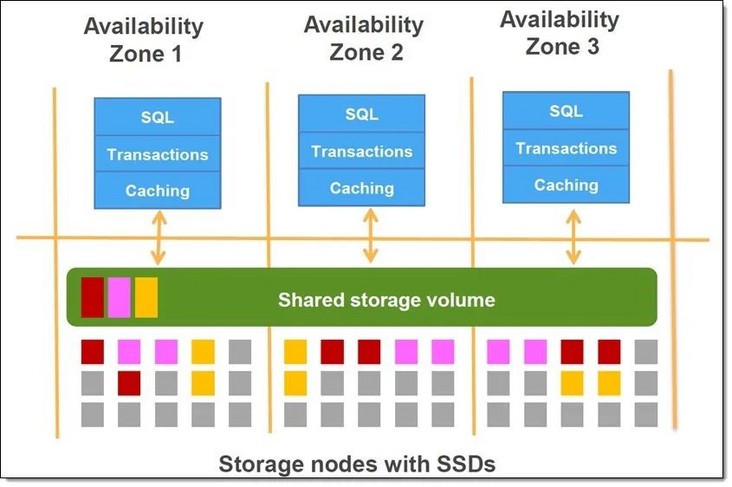
Amazon Aurora cluster architecture diagram
Amazon Aurora Parallel Query (parallel query) is a function of Aurora database, which is applicable to Amazon Aurora compatible with MySQL. Aurora's latest MySQL 5.6 and MySQL 5.7 compatible versions support parallel query. Parallel query makes full use of Aurora's architecture, pushes processing down to Aurora storage layer, and distributes computing to thousands of nodes. By unloading analysis query processing to Auror A storage layer, parallel query reduces the contention with transaction workload for network, CPU and buffer pool, and can improve the query speed by up to two orders of magnitude, while maintaining the high throughput of core transaction workload.
Parallel queries are ideal for Aurora MySQL database clusters with tables containing millions of rows and analytical queries that take minutes or hours to complete. By testing the query time-consuming in each scenario, the enabling of parallel query has little impact on OLTP transactional query, while it can significantly improve the speed of OLAP analytical query. For example, in the experimental scenario: in the data set of tens of millions to hundreds of millions of rows, use dB r5. The 2xlarge model runs a multi table joint analysis query. When parallel query is disabled, it takes 22 minutes and 1.33 seconds. When parallel query is enabled, it takes only 39.74 seconds.
The following is the experimental content, which describes the experimental steps in detail and shows the optimization effect brought by parallel query.
test
Environmental preparation
The test needs to preset Aurora MySQL database cluster and MySQL client instance.
Parallel query has been officially launched in Amazon cloud technology China (Beijing) operated by halo new network and Amazon cloud technology China (Ningxia) operated by West cloud data. This experiment uses Amazon cloud technology China Ningxia.
1. Aurora MySQL database cluster
To create an aurora MySQL Cluster with parallel queries, you can use the same Amazon cloud technology management console and Amazon CLI methods as other Aurora MySQL clusters. You can create a new cluster to use parallel queries, or you can create a database cluster to use parallel queries by restoring from a snapshot of a MySQL compatible Aurora database cluster.
When selecting Aurora MySQL engine version, it is recommended that you select Aurora MySQL 2.09 or higher, the latest engine compatible with MySQL 5.7, and Aurora MySQL 1.23 or higher, which is compatible with MySQL 5.6. With these versions, there are the least restrictions on using parallel queries. These versions also have the greatest flexibility, and parallel queries can be turned on or off at any time.
Aurora MySQL version 2.09 is used in this experiment.
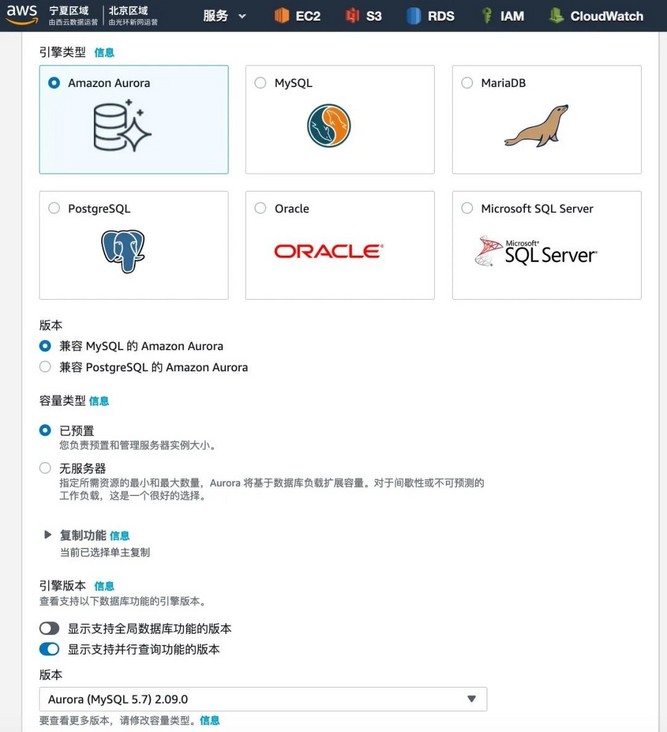
Select the version that supports parallel query
Database instances in the cluster must use dB R * only instance classes can support parallel queries.
In this experiment, two models of large and small data sets are selected. For 10G data set, DB r5. XLarge instance type. For 100G data set, DB r5. 2xlarge instance type.
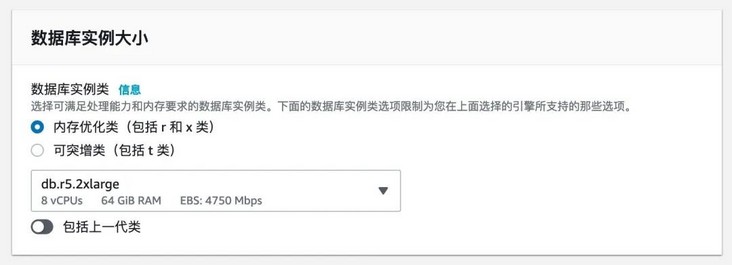
Select the instance type that supports parallel query
For more details, refer to creating database clusters using parallel queries in Aurora user's Guide. https://docs.aws.amazon.com/z...
2. MySQL client instance
According to the options of Aurora MySQL Cluster connection configuration, create an EC2 instance in the network environment that can access the database cluster. Due to the need to generate preloaded measurement data, pay attention to ensure sufficient storage space for instance configuration.
For more details, see enabling instances and connecting to Amazon Aurora database clusters.
Enable instance: https://docs.aws.amazon.com/z...
Amazon Aurora database cluster: https://docs.aws.amazon.com/z...
Data preparation
TPC-H data set was used in this experiment. You can get the table definitions, queries, and dbgen programs that generate sample data from the TPC-H website. Please refer to the following steps to import the dataset into Aurora MySQL Cluster.
http://www.tpc.org/tpch/
1. Download TPC-H tool
Open the TPC Download Current page and find the TPC-H item. The latest version is 2.18 0, click download
http://tpc.org/tpc_documents_...

Download TPC-H tool
Copy the downloaded tool package to the MySQL client instance and unzip it.
2. Generate test data
Enter the subdirectory dbgen and edit the makefile file:
[ec2-user@ip-172-31-42-211 dbgen]$ cp makefile.suite makefile [ec2-user@ip-172-31-42-211 dbgen]$ vi makefile
Update the compiler cc in the makefile file to gcc, the DATABASE engine DATABASE to MYSQL, the operating system MACHINE to LINUX, and the WORKLOAD to TPCH:
################ ## CHANGE NAME OF ANSI COMPILER HERE ################ CC = gcc # Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata) # SQLSERVER, SYBASE, ORACLE, VECTORWISE # Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS, # SGI, SUN, U2200, VMS, LINUX, WIN32 # Current values for WORKLOAD are: TPCH DATABASE=MYSQL MACHINE = LINUX WORKLOAD = TPCH #
Since the default database option in makefile does not have MYSQL option, it needs to be in TPCH Manually add dependencies to the H file.
Open tpcd h. Add code snippets to the file:
#ifdef MYSQL #define GEN_QUERY_PLAN "" #define START_TRAN "START TRANSACTION" #define END_TRAN "COMMIT" #define SET_OUTPUT "" #define SET_ROWCOUNT "limit %d;\n" #define SET_DBASE "use %s;\n" #endif
Execute the compile command make to generate dbgen data generation tool:
[ec2-user@ip-172-31-42-211 dbgen]$ make
Use the dbgen tool to generate data. You can specify the size of the generated data in the parameters. After running, 8 tbl files are generated, corresponding to 8 tables.
This experiment tested two data sets, which were divided into 10G data files and 100G data files.
The small data set specifies 10 parameters, and the generated data file is as follows:
[ec2-user@ip-172-31-42-211 dbgen]$ ./dbgen -s 100 [ec2-user@ip-172-31-42-211 dbgen]$ ls *.tbl -lh -rw-rw-r-- 1 ec2-user ec2-user 234M customer.tbl -rw-rw-r-- 1 ec2-user ec2-user 7.3G lineitem.tbl -rw-rw-r-- 1 ec2-user ec2-user 2.2K nation.tbl -rw-rw-r-- 1 ec2-user ec2-user 1.7G orders.tbl -rw-rw-r-- 1 ec2-user ec2-user 233M part.tbl -rw-rw-r-- 1 ec2-user ec2-user 1.2G partsupp.tbl -rw-rw-r-- 1 ec2-user ec2-user 389 region.tbl -rw-rw-r-- 1 ec2-user ec2-user 14M supplier.tbl
The big data set specifies a parameter of 100, and the generated data file is as follows:
[ec2-user@ip-172-31-42-211 dbgen]$ ./dbgen -s 100 [ec2-user@ip-172-31-42-211 dbgen]$ ls *.tbl -lh -rw-rw-r-- 1 ec2-user ec2-user 2.3G customer.tbl -rw-rw-r-- 1 ec2-user ec2-user 75G lineitem.tbl -rw-rw-r-- 1 ec2-user ec2-user 2.2K nation.tbl -rw-rw-r-- 1 ec2-user ec2-user 17G orders.tbl -rw-rw-r-- 1 ec2-user ec2-user 2.3G part.tbl -rw-rw-r-- 1 ec2-user ec2-user 12G partsupp.tbl -rw-rw-r-- 1 ec2-user ec2-user 389 region.tbl -rw-rw-r-- 1 ec2-user ec2-user 137M supplier.tbl
3. Import test data
Two scripts are provided in the tpch Toolkit: DSS DDL database and table initialization script, DSS Primary key index and foreign key script of RI data table. We will first perform DSS DDL script creates database and tables, and then executes DSS RI creates the primary key index and foreign key Association of the corresponding table, and finally imports the data.
Since the script is not applicable to MySQL, it needs to be adjusted accordingly.
Update DSS DDL header:
create database tpch; use tpch;
Connect to MySQL:
mysql --host=database-test-instance-1.xxx.rds.cn-northwest-1.amazonaws.com.cn --user=admin --password=xxx
Run DSS DDL script, pay attention to replacing the corresponding DSS RI file path:
MySQL [(none)]> \. /home/ec2-user/2.18.0_rc2/dbgen/dss.ddl
To view the successfully built tpch database:
MySQL [tpch]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | tpch | +--------------------+
To view the successfully created database tables:
MySQL [tpch]> use tpch; Database changed MySQL [tpch]> show tables; +----------------+ | Tables_in_tpch | +----------------+ | CUSTOMER | | LINEITEM | | NATION | | ORDERS | | PART | | PARTSUPP | | REGION | | SUPPLIER | +----------------+
Update DSS RI, including modifying the connection mode and updating the CONNECT TO TPCD to use tpch; Replace database name TPCD tpch; Add foreign key Association column; Change the upper case table name to lower case table name to adapt to the query statement; Updated DSS RI complete content:
use tpch;
-- For table REGION
ALTER TABLE tpch.REGION
ADD PRIMARY KEY (R_REGIONKEY);
-- For table NATION
ALTER TABLE tpch.NATION
ADD PRIMARY KEY (N_NATIONKEY);
ALTER TABLE tpch.NATION
ADD FOREIGN KEY NATION_FK1 (N_REGIONKEY) references tpch.REGION(R_REGIONKEY);
COMMIT WORK;
-- For table PART
ALTER TABLE tpch.PART
ADD PRIMARY KEY (P_PARTKEY);
COMMIT WORK;
-- For table SUPPLIER
ALTER TABLE tpch.SUPPLIER
ADD PRIMARY KEY (S_SUPPKEY);
ALTER TABLE tpch.SUPPLIER
ADD FOREIGN KEY SUPPLIER_FK1 (S_NATIONKEY) references tpch.NATION(N_NATIONKEY);
COMMIT WORK;
-- For table PARTSUPP
ALTER TABLE tpch.PARTSUPP
ADD PRIMARY KEY (PS_PARTKEY,PS_SUPPKEY);
COMMIT WORK;
-- For table CUSTOMER
ALTER TABLE tpch.CUSTOMER
ADD PRIMARY KEY (C_CUSTKEY);
ALTER TABLE tpch.CUSTOMER
ADD FOREIGN KEY CUSTOMER_FK1 (C_NATIONKEY) references tpch.NATION(N_NATIONKEY);
COMMIT WORK;
-- For table LINEITEM
ALTER TABLE tpch.LINEITEM
ADD PRIMARY KEY (L_ORDERKEY,L_LINENUMBER);
COMMIT WORK;
-- For table ORDERS
ALTER TABLE tpch.ORDERS
ADD PRIMARY KEY (O_ORDERKEY);
COMMIT WORK;
-- For table PARTSUPP
ALTER TABLE tpch.PARTSUPP
ADD FOREIGN KEY PARTSUPP_FK1 (PS_SUPPKEY) references tpch.SUPPLIER(S_SUPPKEY);
COMMIT WORK;
ALTER TABLE tpch.PARTSUPP
ADD FOREIGN KEY PARTSUPP_FK2 (PS_PARTKEY) references tpch.PART(P_PARTKEY);
COMMIT WORK;
-- For table ORDERS
ALTER TABLE tpch.ORDERS
ADD FOREIGN KEY ORDERS_FK1 (O_CUSTKEY) references tpch.CUSTOMER(C_CUSTKEY);
COMMIT WORK;
-- For table LINEITEM
ALTER TABLE tpch.LINEITEM
ADD FOREIGN KEY LINEITEM_FK1 (L_ORDERKEY) references tpch.ORDERS(O_ORDERKEY);
COMMIT WORK;
ALTER TABLE tpch.LINEITEM
ADD FOREIGN KEY LINEITEM_FK2 (L_PARTKEY,L_SUPPKEY) references
tpch.PARTSUPP(PS_PARTKEY,PS_SUPPKEY);
COMMIT WORK;
alter table CUSTOMER rename to customer ;
alter table LINEITEM rename to lineitem ;
alter table NATION rename to nation ;
alter table ORDERS rename to orders ;
alter table PART rename to part ;
alter table PARTSUPP rename to partsupp ;
alter table REGION rename to region ;
alter table SUPPLIER rename to supplier ;Run DSS RI script establishes database table primary key and foreign key, and pay attention to replacing the corresponding DSS RI file path:
MySQL [(none)]> \. /home/ec2-user/2.18.0_rc2/dbgen/dss.ri
Execute the script in order to import the tbl file into the corresponding table of the database. Note to replace the corresponding tbl file path:
load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/region.tbl' into table region fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/nation.tbl' into table nation fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/part.tbl' into table part fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/supplier.tbl' into table supplier fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/partsupp.tbl' into table partsupp fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/customer.tbl' into table customer fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/orders.tbl' into table orders fields terminated by '|' lines terminated by '|\n'; load data local infile '/home/ec2-user/2.18.0_rc2/dbgen/lineitem.tbl' into table lineitem fields terminated by '|' lines terminated by '|\n';
After the import is completed, you can view the imported data. The tables used in the test query include customer, lineitem and orders. Please observe the import status of each table.
The following is the import status of 10G level data table. The data table has millions of rows to tens of millions of rows of data:
MySQL [tpch]> show table status; +----------+--------+---------+------------+----------+----------------+-------------+ | Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | +----------+--------+---------+------------+----------+----------------+-------------+ | customer | InnoDB | 10 | Dynamic | 1480453 | 194 | 288112640 | | lineitem | InnoDB | 10 | Dynamic | 55000836 | 148 | 8158969856 | | nation | InnoDB | 10 | Dynamic | 25 | 655 | 16384 | | orders | InnoDB | 10 | Dynamic | 14213703 | 131 | 1873805312 | | part | InnoDB | 10 | Dynamic | 1912304 | 162 | 310149120 | | partsupp | InnoDB | 10 | Dynamic | 7467820 | 268 | 2005925888 | | region | InnoDB | 10 | Dynamic | 5 | 3276 | 16384 | | supplier | InnoDB | 10 | Dynamic | 98503 | 186 | 18366464 | +----------+--------+---------+------------+----------+----------------+-------------+
The following is the import status of 100G level data table, which has tens of millions to hundreds of millions of rows of data:
+----------+--------+---------+------------+-----------+----------------+-------------+ | Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | +----------+--------+---------+------------+-----------+----------------+-------------+ | customer | InnoDB | 10 | Dynamic | 13528638 | 194 | 2631925760 | | lineitem | InnoDB | 10 | Dynamic | 106592268 | 137 | 14687404032 | | nation | InnoDB | 10 | Dynamic | 25 | 655 | 16384 | | orders | InnoDB | 10 | Dynamic | 141958614 | 131 | 18708692992 | | part | InnoDB | 10 | Dynamic | 18240054 | 162 | 2970615808 | | partsupp | InnoDB | 10 | Dynamic | 79991226 | 252 | 20198719488 | | region | InnoDB | 10 | Dynamic | 5 | 3276 | 16384 | | supplier | InnoDB | 10 | Dynamic | 988185 | 178 | 176865280 | +----------+--------+---------+------------+-----------+----------------+-------------+
Query test
In Aurora MySQL 1.23 or 2.09 and later, parallel query and hash join settings are turned off by default. Parallel queries can be enabled or disabled by modifying the database parameter aurora_parallel_query. The default parameter group is read-only. Please refer to using database parameter group and database cluster parameter group for modifying parameter group. https://docs.aws.amazon.com/z...
To check the startup status of cluster parallel query, the following commands are available:
mysql> select @@aurora_parallel_query; +-------------------------+ | @@aurora_parallel_query | +-------------------------+ | 1 | +-------------------------+
By default, even if parallel query is enabled, the Aurora query optimizer will automatically decide whether to use parallel query according to the query. You can use the command to force it on at the session level to override the automatic selection of the query optimizer:
mysql> set aurora_pq_force = 1;
This experiment uses different query scripts to test single table transaction query, single table analysis query and multi table analysis query.
The tables involved in the query script include: orders, customer, lineitem
The structure of the orders table is as follows:
MySQL [tpch]> describe orders; +-----------------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------------+---------------+------+-----+---------+-------+ | O_ORDERKEY | int(11) | NO | PRI | NULL | | | O_CUSTKEY | int(11) | NO | MUL | NULL | | | O_ORDERSTATUS | char(1) | NO | | NULL | | | O_TOTALPRICE | decimal(15,2) | NO | | NULL | | | O_ORDERDATE | date | NO | | NULL | | | O_ORDERPRIORITY | char(15) | NO | | NULL | | | O_CLERK | char(15) | NO | | NULL | | | O_SHIPPRIORITY | int(11) | NO | | NULL | | | O_COMMENT | varchar(79) | NO | | NULL | | +-----------------+---------------+------+-----+---------+-------+
The structure of the customer table is as follows:
MySQL [tpch]> describe customer; +--------------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+---------------+------+-----+---------+-------+ | C_CUSTKEY | int(11) | NO | PRI | NULL | | | C_NAME | varchar(25) | NO | | NULL | | | C_ADDRESS | varchar(40) | NO | | NULL | | | C_NATIONKEY | int(11) | NO | MUL | NULL | | | C_PHONE | char(15) | NO | | NULL | | | C_ACCTBAL | decimal(15,2) | NO | | NULL | | | C_MKTSEGMENT | char(10) | NO | | NULL | | | C_COMMENT | varchar(117) | NO | | NULL | | +--------------+---------------+------+-----+---------+-------+
The lineitem table structure is as follows:
MySQL [tpch]> describe lineitem; +-----------------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------------+---------------+------+-----+---------+-------+ | L_ORDERKEY | int(11) | NO | PRI | NULL | | | L_PARTKEY | int(11) | NO | MUL | NULL | | | L_SUPPKEY | int(11) | NO | | NULL | | | L_LINENUMBER | int(11) | NO | PRI | NULL | | | L_QUANTITY | decimal(15,2) | NO | | NULL | | | L_EXTENDEDPRICE | decimal(15,2) | NO | | NULL | | | L_DISCOUNT | decimal(15,2) | NO | | NULL | | | L_TAX | decimal(15,2) | NO | | NULL | | | L_RETURNFLAG | char(1) | NO | | NULL | | | L_LINESTATUS | char(1) | NO | | NULL | | | L_SHIPDATE | date | NO | | NULL | | | L_COMMITDATE | date | NO | | NULL | | | L_RECEIPTDATE | date | NO | | NULL | | | L_SHIPINSTRUCT | char(25) | NO | | NULL | | | L_SHIPMODE | char(10) | NO | | NULL | | | L_COMMENT | varchar(44) | NO | | NULL | | +-----------------+---------------+------+-----+---------+-------+
The single table transaction query script is as follows: query according to the conditions specified in different columns of the orders table:
SELECT * FROM orders WHERE o_custkey = 3689999 AND o_orderdate > date '1995-03-14' AND o_orderstatus = 'O' LIMIT 15;
The single table analysis query script is as follows. Conditions are specified for different columns of the orders table, and the statistical function avg is used for analysis query:
SELECT avg(o_totalprice)
FROM orders
WHERE o_orderdate > date '1995-03-14'
AND o_orderstatus = 'O'
AND o_orderpriority not in ('1-URGENT', '2-HIGH');The multi table analysis query script is as follows, associating multi table customers, orders and lineitem, and specifying criteria for analysis query:
SELECT l_orderkey, SUM(l_extendedprice * (1-l_discount)) AS revenue, o_orderdate, o_shippriority FROM customer, orders, lineitem WHERE c_mktsegment='AUTOMOBILE' AND c_custkey = o_custkey AND l_orderkey = o_orderkey AND o_orderdate < date '1995-03-14' AND l_shipdate > date '1995-03-14' GROUP BY l_orderkey, o_orderdate, o_shippriority ORDER BY revenue DESC, o_orderdate LIMIT 15;
In the multi table joint query scenario, when Aurora MySQL needs to use equijoin to join a large amount of data, hash join can improve the query performance. To enable hash join for parallel query clusters, you can set the cluster configuration parameter aurora_disable_hash_join=OFF to enable hash join optimization in conjunction with parallel queries.
To check the startup status of cluster hash join optimization, the following commands are available:
mysql> select @@aurora_disable_hash_join; +----------------------------+ | @@aurora_disable_hash_join | +----------------------------+ | 0 | +----------------------------+
Aurora query optimizer will automatically decide whether to use hash join according to the query. You can use the command to force it on at the session level to override the automatic selection of the query optimizer:
mysql> SET optimizer_switch='hash_join=on'; mysql> SET optimizer_switch='hash_join_cost_based=off';
This experiment was conducted on two database clusters with two data sets (db.r5.xlarge database cluster with 10G test data set and db.r5.2xlarge database cluster with 100G test data set) according to the following steps:
- Disable parallel query. Check and confirm the disabled status of parallel query
- Run single table transaction query script
- Analyze single table transaction query execution plan
- Run single table analysis query script
- Analysis table analysis query execution plan
- Run multi table analysis query script
- Analyze multi table analysis query execution plan
Enable parallel query and hash connection. Check and confirm the enabling status of parallel query and hash connection - Run single table transaction query script
- Analyze single table transaction query execution plan
- Run single table analysis query script
- Analysis table analysis query execution plan
- Run multi table analysis query script
- Analyze multi table analysis query execution plan
By analyzing query plans, we can see the difference between traditional query plans and parallel query plans. When parallel queries are enabled, the steps in the query can be optimized using parallel queries, as shown in the Extra column in the EXPLAIN output. The I/O-Intensive and CPU intensive processing of these steps is pushed down to the storage tier.
The following is the query results and execution plan analysis of 100G test data set:
Results of single table transaction query (parallel query disabled):
MySQL [tpch]> SELECT *
-> FROM orders
-> WHERE o_custkey = 3689999
-> AND o_orderdate > date '1995-03-14'
-> AND o_orderstatus = 'O'
-> LIMIT 15;
+------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+-----------------------------------------------------------------+
| O_ORDERKEY | O_CUSTKEY | O_ORDERSTATUS | O_TOTALPRICE | O_ORDERDATE | O_ORDERPRIORITY | O_CLERK | O_SHIPPRIORITY | O_COMMENT |
+------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+-----------------------------------------------------------------+
| 1 | 3689999 | O | 224560.83 | 1996-01-02 | 5-LOW | Clerk#000095055 | 0 | nstructions sleep furiously among |
| 37007300 | 3689999 | O | 189889.17 | 1998-05-12 | 5-LOW | Clerk#000097117 | 0 | ully. carefully busy accoun |
| 110398694 | 3689999 | O | 40190.10 | 1998-06-08 | 3-MEDIUM | Clerk#000071343 | 0 | ideas? quickly thin accounts wake slyly. blithely |
| 166279651 | 3689999 | O | 8270.88 | 1997-10-23 | 1-URGENT | Clerk#000039384 | 0 | ic, final accounts sleep. blithely pending requests nag slyly u |
| 276450979 | 3689999 | O | 43595.81 | 1997-04-26 | 3-MEDIUM | Clerk#000010520 | 0 | quickly alongside of the furiously expr |
| 404928295 | 3689999 | O | 20719.85 | 1996-11-05 | 2-HIGH | Clerk#000027012 | 0 | y regular platelets |
+------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+-----------------------------------------------------------------+
6 rows in set (0.00 sec)Execution plan analysis of single table transaction query (parallel query disabled):
+----+-------------+--------+...+-------------+ | id | select_type | table |...| Extra | +----+-------------+--------+...+-------------+ | 1 | SIMPLE | orders |...| Using where | +----+-------------+--------+...+-------------+
Results of single table transaction query (enabling parallel query):
MySQL [tpch]> SELECT *
-> FROM orders
-> WHERE o_custkey = 3689999
-> AND o_orderdate > date '1995-03-14'
-> AND o_orderstatus = 'O'
-> LIMIT 15;
+------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+-----------------------------------------------------------------+
| O_ORDERKEY | O_CUSTKEY | O_ORDERSTATUS | O_TOTALPRICE | O_ORDERDATE | O_ORDERPRIORITY | O_CLERK | O_SHIPPRIORITY | O_COMMENT |
+------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+-----------------------------------------------------------------+
| 1 | 3689999 | O | 224560.83 | 1996-01-02 | 5-LOW | Clerk#000095055 | 0 | nstructions sleep furiously among |
| 37007300 | 3689999 | O | 189889.17 | 1998-05-12 | 5-LOW | Clerk#000097117 | 0 | ully. carefully busy accoun |
| 110398694 | 3689999 | O | 40190.10 | 1998-06-08 | 3-MEDIUM | Clerk#000071343 | 0 | ideas? quickly thin accounts wake slyly. blithely |
| 166279651 | 3689999 | O | 8270.88 | 1997-10-23 | 1-URGENT | Clerk#000039384 | 0 | ic, final accounts sleep. blithely pending requests nag slyly u |
| 276450979 | 3689999 | O | 43595.81 | 1997-04-26 | 3-MEDIUM | Clerk#000010520 | 0 | quickly alongside of the furiously expr |
| 404928295 | 3689999 | O | 20719.85 | 1996-11-05 | 2-HIGH | Clerk#000027012 | 0 | y regular platelets |
+------------+-----------+---------------+--------------+-------------+-----------------+-----------------+----------------+-----------------------------------------------------------------+
6 rows in set (0.00 sec)Execution plan analysis of single table transaction query (enabling parallel query):
+----+-------------+--------+...+-------------+ | id | select_type | table |...| Extra | +----+-------------+--------+...+-------------+ | 1 | SIMPLE | orders |...| Using where | +----+-------------+--------+...+-------------+
Results of single table analysis query (parallel query disabled):
MySQL [tpch]> SELECT avg(o_totalprice)
-> FROM orders
-> WHERE o_orderdate > date '1995-03-14'
-> AND o_orderstatus = 'O'
-> AND o_orderpriority not in ('1-URGENT', '2-HIGH');
+-------------------+
| avg(o_totalprice) |
+-------------------+
| 150271.119856 |
+-------------------+
1 row in set (5 min 39.08 sec)Execution plan analysis of single table analysis query (parallel query disabled):
+----+-------------+--------+...+-------------+ | id | select_type | table |...| Extra | +----+-------------+--------+...+-------------+ | 1 | SIMPLE | orders |...| Using where | +----+-------------+--------+...+-------------+
Results of single table analysis query (enabling parallel query):
MySQL [tpch]> SELECT avg(o_totalprice)
-> FROM orders
-> WHERE o_orderdate > date '1995-03-14'
-> AND o_orderstatus = 'O'
-> AND o_orderpriority not in ('1-URGENT', '2-HIGH');
+-------------------+
| avg(o_totalprice) |
+-------------------+
| 150271.119856 |
+-------------------+
1 row in set (20.24 sec)Execution plan analysis of single table analysis query (enabling parallel query):
+----+-------------+--------+...+----------------------------------------------------------------------------+ | id | select_type | table |...| Extra | +----+-------------+--------+...+----------------------------------------------------------------------------+ | 1 | SIMPLE | orders |...| Using where; Using parallel query (5 columns, 2 filters, 1 exprs; 0 extra) | +----+-------------+--------+...+----------------------------------------------------------------------------+
Results of multi table analysis query (parallel query disabled):
MySQL [tpch]> SELECT
-> l_orderkey,
-> SUM(l_extendedprice * (1-l_discount)) AS revenue,
-> o_orderdate,
-> o_shippriority
-> FROM customer, orders, lineitem
-> WHERE
-> c_mktsegment='AUTOMOBILE'
-> AND c_custkey = o_custkey
-> AND l_orderkey = o_orderkey
-> AND o_orderdate < date '1995-03-14'
-> AND l_shipdate > date '1995-03-14'
-> GROUP BY
-> l_orderkey,
-> o_orderdate,
-> o_shippriority
-> ORDER BY
-> revenue DESC,
-> o_orderdate LIMIT 15;
+------------+-------------+-------------+----------------+
| l_orderkey | revenue | o_orderdate | o_shippriority |
+------------+-------------+-------------+----------------+
| 81011334 | 455300.0146 | 1995-03-07 | 0 |
| 28840519 | 454748.2485 | 1995-03-08 | 0 |
| 16384100 | 450935.1906 | 1995-03-02 | 0 |
| 72587110 | 443895.1245 | 1995-03-01 | 0 |
| 11982337 | 433364.5961 | 1995-02-15 | 0 |
| 34736612 | 428316.3377 | 1995-02-19 | 0 |
| 62597284 | 425985.1162 | 1995-03-04 | 0 |
| 59481859 | 421696.5251 | 1995-03-12 | 0 |
| 76740996 | 421355.8745 | 1995-02-25 | 0 |
| 20601378 | 419369.0300 | 1995-03-13 | 0 |
| 23482308 | 418992.5933 | 1995-02-14 | 0 |
| 3400066 | 418830.9286 | 1995-03-06 | 0 |
| 53367108 | 413322.3462 | 1995-03-06 | 0 |
| 44846022 | 412002.8474 | 1995-03-06 | 0 |
| 41160167 | 409386.8393 | 1995-03-09 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (22 min 1.33 sec)Execution plan analysis of multi table analysis query (parallel query disabled):
+----+-------------+----------+...+----------------------------------------------+ | id | select_type | table |...| Extra | +----+-------------+----------+...+----------------------------------------------+ | 1 | SIMPLE | customer |...| Using where; Using temporary; Using filesort | | 1 | SIMPLE | orders |...| Using where | | 1 | SIMPLE | lineitem |...| Using where | +----+-------------+----------+...+----------------------------------------------+
Results of multi table analysis query (parallel query enabled):
MySQL [tpch]> SELECT
-> l_orderkey,
-> SUM(l_extendedprice * (1-l_discount)) AS revenue,
-> o_orderdate,
-> o_shippriority
-> FROM customer, orders, lineitem
-> WHERE
-> c_mktsegment='AUTOMOBILE'
-> AND c_custkey = o_custkey
-> AND l_orderkey = o_orderkey
-> AND o_orderdate < date '1995-03-14'
-> AND l_shipdate > date '1995-03-14'
-> GROUP BY
-> l_orderkey,
-> o_orderdate,
-> o_shippriority
-> ORDER BY
-> revenue DESC,
-> o_orderdate LIMIT 15;
+------------+-------------+-------------+----------------+
| l_orderkey | revenue | o_orderdate | o_shippriority |
+------------+-------------+-------------+----------------+
| 81011334 | 455300.0146 | 1995-03-07 | 0 |
| 28840519 | 454748.2485 | 1995-03-08 | 0 |
| 16384100 | 450935.1906 | 1995-03-02 | 0 |
| 72587110 | 443895.1245 | 1995-03-01 | 0 |
| 11982337 | 433364.5961 | 1995-02-15 | 0 |
| 34736612 | 428316.3377 | 1995-02-19 | 0 |
| 62597284 | 425985.1162 | 1995-03-04 | 0 |
| 59481859 | 421696.5251 | 1995-03-12 | 0 |
| 76740996 | 421355.8745 | 1995-02-25 | 0 |
| 20601378 | 419369.0300 | 1995-03-13 | 0 |
| 23482308 | 418992.5933 | 1995-02-14 | 0 |
| 3400066 | 418830.9286 | 1995-03-06 | 0 |
| 53367108 | 413322.3462 | 1995-03-06 | 0 |
| 44846022 | 412002.8474 | 1995-03-06 | 0 |
| 41160167 | 409386.8393 | 1995-03-09 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (39.74 sec)Execution plan analysis of multi table analysis query (enabling parallel query):
+----+-------------+----------+...+--------------------------------------------------------------------------------------------------------------------------------+ | id | select_type | table |...| Extra | +----+-------------+----------+...+--------------------------------------------------------------------------------------------------------------------------------+ | 1 | SIMPLE | customer |...| Using where; Using temporary; Using filesort; Using parallel query (2 columns, 1 filters, 0 exprs; 0 extra) | | 1 | SIMPLE | orders |...| Using where; Using join buffer (Hash Join Outer table orders); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) | | 1 | SIMPLE | lineitem |...| Using where; Using join buffer (Hash Join Outer table lineitem); Using parallel query (5 columns, 1 filters, 1 exprs; 0 extra) | +----+-------------+----------+...+--------------------------------------------------------------------------------------------------------------------------------+
In addition to monitoring the Amazon CloudWatch indicators described in the Amazon Aurora database cluster indicators, Aurora also provides other global status variables. You can use these global state variables to help monitor the execution of parallel queries. They give you insight into why the optimizer may or may not use parallel queries in a given situation. For a complete list of variables, see monitoring parallel queries.
https://docs.aws.amazon.com/z...
Run the following command to view the status related to parallel queries:
MySQL [tpch]> SHOW GLOBAL STATUS LIKE 'Aurora_pq%'; +--------------------------------------------------------------+-------+ | Variable_name | Value | +--------------------------------------------------------------+-------+ | Aurora_pq_max_concurrent_requests | 4 | | Aurora_pq_request_attempted | 1 | | Aurora_pq_request_attempted_grouping_aggr | 0 | | Aurora_pq_request_attempted_partition_table | 0 | | Aurora_pq_request_by_force_config | 1 | | Aurora_pq_request_by_global_config | 0 | | Aurora_pq_request_by_hint | 0 | | Aurora_pq_request_by_session_config | 0 | | Aurora_pq_request_executed | 1 |
summary
By testing the workload, this paper shows the query time in each scenario. The enabling of parallel query has little impact on OLTP transactional query, while it significantly improves the query speed for OLAP analytical query.
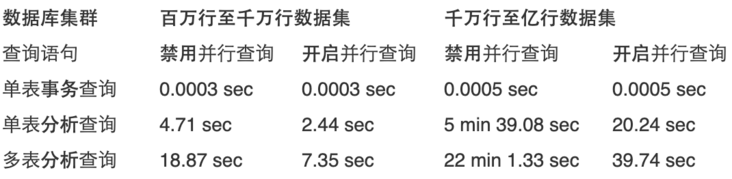
Note: single table transaction query is an OLTP query statement, which uses foreign keys, and the query speed is very fast; Single table analysis query and multi table analysis query are OLAP query statements, which require full table scanning and associated query, and the query takes a long time.
Using parallel queries, you can run data intensive analytical queries against Aurora MySQL tables. In many cases, compared with the traditional query processing division, the performance is improved by an order of magnitude, while maintaining the high throughput of the core transaction workload.
You can enable parallel queries in new or existing Aurora clusters by clicking several times in Amazon RDS console or downloading the latest Amazon cloud technology development kit or CLI. Please read Aurora documentation for more information.
Amazon RDS console:
https://console.aws.amazon.co...
urora document: https://docs.aws.amazon.com/A...
You can combine parallel queries with other Aurora MySQL 5.7 functions such as global databases. In addition, the applicability of this function to MySQL 5.7 and MySQL 5.6 databases has been extended to more than 20 Amazon cloud technology regions including Beijing and Ningxia, China. For a complete list of regions that provide parallel queries, see aurora pricing.
https://aws.amazon.com/cn/rds...
Author of this article
Lin Yuchen
Amazon cloud technology solution architect
Responsible for Cloud Architecture Consulting and design in the Internet industry. Engaged in Microsoft Solution Development and consulting from, microsoft certified technical expert. Previously, he worked for Thomson Reuters as a technical expert, participated in the design and development of financial data platform, and has rich experience in metadata management system architecture design and process automation.