An article takes you to understand the introduction syntax of C + +
C + + keyword (C++98)
There are 63 keywords in C + + and 32 keywords in C language
Let's take a look at the keywords of C + + through the table
| asm | do | if | return | try | continue |
|---|---|---|---|---|---|
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | export | new | struct | using | friend |
| class | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
Namespace
In C/C + +, there are a large number of variables, functions and classes to be learned later. The names of these variables, functions and classes exist in the global scope, which may lead to many conflicts. The purpose of using namespace is to localize the name of identifier to avoid naming conflict or name pollution. The emergence of namespace keyword is aimed at this problem.
Namespace definition
To define a namespace, you need to use the namespace keyword, followed by the name of the namespace, followed by a pair of {}, which are the members of the namespace.
//Defines a namespace called mlf -- domain
namespace mlf
{
//1. Variables / functions / types can be defined in the namespace
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
Namespaces can also be nested
//2. Namespaces can be nested
namespace mlf
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace lf
{
int c;
int d;
int Sub(int left, int right)
{
return left + right;
}
}
}
Note: a namespace defines a new scope, and all contents in the namespace are limited to the namespace.
Use of namespaces
Before learning how to use namespaces, let's first think about a question: * * why does C + + have namespaces? What are namespaces used for** 1. Variables and functions defined by ourselves may conflict with duplicate names in the library. 2. After entering the company's project team, the projects are usually relatively large. Multi person collaboration, code written by two colleagues, naming conflict. C language can't solve this problem well, so CPP puts forward a new syntax - namespace.
The implementation of the C + + library is defined in a namespace called std
There are three ways to use namespaces:
1. Specify the namespace - this is the most standardized and standard
int main()
{
std::cout << "hello world!" << std::endl;
return 0;
}
2. Expand the commonly used
//Expand common
using std::cout;
using std::endl;
int main()
{
cout << "hello world!" << endl;
return 0;
}
3. Expand the std namespace and use it directly. Although convenient, it is easy to cause naming conflicts. You can write code in this way at ordinary times, but don't write it in this way when writing projects or projects in the future. You have to write it in the first way.
using namespace std;
int main()
{
cout << "hello world!" << endl;
return 0;
}
C + + input and output
We all know that the input and output of C language are printf and scanf respectively. What are the input and output in C + +? In C + +, cout standard output (console) and cin standard input (keyboard) are used. When using them, you must include header files and std standard namespaces. Note: the following endl means line feed, which is equivalent to printf("\n");
#include<iostream>
using namespace std;
int main()
{
cout << "Hello World!" << endl;
return 0;
}
Conclusion: Generally speaking, it is more convenient to use c + + input and output without adding data format control, such as integer% d and character% c. However, printf is more convenient when outputting structures. In a word, you can use whichever is convenient.
#include<iostream>
using namespace std;
int main()
{
//< < stream insert
//Both it and printf can be used, whichever is convenient
cout << "hello world" << endl;
const char* str = "hello lf";
cout << str << endl;
int i = 2;
double d = 1.11;
cout << i << " " << d << endl;
printf("%d %.2lf\n", i, d);
struct Student
{
char name[20];
int age;
//...
};
struct Student s = { "Ling Feng", 20 };
//cpp
cout << "full name:" << s.name << endl;
cout << "Age:" << s.age << endl;
//c
printf("full name:%s\n Age:%d\n", s.name, s.age);
//>>Stream extraction operator
cin >> s.name >> s.age;
cout << "full name:" << s.name << endl;
cout << "Age:" << s.age << endl;
scanf("%s%d", s.name, &s.age);
printf("full name:%s\n Age:%d\n", s.name, s.age);
return 0;
}
Default parameters
Concept of default parameters
The default parameter is a default value specified for the function's parameters when the function is declared or defined. When calling the function, if no argument is specified, the default value is adopted; otherwise, the specified argument is used.
//Default parameters
//It is equivalent to a default value specified for function parameters
void Func(int a = 0)
{
cout << a << endl;
}
int main()
{
Func();//When no parameter is passed, the default value of the parameter is used
Func(1);//When transmitting parameters. Use specified arguments
return 0;
}
Classification of default parameters
There are two kinds of default parameters - one is full default parameter and the other is semi default parameter. Let's introduce these two default parameters.
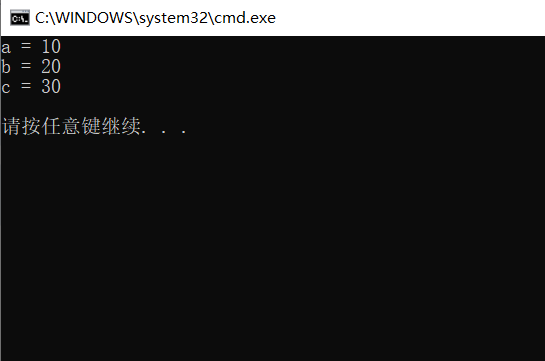
1. All default parameters
//Full default
void Func(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Func();
printf("\n");
}
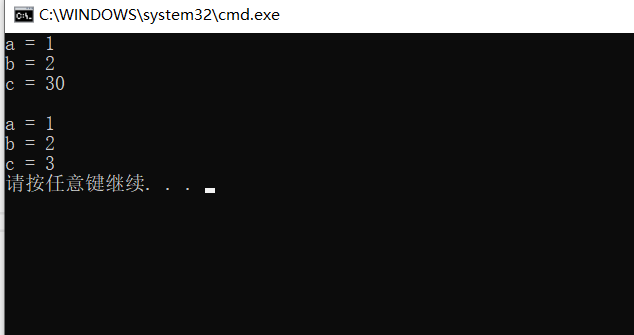
2. Semi default parameters
//Semi default -- default partial parameters -- must default from right to left, and must default continuously
void Func(int a, int b, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Func(1, 2);
printf("\n");
Func(1, 2, 3);
return 0;
}
be careful:
1. The semi default parameters must be given from right to left, and cannot be given at intervals
2. Default parameters cannot appear in function declaration and definition at the same time
//a.h
void func(int a = 10);
//a.c
void func(int a = 20)
{
}
//Note: if the declaration and definition locations appear at the same time, and the values provided by the two locations happen to be different, the compiler cannot determine which default value to use.
3. The default value must be a constant or a global variable
4.C language does not support default parameters (compiler does not support them)
function overloading
In natural language, a word can have multiple meanings. People can judge the true meaning of the word through the context, that is, the word is overloaded. For example, there is a joke that there are two sports in China. You don't have to watch or worry at all. One is table tennis and the other is men's football. The former is "no one can win!", The latter is "no one can win!"
Concept of function overloading
Function overloading: it is a special case of functions. C + + allows to declare several functions with the same name with similar functions in the same scope, * * the formal parameter list (number or type or order of parameters) of these functions with the same name must be different, * * it is commonly used to deal with the problems of similar functions and different data types.
//Function overload (first, the function name is the same, then the number of function parameters, the type of function parameters and the order of parameters are different. As long as one of them is met, it can constitute a function overload
//It is independent of the return value type of the function
//1. Different types of function parameters
int Add(int left, int right)
{
cout << "int Add(int left,int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left,double right)"<<endl;
return left + right;
}
//2. The number of function parameters is different
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
//3. The order of function parameters is different
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b,int a)" << endl;
}
int main()
{
Add(1, 2);
printf("\n");
Add(1.1, 2.2);
printf("\n");
f(1, 'c');
printf("\n");
f('b', 2);
return 0;
}
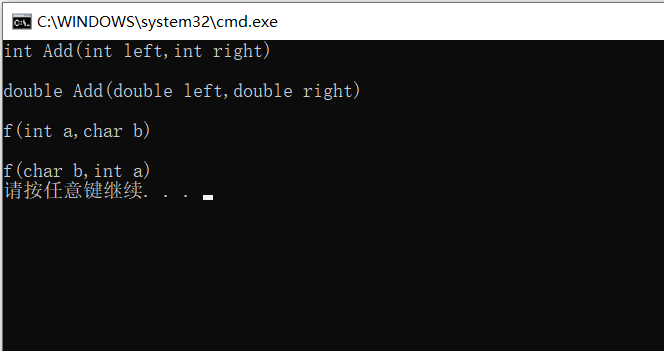
In general: if a function wants to constitute a function overload, first, the function name must be the same. Secondly, the number of function parameters, the type of function parameters and the order of parameters are different. As long as one of them is met, it can constitute a function overload, which is independent of the return value type of the function.
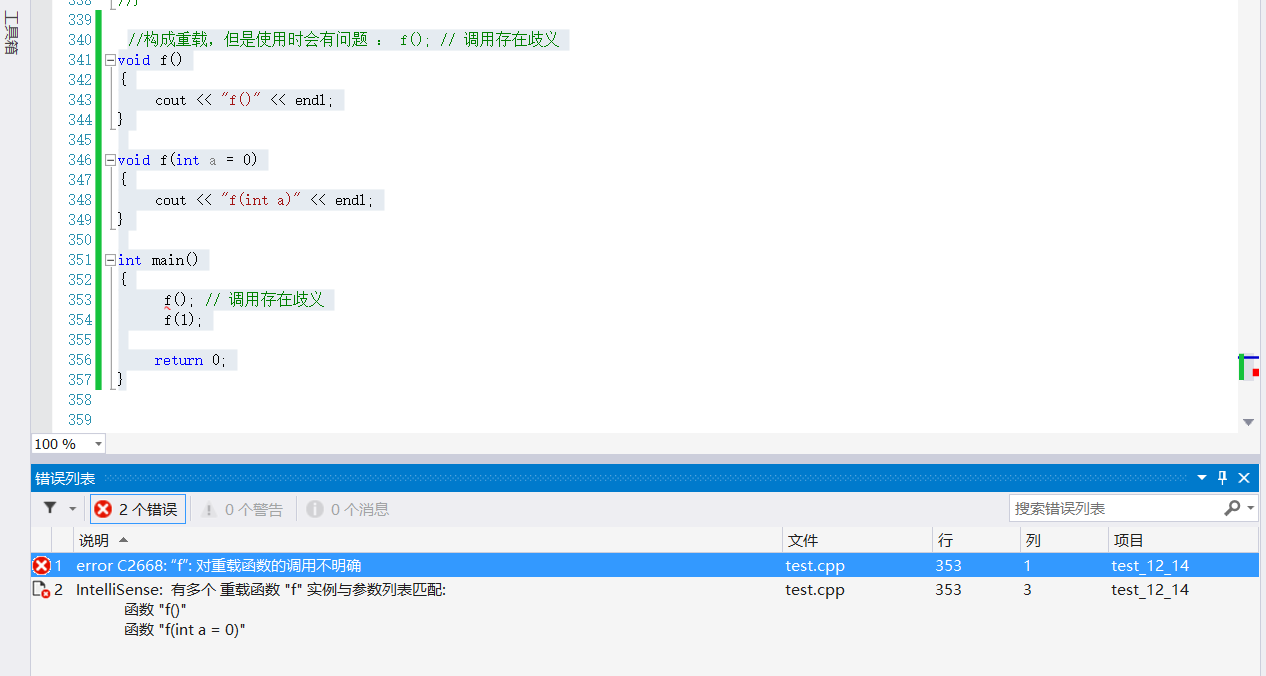
Note: in some cases, although it constitutes a function overload, there will be ambiguity when calling
//Constitute an overload, but there will be problems when using: f()// Ambiguous call
void f()
{
cout << "f()" << endl;
}
void f(int a = 0)
{
cout << "f(int a)" << endl;
}
int main()
{
f(); // Ambiguous call
f(1);
return 0;
}
Interview questions
1. Why does C + + support function overloading, but C language does not support function overloading? How does the underlying C + + support overloading?
The principle of function overloading is inconvenient to show in VS. next, I will show you in Linux.
We first created func h,func.c,test.c these three documents
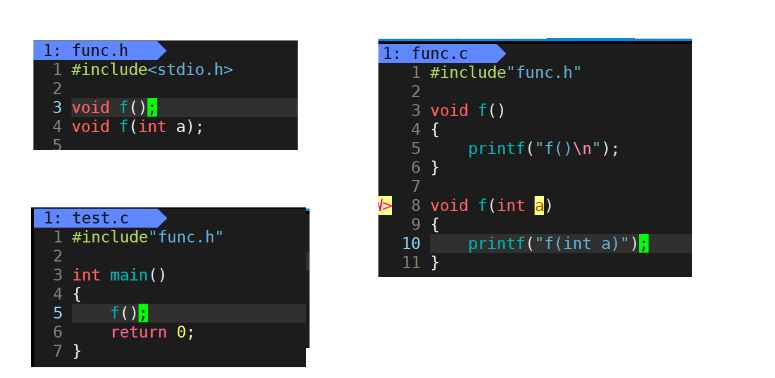
In C/C + +, a program needs to go through the following stages: preprocessing, compilation, assembly and linking.
Before we begin, let's briefly review the process of compiling this program by the compiler
func.h func.c test.c
//1. Preprocessing - > header file expansion, macro replacement, conditional compilation, removing comments
func.i,test.i
//2. Compile - > check syntax and generate assembly code
func.s,test.s
//3. Assembly - > Convert assembly code to binary machine code
func.o,test.o
//4. link
a.out
**We generated fun. Com by preprocessing and compiling the assembly O and test O file. It should be noted that there is no function address when we compile, but why can we compile it? This is because we have a function declaration. If we want to call this function later, we just need to fill in the address of the function when linking. It's similar to this - you're getting married recently and you're going to buy a house, but you're still 5w yuan short. Then you call your buddy and say I'm going to buy a house recently, but you're still 5w yuan short. Ask him to borrow 5w yuan. Then your buddy says it's no problem. It's basically stable at this time. This is equivalent to a statement, because your brother hasn't called the 50000 yuan. But when you hear Alipay arrival 5w yuan, when the function has its address, you can pay the down payment to buy a house. When the compiler sees test O when calling f function, if you find that there is no address of f function, you will go to func O's symbol table, and then link them together. When linking, how does the linker find the f function? Let's talk about it in detail.
C language does not support function overloading, because when compiling, two overloaded functions have the same function name in fun O there are ambiguities and conflicts in the symbol table. Secondly, there are ambiguities and conflicts when linking, because they all directly use the function name to identify and find, while overloaded functions have the same function name.
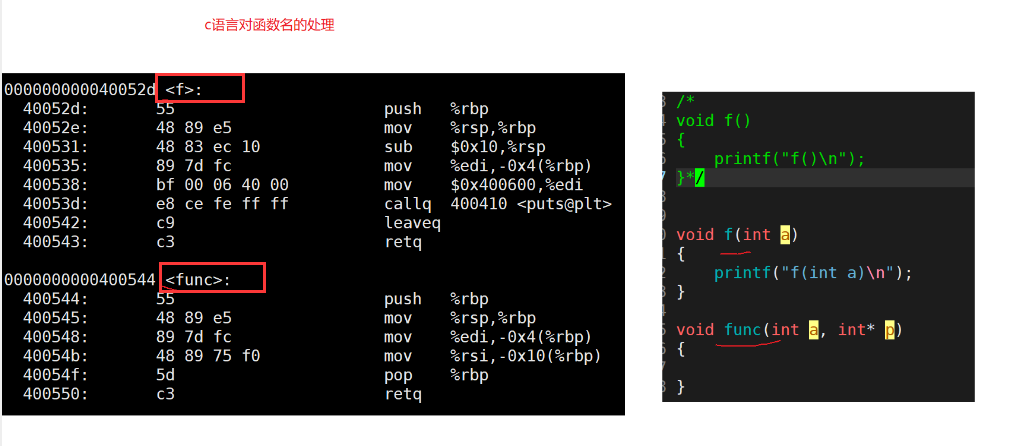
C + + supports function overloading because function names are not directly used to identify and find functions in the symbol table of C + + object files
1.C + + has function name modification rules, but the modification rules are different for different compilers. Modification rules for g + + function names under Linux:_ Z + function name length + function name + parameter name initial
2. With the modification rule of function name, func O the overloaded functions in the symbol table do not have ambiguity and conflict
3. When linking, test It is also clear when calling the two overloaded functions to find the address in the main function of O.
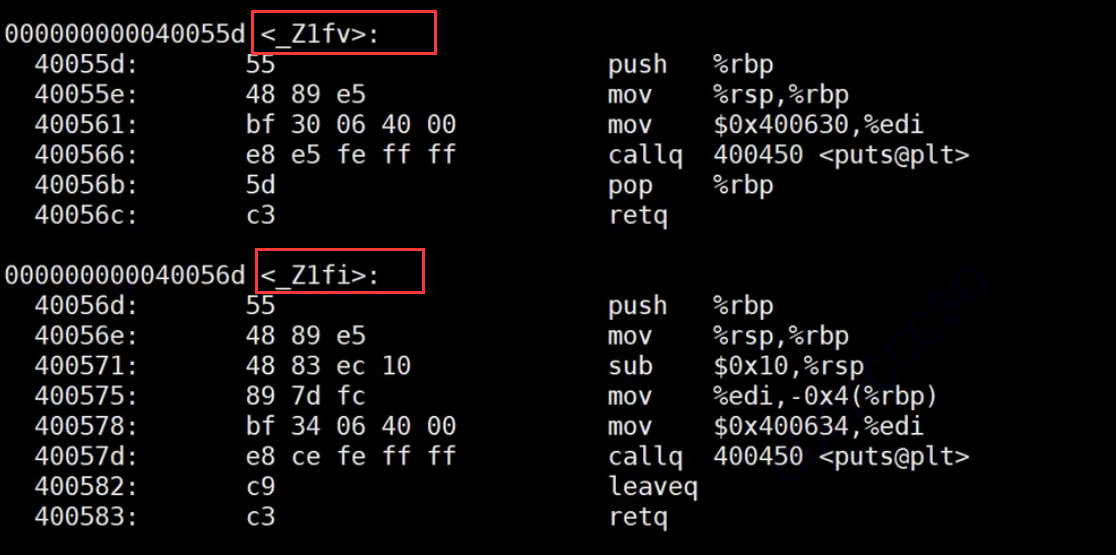
Summary: C language cannot support function overloading because they directly use function names to identify and search, and functions with the same name cannot be distinguished. C + + supports function overloading because C + + is distinguished by function name modification rules. As long as the formal parameters of functions are different, the modified names will be different. Therefore, C + + supports overloading.
If there is a function definition in the current file, the address will be filled in at compile time. If there is only a function declaration in the current file, the definition is in other XXX In the cpp file, there is no address at compile time, so you can only link to XXX O in the symbol table, search according to the function modification name, which is the important work of the link.
What is the role of extern"C"?
Sometimes in C + + projects, some functions may need to be compiled in the style of C. adding extern "C" before the function means telling the compiler to compile the function according to the rules of C language. Note: after adding extern "C" before the function, the function cannot support function overloading.
quote
Reference concept
Instead of defining a new variable, a reference gives an alias to an existing variable. The compiler will not open up memory space for the referenced variable. It shares the same memory space with the variable it references.
For example, Li Kui in the water margin is called "iron bull" at home and "Black Whirlwind" in the Jianghu. Or your parents will call you your nickname when you are at home, but others will call you your full name when you are outside, but they all call the same person.
Type & reference variable name (object name) = reference entity
#include<iostream>
using namespace std;
int main()
{
int a = 10;
//Reference definition
int&b = a;
//Get address
int* p = &b;
printf("%p\n", a);
printf("%p\n", b);
return 0;
}
Reference properties
1. Reference must be initialized when defining
2. A variable can have multiple references
3. Reference once an entity is referenced, other entities cannot be referenced
int main()
{
//1. The index must be initialized during redefinition
int a = 10;
int&b = a;
//2. A variable can have multiple references
int a = 10;
int&b = a;
int&c = a;
int&d = a;
//3. Reference once an entity is referenced, other entities cannot be referenced
int a = 20;
int& b = a;
int c = 30;
//1. Is this the alias that makes b become c? no
//2. Here is the assignment of c to b? yes
b = c;
//The pointer can be changed at any time
int* p1 = &a;
p1 = &c;
return 0;
}
Conclusion: pointer - slag man, quote - single-minded to emotion.
Often cited
/ Often cited
//Permissions can be reduced or unchanged, but not enlarged
int main()
{
//Permission amplification is not allowed
const int a = 10;
int& b = a;
// Permission unchanged
const int ra = 10;
const int& rb = ra;
// Permission can be reduced
int c = 10;
const int& d = c;
double d = 11.11;
int b = d;//Implicit type conversion
int& b = d;
//No, because when implicit type conversion occurs, d will first assign its own value to a temporary variable, and then b is the reference of the temporary variable
//Temporary variables are permanent and can only be read and written. Using b as a reference to temporary variables is an amplification of permissions and is not allowed
//However, if you add the const modifier in front of it, the permission will remain unchanged
const int& b = d;//ok
return 0;
}
Summary: permissions can be reduced or unchanged, but cannot be enlarged. Const type & can receive various types of objects, referred to as const take all!
Usage scenario
1. Make parameters
I remember that we wrote a Swap function in C language. At that time, we used it to explain the difference between value transmission and address transmission. Now that we have learned about references, we can use references instead of pointers as formal parameters.
void Swap(int* p1, int* p2)//Transmission address
{
int temp = *p1;
*p1 = *p2;
*p2 = temp;
}
void Swap(int r1, int r2)//Value transmission
{
int temp = r1;
r1 = r2;
r2 = temp;
}
void Swap(int& r1, int& r2)//Pass reference
{
int temp = r1;
r1 = r2;
r2 = temp;
}
Why can this be? Because r1 and r2 are references (aliases) of arguments, we exchange the values of r1 and r2, which is equivalent to exchanging arguments.
2. Return value
The same reference can also be used as the return value, but it should be noted that the data we return cannot be local variables created inside the function, because the local variables defined inside the function will be destroyed as the function call ends. The data we return must be static modified or dynamically developed, or global variables and other data that will not be destroyed with the end of the function call.
Let's talk about the difference between value passing return and reference passing return
1. Value transfer return
//All returned values will generate a copy
int Add(int a, int b)
{
int c = a + b;
return c;
//Instead of c, the value of c is copied through a temporary variable and returned to ret
//If c is small (4or8), the register is usually used as a temporary variable
//If c is large, the temporary variable will be stored in the stack frame calling the Add function
}
int main()
{
int x = 1;
int y = 2;
int ret = Add(x, y);
cout <<ret<< endl;
return 0;
}
2. Pass reference return
//A copy is not generated as if it were returned by passing a value
int& Add(int a, int b)
{
int c = a + b;
return c;
//A reference (alias) of c is returned
}
int main()
{
int x = 1;
int y = 2;
int ret = Add(x, y);
cout <<ret<< endl;
return 0;
}
Some problems with the current code:
1. There is illegal access. Because the return value of Add(1,2) is a reference to c, the Add function will access the c location space after the stack frame is destroyed
2. If the Add function stack frame is destroyed and the space is cleared, the random value is obtained when taking the value of c, and the random value is given to ret. At present, this depends on the implementation of the compiler.
Note: if the scope is given when the function returns, if the returned object has not been returned to the operating system, it can be returned by reference. If it has been returned to the operating system, it must be returned by value.
Performance comparison of values and references as return value types
#include <time.h>
struct A{ int a[10000]; };
A a;
// Return value -- 40000 bytes per copy
A TestFunc1() { return a; }
// Reference return -- no copy
A& TestFunc2(){ return a; }
void TestReturnByRefOrValue()
{
// Takes the value as the return value type of the function
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// Take reference as the return value type of the function
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// Calculate the time after the operation of two functions is completed
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
return 0;
}
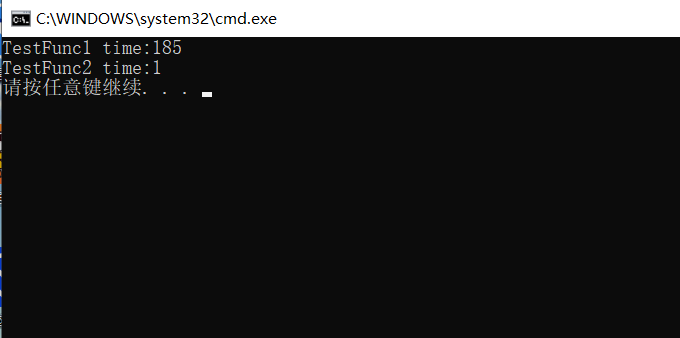
We can find that there is a great difference in efficiency between value passing and reference as return value types
The difference between reference and pointer
Syntactically, a reference is an alias. There is no independent space, and it shares the same space with its reference entity
int main()
{
int a = 10;
int&b = a;
//b is the alias of a. it shares the same space with a. there is no new space
int* p = &a;
//A pointer to p is defined here, and a space of 4 bytes (under 32-bit platform) is opened up to store the address of A
}
However, there is space in the underlying implementation, because references are implemented in the form of pointers
int main()
{
int a = 10;
int&ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
Let's look at the assembly code for references and pointers

The difference between quotation and pointer (very important!!! Interview often examines, it is best to fully understand it):
1. Reference conceptually defines the alias of a variable (no open space), and the pointer stores a variable address.
2. The reference must be initialized during definition. The pointer is best initialized, but no error will be reported if it is not initialized.
3. After a reference references an entity during initialization, it can no longer reference other entities, and the pointer can point to an entity of the same type at any time.
4. There is no NULL reference, but there is a NULL pointer.
5. Different meanings in sizeof. The reference result is the size of the reference type, but the pointer is always the number of bytes in the address space (4 bytes in 32-bit platform)
6. Reference self addition means that the referenced entity increases by 1, and pointer word addition means that the pointer is offset backward by one type.
7. There are multi-level pointers, but there are no multi-level references.
8. There are different ways to access entities. The pointer needs to display dereference, and the reference compiler handles it by itself.
9. References are relatively safer to use than pointers.
Inline function
Concept of inline function
In C language, in order to avoid the establishment of stack frames for small functions, macro functions are usually used to expand in the preprocessing stage. In C + +, the function modified with inline is called inline function. During compilation, the C + + compiler will expand where the inline function is called, without the overhead of function stack. The inline function improves the efficiency of program operation.
We can observe its advantages by observing the assembly code calling ordinary functions and inline functions:
int Add(int left, int right)
{
return left + right;
}
int main()
{
int ret = 0;
ret = Add(1, 2);
return 0;
}
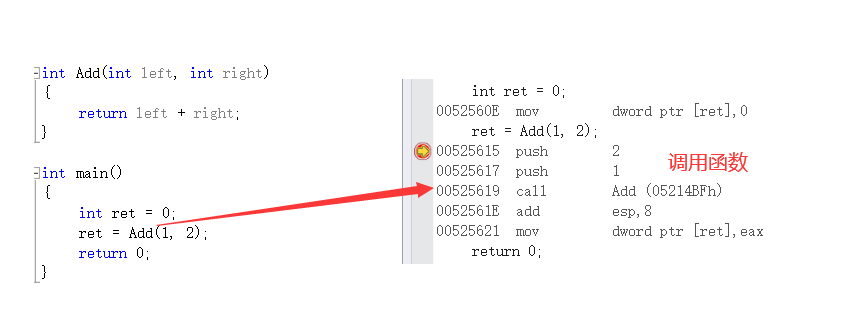
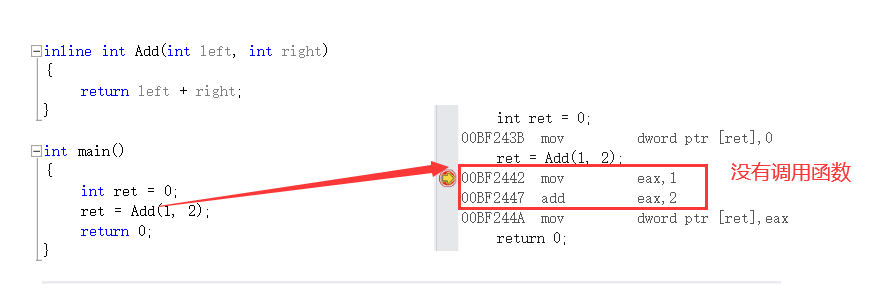
We can see from the assembly code that when the inline function is called, there is no assembly instruction to call the function.
Characteristics of inline functions
1.inline is a method of exchanging space for practice, which reduces the extra cost of calling functions in provinces and regions. Therefore, functions with long code or circular recursion are not suitable for inline functions.
2.inline is a suggestion for the compiler. The compiler will automatically optimize. If it is defined as loop / recursion in inline, the compiler will ignore inline during optimization.
3.inline does not recommend the separation of declaration and definition, which will lead to link errors. Because the inline is expanded, there will be no function address, and the link will not be found.
//F.h
#include<iostream>
using namespace std;
inline void f(int i);
//F.cpp
#include"F.h"
void f(int i)
{
cout << i << endl;
}
//main.cpp
#include"F.h"
int main()
{
f(10);
return 0;
}
// Link error: main Obj: error LNK2019: unresolved external symbol "void _cdeclf (int)" (? F)@@ YAXH@Z ), the symbol in the function_ Referenced in main
Summary: it is recommended to define small functions called frequently as inline
Interview questions
Since C language has been solved, why does C + + provide inline function? (disadvantages of macro functions) interview questions and test points
a. Macro functions do not support debugging
b. Macro function syntax is complex and error prone
c there is no type safety check
What technologies do C + + have in place of macros?
1. Constant definitions are replaced by const
2. Use inline function instead of function definition
auto keyword (C++11)
Introduction to auto
In the early C/C + +, the meaning of auto is that the variable modified by auto is a local variable with automatic memory, but unfortunately, no one has used it.
In C++11, the standards committee gives a new meaning to auto, that is, auto is no longer a storage type indicator, but as a new type indicator to indicate the compiler. The variables declared by auto must be derived by the compiler at compile time.
#include<iostream>
using namespace std;
double Test()
{
return 3.14;
}
int main()
{
int a = 10;
auto b = a;//The type is declared as auto, which can be automatically pushed to the type of b according to the type of a
auto c = 'a';
auto d = Test();
//Print the types of variables b, c, d
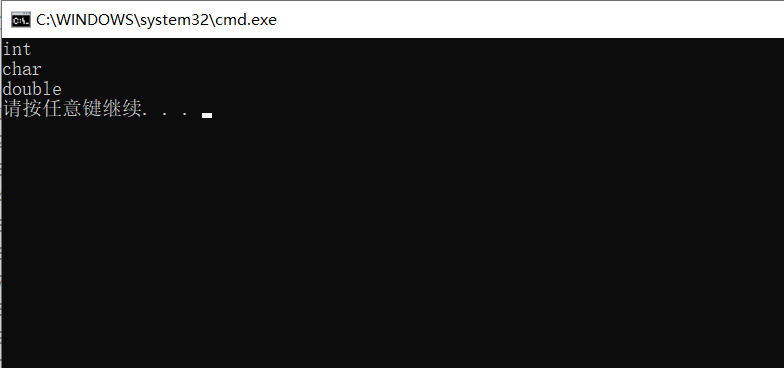
cout << typeid(b).name() << endl;//int
cout << typeid(c).name() << endl;//char
cout << typeid(d).name() << endl;//double
return 0;
}
be careful:
When using auto to define a variable, it must be initialized. In the compilation stage, the compiler needs to deduce the actual type of auto according to the initialization expression. Therefore, auto is not a declaration of "type", but a "placeholder" in the type declaration. The compiler will replace Auto with the actual type of the variable in the compilation stage.
Usage rules of auto
1.auto is used in combination with pointers and references
When declaring a pointer type with auto, there is no difference between auto and auto *, but when declaring a reference type with auto, you must add&
#include<iostream>
using namespace std;
int main()
{
int x = 10;
auto a = &x;//int*
auto* b = &x;//int*
int& y = x;//What is the type of y? int
auto c = y;//int
auto&d = x;//The type of d is int, but it is specified here that d is a reference to x
//Type of print variable
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
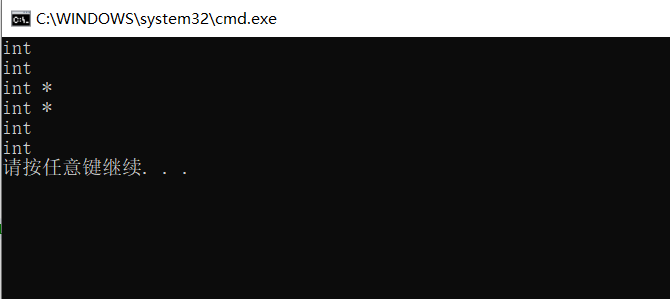
Note: when declaring the pointer type with auto, there is no difference between auto and auto *, but when declaring the reference type with auto, you must add &. No, the thief creates the same common variable as the entity type.
2. Define multiple variables on the same line
When multiple variables are declared on the same line, these variables must be of the same type, otherwise the compiler will report an error, because the compiler actually deduces only the first type, and then uses the derived type to define other variables.
int main()
{
auto a = 1, b = 3;//correct
auto c = 4, d = 5.0//The code will fail to compile because the initial expression types of c and d are different
}
Scenes that cannot be deduced by auto
1.auto cannot be used as a parameter of a function
//The code here will fail to compile. auto cannot be used as a formal parameter type because the compiler cannot deduce the actual type of A
void fun(auto a)
{
cout << "hello" << endl;
}
2.auto cannot be used directly to declare arrays
void Test()
{
int a[] = { 1, 2, 3 };
auto b[] = { 4, 5, 6 };
}
3. In order to avoid confusion with auto in C++98, C++11 only retains the use of auto as a type indicator
4. The most common advantage of auto in practice is to use it in combination with the new for loop provided by C++11 and lambda expression, which will be mentioned later.
Range based for loop (C++11)
Usage of scope for
In C++98, if you want to traverse an array, you can do it in the following way
int main()
{
int arr[] = { 1, 2, 3, 4, 5 };
//Multiply each element of the array by 2
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
arr[i] *= 2;
}
//Prints all elements in the array
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
cout << arr[i] << " ";
}
}
It is not difficult to find that our previous C language traverses an array in this way. However, for a set with scope, it is redundant for programmers to explain the scope of the loop, and sometimes it is easy to make mistakes. Therefore, a range based for loop is introduced in C++11. The parenthesis after the for loop has a colon ":" which is divided into two parts: the first part is the variable within the scope due to iteration, and the second part represents the scope to be iterated.
int main()
{
//Scope forC++11 new syntax traversal, simpler, arrays can
//Automatic traversal, successively take out the elements in arr and assign them to e until the end
for (auto&e : arr)
{
e *= 2;
}
for (auto e : arr)
{
cout << e << " ";
}
cout << endl;
}
Note: similar to the normal loop, you can use continue to end this loop or break to jump out of the whole loop.
Conditions for use of the scope
1. The scope of for loop iteration must be determined
For an array, it is the range of the first element and the last element in the array; For classes, you should provide methods of begin and end, which are the scope of the for loop iteration
Note: the following code is problematic because the scope of the for loop is uncertain
void Test(int arr[])
{
for (auto&e : arr)
{
cout << e << endl;
}
}
2. The iterated object should implement the operations of + + and = =
This is a question about iterators. Let's learn about them first.
Pointer null nullptr (C++11)
Pointer null value in C++98
In good C/C + + programming habits, when declaring a variable, it is best to give the variable an appropriate initial value, otherwise unexpected errors may occur, such as uninitialized pointers. If a pointer does not have a legal point, we basically initialize it as follows:
int main()
{
int* p = NULL;
int* p2 = 0;
}
NULL is actually a macro. In the traditional C header file (stddef.h), you can see the following code:
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif #endif
As you can see, NULL may be defined as a literal constant 0 or as a constant of a typeless pointer (void *). No matter what definition is adopted, some troubles will inevitably be encountered when using NULL pointers, such as:
void f(int i)
{
cout << "f(int)" << endl;
}
void f(int*p)
{
cout << "f(int*)" << endl;
}
//C++11
int main()
{
int* p1 = NULL;//int* p1 = 0;
int* p2 = nullptr;
f(0);
f(NULL);
f(nullptr);
return 0;
}
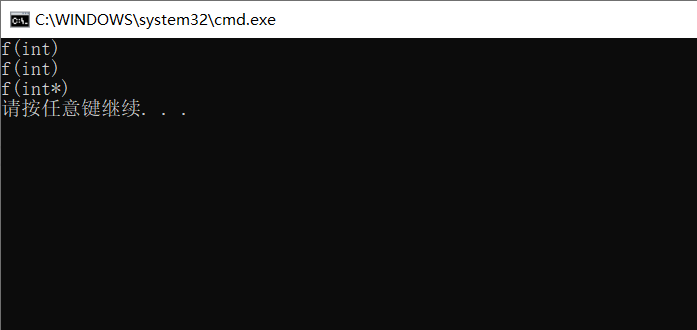
The purpose of the program is to call the pointer version of f(int*p) function through f(NULL), but since NULL is defined as 0, f(NULL) finally calls f(int i) function. Therefore, it is contrary to the original intention of the procedure.
Note: in C++98, the literal constant 0 can be either an integer number or an untyped pointer (void *) constant, but the compiler regards it as an integer variable by default. If you want to use it as a pointer, you must cast it.
Pointer null value in C++11
For the problems in C++98, C++11 introduces a new keyword nullptr
be careful:
1. When nullptr is used to represent the null value of the pointer, it is not necessary to include the header file, because nullptr is introduced by C++11 as a new keyword.
2. In C++11, sizeof(nullptr) and sizeof((void*)0) occupy the same number of bytes.
3. In order to improve the robustness of the code, it is recommended to use nullptr when representing pointer null values later.