Understanding the principles of Concurrent HashMap implementations, it is recommended that you first understand the following HashMap Realization principle.
HashMap source code parsing (JDK 1.8)
Why use Concurrent HashMap
Hashtable is thread-safe, but it uses synchronized method to synchronize. Both insert and read data are synchronized. When inserting data, it can not read (equivalent to locking the whole Hashtable, full publication lock). When multi-threaded concurrent situation. All of them have to compete for the same lock, resulting in extremely low efficiency. After JDK 1.5, Concurrent HashMap came into being to improve the pain point of Hashtable.
Why is Concurrent HashMap efficient?
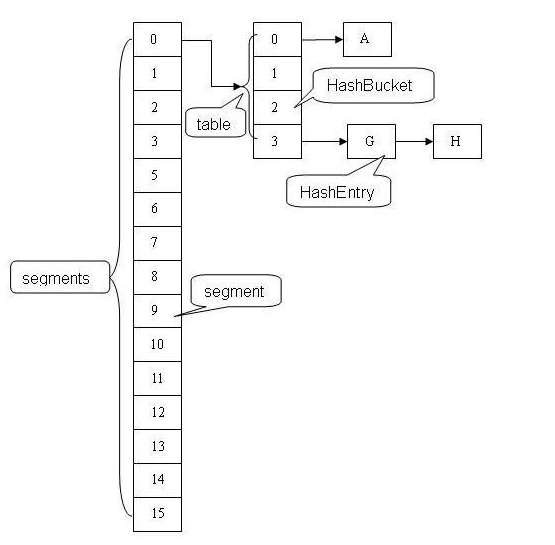
Implementation in JDK 1.5
Concurrent HashMap uses segmented locking technology. Concurrent HashMap will lock a segment of storage, and then allocate a segment to each segment of data. When a thread occupies a segment to access one segment of data, other segments of data can also be accessed by other threads by default. With 16 segments. The default is 16 times more efficient than Hashtable.
The structure of Concurrent HashMap is as follows.
Implementation in JDK 1.8
Concurrent HashMap cancels segmental segmental lock and uses CAS and synchronized to ensure concurrency security. The data structure is the same as HashMap 1.8, array + linked list / red-black binary tree.
synchronized only locks the first node of the current linked list or red-black binary tree, so as long as hash does not conflict, there will be no concurrency, and the efficiency will be improved by N times.
The structure of JDK 1.8 Concurrent HashMap is as follows:
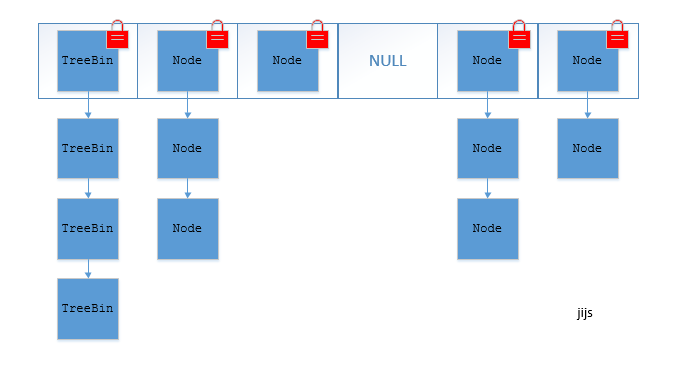
TreeBin: Red-Black Binary Tree Node
Node: Linked List Node
Concurrent HashMap Source Code Analysis
Concurrent HashMap class structure reference HashMap Here are a few attributes that HashMap does not have.
/** * Table initialization and resizing control. When negative, the * table is being initialized or resized: -1 for initialization, * else -(1 + the number of active resizing threads). Otherwise, * when table is null, holds the initial table size to use upon * creation, or 0 for default. After initialization, holds the * next element count value upon which to resize the table. hash A control bit identifier for table initialization or expansion. Negative numbers represent initialization or expansion operations in progress -1 Representatives are initializing -N Represents that N-1 threads are expanding Positive or zero means that the hash table has not yet been initialized. This value indicates the size of the initialization or the next expansion. */ private transient volatile int sizeCtl; // The following two variables are used to control single thread entry during expansion /** * The number of bits used for generation stamp in sizeCtl. * Must be at least 6 for 32bit arrays. */ private static int RESIZE_STAMP_BITS = 16; /** * The bit shift for recording size stamp in sizeCtl. */ private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; /* * Encodings for Node hash fields. See above for explanation. */ static final int MOVED = -1; // The hash value is - 1, indicating that this is a forward Node node static final int TREEBIN = -2; // A hash value of - 2 indicates a TreeBin node at this point
The main purpose of analyzing code is to update data efficiently and synchronously using CAS and Synchronized.
Insert the data source code below:
public V put(K key, V value) { return putVal(key, value, false); } /** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { //Concurrent HashMap does not allow null keys to be inserted, and HashMap allows null keys to be inserted. if (key == null || value == null) throw new NullPointerException(); //Calculate the hash value of key int hash = spread(key.hashCode()); int binCount = 0; //The function of the for loop: Because the update elements are updated using CAS mechanism, they need to be retried continuously until they succeed. for (Node<K,V>[] tab = table;;) { // f: Link list or red-black binary tree head node, when adding elements to the list, need synchronized to get the lock of f. Node<K,V> f; int n, i, fh; //Determine whether the Node [] array is initialized or not, and initialize if it is not. if (tab == null || (n = tab.length) == 0) tab = initTable(); //Locate the index coordinates of the Node [] array by hash, whether there are Node nodes, if not, add using CAS (the head node of the list), add failure will enter the next cycle. else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } //Check for moving elements inside (Node [] array expansion) else if ((fh = f.hash) == MOVED) //Help it expand tab = helpTransfer(tab, f); else { V oldVal = null; //Lock the head node of a chain or red-black binary tree synchronized (f) { //Determine if f is the head node of the list if (tabAt(tab, i) == f) { //If FH >= 0 is a linked list node if (fh >= 0) { binCount = 1; //Traversing all nodes of the list for (Node<K,V> e = f;; ++binCount) { K ek; //If a node exists, update value if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } //If not, add a new node at the end of the list. Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } //TreeBin is a red-black binary tree node else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; //Adding tree nodes if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { //If the list length has reached the critical value of 8, it needs to be converted into a tree structure. if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } //Number of size s for the current Concurrent HashMap + 1 addCount(1L, binCount); return null; }
- Determine whether the Node [] array is initialized or not, and initialize if it is not.
- Locate the index coordinates of the Node [] array by hash, whether there are Node nodes, if not, add using CAS (the head node of the list), add failure will enter the next cycle.
- Check that the internal capacity is expanding, if it is expanding, help it expand together.
- If f!=null, use synchronized to lock the F element (the head element of the linked list/red-black binary tree)
4.1 If it is Node, add the list.
4.2 If it is TreeNode (tree result), the tree addition operation is performed. - To judge that the length of the linked list has reached the critical value of 8, it is necessary to transform the linked list into a tree structure.
Summary:
The implementation of JDK8 is also the idea of lock separation, which makes the lock score smaller than segment (JDK1.5). As long as hash does not conflict, there will be no concurrent acquisition of locks. It first uses the lock-free operation CAS to insert the header node. If the insertion fails, it indicates that other threads have inserted the header node, and the operation is repeated. If the header node already exists, the header node lock is obtained through synchronization and subsequent operations are carried out. Performance is improved again than segmented segmented segmented lock.