Thread safe collection
- Hashtable
- Concurrenthasnmap
- Vector
ConcurrentHashMap is the thread safe version of HashMap, and ConcurrentSkipListMap is the thread safe version of TreeMap
Hashtable is the only thread safe built-in implementation of Map before JDK 5 (Collections.synchronizedMap does not count). Hashtable inherits Dictionary (hashtable is its only exposed subclass) and does not inherit AbstractMap or HashMap. Although the structures of hashtable and HashMap are very similar, there is not much connection between them.
Why use ConcurrentHashMap
Because using HashMap in concurrent programming may lead to program dead loop, and HashTable is inefficient.
1) hashmap is non thread safe
Under multi-threaded operation, if you call hasmap Put () can cause dead loops and lead to high cpu resource consumption.
The multi-threaded operation put () will make the Entry linked list form a ring data structure, so that the next node of the Entry will never be empty, and an endless loop will be generated to obtain the Entry.
2) HashTable is inefficient
hashTable uses synchronized to ensure thread safety. All threads must compete for a lock, which is too inefficient.
For example, thread A accesses the HashTable synchronization method put (), thread B also accesses the synchronization method put (), but B does not lock into the blocking or polling state, and cannot access other methods, resulting in the lower efficiency with more threads.
ConcurrentHashMap analysis jdk1 seven
attribute
int DEFAULT_INITIAL_CAPACITY = 16; //Default value of initial capacity - table attribute of hashentry
float DEFAULT_LOAD_FACTOR = 0.75f; //Default load factor - HashEntry
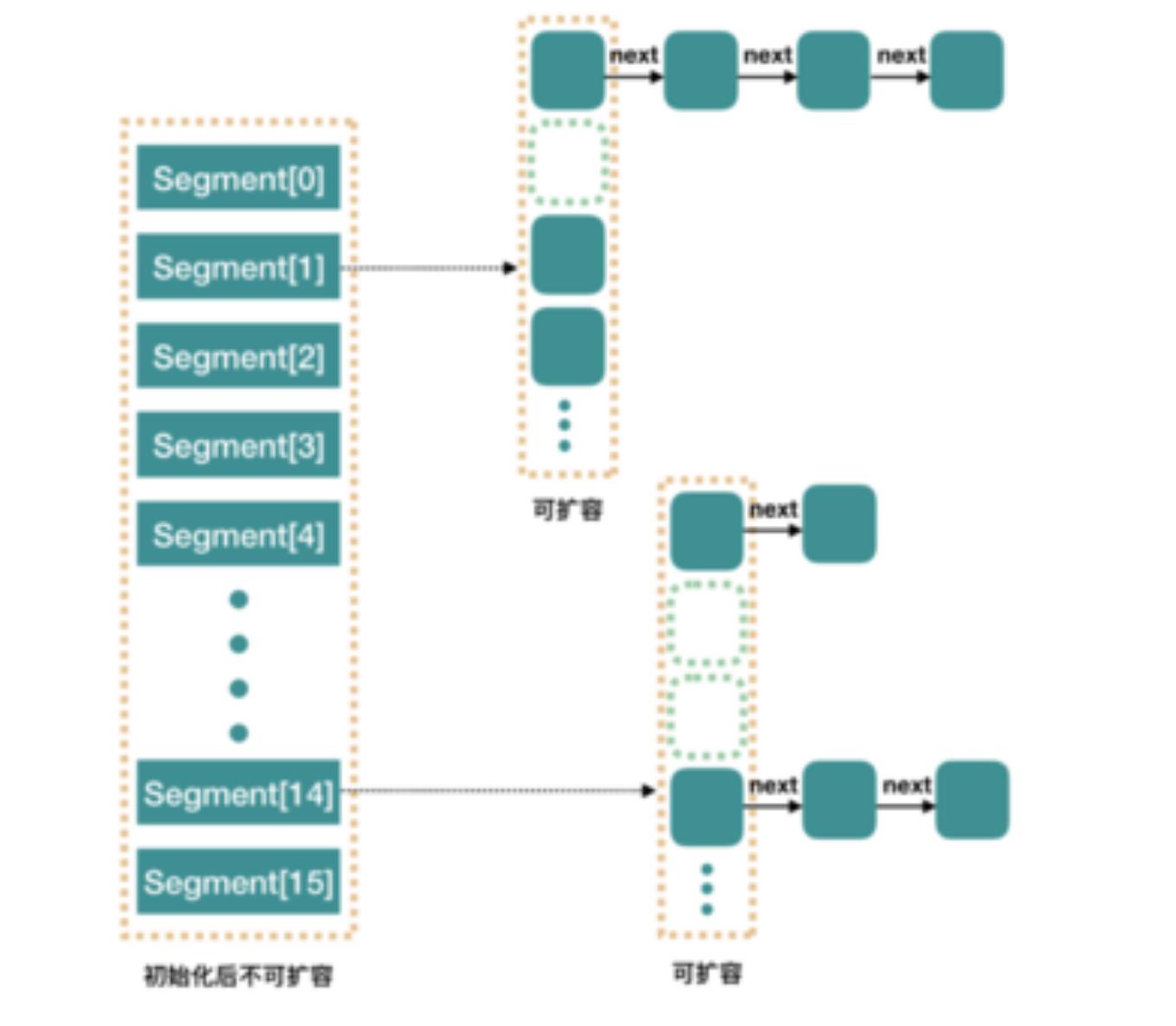
int DEFAULT_CONCURRENCY_LEVEL = 16; //Default concurrency - segment array size
int MAXIMUM_CAPACITY = 1 << 30; //Maximum capacity - maximum value of array in segment - > tab length<MAXIMUM_ CAPACITY
int MIN_SEGMENT_TABLE_CAPACITY = 2; //Minimum value of HashEntry array
int MAX_SEGMENTS = 1 << 16; // Slowly conservative / / maximum concurrency = maximum value of segment array
int RETRIES_BEFORE_LOCK = 2; //Lock retries
final int segmentMask; //It is mainly used in keyhash process
final int segmentShift;
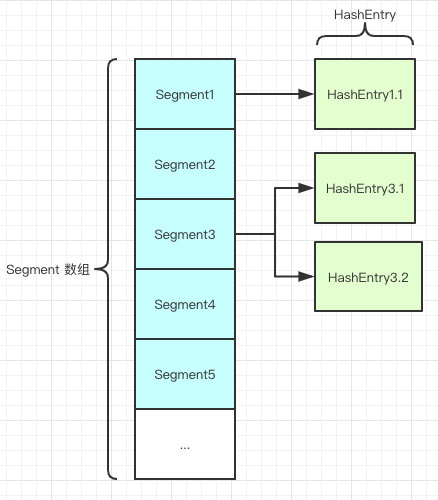
final Segment<K,V>[] segments; //Location of the storage data node
//Lock for storing data:
static final class Segment<K,V> extends ReentrantLock { //Segment is a reentrant lock that acts as a lock;
static final int MAX_SCAN_RETRIES =Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1; //segment maximum number of lock retries
transient volatile HashEntry<K,V>[] table; //Storage of data
transient int count;
}
//Properties of HashEntry
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
Add volatile to the value and next attributes of HashEntry to ensure visibility
The default ConcurrentHashMap has 16 HashMap like structures, and each HashMap has an exclusive lock. In other words, the final effect is to uniformly map any element to the map of a HashMap through a Hash algorithm Entry, and the operation on an element is concentrated on its distributed HashMap, which has nothing to do with other hashmaps. This supports up to 16 concurrent writes.
Constructor
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {}
//Array size loading factor concurrency, 16 by default
The length of segments array is related to ssize and concurrentLevel. Ssize > = the minimum power of concurrentLevel.
If you think this description is difficult to understand, take an example. For example, if concurrentLevel=17, how many powers of 2 are just > = 17? It's 32, right! So ssize=32. More importantly, the reason why the array size of the Segment must be a power of 2 is to facilitate the positioning of the index position of the Segment through the bit and hash algorithm
put()
Insert data through locking mechanism
1. In which Segment should the location data be placed
Locate the corresponding Segment through the hash algorithm. If the obtained Segment is empty, call the ensuesegment () method;
Otherwise, directly call the put method of the queried Segment to insert the value
The ensuesegment () method uses getObjectVolatile() to read the corresponding Segment. If it is still empty, create a Segment object based on segments[0], set this object to the corresponding Segment value and return it.
if (value == null) throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask; //Find the index position of the segment array corresponding to the key
// segmentShift = 32 - sshift;
// segmentMask = ssize - 1; //segmentMask - segment mask to ensure hash uniformity, where size is the length of the segmentmask array
// 2^sshift==ssize if zize = 16, sshift = 4
if ((s = (Segment <K, V>) UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null) s = ensureSegment(j);
return s.put(key, hash, value, false);
2. The location data should be placed under which array subscript in the Segment
3. Put the data in the corresponding position
(1) if thread A successfully executes the tryLock() method, insert the HashEntry object into the corresponding position;
HashEntry <K, V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
(2) if thread B fails to acquire the lock, it will execute scanAndLockForPut() method. In scanAndLockForPut() method, it will attempt to acquire the lock by repeatedly executing tryLock() method. In multiprocessor environment, the number of repetitions is 64, and the number of repetitions of single processor is 1. When the number of times of executing tryLock() method exceeds the upper limit, it will execute lock() method to suspend thread B;
(3) when thread A completes the insertion operation, it will release the lock through the unlock() method, and then wake up thread B to continue execution;
get()
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
- hash(key) re hash the hashcode of key int h = hash(key);
- Positioning Segment
- Locate HashEntry
- Obtain the HashEntry on the specified offset through the getObjectVolatile() method
- Get the corresponding value by looping through the linked list
In jdk1 The get operation of ConcurrentHashMap in 7 is not locked because the HashEntry array defined in each Segment and the value and next HashEntry nodes defined in each HashEntry are of volatile type. Variables of volatile type can ensure their visibility among multiple threads, so they can be read by multiple threads at the same time
transient volatile HashEntry<K,V>[] table;
static final class HashEntry<K,V> {
volatile V value;
volatile HashEntry<K,V> next;
}
size
Because concurrent HashMap can insert data concurrently, it is difficult to accurately calculate elements. The general idea is to count the number of elements in each Segment object and then accumulate them. However, the results calculated in this way are not the same accurate, because when calculating the number of elements in the following segments, The calculated Segment may also have data insertion or deletion. In the implementation of 1.7, the following methods are adopted:
First, the number of elements is calculated continuously without locking, up to 3 times:
1. If the results of the previous and subsequent calculations are the same, the number of elements calculated is accurate;
2. If the results of the previous and subsequent calculations are different, lock each Segment and calculate the number of elements again;
What is a sectional lock??
Divide the data into sections for storage, and then assign a lock to each section of data. When a thread occupies the lock to access one section of data, the data of other sections can also be accessed by other threads.
For example, each Segment of concurrent HashMap has a lock, and each thread will lock only one Segment during operation. As long as different threads operate the data in different segments, the threads will not interfere with each other
The get method in ConcurrentHashMap is not locked, so multiple threads will not be mutually exclusive
Operating different data is not mutually exclusive as long as the data is not in the same Segment
Locking requirements for read operation:
(1) key, hash and next in hashentry are declared as final:
This means that you cannot add nodes to the middle and tail of a link, or delete nodes in the middle and tail of a link.
This feature can ensure that when accessing a node, the link after the node will not be changed. This feature can greatly reduce the complexity of processing linked lists;
(2) The value field of hashentry class is declared as Volatile:
Java's memory model can ensure that the write of a write thread to the value field can be immediately "seen" by a subsequent read thread.
In ConcurrentHashMap, null is not allowed to be used as the key and value. When the reading thread reads that the value field of a HashEntry is null, it knows that a conflict has occurred (reordering has occurred), and it needs to re read the value after locking. These features cooperate with each other so that the read thread can correctly access the ConcurrentHashMap even in the unlocked state; Since the write operation to the Volatile variable will be synchronized with the subsequent read operation to the variable. When a writer thread modifies the value field of a HashEntry, another reader thread reads the value field,
The Java memory model can ensure that the read thread must read the updated value. Therefore, the non structural modification of the linked list by the write thread can be seen by the subsequent unlocked read thread;
High concurrency
It mainly comes from three aspects:
(1). Segment lock is used to realize deeper shared access among multiple threads;
(2). The invariance of the hashentry object is used to reduce the need for locking during the traversal of the linked list by the thread executing the read operation;
(3). Coordinate the memory visibility of read / write operations between different threads through write / read access to the same Volatile variable;
ConcurrentHashMap analysis jdk1 eight
Relative to jdk1 7. The segment lock is cancelled, the data structure of red black tree is added, and the lock is changed to lock the Node (element of array).
Node + CAS + Synchronized is adopted to ensure concurrent security
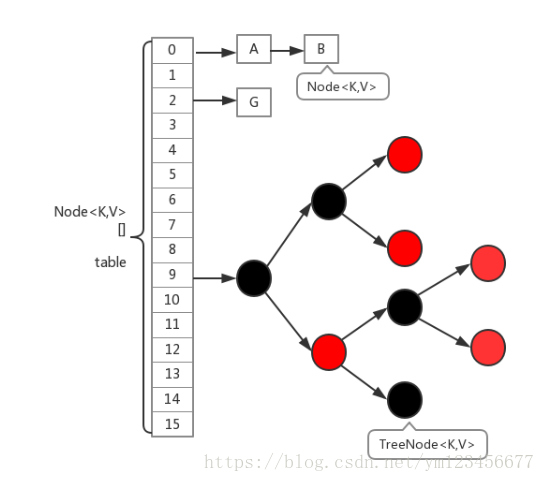
put method
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) tab = initTable(); //Initialize array
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //If the Node at the corresponding location has not been initialized, insert the corresponding data through CAS
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break;
}
else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); //Capacity expansion
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
//If the Node in the corresponding position is not empty and the Node is not in the moving state, the synchronized lock is added to the Node,
//If the hash of the node is not less than 0, traverse the linked list to update the node or insert a new node;
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//If the node is a TreeBin type node, it indicates that it is a red black tree structure, then insert the node into the red black tree through the putTreeVal method;
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent) p.val = value;
}
}
}
}
//If binCount is not 0, it indicates that the put operation has an impact on the data. If the current number of linked lists reaches 8, it will be transformed into a red black tree through the treeifyBin method
//If oldVal is not empty, it indicates that it is an update operation and does not affect the number of elements, the old value will be returned directly;
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);//If a new node is inserted, execute the addCount() method to try to update the number of elements basecont
return null;
}
Process steps:
1. For the first put, you need to initialize the array and call the initTable () method.
2. If there is no hash conflict, CAS is inserted directly
3. If you are in the moved state, expand the capacity
3. If the node corresponding to the added element is not null and is not in the moved state, the synchronized lock shall be applied to the node
If the hash of the node > = 0, traverse the linked list to update the node or insert a new node;
4. If the node is a red black tree type, use the putTreeVal() method
Finally, if the number of the linked list is greater than the threshold 8, it must first be converted to the structure of black mangrove, and break enters the cycle again
5. If the addition is successful, execute the addCount() method, try to update the number of elements, count the size, and check the expansion
get()
1. Calculate the hash value and locate it at the index position of the table. If the first node matches, it will be returned
2. In case of capacity expansion, it will call the find method that marks the ForwardingNode of the node being expanded to find the node, and the matching will be returned
3. If none of the above is met, traverse the node down, and the matching will be returned. Otherwise, null will be returned
size
For the size calculation, it is already handled in the capacity expansion and addCount() methods, and jdk1 7. It is calculated by calling the size() method. In fact, it is meaningless to calculate the size in the concurrent set, because the size is changing in real time, and can only calculate the size at a certain moment, but a certain moment is too fast, and people's perception is a time period, so it is not very accurate
The variable baseCount of volatile type records the number of elements. When new data is inserted or deleted, the baseCount will be updated through the addCount() method
private transient volatile long baseCount;
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a; //Number of changes
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
difference
1,jdk1.7 is ReentrantLock+Segment+HashEntry, and jdk1 8 uses synchronized+CAS+HashEntry + red black tree.
2,jdk1.8. The granularity of locks is HashEntry and jdk1 7. The granularity of the lock is segment and contains multiple hashentries, so jdk1 8 reduces the granularity of locks
3,jdk1.8 uses synchronized for synchronization, so segmented lock is not required
4,jdk1. The red black tree is used to optimize the linked list. When the threshold is greater than 8, the linked list is transformed into a red black tree, and the traversal efficiency of the red black tree is higher than that of the linked list
JDK1.8 why use the built-in lock synchronized to replace the reentrant lock??
Because the granularity is reduced, synchronized is no worse than ReentrantLock in relatively low granularity locking. In coarse granularity locking, ReentrantLock may control the boundaries of each low granularity through Condition, which is more flexible. In low granularity, the advantage of Condition is lost