KubeSphere is a container hybrid cloud management system for cloud native applications built on K8s. Support multi cloud and multi cluster management, provide automatic operation and maintenance capability of the whole stack, help enterprise users simplify DevOps workflow, provide operation and maintenance friendly wizard operation interface, and help enterprises quickly build a powerful and feature rich container cloud platform.
KubeSphere provides users with many functions required to build an enterprise K8s environment, such as multi cloud and multi cluster management, K8s resource management, DevOps, application lifecycle management Microservice governance (service grid), log query and collection, service and network, multi tenant management, monitoring alarm, event and audit query, storage management, access control, GPU support, network policy, image warehouse management and security management.
Thanks to the excellent architecture and design of K8s, KubeSphere has adopted a lighter architecture mode and flexibly integrated resources to further enrich the K8s ecology.
KubeSphere core architecture
The core architecture of KubeSphere is shown in the figure below:
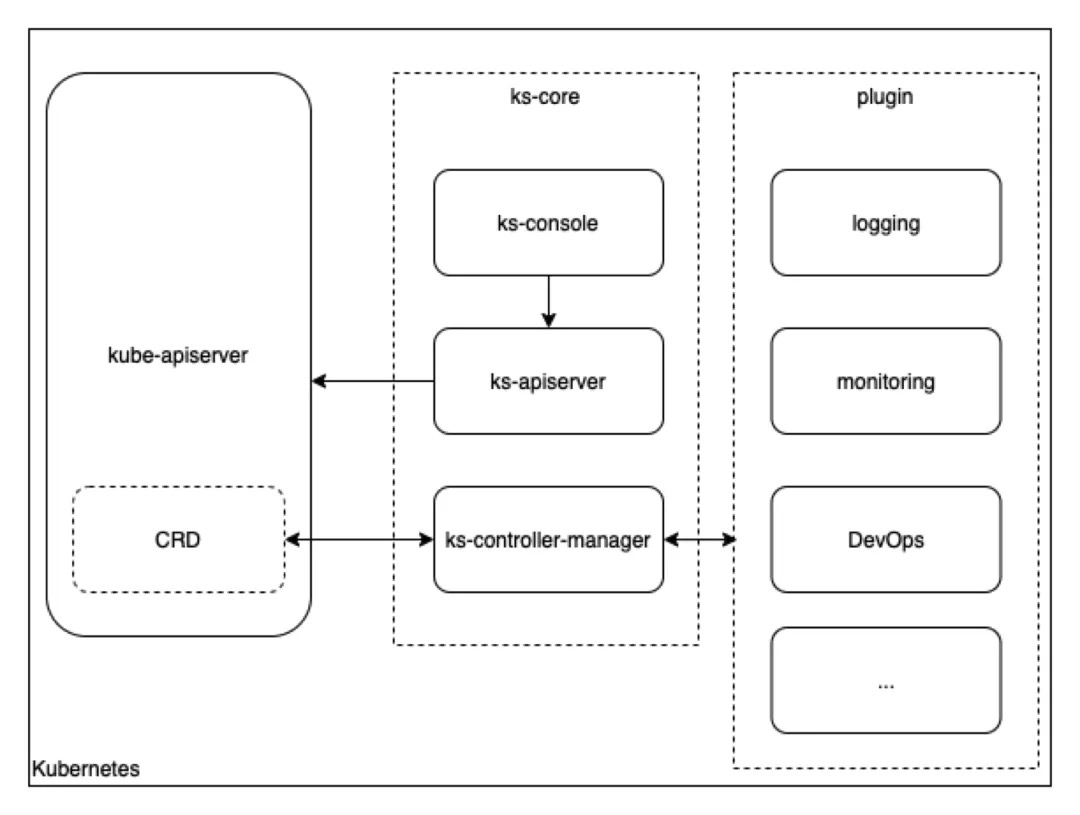
There are three main core components:
-
KS console front end service component
-
KS apiserver backend service component
-
KS controller manager resource status maintenance component
KubeSphere's back-end design follows the style of K8s declarative API, and all operable resources are abstracted into customresources as much as possible [1]. Compared with the imperative API, the declarative API is more concise and provides better abstraction, telling the final expected state of the program (what to do) without caring about how to do it.
In declarative API s:
-
Your API contains a relatively small number of smaller objects (resources).
-
Object defines the configuration information of an application or infrastructure.
-
The frequency of object update operations is low.
-
People are usually required to read or write objects.
-
The main operations of objects are CRUD style (create, read, update, and delete).
-
No cross object transaction support is required: API objects represent the expected state rather than the exact actual state.
The Imperative API is different from the declarative API. The following indications indicate that your API may not be declarative:
-
The client sends the "do this operation" instruction, and then obtains a synchronous response at the end of the operation.
-
The client sends the "do this operation" instruction and obtains an operation ID. then it needs to judge whether the request is successfully completed.
-
You will compare your API to RPC.
-
Store large amounts of data directly.
-
General operations performed on objects are not CRUD style.
-
API s are not easy to model with objects.
Kube apiserver and etcd are used to realize data synchronization and data persistence, and KS controller manager is used to maintain the state of these resources to achieve the consistency of the final state. If you are familiar with K8s, you can well understand the benefits of declarative API, which is also the core part of KubeSphere.
For example, the configuration of pipeline, user credentials, user entities and alarm notifications in KubeSphere can be abstracted as resource entities. With the help of K8s mature architecture and tool chain, it can be easily combined with K8s to reduce the coupling between components and reduce the complexity of the system.
The core architecture of KS apiserver
KS apiserver is the core back-end component of KubeSphere. It is responsible for the interaction of front and rear data, proxy distribution of requests, authentication and authentication. The following figure shows the core architecture of KS apiserver:
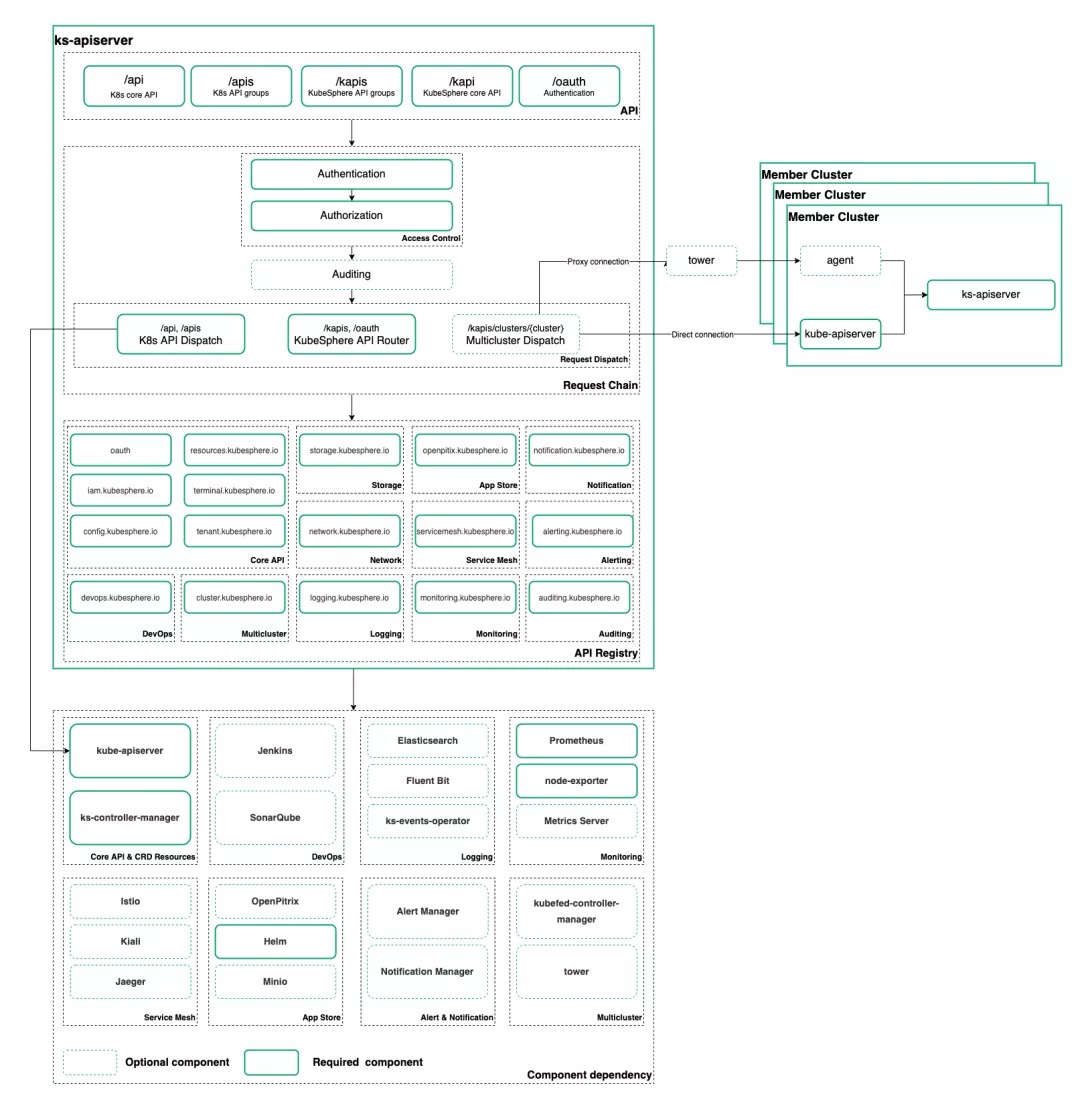
The development of KS apiserver uses the go restful [2] framework. Multiple filters can be added in the request link to dynamically intercept requests and responses, and realize authentication, authentication, audit logic forwarding and reverse proxy functions. KubeSphere's API style also learns K8s mode [3] as much as possible to facilitate the use of RBAC[4] for permission control.
Decoupling with CRD + controller can greatly simplify the integration with third-party tools and software.
K8s community also provides rich tool chains. With the help of controller runtime [5] and kubebuilder [6], we can quickly build a development scaffold.
API aggregation and permission control
By expanding KS apiserver, API aggregation can be realized to further realize function expansion, aggregation query and other functions. During the development of API, the following specifications need to be followed in order to integrate with KubeSphere's tenant system and resource system.
-
API aggregation
-
Permission control
-
CRD + controller
API specification
# Group through api group
/apis/{api-group}/{version}/{resources}
# Example
/apis/apps/v1/deployments
/kapis/iam.kubesphere.io/v1alpha2/users
# api core
/api/v1/namespaces
# Distinguish different actions through path
/api/{version}/watch/{resources}
/api/{version}/proxy/{resources}/{resource}
# Different resource levels are distinguished by path
/kapis/{api-group}/{version}/workspaces/{workspace}/{resources}/{resource}
/api/{version}/namespaces/{namespace}/{resource}
Purpose of API specification:
-
It is better to abstract resources as Object, which is more suitable for declarative API.
-
Better API management, version, grouping and layering, which is more convenient for API expansion.
-
Better integration with permission control can easily obtain metadata, apigroup, scope, version and verb from requests.
Permission control
The core of KubeSphere permission control is RBAC[7] role-based access control.
Key objects include Role, User and RoleBinding.
Role defines the resources that a role can access.
Roles are divided according to resource levels. Roles at different levels of cluster role, workspace role and namespace role define the resources that the role can access at the current level.
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: role-grantor rules: - apiGroups: ["rbac.authorization.k8s.io"] resources: ["rolebindings"] verbs: ["create"] - apiGroups: ["rbac.authorization.k8s.io"] resources: ["clusterroles"] verbs: ["bind"] # Ignoring resourceNames means that any ClusterRole is allowed to bind resourceNames: ["admin","edit","view"] - nonResourceURLs: ["/healthz", "/healthz/*"] # '*' in nonResourceURL is a global wildcard verbs: ["get", "post"]
RoleBinding can bind a role to a Subject. The Subject can be a group, user or service account.
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: role-grantor-binding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: role-grantor subjects: - apiGroup: rbac.authorization.k8s.io kind: User name: user-1
CRD + controller
Custom Resource is an extension of K8s API, which can be expanded through dynamic registration. Users can use kubectl to create and access objects in it, just like operating built-in resources.
Abstract resources through CRD, and then monitor resource changes and maintain resource status through controller. The core of controller is Reconcile. As it means, maintain resource status through passive and timed triggering until it reaches the declared state.
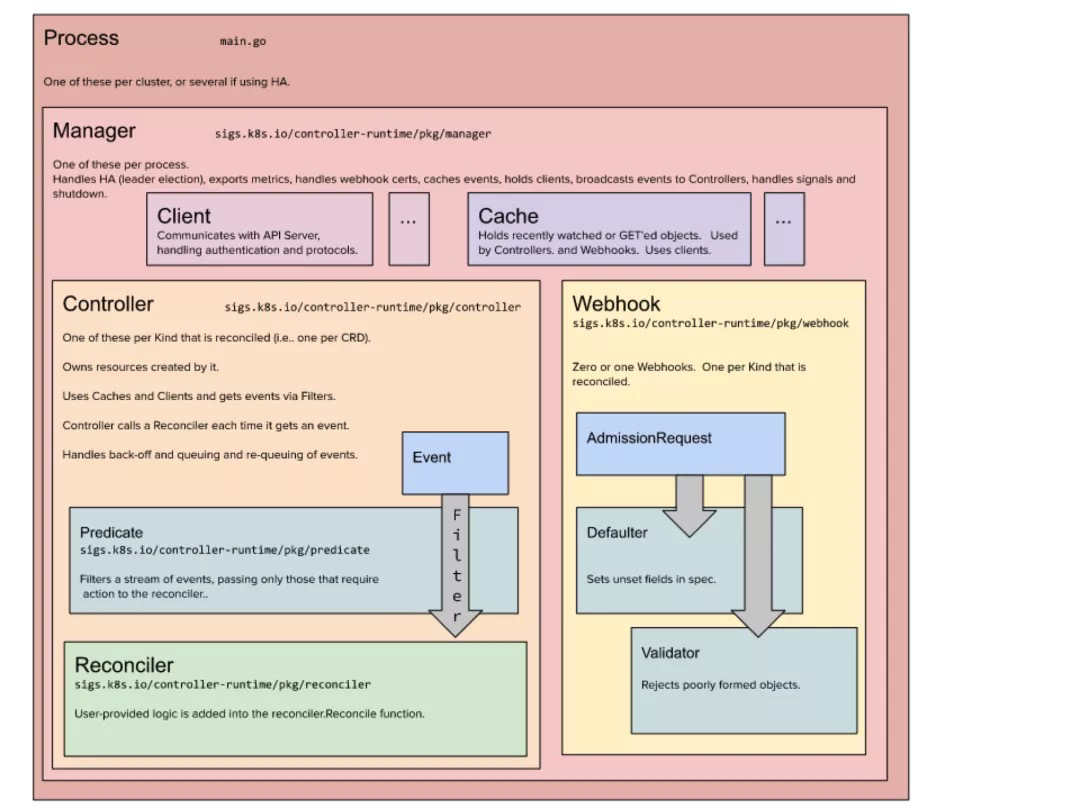
Taking the User resource as an example, we can define the CRD[8] of the following structure to abstract the User:
apiVersion: iam.kubesphere.io/v1alpha2 kind: User metadata: annotations: iam.kubesphere.io/last-password-change-time: "2021-05-12T05:50:07Z" name: admin resourceVersion: "478503717" selfLink: /apis/iam.kubesphere.io/v1alpha2/users/admin uid: 9e438fcc-f179-4254-b534-e913dfd7a727 spec: email: admin@kubesphere.io lang: zh description: 'description' password: $2a$10$w312tzLTvXObnfEYiIrk9u5Nu/reJpwQeI66vrM1XJETWtpjd1/q2 status: lastLoginTime: "2021-06-08T06:37:36Z" state: Active
The corresponding API is:
# establish
POST /apis/iam.kubesphere.io/v1alpha2/users
# delete
DELETE /apis/iam.kubesphere.io/v1alpha2/users/{username}
# modify
PUT /apis/iam.kubesphere.io/v1alpha2/users/{username}
PATCH /apis/iam.kubesphere.io/v1alpha2/users/{username}
# query
GET /apis/iam.kubesphere.io/v1alpha2/users
GET /apis/iam.kubesphere.io/v1alpha2/users/{username}
KS apiserver is responsible for writing these data to K8s, and then informer synchronizes them to each replica.
KS controller manager monitors data changes to maintain resource status. Take creating users as an example, through post / APIs / Iam kubesphere. After IO / v1alpha2 / users creates a user, the user controller synchronizes the user resource status.
func (c *userController) reconcile(key string) error {
// Get the user with this name
user, err := c.userLister.Get(key)
if err != nil {
// The user may no longer exist, in which case we stop
// processing.
if errors.IsNotFound(err) {
utilruntime.HandleError(fmt.Errorf("user '%s' in work queue no longer exists", key))
return nil
}
klog.Error(err)
return err
}
if user, err = c.encryptPassword(user); err != nil {
klog.Error(err)
return err
}
if user, err = c.syncUserStatus(user); err != nil {
klog.Error(err)
return err
}
// synchronization through kubefed-controller when multi cluster is enabled
if c.multiClusterEnabled {
if err = c.multiClusterSync(user); err != nil {
c.recorder.Event(user, corev1.EventTypeWarning, controller.FailedSynced, fmt.Sprintf(syncFailMessage, err))
return err
}
}
c.recorder.Event(user, corev1.EventTypeNormal, successSynced, messageResourceSynced)
return nil
}
The complex logic is put into the controller for processing through the declarative API to facilitate decoupling. It can be easily integrated with other systems and services, such as:
/apis/devops.kubesphere.io/v1alpha2/namespaces/{namespace}/pipelines
/apis/devops.kubesphere.io/v1alpha2/namespaces/{namespace}/credentials
/apis/openpitrix.io/v1alpha2/namespaces/{namespace}/applications
/apis/notification.kubesphere.io/v1alpha2/configs
Corresponding permission control policies:
Define a role that can add, delete, modify and query user resources.
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: user-manager rules: - apiGroups: ["iam.kubesphere.io"] resources: ["users"] verbs: ["create","delete","patch","update","get","list"]
Define a role that can create pipeline resources.
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: devops-manager rules: - apiGroups: ["devops.kubesphere.io"] resources: ["pipelines"] verbs: ["create","delete","patch","update","get","list"]
Reference link
[1]CustomResource: https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
[2]go-restful: https://github.com/emicklei/go-restful
[3]K8s mode: https://kubernetes.io/docs/reference/using-api/api-concepts/
[4]RBAC: https://kubernetes.io/docs/reference/access-authn-authz/rbac/
[5]controller-runtime: https://github.com/kubernetes-sigs/controller-runtime
[6]kubebuiler: https://github.com/kubernetes-sigs/kubebuilder
[7]RBAC: https://kubernetes.io/zh/docs/reference/access-authn-authz/rbac/
[8]CRD : https://raw.githubusercontent.com/kubesphere/kubesphere/master/config/crds/iam.kubesphere.io_users.yaml
author
Wan Hongming is a core contributor to KubeSphere, focusing on the field of cloud native security