1.partitionBy
1) Function signature
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
2) Function description
Repartition the data according to the specified Partitioner. Spark's default Partitioner is HashPartitioner
Note: partitionBy can only be called when rdd is converted to key value tuple type
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4))
rdd.map((_, 1))
.partitionBy(new HashPartitioner(2))
.saveAsTextFile("output")
sc.stop
}
}
The result is that two files part-00000 and part-00001 are generated in the output directory, respectively
(2, 1), (4, 1) and (1, 1), (3, 1)
3)HashPartitioner
The underlying core source code is as follows:


4) What if the partition of the repartition is the same as that of the current RDD?
Before partitioning, it will first judge whether the re partitioned partition and the current RDD partition are the same (type and number of partitions). If they are the same, they will not be re partitioned
5) Spark has other partitions
HashPartitioner,RangePartitioner,PythonPartitioner
6) You can customize the partitioner to partition data
2.reduceByKey
1) Function signature
def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
2) Function description
Value s can be aggregated by the same Key
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
rdd.reduceByKey(_ + _)
.collect.foreach(println)
sc.stop
}
}
The output result is (a, 6) (b, 4)
Note: in reduceByKey, if there is only one Key data, it will not participate in the operation
3.groupByKey
1) Function signature
def groupByKey(): RDD[(K, Iterable[V])] def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
2) Function description
Divide the data in the data source and the data with the same Key into a group to form a dual tuple
The first element in a tuple is a Key, and the second element is a collection of values with the same Key
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4)
))
rdd.groupByKey
.collect.foreach(println)
sc.stop
}
}
3) Distinguish between groupBy and groupByKey
The objects grouped by groupBy are uncertain, and parameters need to be passed in; groupByKey must be grouped by key
After groupBy is grouped, tuples are stored in the set; After groupByKey is grouped, Value is stored in the collection
4) What is the difference between reduceByKey and groupByKey?
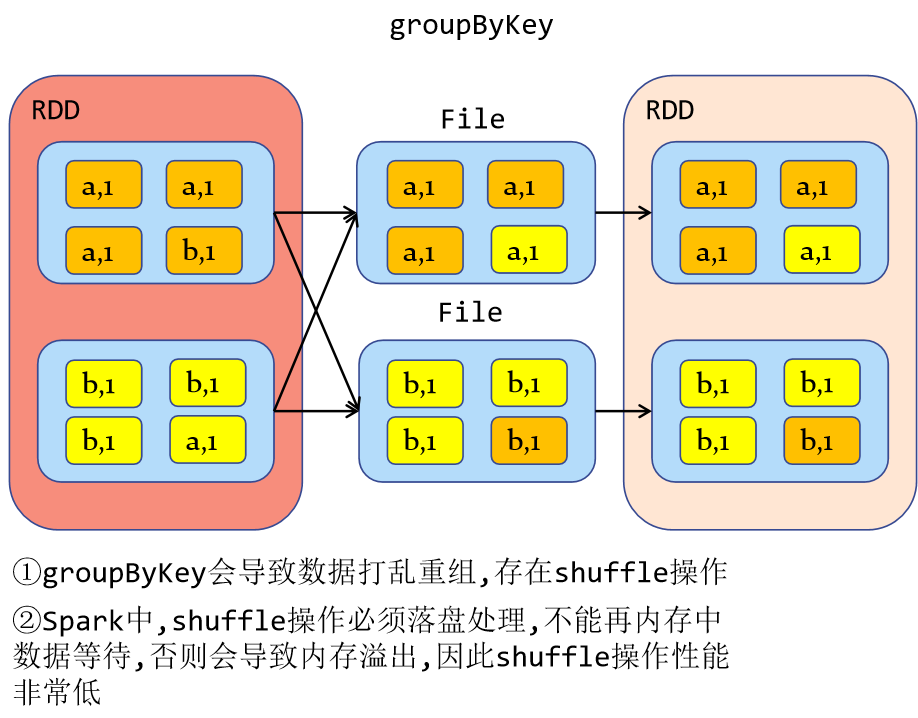
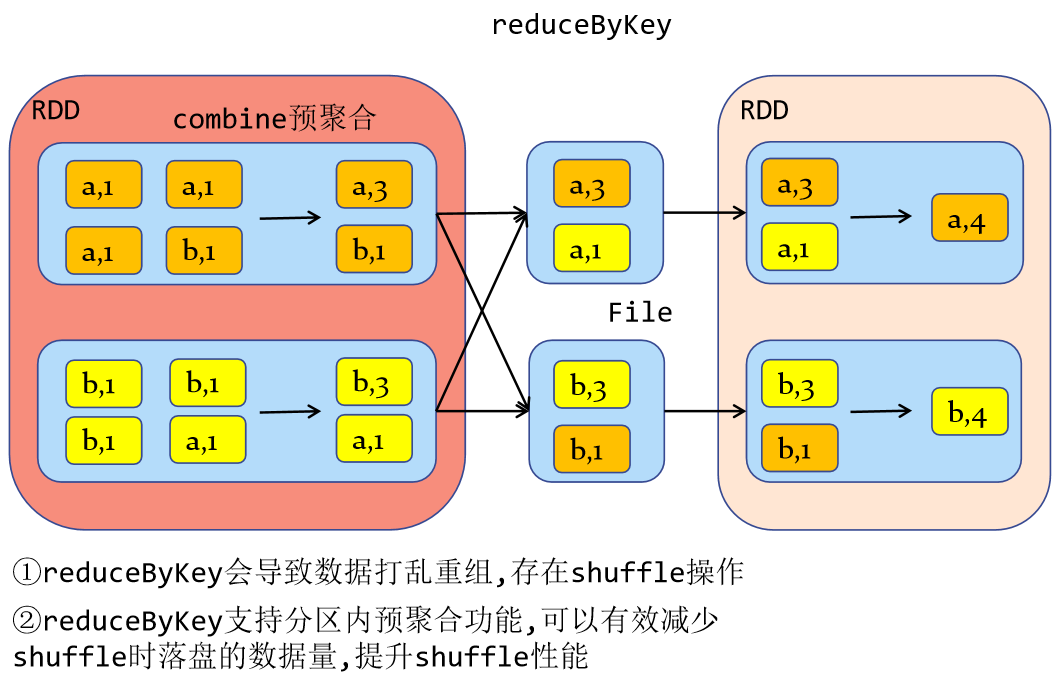
(1) From the perspective of shuffle:
Both reduceByKey and groupByKey have shuffle operations, but reduceByKey can pre aggregate the data of the same key in the partition before shuffle, which will reduce the amount of data falling into the disk. However, groupByKey is only grouping, and there is no problem of reducing the amount of data. reduceByKey has high performance.
(2) From a functional perspective:
reduceByKey actually contains grouping and aggregation functions. groupByKey can only be grouped and cannot be aggregated. Therefore, reduceByKey is recommended for grouping aggregation; If only grouping is needed without aggregation, then only groupByKey can be used
4.aggregateByKey
1) Function signature
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
2) Function description
Calculate the data within and between partitions according to different rules
Different from reduceByKey, reduceByKey has the same calculation within and between partitions
Parameter interpretation:
aggregateByKey has function coritization and has two parameter lists
a. The first parameter list needs to pass a parameter: it represents the initial value. When the first key is encountered, it will be calculated in the partition with value
b. The second parameter list needs to pass two parameters: the first parameter represents the calculation rules within partitions, and the second parameter represents the calculation rules between partitions
Example:
Take the maximum Value of Value in the partition and sum the maximum values between partitions
[("a", 1), ("a", 2)],[("a", 3), ("a", 4)]
[("a", 2)],[("a", 4)]
[("a", 6)]
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("b", 4)), 2)
rdd.aggregateByKey(0)(math.max, _ + _)
.collect.foreach(println)
sc.stop
}
}
3) The calculation process is as follows:
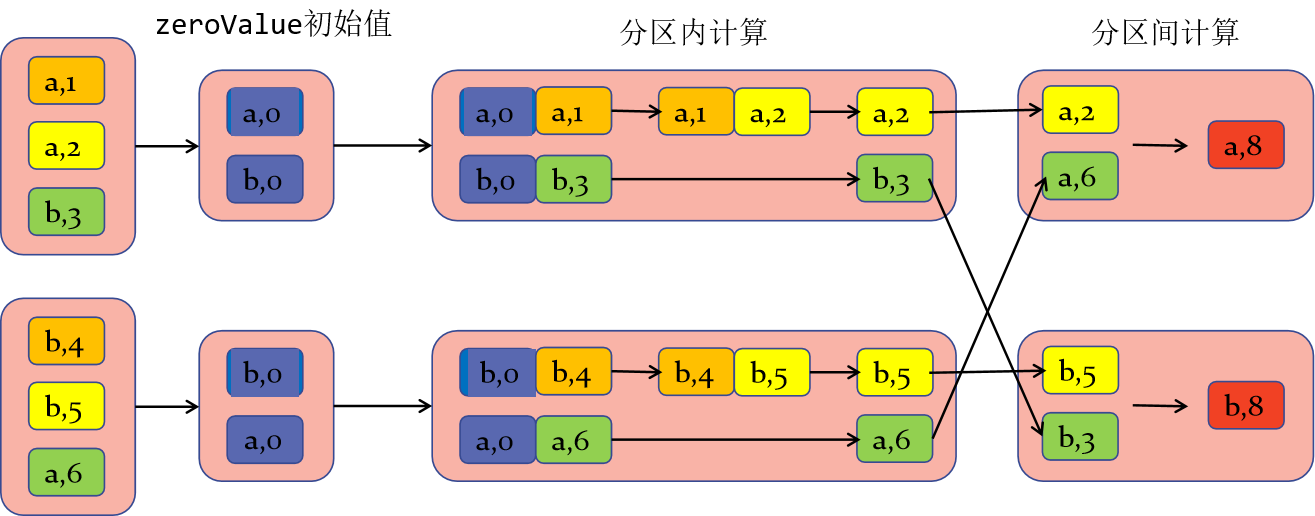
The initial value of zeroValue should be selected reasonably, otherwise the calculation result will be wrong
4) Note:
The final returned data result of the aggregateByKey is consistent with the type of the initial Value, that is, the Value type of the new RDD depends on the type of the incoming initial Value
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)
), 2)
val newRDD = rdd.aggregateByKey((0, 0))(
//Logic in partition: tuple - > (sum of value s of the same key, number of the same key)
(tuple, value) => (tuple._1 + value, tuple._2 + 1),
//Inter partition logic
(tuple1, tuple2) => (tuple1._1 + tuple2._1, tuple1._2 + tuple2._2)
)
val resRDD = newRDD.mapValues {
case (num, count) => num / count
}
resRDD.collect.foreach(println)
sc.stop
}
}
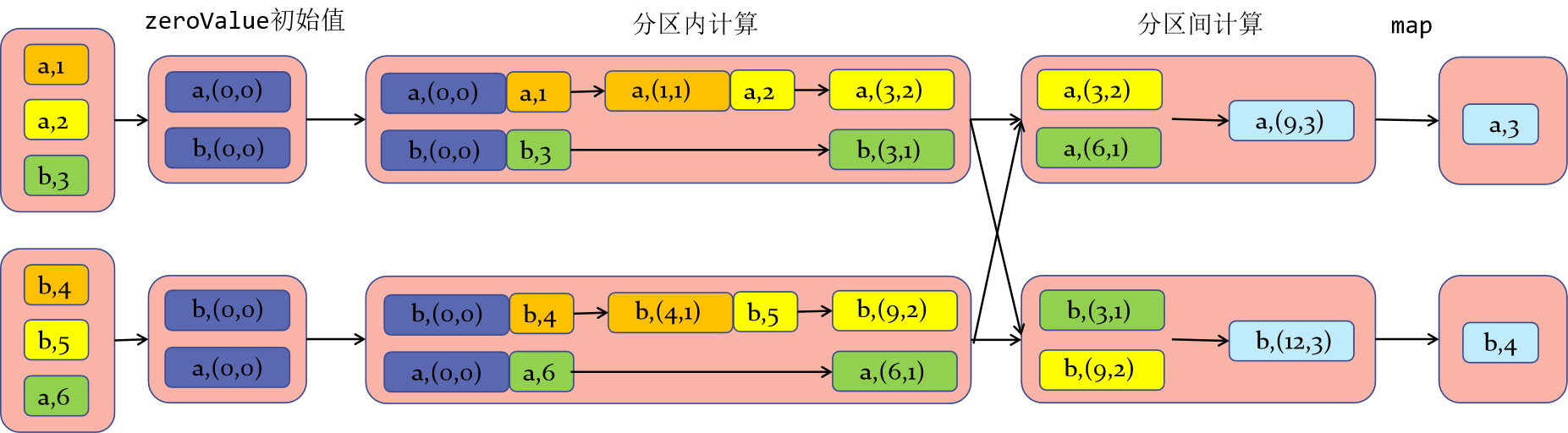
5.foldByKey
1) Function signature
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
2) Function description
When the intra partition calculation rules are the same as the inter partition calculation rules, the aggregateByKey can be simplified to foldByKey
6.combineByKey
1) Function signature
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
2) Function description
The most common aggregation function used to aggregate key value RDDS. Similar to aggregate(), combineByKey() allows the user to return a value whose type is inconsistent with the input
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("b", 3), ("b", 4), ("b", 5), ("a", 6)
), 2)
//The combineByKey method needs to pass in three parameters
//1. Convert the first data of the same key to the structure and realize the operation
//2. Calculation rules within the zone
//3. Calculation rules between zones
//Since the type of the initial value is determined at run time, the type is specified
rdd.combineByKey(
v => (v, 1),
(t:(Int, Int), v) => (t._1 + v, t._2 + 1),
(t1:(Int, Int), t2:(Int, Int)) => (t1._1 + t2._1, t1._2 + t2._2)
)
.mapValues{
case (sum, count) => sum / count
}
.collect.foreach(println)
sc.stop
}
}
The internal calculation diagram is as follows:
Difference from aggregateByKey: the first value is not calculated in the partition, but directly converted
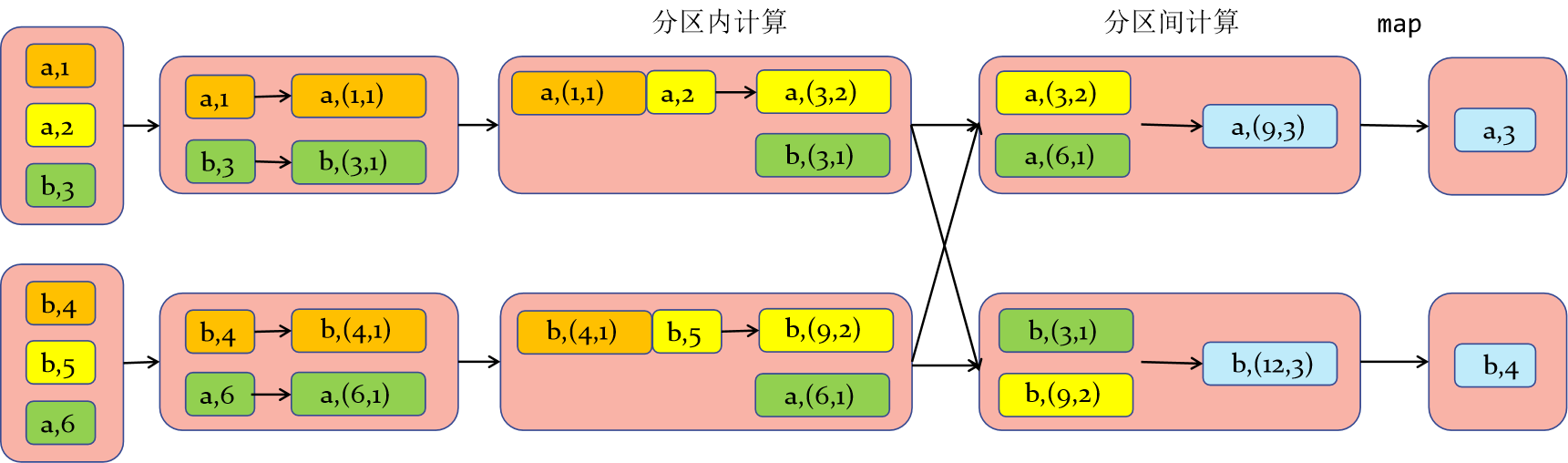
What are the relationships and differences among reduceByKey, aggregateByKey, foldByKey and combineByKey?
In fact, the bottom layers of these four operators call the same function combineByKeyWithClassTag, but the parameters passed in are different
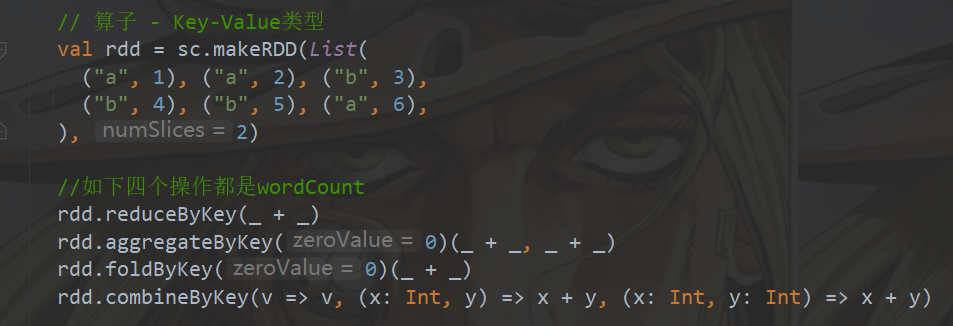

reduceByKey: the first data of the same key is not calculated. The calculation rules within and between partitions are the same
foldByKey: the first data and initial value of the same key are calculated within the partition. The calculation rules within and between partitions are the same
aggregateByKey: the first data and initial value of the same key are calculated within partitions. The calculation rules within and between partitions can be different
combineByKey: when it is found that the data structure does not meet the requirements during calculation, the first data structure can be converted. The calculation rules within and between partitions are different
7.sortByKey
1) Function signature
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
2) Function description
When called on a (K,V) RDD, K must implement the Ordered interface (trait) and return an RDD sorted by key
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a", 1), ("b", 3), ("c", 2)), 2)
//Sort from small to large
rdd.sortByKey(true).collect.foreach(println)
println("--------")
//Sort from large to small
rdd.sortByKey(false).collect.foreach(println)
sc.stop
}
}
The results are as follows:

8.join
1) Function signature
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
2) Function description
Call on RDDS of types (K,V) and (K,W) to return the RDD of (K,(V,W)) connected by all elements corresponding to the same key
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 4), ("c", 6)))
rdd1.join(rdd2)
.collect.foreach(println)
sc.stop
}
}
give the result as follows
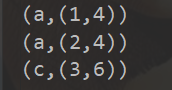
3) Explain
a. For data from two different data sources, the value of the same key will be connected together to form a tuple
b. If the key s in the two data sources do not match, the data will not appear in the result
c. If multiple key s in two data sources are the same, they will be matched in turn. Cartesian product may occur, and the amount of data will increase geometrically, resulting in performance degradation
9.leftOuterJoin
1) Function signature
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
2) Function description
It is similar to the left outer connection in SQL
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5)))
rdd1.leftOuterJoin(rdd2)
.collect.foreach(println)
sc.stop
}
}
The results are as follows:
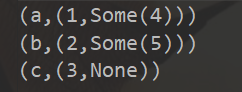
The same goes for rightOuterJoin
10.cogroup
1) Function signature
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
2) Function description
import org.apache.spark.{SparkConf, SparkContext}
object TestRDD {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 2), ("b", 1)))
val rdd2 = sc.makeRDD(List(("a", 5), ("b", 3), ("c", 3), ("c", 7)))
rdd1.cogroup(rdd2)
.collect.foreach(println)
sc.stop
}
}
The results are as follows:

3) Description:
① Unlike join, cogroup will first group (collect + group) within the same RDD
② A cogroup can connect multiple RDD S, and a join can only connect two