
In the previous section, you learned what CAS is, the type of lock formed by synchronized, the heavyweight lock is the process of applying for resource locking from the user state process to the internal core state, the HotSpot Java object structure, and preliminarily analyzed the core process of synchronized from three levels. Remember the core flowchart?
As follows:
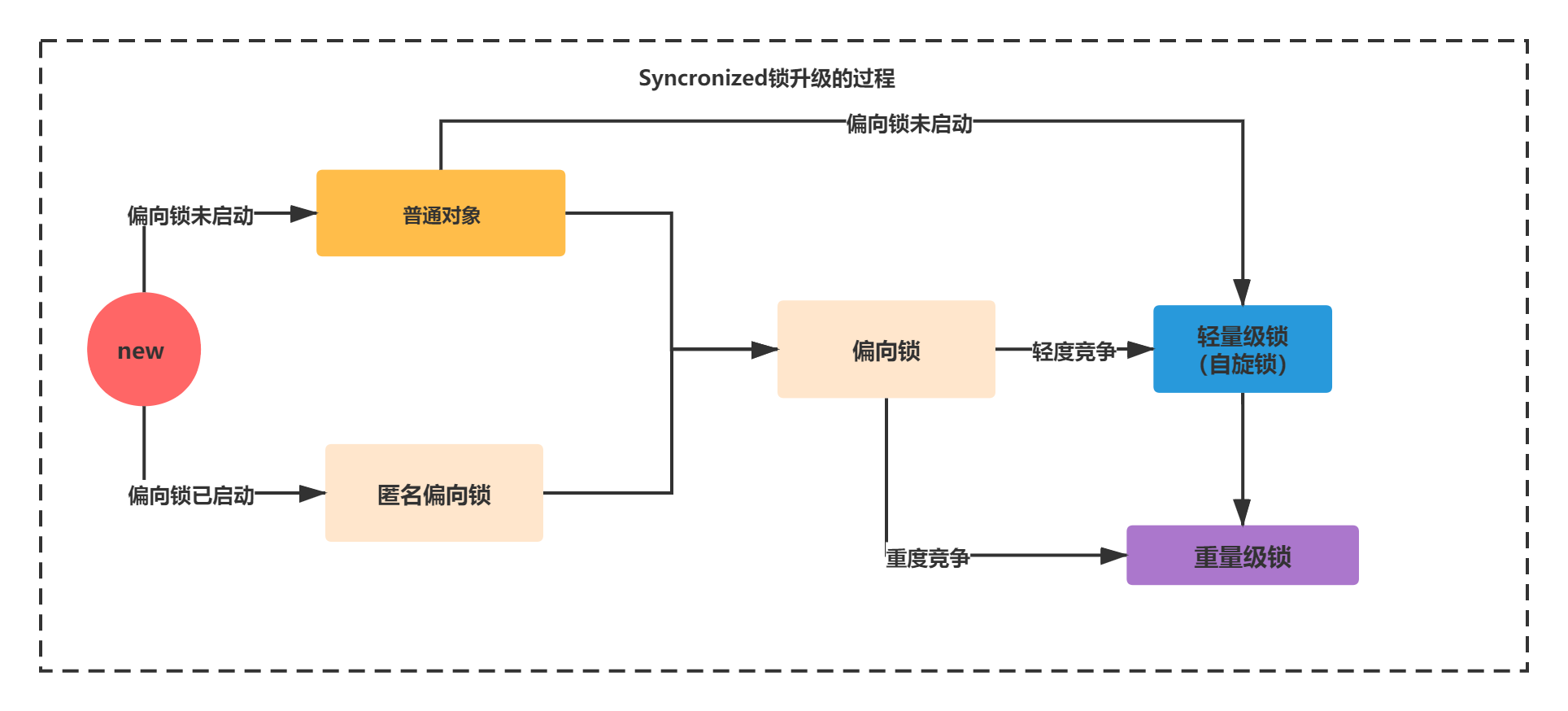
In this section, we will carefully analyze the underlying principles of each step in this process. We need to use a toolkit, JOL, which can print out the information of java objects. You can use this tool to analyze the lock mark changes during the upgrade process.
Detailed explanation of synchronized lock upgrade process
Detailed explanation of synchronized lock upgrade process
First, let's look at:
Bias lock not started: no lock state new - > normal object.
Bias lock started: no lock state new - > anonymous bias lock.
Let's take an example: setting JVM parameters, - XX:BiasedLockingStartupDelay=10 environment: JDK1.8
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.10</version> </dependency>
public class HelloSynchronized {
public static void main(String[] args) {
Object object = new Object();
System.out.println(ClassLayout.parseInstance(object).toPrintable());
synchronized (object){
}
}
}The output results are as follows:
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalLarge end or small end sequence? System.out.println(ByteOrder.nativeOrder()); You can view the byte order of the current cpu. The output is LITTLE_ENDIAN means small endian l small endian: the high-order bytes of data are stored at the high end of the address and the low-order bytes are stored at the low end of the address L Large endian: the high-order bytes of data are stored at the low end of the address and the low-order bytes are stored at the high end of the address. For example, an integer 0x1234567, 1 is high-order data and 7 is low-order data. According to the small end order, 01 is placed in the high order of the memory address, such as 0x100, 23 is placed in 0x101, and so on. The large end sequence is the opposite.
The following figure: (the picture comes from the network)
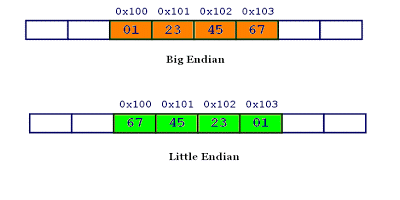
You can see the mark 0 01 in the Value of Obejct header with OFFSET 0-4.
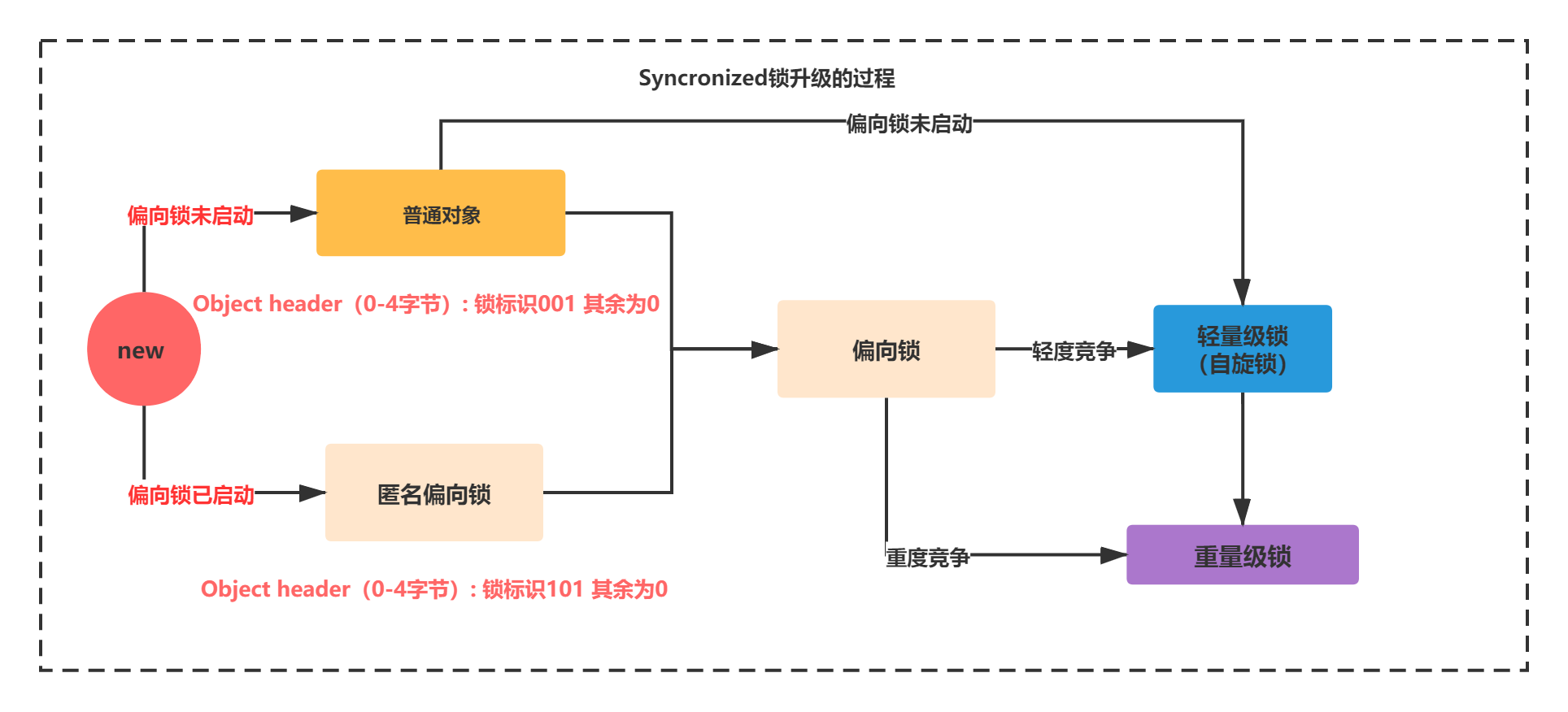
In other words, Object o = new Object() default lock = 0 01 indicates the unlocked state. Note: if the bias lock is opened, the default is the anonymous bias state.
You can modify the JVM parameter - XX:BiasedLockingStartupDelay=0. Run again
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalYou can see the mark 1 01 in the Value of Obejct header with OFFSET 0-4. Indicates a biased lock. Why is it anonymous? In the underlying C + + code of the JVM, the bias lock has a C + + variable JavaThread pointer by default. This pointer is recorded with 54 bits. From the Value of the object header with OFFSET of 0-4, it can be seen that except that the lock is marked as 101, the rest are 0, indicating that there is no JavaThread pointer, so it is an anonymous bias.
What does it mean that the bias lock is not activated? The bias lock is not started, which means that the bias lock has a delay by default. The default is 4 seconds (different JDK versions can be different). It can be controlled through a JVM parameter, - XX:BiasedLockingStartupDelay=4. Because the JVM virtual machine has some threads started by default, and there are many sync codes in them. When these sync codes are started, they know that there will be competition. If the bias lock is used, it will cause the bias lock to continuously revoke and upgrade the lock, which is inefficient.
Therefore, the changes of the two processes are shown in the following figure:
Then we look back:
- Deflection lock started: no lock state new - > anonymous deflection lock
- Bias lock not started: no lock state new - > Common Object - bias lock
When the synchronization code is executed, there is a clear locking thread, so we add a line of log and print the Object header information of the Object. We will find that the following changes have taken place:
public class HelloSynchronized {
public static void main(String[] args) {
Object object = new Object();
System.out.println(ClassLayout.parseInstance(object).toPrintable());
synchronized (object){
System.out.println(ClassLayout.parseInstance(object).toPrintable());
}
}
} java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 f8 ba 86 (00000101 11111000 10111010 10000110) (-2034567163)
4 4 (object header) b0 01 00 00 (10110000 00000001 00000000 00000000) (432)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalYou can see that the Value of Obejct header with OFFSET of 0-4 is not all 0 except 1 01, indicating that it is no longer an anonymous bias lock.
If it is not an anonymous biased lock, but an ordinary object, it will directly become a biased lock after entering the synchronized code block. As shown in the figure below:
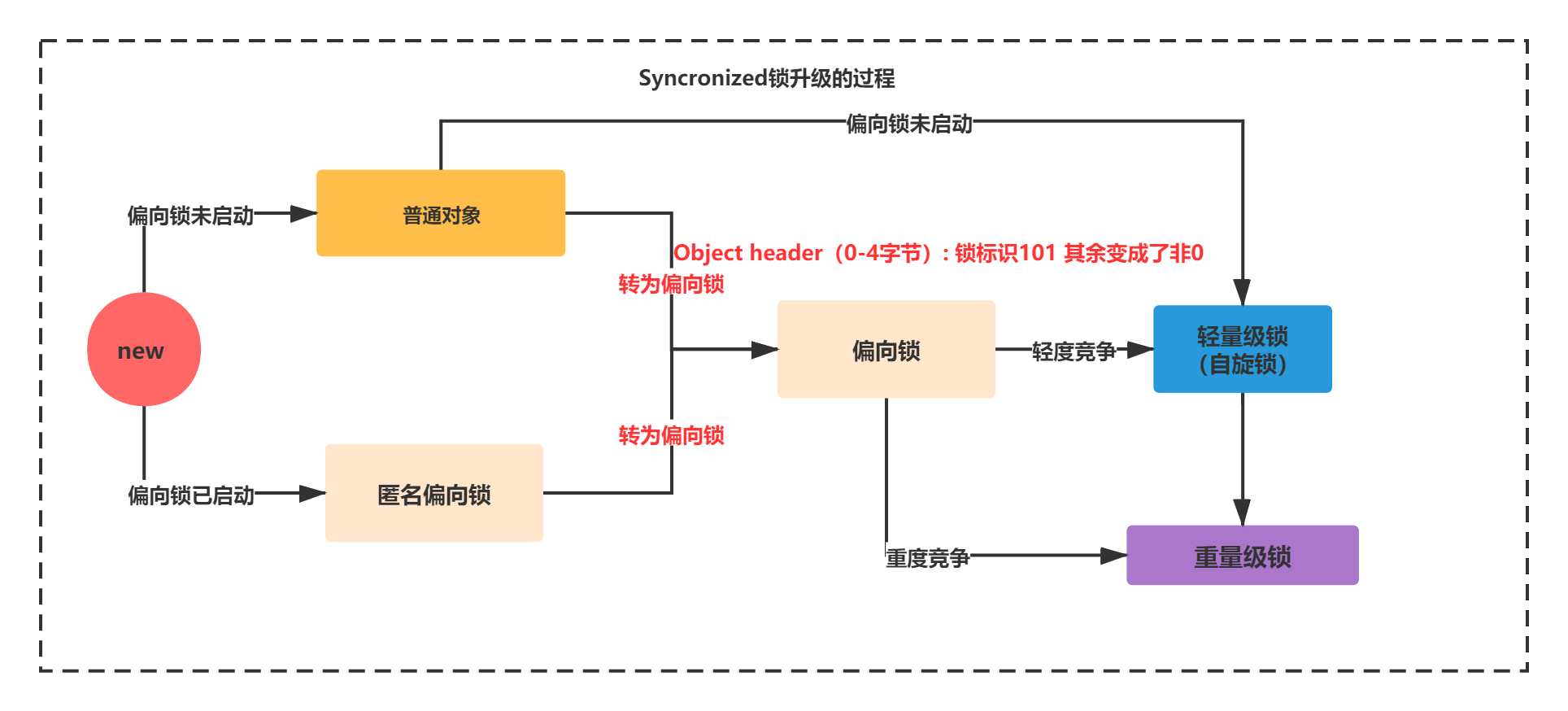
Bias lock not started: no lock state new - > normal object - > lightweight lock (spin lock)
Next, let's take a look. No lock can also directly become a lightweight lock. Set the JVM parameter, - XX:BiasedLockingStartupDelay=10, add the JOL printout in synchronized, and the following object information will be printed:
//-XX:BiasedLockingStartupDelay=10 public static void main(String[] args) { Object object = new Object(); System.out.println(ClassLayout.parseInstance(object).toPrintable()); //new normal object 0 01 synchronized (object){ System.out.println(ClassLayout.parseInstance(object).toPrintable()); //New - > lightweight lock 00 } }
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) e0 f0 9f 70 (11100000 11110000 10011111 01110000) (1889530080)
4 4 (object header) 2a 00 00 00 (00101010 00000000 00000000 00000000) (42)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalThis process is shown in the following figure:
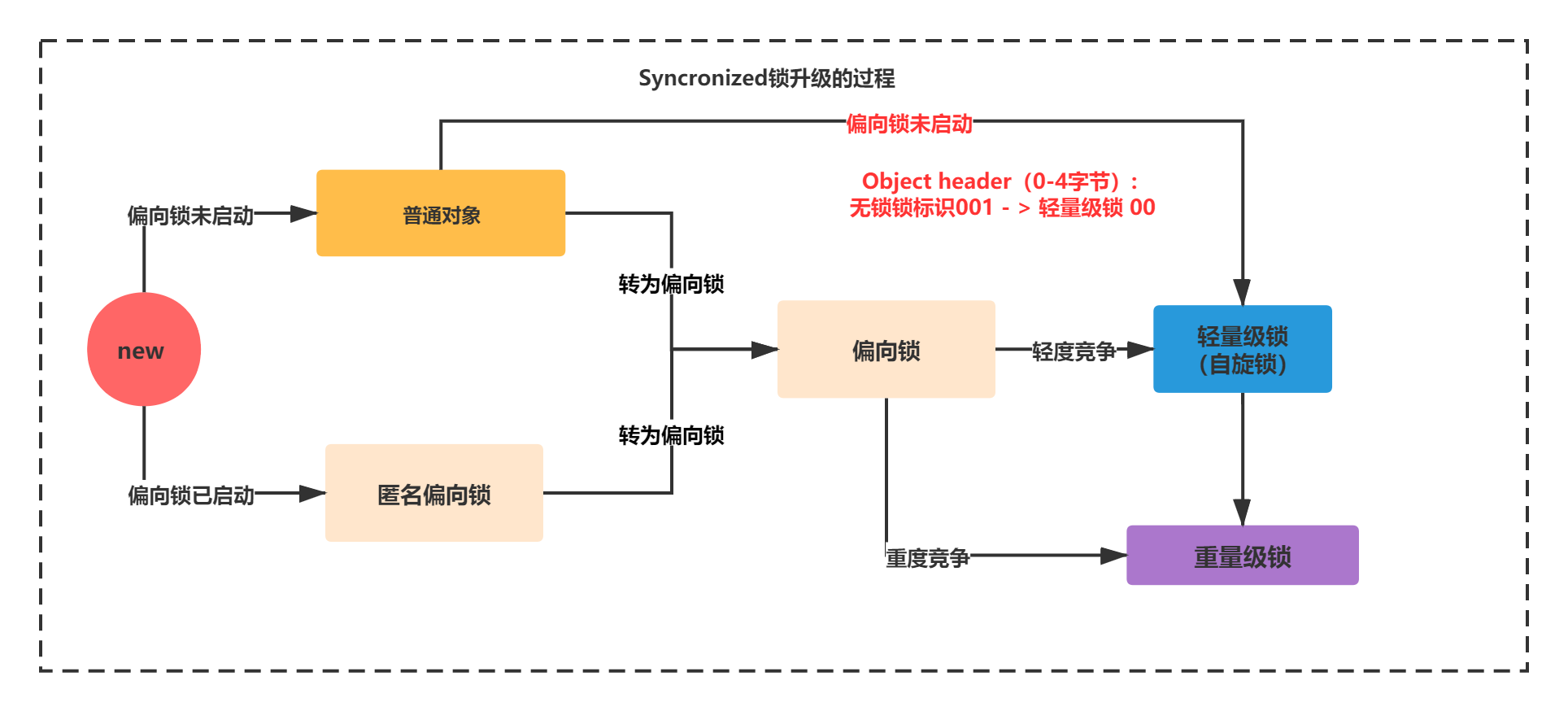
- Bias lock - > lightweight lock (light competition)
When a thread competes for a lock, the bias lock will be revoked and the lightweight lock will be upgraded.
//-XX:BiasedLockingStartupDelay=0
public static void main(String[] args) {
Object object = new Object();
System.out.println("initialization new");
System.out.println(ClassLayout.parseInstance(object).toPrintable()); //101 + all 0 anonymous biased locks
synchronized (object){
System.out.println(ClassLayout.parseInstance(object).toPrintable());//101 + non-0 bias lock
}
new Thread(()->{
try {
Thread.sleep(1000);
synchronized (object){
System.out.println("t Thread acquire lock");
System.out.println(ClassLayout.parseInstance(object).toPrintable()); //00 object is locked by another thread, competing, biased lock - > lightweight lock
}
} catch (InterruptedException e) {}
}).start();
} java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 20 cc 74 (00000101 00100000 11001100 01110100) (1959534597)
4 4 (object header) b3 01 00 00 (10110011 00000001 00000000 00000000) (435)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) d8 f3 df 89 (11011000 11110011 11011111 10001001) (-1981811752)
4 4 (object header) 46 00 00 00 (01000110 00000000 00000000 00000000) (70)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalYou can see that the lock changes from anonymous bias - > bias - > lightweight lock. Here is a brief introduction to the underlying principle of lightweight lock:
When it becomes a lightweight lock, if another thread attempts to obtain the lock, it will generate a LockRecord C + + object in its own thread stack. Use CAS operation to point to the 62 bit address in markword and use reference (c + + called pointer) to point to the corresponding LR object of its own thread. If it is set that the winner gets the lock, otherwise continue CAS to execute circular spin operation. (PS: the bottom layer of lightweight lock is to use a LockRecord C + + object, and the object pointer of JavaThread is preferred)
The whole upgrade process is shown in the figure below:
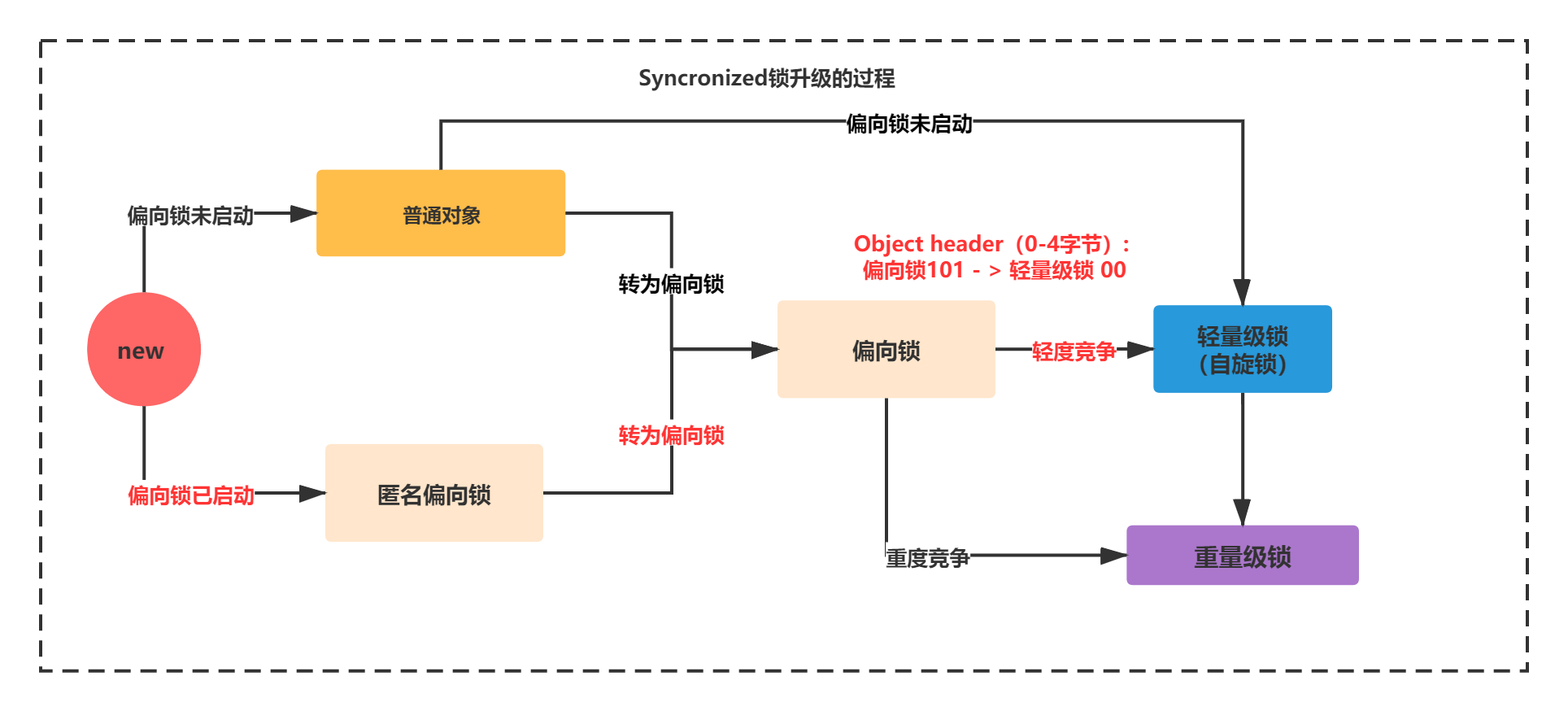
- Bias lock - > heavyweight lock (heavy competition)
A long time ago, JDK judged that the condition of intensified competition was that there were more than 10 spins of threads (through - XX:PreBlockSpin) or the number of spin threads exceeded half of the number of CPU cores. However, after 1.6, the adaptive self spinning mechanism is added, and the upgrade of heavyweight locks is controlled by the JVM itself.
When upgrading, apply for resources from the operating system, apply for mutex through linux mutex, call the CPU from level 3 to level 0, suspend the thread, enter the waiting queue, wait for the scheduling of the operating system, and then map back to the user space.
//-XX:BiasedLockingStartupDelay=0
public static void main(String[] args) {
System.out.println(ByteOrder.nativeOrder());
Object object = new Object();
System.out.println(ClassLayout.parseInstance(object).toPrintable()); //101 + all 0 anonymous biased locks
System.out.println("initialization new");
synchronized (object){
System.out.println(ClassLayout.parseInstance(object).toPrintable());//101 + non-0 bias lock
}
for(int i=0;i<10;i++){
new Thread(()->{
try {
Thread.sleep(1000);
synchronized (object){
System.out.println(Thread.currentThread().getName()+"Thread acquire lock");
System.out.println(ClassLayout.parseInstance(object).toPrintable()); //10. The object is competed by multiple threads, with bias lock - > weight lock
}
} catch (InterruptedException e) {}
}).start();
}
} java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
// Initialize new
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 08 18 e4 (00000101 00001000 00011000 11100100) (-468187131)
4 4 (object header) 1f 02 00 00 (00011111 00000010 00000000 00000000) (543)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
//Thread-0 thread acquires lock
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 02 8f 57 ff (00000010 10001111 01010111 11111111) (-11038974)
4 4 (object header) 1f 02 00 00 (00011111 00000010 00000000 00000000) (543)
8 4 (object header) 00 10 00 00 (00000000 00010000 00000000 00000000) (4096)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes totalAs can be seen from the above code, lock upgrading is a process from anonymous biased lock - > biased lock - > weight lock. The JVM judges that 10 threads are created in the for loop. The competition is fierce. When the thread obtains the lock, it is the heavyweight lock directly. As shown in the figure below:
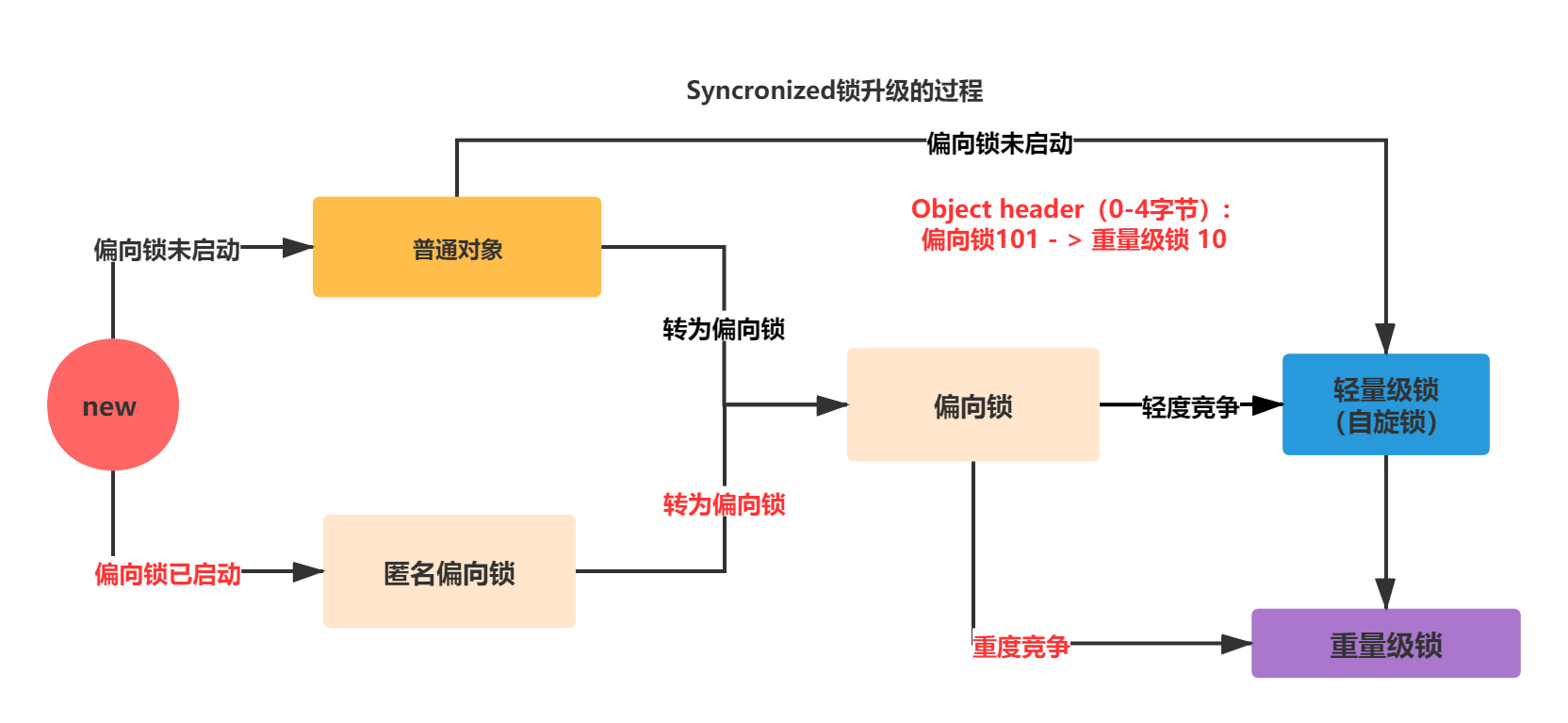
In the last line, I won't demonstrate the code from lightweight lock to heavyweight lock. When the competition intensifies, the lightweight lock will be upgraded to heavyweight lock.
Well, I'm sure you have a very clear understanding of the synchronized lock upgrade process. Next, let's look at some principles and details of the lock upgrade process.
Core principles and details of lock upgrade process
Core principles and details of lock upgrade process
Since the synchronized locking mechanism is closely related to the structure of the java object header, the markword in the object header has the meanings of lock mark, generation age, pointer reference and so on. Next, let's carefully analyze the underlying principles of lower bias lock, spin lock and heavyweight lock and the relationship between markword in the object header.
Basic principle of deflection lock
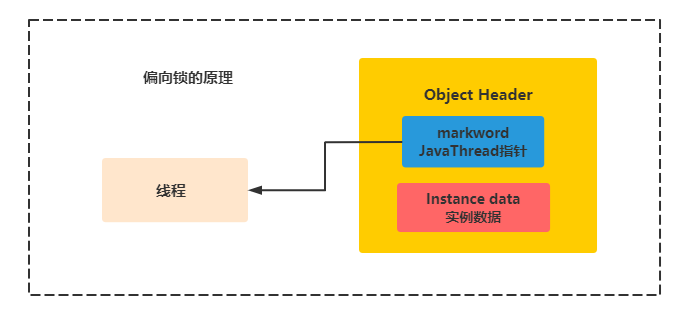
C + + implementation mechanism and reentrancy of lightweight lock (stack based)
The principle of lightweight lock is similar to that of bias lock, except that the pointer in markWord is a LockRecord, and the operation of modifying the pointer is CAS. If the CAS setting of that thread is successful, the lock will be obtained. As shown in the figure below:
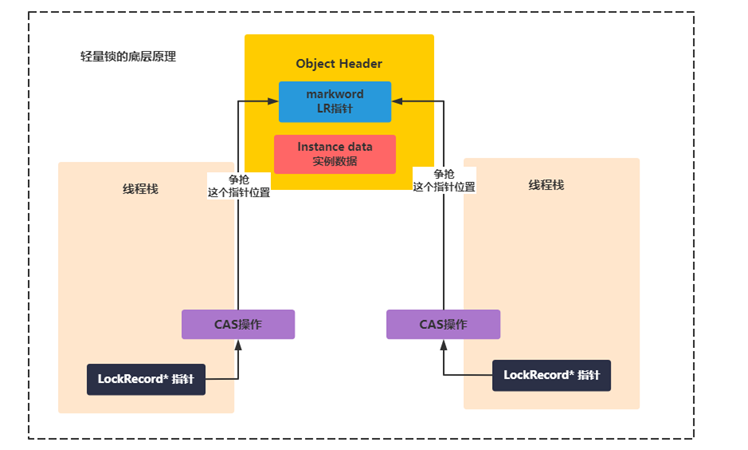
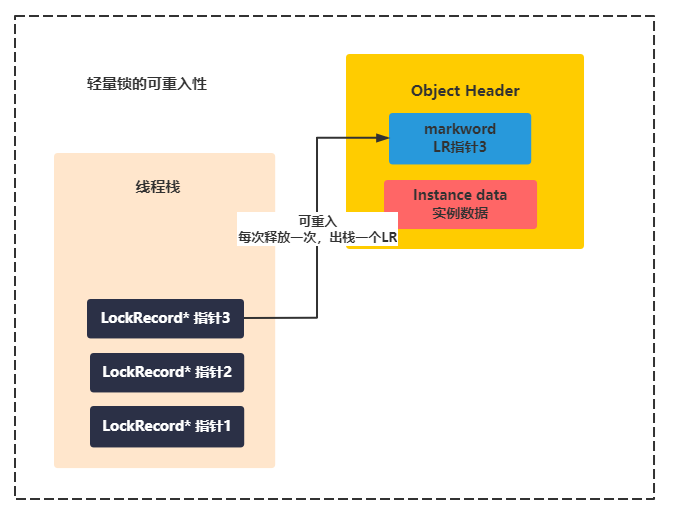
The synchronized lock is reentrant, so that the subclass can call the synchronization method of the parent class without problems. Synchronized code blocks can also be added multiple times using the same object or class. Therefore, the implementation of lightweight lock reentry is based on the stacked LR object to record the reentry times. As follows:
C + + implementation mechanism and reentrancy of weight lock (based on ObjectMonitor, similar to AQS)
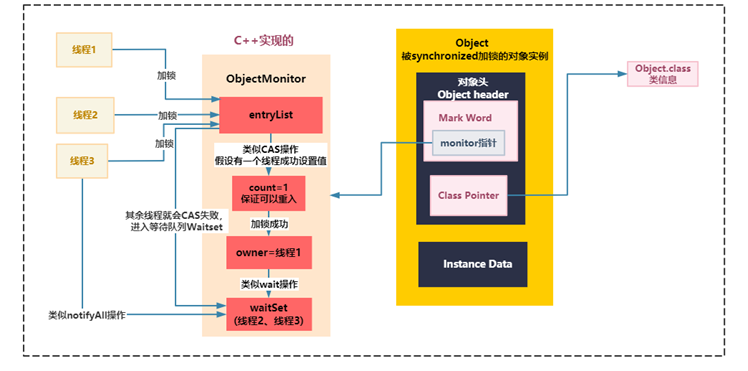
The underlying principle of heavyweight lock is that there is a pointer in Mark Word that points to the address of the monitor object associated with the object instance. The monitor is implemented in C + +, not in java. The monitor is actually an ObjectMonitor object implemented in C + +, which contains an _owner pointer to the thread holding the lock. ObjectMonitor has its C + + structure The structure is as follows:
// objectMonitor.hpp
ObjectMonitor() {
_header = NULL;
_count = 0; // Reentry times
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL; // Thread obtaining lock
_WaitSet = NULL; // Blocked thread calling wait() method
_WaitSetLock = 0 ;
_Responsible = NULL
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // Those threads in the content list that are eligible to be candidates are moved to the Entry List
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}There is also an entrylist in ObjectMonitor. All threads that want to lock enter the entrylist first and wait for the opportunity to try to lock. For threads that actually have the opportunity to lock, they will set the _owner pointer to themselves, and then accumulate the _count counter once.
Each thread tries to compete to lock. At this time, the competitive locking is optimized after JDK 1.6 to lock based on CAS. It is understood that the locking mechanism is similar to that of the previous Lock API. CAS operates and operates the _countcounter, for example, trying to change the _countvalue from 0 to 1.
If it succeeds, the locking succeeds. count is incremented by 1 and modified to. If it fails, the locking fails and the system enters the waitSet to wait.
Then, when releasing the lock, first decrease the _count counter by 1. If it is 0, it will set _owner to null and no longer point to itself, which means that you have completely released the lock.
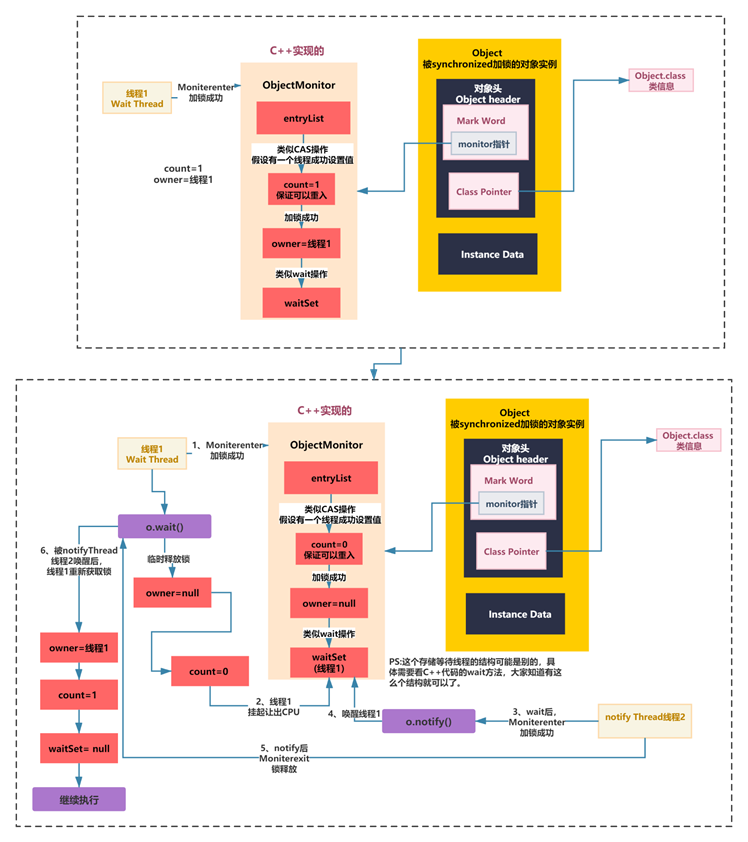
If the thread that obtains the lock executes wait, the counter will be decremented and _owner will be set to null. Then it enters the waitset to wait for wake-up. When others obtain the lock and execute notifyAll, they will wake up the threads in the waitset to compete and try to obtain the lock.
The whole process is as follows:
You may ask, how do you perform the process of trying to lock, that is, accumulating the _count counter? How do you ensure the atomicity of multithreading concurrency?
Very simply, the count operation in this place is an operation similar to CAS.
In fact, if you understand the AQS mechanism at the bottom of ReentrantLock, you will find that the implementation of synchronized bottom layer is similar to AQS.
However, the bottom layer of synchronized is ObjectMonitor, and its status is similar to that of the Sync component corresponding to AQS in ReentrantLock. You will find it when we talk about ReentrantLock later.
Why does a spin lock need a heavyweight lock?
Spin consumes CPU resources. If the lock time is long or there are many spin threads, the CPU will be consumed a lot.
The heavyweight lock has a waiting queue. All those who cannot get the lock enter the waiting queue without consuming CPU resources.
Is bias lock necessarily more efficient than spin lock?
Not necessarily. When it is clearly known that there will be multi-threaded competition, the biased lock will certainly involve lock revocation revoke and consume system resources. Therefore, when the lock competition is particularly fierce, using the biased lock may not be efficient. It is better to use the lightweight lock (spin lock) directly.
For example, during JVM startup, there will be a lot of thread contention (it has been clear), so the bias lock is not opened by default, and it will be opened after a period of time.
Lock elimination
public void add(String str1,String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
} We all know that StringBuffer is thread safe because its key methods are modified by synchronized. However, looking at the above code, we will find that the reference sb will only be used in the add method and cannot be referenced by other threads (because it is a local variable and the stack is private) Therefore, sb is a resource that cannot be shared, and the JVM will automatically eliminate the lock inside the StringBuffer object.
Lock coarsening
public String test(String str){
int i = 0;
StringBuffer sb = new StringBuffer():
while(i < 100){
sb.append(str);
i++;
}
return sb.toString():
} The JVM will detect that such a series of operations lock the same object (append is performed 100 times in the while loop, and lock / unlock is performed 100 times if there is no lock coarsening). At this time, the JVM will coarsen the scope of locking to the outside of the series of operations (such as outside the while phantom), so that the series of operations only need to add locks once.
wait and notify must be used with synchronized!?
wait and notify must be used with synchronized!?
Wait and notify / notifyAll are very useful in multi-threaded development and many open source projects. How to use wait and notifyall? Their main function is thread communication, so one thread can use wait to wait, and other threads can use notify to notify it or wake it up.
The underlying principle of wait and notify implementation is similar to that of synchronized heavyweight locking. It is mainly a monitor object. It should be noted that the same object instance must be locked. In this way, they actually operate the counters and wait set s related to monitor in an object instance.
In other words, wait and notify must be used in synchronized code blocks, because the underlying layer of wait/notify is C + + code, which operates on ObjectMonitor.
for instance:
public static void main(String[] args) throws InterruptedException {
Object o = new Object();
Thread waitThread = new Thread(() -> {
try {
synchronized (o) {
System.out.println(Thread.currentThread().getName() + "The thread acquires the lock and performs wait operation");
o.wait();
System.out.println(Thread.currentThread().getName() + "The thread continues to execute and then releases the lock");
}
} catch (InterruptedException e) {
}
});
waitThread.start();
Thread notifyThread =new Thread(()->{
try {
Thread.sleep(2000);
synchronized (o){
System.out.println(Thread.currentThread().getName()+"Thread acquire lock,implement notify Wake up operation");
o.notify();
System.out.println(Thread.currentThread().getName()+"The thread continues to execute and then releases the lock");
}
} catch (InterruptedException e) {}
});
notifyThread.start();
}The flow of the above code is shown in the following figure:
The above process involves many details. You need to carefully study the HotSpot C + + code. Interested students can study the C + + code of wait and notify/notifyAll.
In most cases, the core is to master the implementation mechanism of ObjectMonitor. You may have some questions. I found some common questions related to wait and notify for your reference.
(reproduced below from: https://zhuanlan.zhihu.com/p/113851988).
Why do I need a synchronized lock
In terms of implementation, this lock is very important. It is precisely because of this lock that the whole wait/notify can play. Of course, I think similar mechanisms can be implemented in other ways, but hotspot at least completely depends on this lock to realize wait/notify.
How can other threads enter the synchronization block if the wait method does not exit the synchronization block after execution
In fact, the answer to this question is very simple, because the synchronization lock will be released temporarily during the wait process. However, it should be noted that when a thread invokes notify to arouse the thread, the lock will be re obtained before the wait method exits. Only after obtaining the lock will the execution continue. Imagine, We know that the wait method is surrounded by the monitorenter and monitorexit instructions. If we release the lock during the execution of the wait method and don't take the lock when we come out, what will happen when the monitorexit instruction is executed? Of course, this can be compatible, but it's still strange to implement.
Why does the wait method throw an interruptedexception exception
Everyone should know this exception. When we call the interrupt method of a thread, the corresponding thread will throw this exception, and the wait method does not want to break this rule. Therefore, even if the current thread has been blocked because of wait, when a thread wants it to get up and continue to execute, it still has to recover from the blocking state, Therefore, when the wait method is awakened, it will detect this state. When a thread interrupts it, it will throw this exception and recover from the blocking state.
Here are two points to note:
If the thread interrupt ed is only created and does not start, it cannot be restored after it enters the wait state after start
If the thread interrupted has start ed, if a thread calls its interrupt method before entering the wait, the wait will jump out without blocking
Are threads notified (all) regular
Here are the following situations:
If a thread is invoked through notify, the thread that first enters the wait will be called first
If the thread is invoked through nootifyAll, by default, the last one will be called first, that is, the LIFO policy
Wake up the thread immediately after notify is executed
In fact, you can verify this. Write some logic after notify to see whether these logic are executed before or after other threads are awakened. This is a detail. Maybe you don't pay attention to this. In fact, the real implementation in hotspot is to wake up the corresponding thread when exiting the synchronization block, but this is also a default strategy, It can also be changed to wake up the relevant threads immediately after notify.
How does notifyAll achieve full arousal
Maybe you immediately think of this simple, a for loop is done, but it is not so simple in the jvm, but with the help of monitorexit. I mentioned above that when a thread recovers from the wait state, it is necessary to obtain the lock first, and then exit the synchronization block, Therefore, the implementation of notifyAll is that the thread calling notify wakes up the last thread entering the wait state when exiting the synchronization block, and then the thread continues to wake up the penultimate thread entering the wait state when exiting the synchronization block, and so on. Similarly, this is a policy problem. The jvm provides parameters for directly waking up threads one by one, But it's rare, so I won't mention it.
Will the wait thread affect the CPU load?
This may be a topic of concern, because it is related to system performance. The underlying layer of wait / nofit is implemented through the park/unpark mechanism in the jvm. In linux, this mechanism is implemented through pthread_cond_wait/pthread_cond_signal, so when a thread enters the wait state, it will actually give up the cpu, that is, such threads will not occupy cpu resources.
Summary
Summary
In today's growth notes, you should master the following knowledge:
1) The whole detailed process of synchronized lock upgrade
The upgrade process of locks is simply as follows: no lock - > biased lock - > spin lock - > heavyweight lock. In addition, there are many other upgrade branches. You must remember the following picture.
2) Core principles of synchronized different locks
Implementation mechanism of JVM lock based on Markword
Function of java thread pointer in bias lock
The role of LockRecord in lightweight lock (spin lock)
The role of ObjectMonitor in heavyweight locks
3) Implementation principle of wait and notify
4) Details about synchronized locks, wait and notify
This article is composed of blog one article multi posting platform OpenWrite release!