As we all know, the JVM's garbage removal algorithm is a copy removal algorithm used in the young generation, which is why the young generation is divided into two memory spaces of the same size: S0 and S1. When S0 is full, copy it to S1, and then empty S0. Of course, GC will tidy up the memory and make it continuous. What other common software or frameworks use this double buffer mechanism?
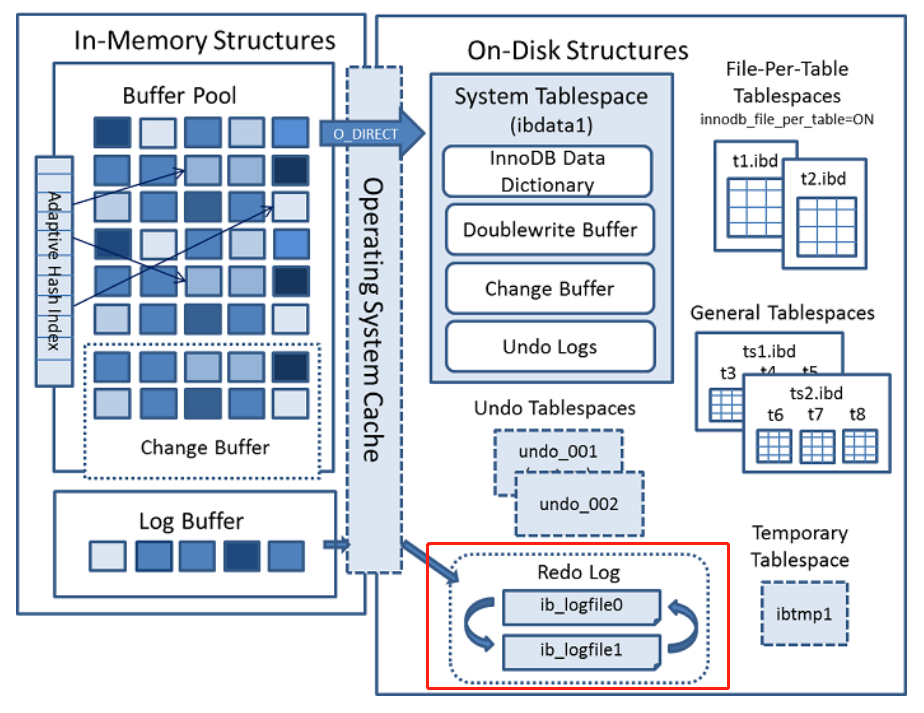
1. Redo Log of MySQL
As we know, there are two named IB in the data directory of InnoDB storage engine_ Logfile0 and ib_logfile1 file, this
It is the redo log file of InnoDB, which records the transaction log of InnoDB storage engine.
What is the role of redo log files?
Redo log files can come in handy when InnoDB's data storage files have errors. InnoDB storage engine can use redo
Make log files to restore the data to the correct state, so as to ensure the correctness and integrity of the data.
In order to obtain higher reliability, users can set multiple mirror log groups and put different file groups on different disks
To improve the high availability of redo logs.
How does the redo log file group write data?
Each InnoDB storage engine has at least one redo log file group, and there are at least two redo log files under each file group, such as default
Recognized ib_logfile0 and ib_logfile1.
In the log group, each redo log file has the same size and runs in a circular write mode.
InnoDB storage engine writes redo log file 1 first. When the file is full, it will switch to redo log file 2, and then on the redo day
When log file 2 is also full, switch to redo log file 1.
2. Hash of redis object type: a hashtable consists of 1 dict structure, 2 dictht structures, 1 dictEntry pointer array (called bucket) and multiple objects
Consists of a dictEntry structure.
Under normal conditions (i.e. when hashtable does not rehash), the relationship of each part is shown in the following figure
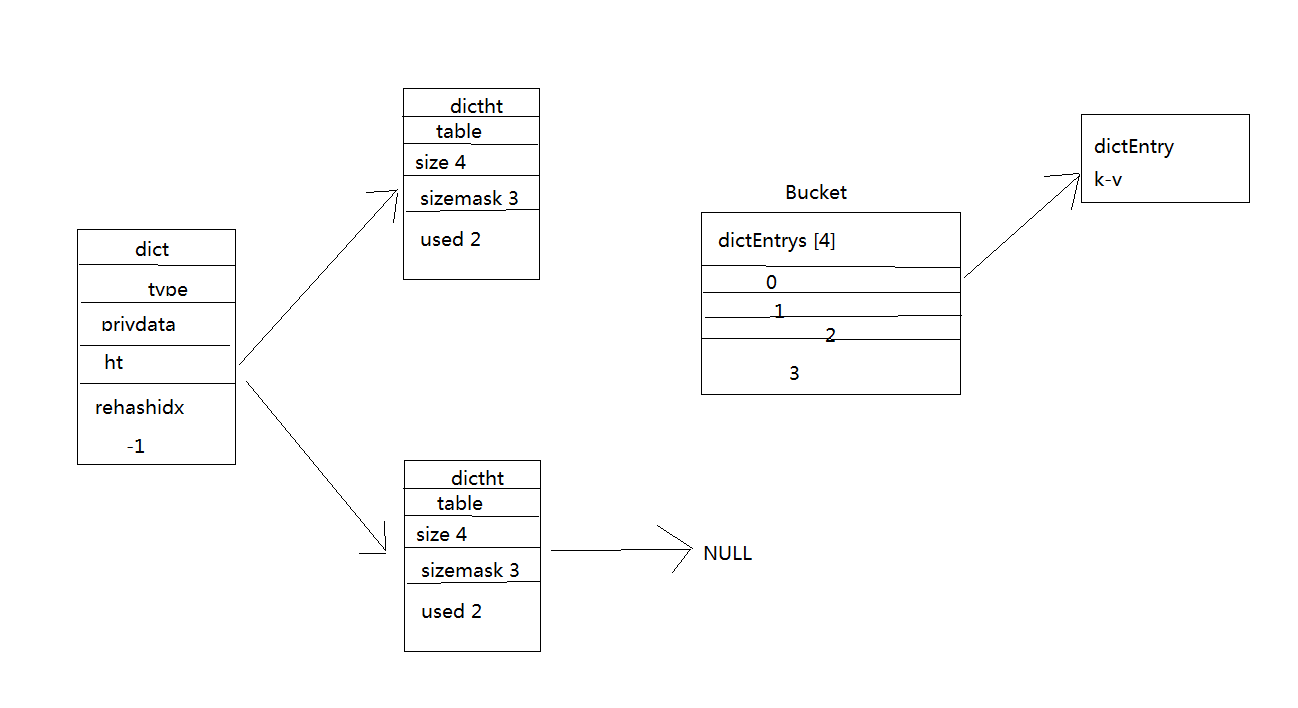
The question is, why are there two dictht? Just one?
Dictht is an array containing two items, and each item points to a dictht structure, which is why Redis hash has one dict and two dictht structures. Usually, all data is stored in ht[0] of dict, and ht[1] is only used in rehash. During rehash operation of dict, rehash all data in ht[0] to ht[1]. Then assign ht[1] to ht[0] and empty ht[1]
3. Metadata of namenode of Hadoop
When dealing with the metadata of directory tree nodes, the namenode of hadoop can withstand the pressure of multithreading and high concurrency. How does it do that? It is also A double buffer mechanism. When the A cache block is full, it is switched to the B cache block, and the A cache block is dropped at the same time
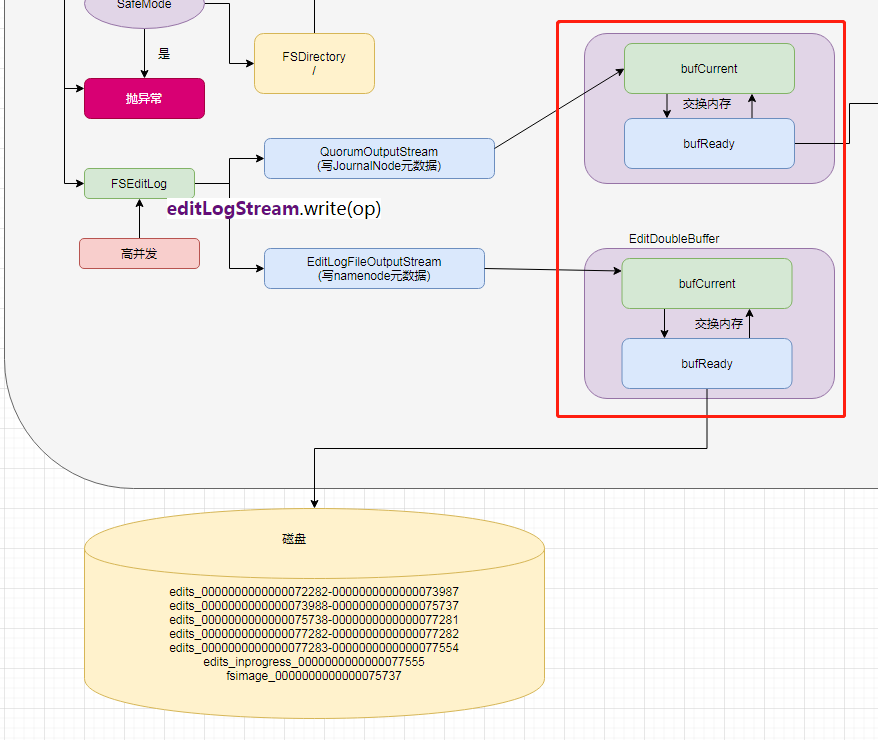
Double buffer java disk dropping Code:
package hadoop;
import java.util.LinkedList;
public class FSEditLog {
//Building metadata information class -- editlog
public class Editlog{
public long txid ; //Transaction id
public String log ; //Metadata information
public Editlog(long txid, String log) {
this.txid = txid;
this.log = log;
}
@Override
public String toString() {
return "Editlog{" +
"txid=" + txid +
", log='" + log + '\'' +
'}';
}
}
public class DoubleBuf{
LinkedList<Editlog> bufCurrent = new LinkedList<>();
LinkedList<Editlog> bufReady = new LinkedList<>();
//Write metadata information to the first memory
public void write(Editlog editlog){
bufCurrent.add(editlog);
}
//Brush metadata operation
public void flush(){
for(Editlog editlog:bufReady){
System.out.println("The metadata of current disk brushing is:"+editlog.toString());
}
bufReady.clear();
}
//Swap memory
public void swap(){
//bufCurrrent ---> bufReady
LinkedList<Editlog> tmp = bufReady ;
bufReady = bufCurrent ;
bufCurrent = tmp ;
}
//Get maximum transaction ID
public long getMaxtxid(){
return bufReady.getLast().txid ;
}
}
private long txid = 0;
DoubleBuf doubleBuf = new DoubleBuf();
ThreadLocal<Long> threadLocal = new ThreadLocal<Long>();
public void writeEditlog(String log){
synchronized (this){//Lock start
txid ++ ;
threadLocal.set(txid);
//Create metadata
Editlog editlog = new Editlog(txid , log);
doubleBuf.write(editlog);
}//End of lock
logFlush();
}
public boolean isSyncRunning = false ; //Are you brushing the disc
long maxTxid = 0 ;//Maximum transaction id currently running
//If ThreadLocal get() >= maxTxid
//This indicates that this is a new task, but the current task is running and needs to wait, otherwise thread insecurity will occur
boolean isWait = false;//Wait
//Brush disk operation
public void logFlush(){
synchronized (this){//Lock start
if(isSyncRunning){
if(threadLocal.get() < maxTxid){//In order to ensure the order, it must be the largest transaction id
//It indicates that the work of the current thread has been completed by other threads
return;
}
if(isWait){
return ;
}
isWait = true ;
while (isSyncRunning){//Thread 1 is brushing the disk. Thread 2 is coming and needs to wait
try {
this.wait(1000);//If a thread comes in and finds that it is in synchronization, wait for 1s
} catch (InterruptedException e) {
e.printStackTrace();
}
}
isWait = false ;//If the above disc brushing is over, there is no need to wait, so change the state
}
//If the disk is not being swiped at this time, swap the memory
doubleBuf.swap();
// maxTxid = doubleBuf.getMaxtxid() ;
if(doubleBuf.bufReady.size()>0){
maxTxid = doubleBuf.getMaxtxid() ;
}
//After exchanging memory, you have the conditions to brush the disk
isSyncRunning = true ;
}//End of lock
doubleBuf.flush();//By this point, the data in bufrady has been brushed
synchronized (this){
isSyncRunning = false ;//This indicates that thread 1 has finished brushing the disk
this.notifyAll();
}
}
public static void main(String[] args) {
final FSEditLog fsEditlog = new FSEditLog();
boolean isFlag = true ;
long taxid = 0 ;
while (isFlag){
taxid ++ ;
if(taxid == 500){
isFlag = false;
}
new Thread(new Runnable() {
boolean isFlag_2 = true ;
long a = 0 ;
public void run() {
while (isFlag_2){
a ++ ;
if(a == 100){
isFlag_2 = false ;
}
//
fsEditlog.writeEditlog("metadata");
}
}
}).start();
}
}
}