Redis application problem solving
Cache penetration
Problem description
The data corresponding to the key does not exist in the data source. Every time a request for this key cannot be obtained from the cache, the request will be pressed to the data source, which may crush the data source. For example, using a nonexistent user id to obtain user information, no matter in the cache or the database, if hackers use this vulnerability to attack, it may crush the database.
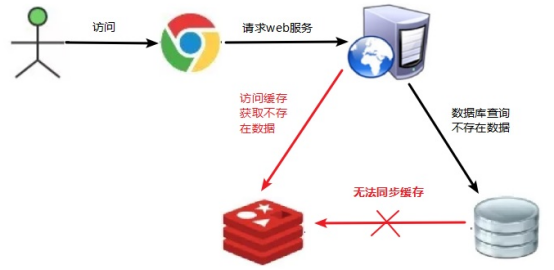

The server accesses redis first. There is no data in redis, and then accesses the database. Because there is no data in the database, it always accesses and always accesses, which creates pressure. Caused the system to crash.
Solution
There must be no cache and data that cannot be queried. Because the cache is written passively when it misses, and for the sake of fault tolerance, if the data cannot be found from the storage layer, it will not be written to the cache, which will cause the nonexistent data to be queried in the storage layer every request, losing the significance of the cache.
Solution:
(1) * * cache null values: * * if the data returned by a query is null (whether the data does not exist or not), we still cache the null result. Set the expiration time of the null result to be very short, no more than five minutes
(2) Set accessible list (white list):
Use the bitmaps type to define an accessible list. The list id is used as the offset of bitmaps. Each access is compared with the id in bitmaps. If the access id is not in bitmaps, it is intercepted and access is not allowed.
(3) Adopt Bloom Filter: (Bloom Filter was proposed by bloom in 1970. It is actually a very long binary vector (bitmap) and a series of random mapping functions (hash function).
Bloom filters can be used to retrieve whether an element is in a collection. Its advantage is that the space efficiency and query time are far more than the general algorithm, but its disadvantage is that it has a certain false recognition rate and deletion difficulty.)
Hash all possible data into a large enough bitmap, and a certain non-existent data will be intercepted by the bitmap, so as to avoid the query pressure on the underlying storage system.
(4) * * real time monitoring: * * when Redis's hit rate starts to decrease rapidly, it is necessary to check the access objects and data, and cooperate with the operation and maintenance personnel to set the blacklist restriction service
Buffer breakdown
Problem description
The data corresponding to the key exists, but it expires in redis. At this time, if a large number of concurrent requests come, if these requests find that the cache expires, they will generally load data from the back-end dB and set it back to the cache. At this time, large concurrent requests may crush the back-end DB instantly.
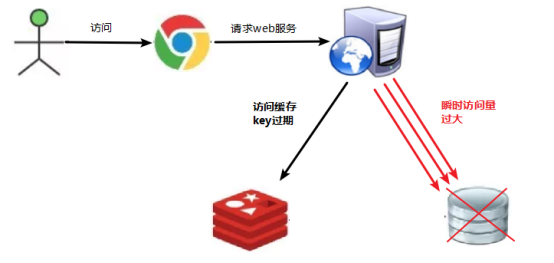
- Database access pressure increases instantaneously
- There are not many expired key s in redis
- redis is running normally
This is because a key in redis has expired and is used for a large number of accesses
Resolve access
key may be accessed at some point in time with high concurrency, which is a very "hot" data. At this time, we need to consider a problem: the cache is "broken down".
solve the problem:
**(1) Preset popular data: * * store some popular data in redis in advance before the peak visit of redis, and increase the duration of these popular data key s
**(2) Real time adjustment: * * monitor which data is popular on site and adjust the expiration time of key in real time
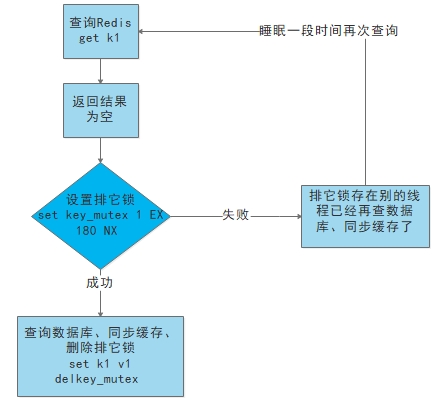
(3) Use lock:
(1) When the cache fails (it is judged that the value is empty), it is not to load db immediately.
(2) First, set a mutex key by using some operations of the caching tool with the return value of successful operations (such as SETNX of Redis)
(3) When the operation returns success, then perform the operation of load db, reset the cache, and finally delete the mutex key;
(4) When the operation returns failure, it is proved that there is a thread in load db. The current thread sleeps for a period of time and then retries the whole get cache method.
Cache avalanche
Problem description
The data corresponding to the key exists, but it expires in redis. At this time, if a large number of concurrent requests come, if these requests find that the cache expires, they will generally load data from the back-end dB and set it back to the cache. At this time, large concurrent requests may crush the back-end DB instantly.
The difference between cache avalanche and cache breakdown is that there are many key caches here, and the former is a key
Normal access
Cache failure instant (a large number of Keys expire at the same time)
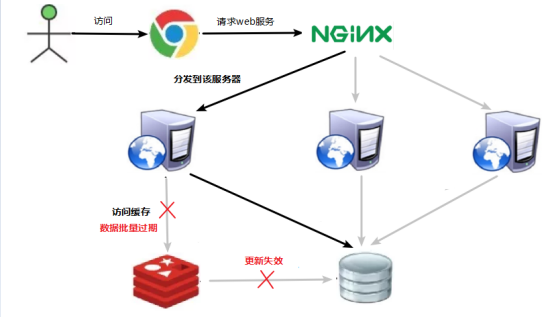
Solution
The avalanche effect of cache failure has a terrible impact on the underlying system!
Solution:
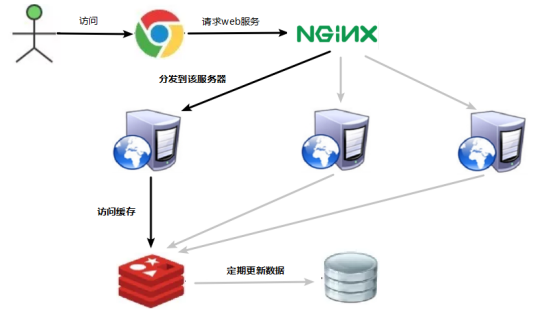
(1) * * build multi-level cache architecture: * * nginx cache + redis cache + other caches (ehcache, etc.)
(2) Use lock or queue * *:**
Lock or queue is used to ensure that a large number of threads will not read and write to the database at one time, so as to avoid a large number of concurrent requests falling on the underlying storage system in case of failure. Not applicable to high concurrency
(3) Set expiration flag to update cache:
Record whether the cached data has expired (set the advance amount). If it has expired, it will trigger another thread to update the cache of the actual key in the background.
(4) Spread cache expiration time:
For example, we can add a random value based on the original failure time, such as 1-5 minutes random, so that the repetition rate of the expiration time of each cache will be reduced, and it is difficult to cause collective failure events.
Distributed lock
Problem description
With the needs of business development, after the system deployed by the original single machine is evolved into a distributed cluster system, because the distributed system is multi-threaded, multi process and distributed on different machines, this will invalidate the concurrency control lock strategy under the original single machine deployment. The simple Java API can not provide the ability of distributed lock. In order to solve this problem, we need a cross JVM mutual exclusion mechanism to control the access of shared resources, which is the problem to be solved by distributed locking!
Mainstream implementation scheme of distributed lock:
-
Implementation of distributed lock based on Database
-
Cache based (Redis, etc.)
-
Based on Zookeeper
Each distributed lock solution has its own advantages and disadvantages:
-
Performance: redis is the highest
-
Reliability: zookeeper highest
Here, we will implement distributed locks based on redis.
Solution: use redis to implement distributed locks
redis: Command
# set sku:1:info "OK" NX PX 10000
EX second: set the expiration time of the key to second seconds. The effect of SET key value EX second is equivalent to that of set key second value.
PX millisecond: set the expiration time of the key to millisecond. SET key value PX millisecond effect is equivalent to PSETEX key millisecond value.
Nx: set the key only when the key does not exist. SET key value NX has the same effect as SETNX key value.
20: Set the key only when it already exists.

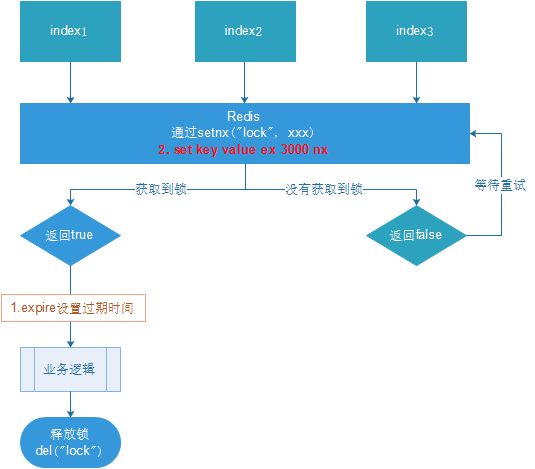
-
Multiple clients acquire locks at the same time (setnx)
-
After successful acquisition, execute the business logic {obtain data from db, put it into the cache}, and release the lock (del) after execution
-
Other clients waiting to retry
Test:
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-BgJRyXVt-1624165470379)(F: \ record \ PicGo\Java Web\image-20210509144134507.png)]

192.168.31.249:6381> expire users 10 #Set expiration time (integer) 1 192.168.31.249:6381> ttl users #View time (integer) 2
Or:
192.168.31.249:6381> set users 10 nx ex 8 OK 192.168.31.249:6381> ttl users (integer) 5 192.168.31.249:6381> ttl users (integer) 1 192.168.31.249:6381> ttl users (integer) -2
nx indicates the expiration time of the lock ex setting
Write code
@GetMapping("testLock")
public void testLock() {
//1 get lock, setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111");
//2. Obtain the lock successfully and query the value of num
if (lock) {
Object value = redisTemplate.opsForValue().get("num");
//2.1 judge whether num is empty return
if (StringUtils.isEmpty(value)) {
return;
}
//2.2 convert value to int
int num = Integer.parseInt(value + "");
//2.3 add 1 to the num of redis
redisTemplate.opsForValue().set("num", ++num);
//2.4 release lock, del
redisTemplate.delete("lock");
} else {
//3. Failed to obtain the lock. Obtain it again every 0.1 seconds
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Restart the service cluster and pass the gateway stress test:
ab -n 5000 -c 100 http://192.168.xx.xx:8080/test/testLock (followed by access address)
View the value of num in redis:

Basic implementation.
Problem: setnx just got the lock, and the business logic was abnormal, so the lock could not be released
Solution: set the expiration time and automatically release the lock.
Optimized setting of lock expiration time
There are two ways to set the expiration time:
- First think about setting the expiration time through expire (lack of atomicity: if an exception occurs between setnx and expire, the lock cannot be released)
- Specify expiration time when set (recommended)
Set expiration time:
@GetMapping("testLock")
public void testLock() {
//1 get lock, setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "111", 2, TimeUnit.SECONDS);
//2. Obtain the lock successfully and query the value of num
if (lock) {
Object value = redisTemplate.opsForValue().get("num");
//2.1 judge whether num is empty return
if (StringUtils.isEmpty(value)) {
return;
}
//2.2 convert value to int
int num = Integer.parseInt(value + "");
//2.3 add 1 to the num of redis
redisTemplate.opsForValue().set("num", ++num);
//2.4 release lock, del
redisTemplate.delete("lock");
} else {
//3. Failed to obtain the lock. Obtain it again every 0.1 seconds
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
There must be no problem with the stress test. Self test
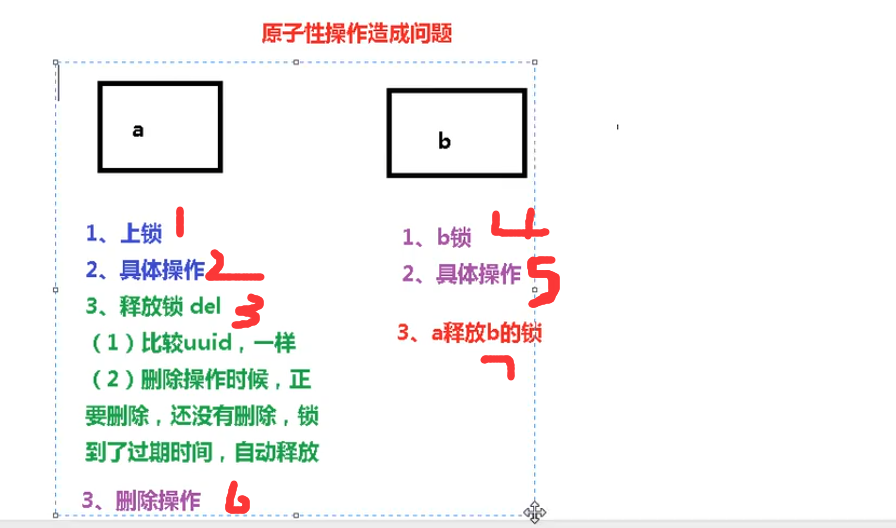
Problem: locks on other servers may be released.
Scenario: if the execution time of business logic is 7s. The execution process is as follows
-
The index1 business logic is not executed, and the lock is automatically released after 3 seconds.
-
index2 obtains the lock and executes the business logic. After 3 seconds, the lock is automatically released.
-
index3 obtains the lock and executes the business logic
-
After the execution of index1 business logic is completed, it starts to call del to release the lock. At this time, the lock of index3 is released, resulting in that index3 business is released by others after only 1s of execution.
In the end, it is equal to the case of no lock.

Solution: when setnx obtains a lock, set a specified unique value (for example: uuid); Obtain this value before releasing to determine whether you own the lock
Optimized UUID anti deletion

@GetMapping("testLock")
public void testLock() {
String uuid = UUID.randomUUID().toString();
//1 get lock, setne
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 2, TimeUnit.SECONDS);
//2. Obtain the lock successfully and query the value of num
if (lock) {
Object value = redisTemplate.opsForValue().get("num");
//2.1 judge whether num is empty return
if (StringUtils.isEmpty(value)) {
return;
}
//2.2 convert value to int
int num = Integer.parseInt(value + "");
//2.3 add 1 to the num of redis
this.redisTemplate.opsForValue().set("num", String.valueOf(++num));
//2.4 release lock, del
if (uuid.equals((String) redisTemplate.opsForValue().get("lock"))) {
redisTemplate.delete("lock");
}
} else {
//3. Failed to obtain the lock. Obtain it again every 0.1 seconds
try {
Thread.sleep(100);
testLock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}

Problem: deletion operation lacks atomicity.
Scenario:
- When index1 performs deletion, the lock value queried is indeed equal to uuid
uuid=v1
set(lock,uuid);

- Before index1 is deleted, the lock has just expired and is automatically released by redis
In redis, there is no lock, no lock.
- index2 got lock
The index2 thread obtains the cpu resources and starts to execute the method
uuid=v2
set(lock,uuid);
- index1 is deleted, and the lock of index2 will be deleted
index1 does not need to be locked again because it is already in the method. index1 has permission to execute. index1 has been compared. At this time, start to execute
Delete the lock of index2!
The optimized LUA script ensures the atomicity of deletion
@GetMapping("testLockLua")
public void testLockLua() {
//1 declare a uuid and put it as a value into the value corresponding to our key
String uuid = UUID.randomUUID().toString();
//2 define a lock: lua script can use the same lock to delete!
String skuId = "25"; // Access item 100008348542 with skuId 25
String locKey = "lock:" + skuId; // Locked is the data of each commodity
// 3 acquire lock
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// The first one: no code is written between lock and expiration time.
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);// Set expiration time
// If true
if (lock) {
// Start of executed business logic
// Get num data in cache
Object value = redisTemplate.opsForValue().get("num");
// If it is empty, return directly
if (StringUtils.isEmpty(value)) {
return;
}
// Not empty, if there is an exception here! Then delete fails! In other words, the lock will always exist!
int num = Integer.parseInt(value + "");
// Put num + 1 into cache each time
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*Use lua script to lock*/
// Define lua script
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// Using redis to execute lua
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// Set the return value type to Long
// Because when deleting the judgment, the returned 0 is encapsulated as a data type. If it is not encapsulated, the String type is returned by default,
// Then there will be an error between the returned string and 0.
redisScript.setResultType(Long.class);
// The first is a script, the second is the key to be judged, and the third is the value corresponding to the key.
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// Other threads waiting
try {
// sleep
Thread.sleep(1000);
// After waking up, call the method.
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Lua script details:
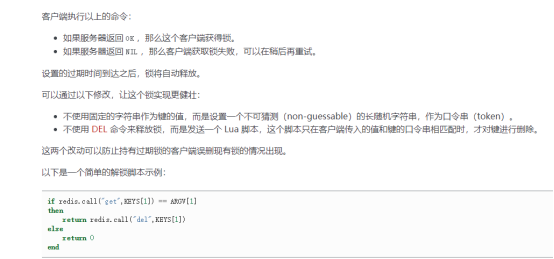
Correct use in the project:
1.definition key,key It should be for everyone sku Defined, that is, each sku There is a lock. String locKey ="lock:"+skuId; // Locked is the data of each commodity Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid,3,TimeUnit.SECONDS);
summary
1. Lock
// 1. Obtain the lock from redis, set k1 v1 px 20000 nx
String uuid = UUID.randomUUID().toString();
Boolean lock = this.redisTemplate.opsForValue()
.setIfAbsent("lock", uuid, 2, TimeUnit.SECONDS);
2. Using lua to release the lock
// 2. Release the lock del
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// Set the data type returned by lua script
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
// Set lua script return type to Long
redisScript.setResultType(Long.class);
redisScript.setScriptText(script);
redisTemplate.execute(redisScript, Arrays.asList("lock"),uuid);
3. Try again
Thread.sleep(500); testLock();
In order to ensure the availability of distributed locks, we should at least ensure that the implementation of locks meets the following four conditions at the same time:
-Mutex. At any time, only one client can hold the lock.
-There will be no deadlock. Even if one client crashes while holding the lock without actively unlocking, it can ensure that other subsequent clients can lock.
-Whoever unties the bell must tie it. Locking and unlocking must be the same client. The client cannot unlock the lock added by others.
-Locking and unlocking must be atomic.
Redis6.0 new features
ACL
brief introduction
Redis ACL is the abbreviation of Access Control List. This function allows to restrict some connections according to the executable commands and accessible keys.
Before Redis 5, redis security rules only had password control and adjusted high-risk commands through rename, such as flushdb, KEYS *, shutdown, etc. Redis 6 provides the function of ACL to control the user's permissions in a finer granularity:
(1) Access rights: user name and password
(2) Executable commands
(3) Operable KEY
Refer to the official website: https://redis.io/topics/acl
command
1. Use the acl list command to display the user permission list
(1) Data description

2. Using the acl cat command
(1) View and add permission instruction categories
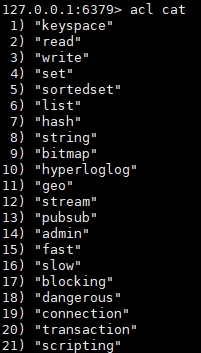
(2) Add the parameter type name to view the specific commands under the type

3. Use the acl whoami command to view the current user

4. Use the aclsetuser command to create and edit user ACL S
(1) ACL rules
The following is a list of valid ACL rules. Some rules are just a single word used to activate or delete flags, or to make a given change to a user's ACL. Other rules are character prefixes, which are linked to command or category names, key patterns, and so on.
| ACL rules | ||
|---|---|---|
| type | parameter | explain |
| Start and disable users | on | Activate a user account |
| off | Disable a user account. Note that the verified connection still works. If the default user is marked off, the new connection starts without authentication and requires the user to send AUTH or HELLO using the AUTH option to authenticate in some way. | |
| Adding and deleting permissions | + | Adds an instruction to the list of instructions that the user can invoke |
| - | Removes an instruction from the user executable instruction list | |
| +@ | Add all instructions to be called by users in this category. The valid categories are @ admin, @ set, @ sortedset... Etc. view the complete list by calling ACL CAT command. The special category @ all represents all commands, including those currently existing in the server and those that will be loaded through the module in the future. | |
| -@ | Removes a category from a user callable instruction | |
| allcommands | +@Alias for all | |
| nocommand | -@Alias for all | |
| Addition or deletion of operable keys | Add a mode that can be used as a user operable key. For example, ~ * allows all keys |
(2) Create default permissions for new users through commands
acl setuser user1
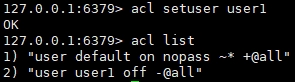
In the above example, I didn't specify any rules at all. If the user does not exist, this will use the default attribute of just created to create the user. If the user already exists, the above command will not perform any operation.
(3) Users with user name, password, ACL permission and enabled
acl setuser user2 on >password ~cached:* +get
acl setuser las on >123456 ~cached:* +get OK 192.168.31.249:6391> acl list 1) "user default on nopass ~* &* +@all" 2) "user las on #8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92 ~cached:* &* -@all +get" 3) "user ljy off &* -@all"
(4) Switch users and verify permissions
auth username password / blank

IO multithreading
brief introduction
Redis6 finally supports multithreading. Have you said goodbye to single threading?
IO multithreading actually refers to the multithreading of the network IO interactive processing module of the client interaction part, rather than the multithreading of executing commands. Redis6 still executes commands in a single thread.
Principle architecture
Redis 6 adds multithreading, but it is different from Memcached, which implements multithreading from IO processing to data access. The multithreaded part of redis is only used to handle the reading and writing of network data and protocol parsing, and the execution of commands is still single thread. The reason for this design is that it doesn't want to be complicated by multithreading. It needs to control the concurrency of key, lua, transaction, LPUSH/LPOP and so on. The overall design is as follows:

In addition, multithreaded IO is not enabled by default and needs to be configured in the configuration file
vim /etc/redis.conf
io-threads-do-reads yes
io-threads 4
Cluster tool support
Previously, the old version of redis needs to install ruby environment separately to build a cluster. Redis 5 will redis trib The functions of Rb are integrated into redis cli. In addition, the official redis benchmark tool began to support the cluster mode, and pressure test multiple slices through multithreading.
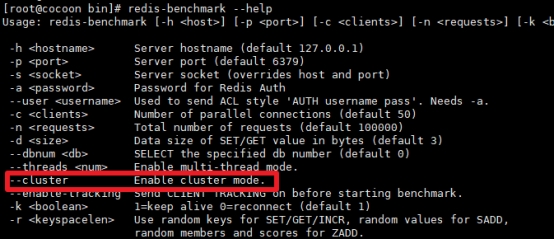
Redis continues to pay attention to new functions
Redis6's new features include:
1. RESP3 new Redis communication protocol: optimize the communication between server and client
2. Client side caching: client side caching based on RESP3 protocol. In order to further improve the performance of the cache, the data frequently accessed by the client is cached to the client. Reduce TCP network interaction.
3. Proxy cluster proxy mode: the proxy function enables the cluster to have the same access mode as a single instance, reducing the threshold for everyone to use the cluster. However, it should be noted that the agent does not change the functional restrictions of the cluster, and unsupported commands will not be supported, such as multi Key operations across slot s.
4,Modules API
The development of module API in Redis 6 has made great progress, because Redis Labs used redis module from the beginning in order to develop complex functions. Redis can become a framework that uses Modules to build different systems without having to write from scratch and then require BSD license. Redis was an open platform for writing various systems from the beginning.