🧡 Fast dialog generation based on PaddleHUB -- Taking crosstalk support generator as an example
Link from AI Studio project https://aistudio.baidu.com/aistudio/projectdetail/3502884
stay Generate military training impressions using PaddleHub In the project, the generation of style text is realized based on PaddleHub, which is based on paddle2 Style text generation in version 0 +. (error again due to version upgrade)
📖 0. Project background
project Valentine's Day reverse operation: a love word, a hate, what? Spring Festival couplets AI is played into gossip? This paper introduces the case of natural language processing generative task, but lacks the detailed introduction and demonstration of training using their own data. In addition, due to the version upgrade, similar projects and basic failure, the latest PaddleHUB sample project is necessary.
This project completes the task of text dialogue generation based on paddlehub, and introduces how to use your own data set to complete the task of matching text generation. It can help you quickly use paddlehub to realize your ideas.
The effects of the project are as follows:
Funny input: eat a candy cake and stick your teeth
- For details about the API and parameter interpretation of the algorithm, see the project: Valentine's Day reverse operation: a love word, a hate, what? Spring Festival couplets AI is played into gossip?
reference material:
- https://zhuanlan.zhihu.com/p/42568781
- https://aistudio.baidu.com/aistudio/projectdetail/2341543
📖 1.PaddleHub introduction
Through API, we can get the pre training model of PaddlePaddle ecosystem conveniently, and complete the management and one key prediction of the model. With the use of fine tune API, the migration learning can be quickly completed based on the large-scale pre training model, so that the pre training model can better serve the application of users' specific scenes.
-
Based on excellent community ecology and continuous investment, paddlepaddle has a number of models that can be directly invoked to quickly realize ideas.
-
These models are stored in different suites according to different directions, such as paddelnlp based on NLP, paddegan based on GAN, etc
If you encounter key point detection, segmentation, target recognition and other tasks, you might as well take a look first PaddleHub model library
⏲️ 1.1 installation instructions
-
PaddlePaddle installation
This project relies on PaddlePaddle 2.2 and above. Please refer to Installation guide Install
-
PaddleNLP installation
pip install --upgrade paddlenlp -i https://pypi.org/simple
-
Environmental dependence
Python version requires 3.7+
# paddlenlp upgrade required !pip install --upgrade pip --user !pip install --upgrade paddlenlp -i https://pypi.org/simple
# Decompress data set !unzip -o work/data_crosstalk.zip -d /home/aistudio/work/
📖 2. Data set introduction
Multiple collected crosstalk texts come from the network and are stored as TXT after processing. For details, see Crosstalk dataset

Dataset production:
(1). The matching data set is constructed with comma as input and bang as output.
(2). Modify the return value of yield in the read function. It is required that the return value is a dictionary containing first and second. The value of first is the input and the value of second is the corresponding output.
(3). The value of first/second is the data after word segmentation, which is connected at an interval of '\ x02', data_path is the parameter of input read.
In this project, multiple txt files are synthesized into a train Txt, and then use jieba word segmentation for processing.
- Examples of generated data: {'first': 'especially this time \ x02 this \ x02 disease \ x02 is very serious \ x02,\x02 all \ x02 broken \ x02 phase \ x02', 'second': 'why \ x02 broken phase \ x02?'}
# Data set processing
import glob
path_ ='work/data_crosstalk/*.txt'
txt_list_ = glob.glob(path_)
with open("work/train.txt","w+") as save_f:
for txt_ in txt_list_:
f = open(txt_, encoding='gbk')
lines = f.readlines()
for i in range(len(lines)-1):
if 'Funny:' in lines[i] and 'Hold:' in lines[i+1]:
# Input and output
text = lines[i].replace('\n','')[2:] + '\t' + lines[i+1].replace('\n','')[2:] + '\n'
save_f.write(text)
f.close()
from paddlenlp.datasets import load_dataset
import pandas as pd
import jieba
def read(data_path):
data_ori = pd.read_csv(data_path, names=['first','second'], header=None,sep='\t')
temp = {}
for i in range(len(data_ori)):
temp_data_0 = jieba.lcut(data_ori.iloc[i,0]) # 0 is funny
temp_data_1 = jieba.lcut(data_ori.iloc[i,1]) # 1 is holding
yield {'first': '\x02'.join(temp_data_0), 'second': '\x02'.join(temp_data_1)}
# data_path is the parameter of the read() method
train_ds = load_dataset(read, data_path='work/train.txt',lazy=False)
for idx in range(2):
print(train_ds[idx])
print()
{'first': 'thank\x02 to\x02 teacher\x02,\x02 Sick\x02 come\x02 participate in\x02 show\x02.\x02 this\x02 Period of time\x02 you\x02 body\x02 Not good', 'second': 'no\x02 comfortable'}
{'first': 'especially\x02 this time\x02 this\x02 illness\x02 Very heavy\x02,\x02 all\x02 broken\x02 Yes\x02 mutually\x02 Yes', 'second': 'Yes?\x02 Disfigurement\x02 Yes\x02?'}
# View the first five data sets
data_ori = pd.read_csv('work/train.txt', names=['first','second'], header=None,sep='\t')
data_ori.head()
| first | second | |
|---|---|---|
| 0 | Thank teacher Yu for coming to the performance with illness You are not in good health during this period | uncomfortable |
| 1 | Especially this time, the disease is very serious and has broken its appearance | What's wrong? |
| 2 | hemorrhoids | Hemorrhoids disfigured? |
| 3 | Incomplete | Never heard of it |
| 4 | At first glance, it doesn't come out | No, I didn't |
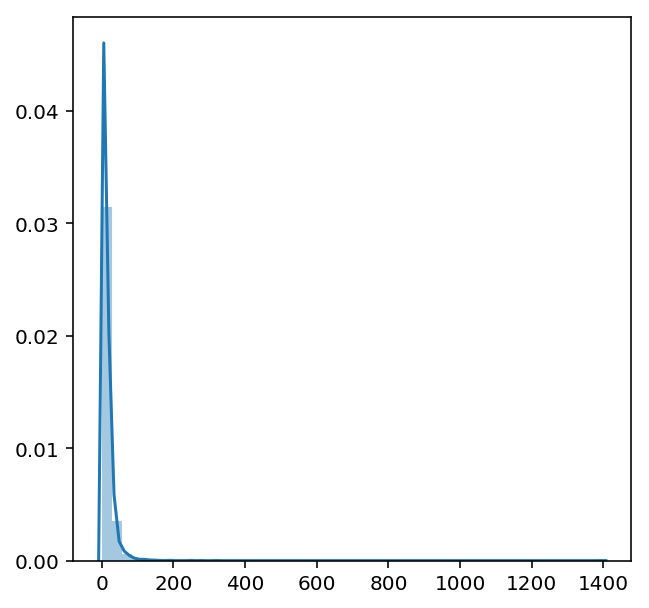
# View the length distribution of data and modify the maximum length entered
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
len_list = []
for i in range(len(data_ori)):
temp_data = data_ori.iloc[i,0] # 0 is funny and 1 is flattering
len_list.append(len(temp_data))
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5))
sns.distplot(len_list)
plt.show()
📖 3. Model implementation and training
import paddlenlp # Set model name MODEL_NAME = 'unimo-text-1.0' tokenizer = paddlenlp.transformers.UNIMOTokenizer.from_pretrained(MODEL_NAME)
[2022-02-20 16:52:01,087] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/unimo-text-1.0/unimo-text-1.0-vocab.txt
from functools import partial
from utils import convert_example
train_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='train')
train_ds.map(train_trans_func, lazy=False, num_workers=4)
<paddlenlp.datasets.dataset.MapDataset at 0x7fb262505690>
idx = 1 # View output print(train_ds[idx]['input_ids']) print(train_ds[idx]['token_type_ids']) print(train_ds[idx]['position_ids']) print(train_ds[idx]['masked_positions']) print(train_ds[idx]['labels']) print()
import paddle
from utils import batchify_fn
batch_size = 32
# Define BatchSampler
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
# Define batchify_fn
train_collate_fn = partial(batchify_fn, pad_val=0, mode='train')
# Construct DataLoader
train_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_collate_fn,
return_list=True)
from paddlenlp.transformers import UNIMOLMHeadModel model = UNIMOLMHeadModel.from_pretrained(MODEL_NAME)
[2022-02-20 19:14:21,134] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/unimo-text-1.0/unimo-text-1.0.pdparams
# Maximum learning rate during training
learning_rate = 1e-4
# Training rounds
epochs = 20
# Learning rate preheating ratio
warmup_proportion = 0.02
# The weight attenuation coefficient is similar to the regular term strategy of the model to avoid over fitting of the model
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
# Learning rate attenuation strategy
lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
from utils import evaluation
import paddle.nn.functional as F
from tqdm import tqdm
for epoch in range(0, epochs):
for batch in tqdm(train_data_loader,desc='epoch:'+str(epoch+1)):
labels = batch[-1]
logits = model(*batch[:-1])
labels = paddle.nn.functional.one_hot(labels, num_classes=logits.shape[-1])
labels = paddle.nn.functional.label_smooth(labels)
loss = F.cross_entropy(logits, labels, soft_label=True)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
ppl = paddle.exp(loss)
print(" epoch: %d, ppl: %.4f, loss: %.5f" % (epoch + 1, ppl, loss))
from utils import post_process_sum
num_return_sequences = 8 #
inputs = 'The first sentence of getting up every day'
inputs_ids = tokenizer.gen_encode(
inputs,
return_tensors=True,
add_start_token_for_decoding=True,
return_position_ids=True)
# Call the generation api and specify the decoding strategy as beam_search
outputs, scores = model.generate(**inputs_ids, decode_strategy='beam_search', num_beams=8,num_return_sequences=num_return_sequences)
print("Result:\n" + 100 * '-')
for i in range(num_return_sequences):
='beam_search', num_beams=8,num_return_sequences=num_return_sequences)
print("Result:\n" + 100 * '-')
for i in range(num_return_sequences):
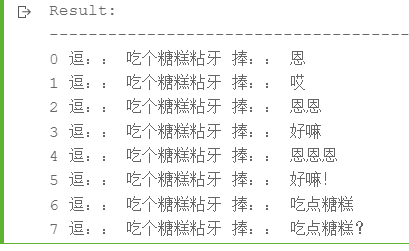
print(i, 'Funny:', inputs, 'Hold:', ''.join(post_process_sum(outputs[i].numpy(), tokenizer)[1]))
Result: ---------------------------------------------------------------------------------------------------- 0 Funny: get up every day, the first sentence is: HMM 1 Tease: get up every day first sentence: hold: first sentence 2 Funny: get up every day the first sentence: ah 3 Funny: get up every day, the first sentence: ah 4 Funny: get up every day the first sentence: ah? 5 Tease: get up every day, the first sentence: hold: the first sentence 6 Funny: get up every day, the first sentence: Oh 7 Funny: get up every day, the first sentence: hold the first sentence
🐱 4 project summary
-
The project mainly explains how to use its own data set to realize the generation task of dialogue text
-
In the training part, the progress bar is used to optimize the display effect, and the output of the training process is carried out according to Epoch
-
If the model parameters need to be adjusted for optimization, it is recommended to study the project Valentine's Day reverse operation: a love word, a hate, what? Spring Festival couplets AI is played into gossip? And official documents.
Special note: if you need to modify the dataset, you can run it with one click after modifying it according to the project description.
If you have any questions, please leave a message in the comment area.