From:
mongoosejs: Populate official documentation
Mongodb: official document of lookup
1, Foreword
The association relationship between data in database design is extremely common: one-to-one, one to many and many to many. As the leader of NoSQL, MongoDB has two common practices: embedded and reference,
Because the Document has a 16MB size limit [1] and "embedded" is not suitable for complex many to many relationships, "reference" is a more widely used association method,
So MongoDB officially calls it "Normalized Data Models" -- standardized data models.
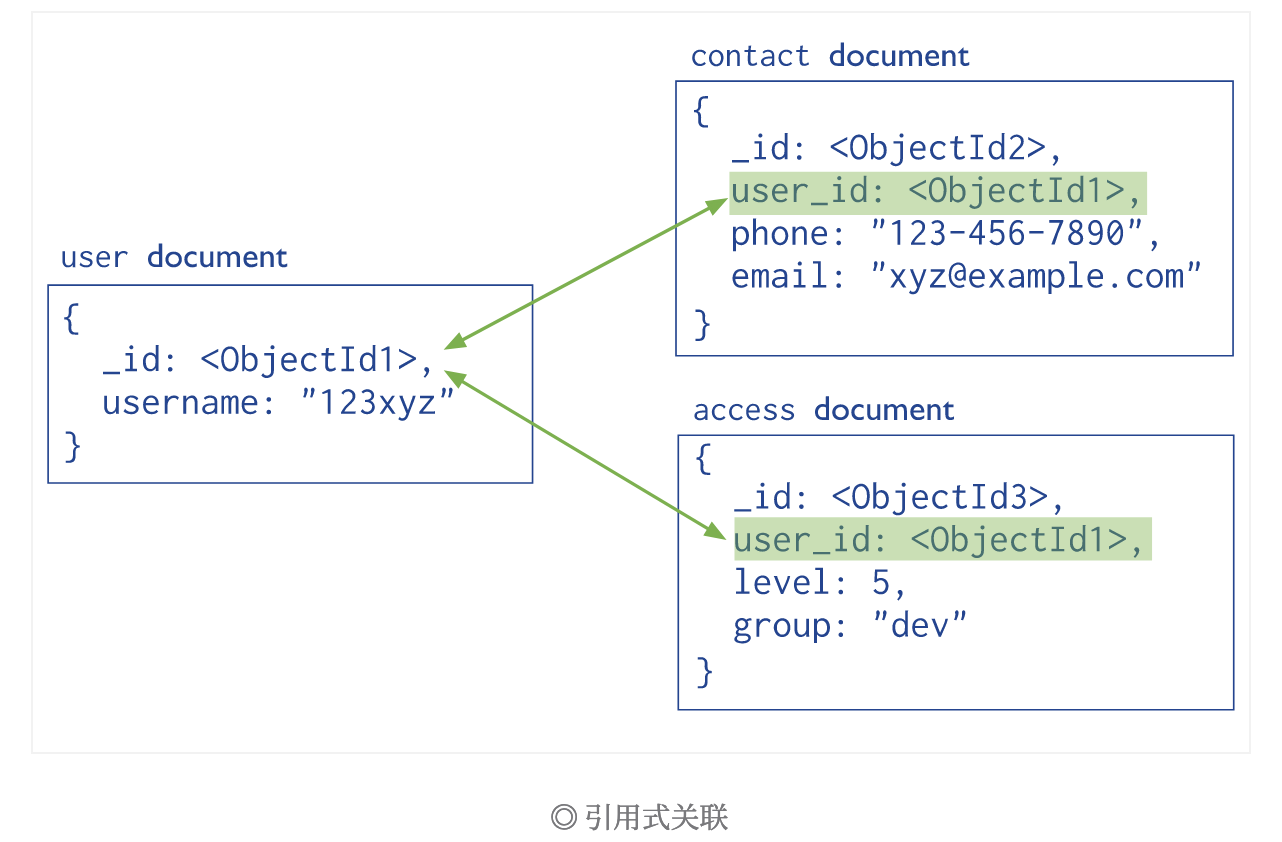
Referential association is actually very simple. It refers to the passage between documents_ id field.
When you need all the information of "123xyz" in the user set, you only need to look up two more tables to get it.
The focus of this article is how to check these two tables - aggregate and populate.
2, Dissect
1,aggregate + lookup
Let's talk about aggregate first. Why should we talk about it first?
Because it is the function provided by MongoDB - the official recommendation of genuine blood 🌚,
And I have to mention that aggregate is also a node i just started to contact JS + mongodb mistakenly uses the core business technology,
It has been used to write many interfaces that are now being refactored with company leaders 🤪…… This issue will be discussed below.
aggregate aggregation is actually a relatively large function module provided by MongoDB,
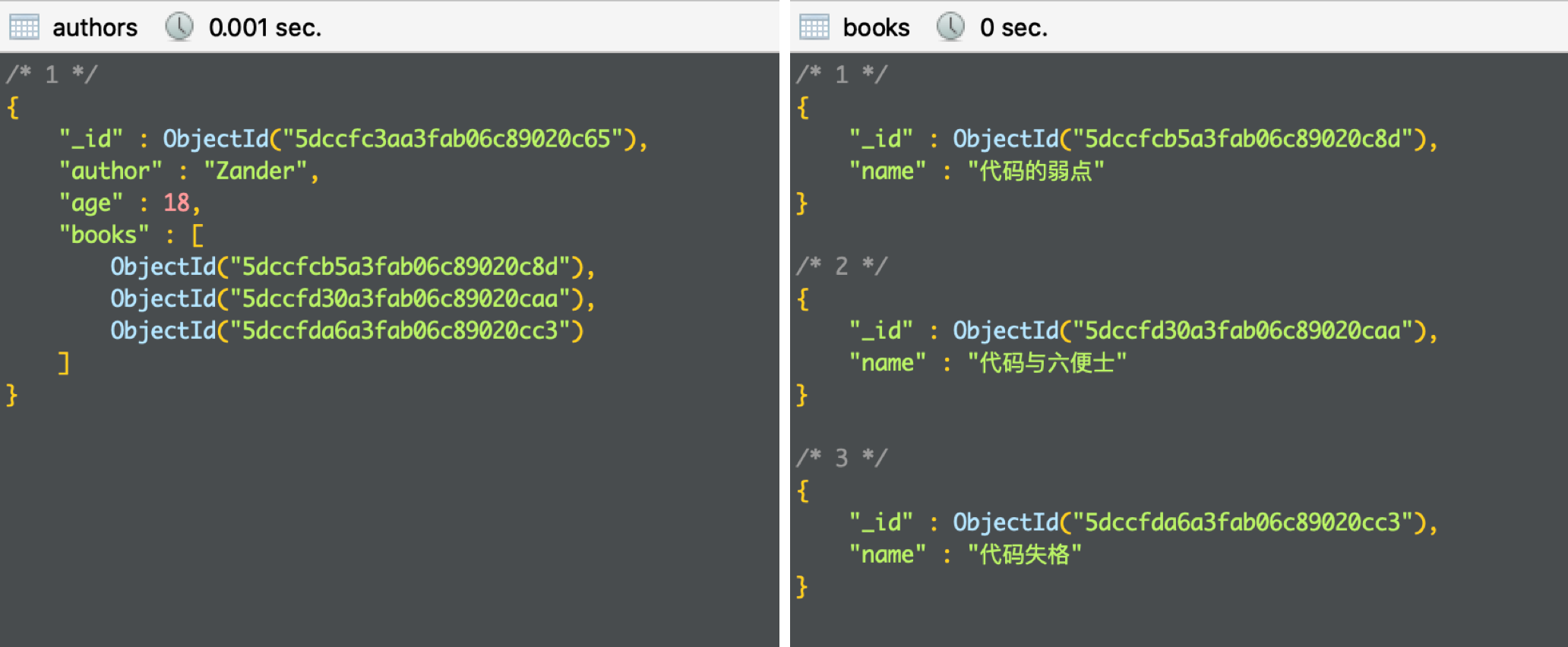
The $lookup is used to associate multiple sets. For example, there is an author set authors and a book set books. The author and the book are "one to many" associations. Reference association is used:
Because the technology stack is node JS + Express + mongoose. The following code example also uses express generator to generate demo directory structure.
Use aggregate to aggregate and query the basic information of author Zander and all his works:
router.get('/getAuthorInfo_a', async (req, res) => {
let result = await Author.aggregate([{ // The Model of the operation is Author
$lookup: {
from: "books", // The name of the associated collection in the database
localField: "books", // Associated fields in the author document
foreignField: "_id", // Associated fields in a book document
as: "bookList" // Returns the field name of the data
}
}, {
$match: { // Screening conditions
"author": "Zander"
}
}]);
res.json({
status: 200,
result: result
})
});
Return data:
{
"status": 200,
"result": [
{
"_id": "5dccfc3aa3fab06c89020c65",
"author": "Zander",
"age": 18,
"bookList": [
{
"_id": "5dccfcb5a3fab06c89020c8d",
"name": "Code weaknesses"
},
{
"_id": "5dccfd30a3fab06c89020caa",
"name": "Code and Sixpence"
},
{
"_id": "5dccfda6a3fab06c89020cc3",
"name": "Code disqualification"
}
]
}
]
}
The use of aggregate is not difficult. Let's look at the implementation of populate without talking about the results.
2,populate + ref
Populate is a method provided in Mongoose, and the populate() of mongoose single dialect is more powerful than the $lookup of MongoDB 🧐. Then pull it out for a walk 🐎
First of all, everything about Mongoose begins with Schema[3]. The key point of using populate also lies in the settings in Schema:
const mongoose = require('mongoose');
const Schema = mongoose.Schema;
const authorSchema = new Schema({
"author": String,
"age": Number,
"books": [{
type: Schema.Types.ObjectId,
ref: 'Book' // Associated Model
}]
});
module.exports = mongoose.model("Author", authorSchema, "authors");
// They are Model name, Schema and collection name in the database
Use populate() in the interface:
router.get('/getAuthorInfo_p', async (req, res) => {
let result = await Author.find({
"author": "Zander"
}).populate("books");
res.json({
status: 200,
result: result
})
})
Return data:
{
"status": 200,
"result": [
{
"books": [
{
"_id": "5dccfcb5a3fab06c89020c8d",
"name": "Code weaknesses"
},
{
"_id": "5dccfd30a3fab06c89020caa",
"name": "Code and Sixpence"
},
{
"_id": "5dccfda6a3fab06c89020cc3",
"name": "Code disqualification"
}
],
"_id": "5dccfc3aa3fab06c89020c65",
"author": "Zander",
"age": 18
}
]
}
3, Contrast
- flexibility
What you can observe now is that the flexibility of aggregate is that you can change the key of the data returned after the associated query (bookList in the returned data), while the key of the data returned by populate can only be the original field name (books in the returned data).
It is worth mentioning that aggregate is better at secondary processing of data in the aggregation pipeline, such as $unwind splitting, $group grouping, etc.
- Functionality
Both can be used for positive correlation, and only lookup can be used for reverse correlation (but I think the positive words are still populate d because the lookup method is more troublesome)
In addition, there is another situation: it is still the above data. If you want to find the author information and author information according to the author name, you only need to do so by using the $lookup of aggregate 😏:
$lookup: {
from: "authors",
localField: "_id",
foreignField: "books",
as: "author"
}
However, populate: "I'm too difficult!"
Yes, it can't do this_ id implements reverse association query. Generally speaking, Mongoose does not allow you to write this:
const bookSchma = new Schema({
"_id": { // You can't write that 🙅♂️
type: Schema.Types.ObjectId,
ref: 'Author'
},
"name": String
});
If you insist on trying, then this is your end 🙃:
{
"status": 200,
"result": [
{
"_id": null,
"name": "Code weaknesses"
}
]
}
populate is the of a collection_ id and non id of another set_ The id field is associated, but after mongoose version 4.5.0, it provides a virtual() method that is very similar to the description of the aggregate function. It will not be described in detail here. Is it not fragrant for me to use aggregate for this requirement? 🤨
- Code simplicity
After knowing their usage methods and applicable scenarios, let's take a look at other aspects, such as why we need to refactor the previously completed aggregate interface 🥶. When I first started my job, I didn't have enough experience. I used someone else's code to draw a scoop. The "scoop" is as follows:
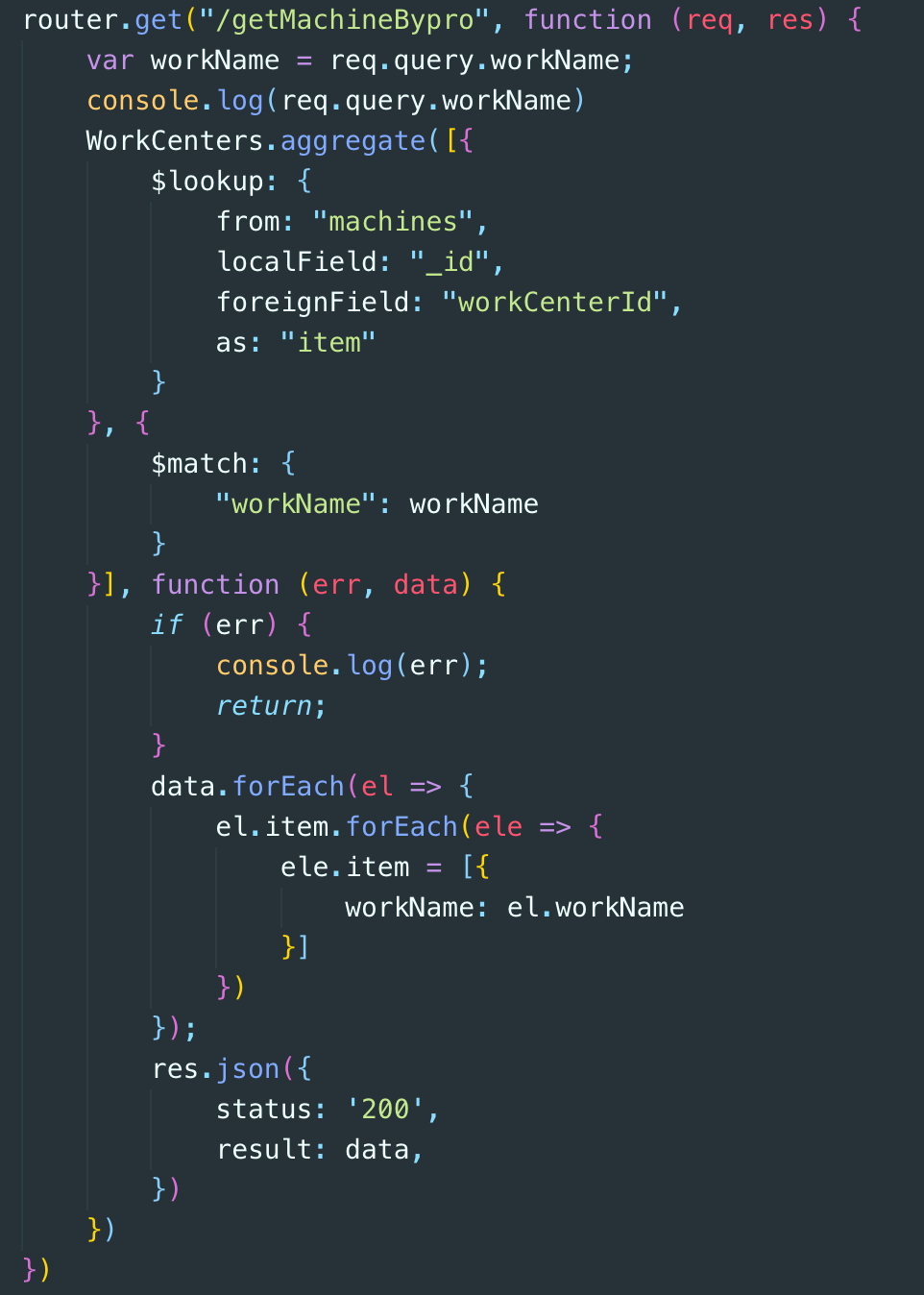
On the one hand, there are a large number of callback functions, and on the other hand, the complex writing of aggregate leads to a large amount of redundancy and poor readability. Now the elegant "gourd" after reconstruction:
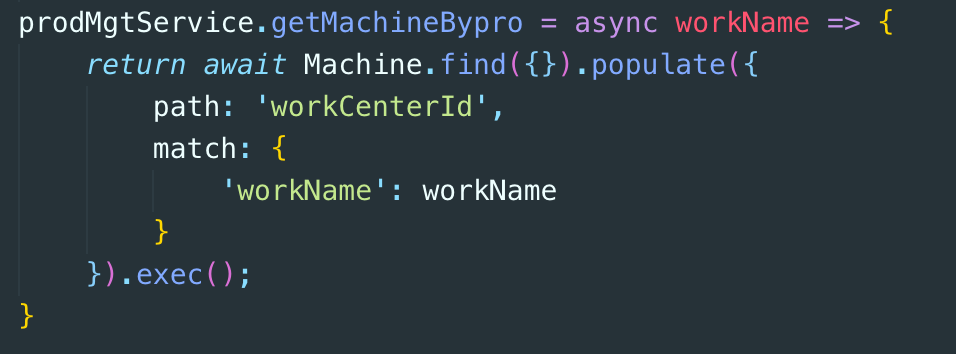
- Performance aspect
After reading the appearance, we can talk about the internal query performance. In fact, populate is the reference method of DBRef[4], which is equivalent to constructing one more layer of query. For example, there are 10 pieces of data. After find() queries the 10 pieces of data in the main collection, it will query the additional 10 pieces of data referenced by populate() and the performance will be greatly reduced. Here, a big man compares the performance of aggregate() and find (), and the conclusion is obvious - aggregate, which is faster than find query, must be better than find + populate of associated query.
4, Summary

On the whole, aggregate is better in multi set association query and secondary processing of query data, while populate is more suitable for simple positive association relationship, and its code style is elegant, readable and easy to maintain. The research in performance is negligible for ordinary applications in daily development.
The use of technology is based on the needs and scenarios. It does not abide by the laws and regulations, does not give up eating because of choking, knows flexibility and selects the best. After all, technology is only a tool, and the purpose is the key.