catalogue
1, AJAX technology introduction
2, Introduction and use of JSON
1. Find in the web page source code
2. Use the Chrome check tool to find valid requests
Get the data on the current page in python 5
6. Get the data of each comment in python
1, AJAX technology introduction
Ajax, Asynchronous JavaScript and XML. AJAX is not a new programming language, but a new way to use existing standards.
The value of AJAX is that web pages can be updated asynchronously by exchanging a small amount of data with the server in the background. This means that a part of a web page can be updated without reloading the entire web page. On the one hand, it reduces the downloading of repeated contents of web pages, on the other hand, it saves traffic, so Ajax has been widely used. For example, the comment data of sina Weibo and the singer information in the singer list of QQ music all use ajax technology. For more information about Ajax, visit W3school.
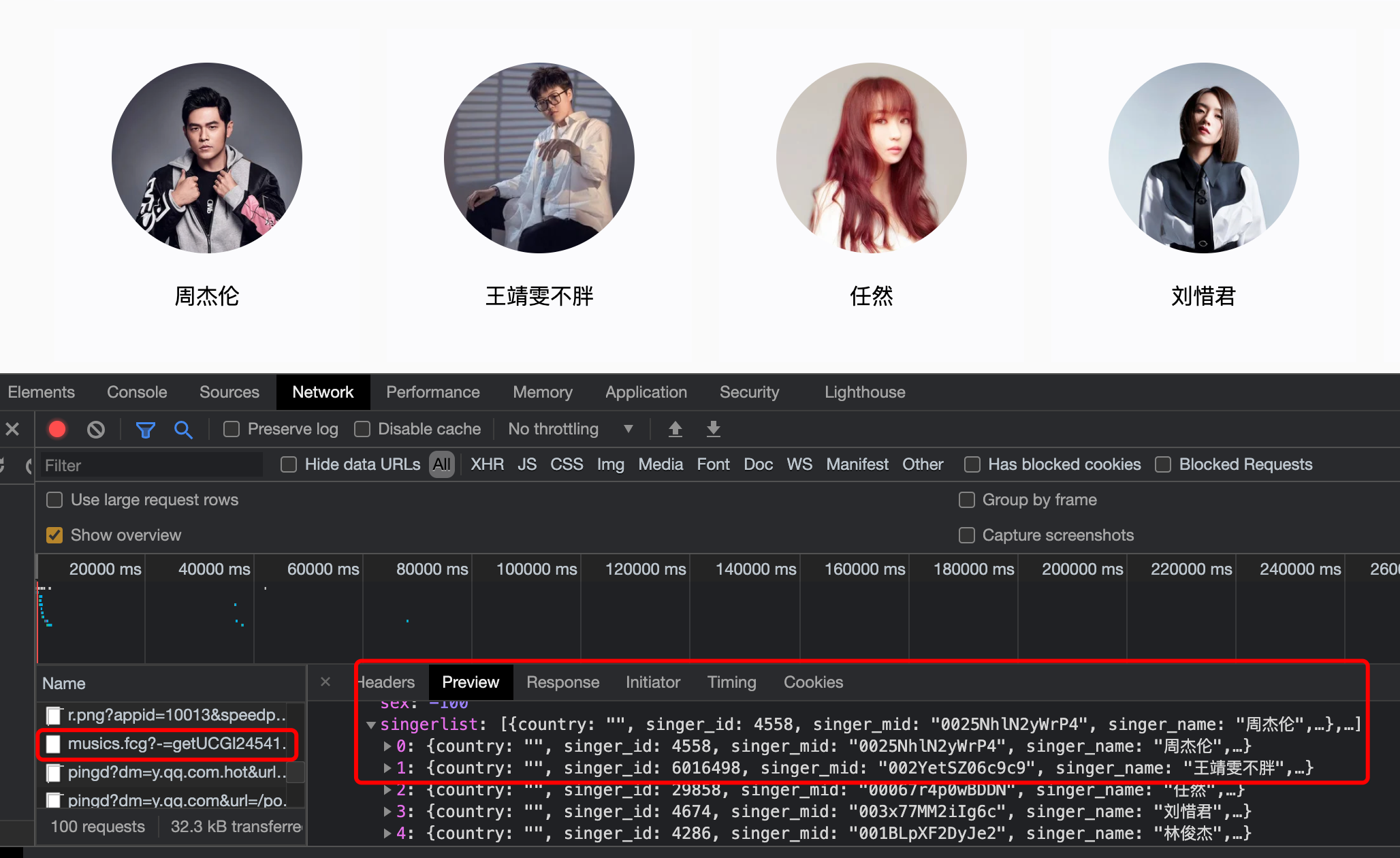 Figure 1: the list of singers in QQ music uses AJAX asynchronous transmission
Figure 1: the list of singers in QQ music uses AJAX asynchronous transmission
If you check the source code of QQ music singer list, you will find that there is no singer information displayed on the web page in the source code. Most of the information on such web pages does not exist in the source code, but asynchronous technology is used.
Asynchronous technology mainly loads txt, json and other text and xml into the web page through JavaScript, or uses asp files to communicate with the database.
2, Introduction and use of JSON
JSON (JavaScript object notation) is a lightweight data exchange format. JSON strings are very similar to Python dictionaries, with only minor differences.
JSON can convert a set of data represented in JavaScript objects into strings, and then easily transfer this string between networks or programs, and restore it to the data format supported by various programming languages when necessary.
1. Convert dictionary to JSON
First, import the JSON module
import json
Use JSON Dumps (dict) to convert the dictionary into JSON
# Dictionaries
data = {
"country": None,
"singer_id": 4558,
"singer_mid": '0025NhlN2yWrP4',
"singer_name": 'Jay Chou',
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M0000025NhlN2yWrP4.webp"
}
# JSON
data_json = json.dumps(data,indent=4) # When the dictionary is converted to JSON, indent can add 4 spaces to the string in JSON format
print(data_json)
print(type(data))
print(type(data_json))
# output
{
"country": null,
"singer_id": 4558,
"singer_mid": "0025NhlN2yWrP4",
"singer_name": "\u5468\u6770\u4f26",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M0000025NhlN2yWrP4.webp"
}
<class 'dict'>
<class 'str'>Differences between dictionary and JSON:
- The key of json can only be a string, and the dict Of python can be any hash able type.
- json keys can be ordered and repeated; The key of dict cannot be repeated.
- The value of json can only be string, floating point number, Boolean value or null, or an array or object composed of them.
- json string enforces double quotation marks, and dict string can be single quotation marks and double quotation marks.
- dict can nest tuple s, and json has only arrays.
- json:true,false,null.
- python: True,False,None.
- json Chinese must be unicode, such as "\ u6211".
- The type of json is string, and the type of dictionary is dictionary.
Not only dictionaries, lists in Python or lists containing dictionaries, but also strings in JSON format.
data = [
{
"country": "",
"singer_id": 4558,
"singer_mid": "0025NhlN2yWrP4",
"singer_name": "Jay Chou",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M0000025NhlN2yWrP4.webp"
},
{
"country": "",
"singer_id": 6016498,
"singer_mid": "002YetSZ06c9c9",
"singer_name": "Wang Jingwen is not fat",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M000002YetSZ06c9c9.webp"
}
]
dict_to_json = json.dumps(data,indent=4)
print(dict_to_json)
# output
[
{
"country": "",
"singer_id": 4558,
"singer_mid": "0025NhlN2yWrP4",
"singer_name": "\u5468\u6770\u4f26",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M0000025NhlN2yWrP4.webp"
},
{
"country": "",
"singer_id": 6016498,
"singer_mid": "002YetSZ06c9c9",
"singer_name": "\u738b\u9756\u96ef\u4e0d\u80d6",
"singer_pic": "http://y.gtimg.cn/music/photo_new/T001R150x150M000002YetSZ06c9c9.webp"
}
]2. Convert JSON to dictionary
json_to_dict = json.loads(dict_to_json)
json_to_dict is a list of nested dictionaries, which can be used like a normal dictionary. For more information about JSON, visit W3school JSON tutorial.
3, Crawling dynamic data
The following is to find the video data of BiliBili website and understand the process of parsing asynchronous data (only for technical exchange and support originality).
Target website: https://www.bilibili.com/v/technology/career/#/ Here is the professional career column of the knowledge section of BiliBili website.
Drag the page down a little, we can see the latest video here, and support the sorting of submission time and video popularity. After we click "video heat ranking", we can immediately see the video that has been played the most in the past seven days.
At this time, we can see that the top video name at present is "how to see a person's strength in 3 seconds? | experience sharing of unscrupulous businessmen wandering the Jianghu for 7 years". Let's remember this title. Maybe you have changed another video during the actual operation. Just remember this title, because now we're going to try to find this information in the data behind the web page. OK, let's start ~
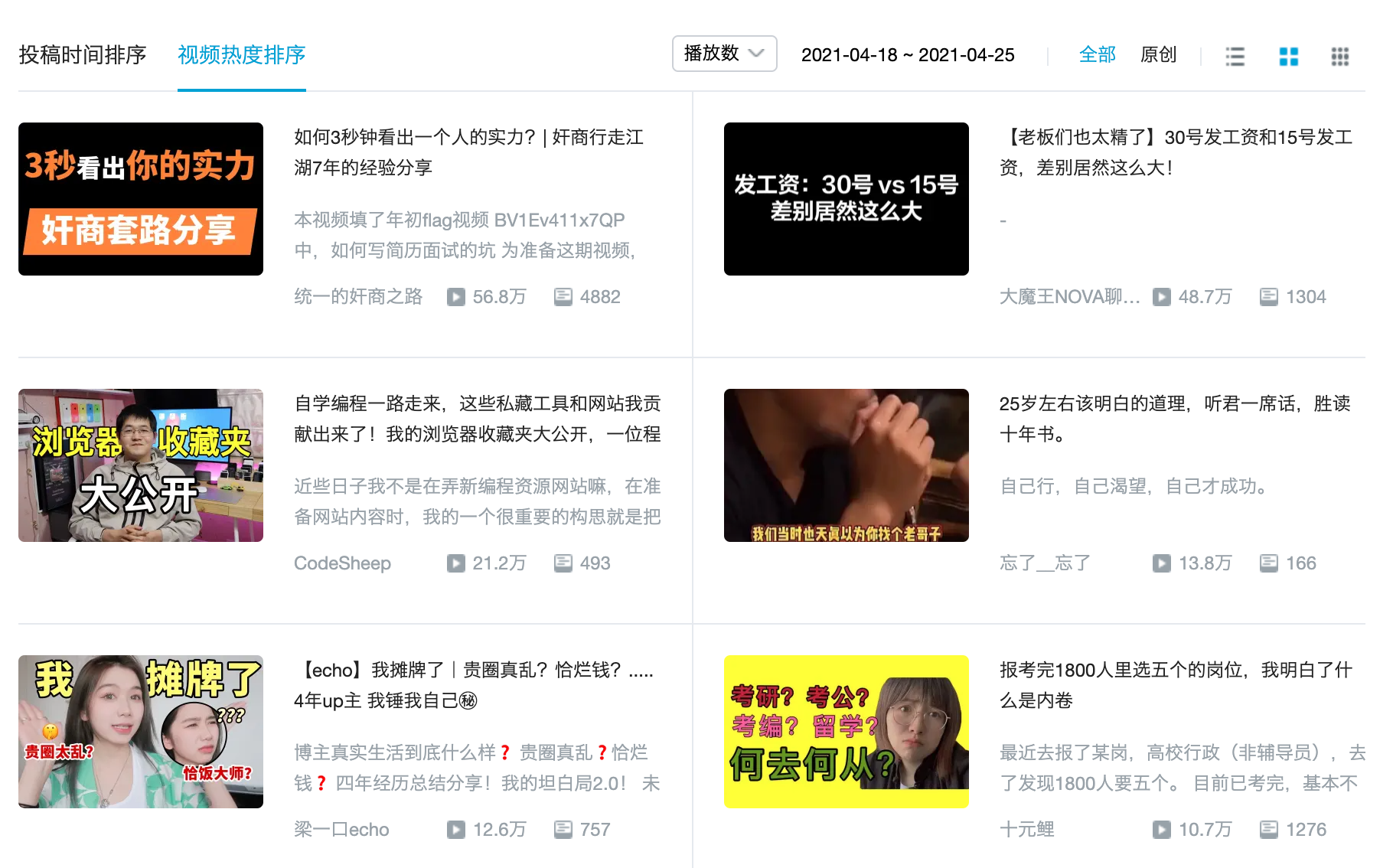 Figure 2 popular videos of BiliBili
Figure 2 popular videos of BiliBili
1. Find in the web page source code
At a glance in the source code of the web page, we know that these video information does not exist in the source code of the web page. We must use asynchronous loading technology to hide it somewhere.
 Figure 3 source code of web page
Figure 3 source code of web page
2. Use the Chrome check tool to find valid requests
Use the Chrome check tool to see what requests the page has.
 Figure 4 open the inspection tool and view the request information in the Network
Figure 4 open the inspection tool and view the request information in the Network
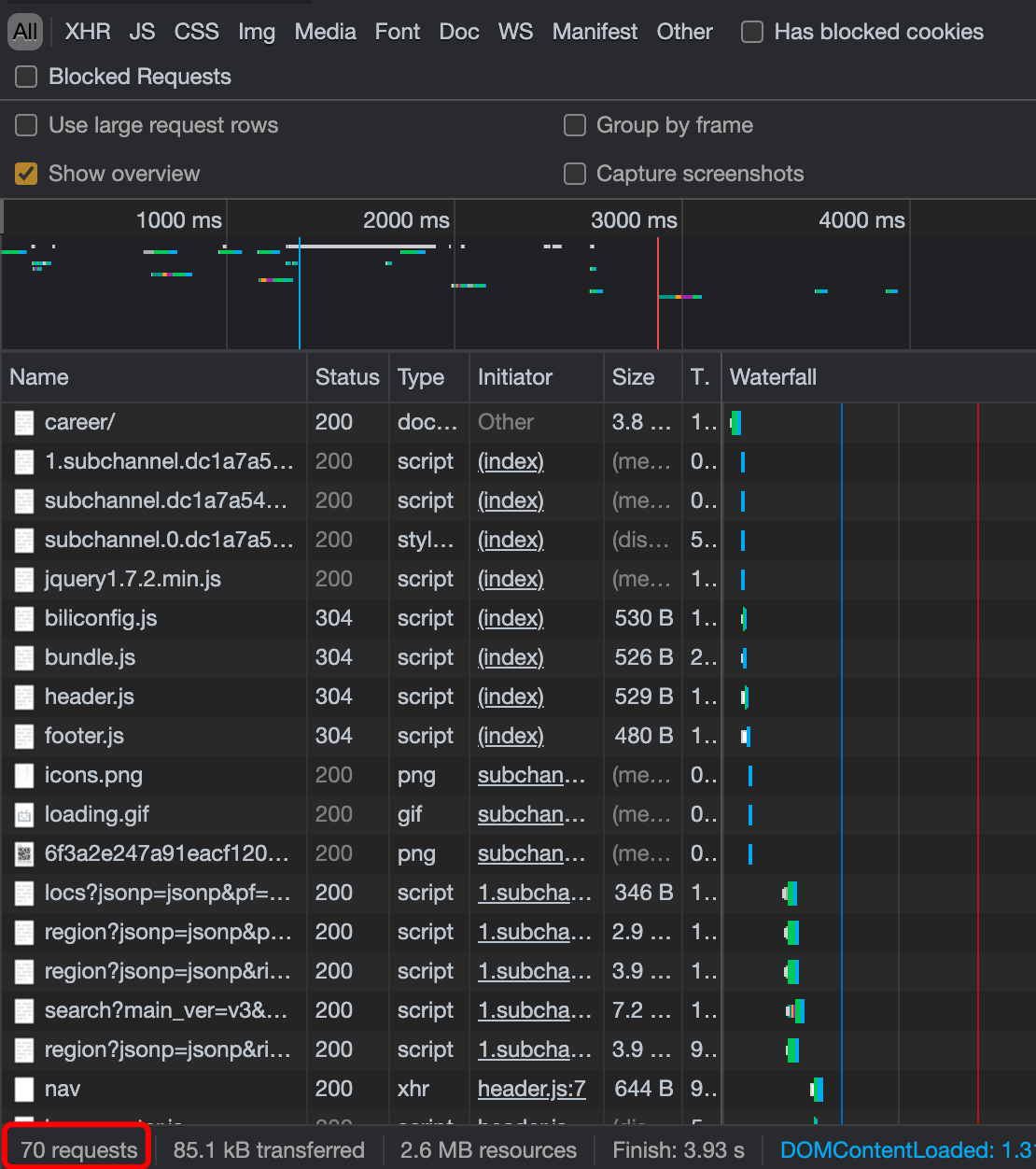 Figure 5 request information after refreshing the page
Figure 5 request information after refreshing the page
After refreshing the page, there are a lot of request information, a total of 70. The data we need is hidden here. But which one? Crawler veterans know that they usually hide in JS or XHR files.
OK, let's select JS type.
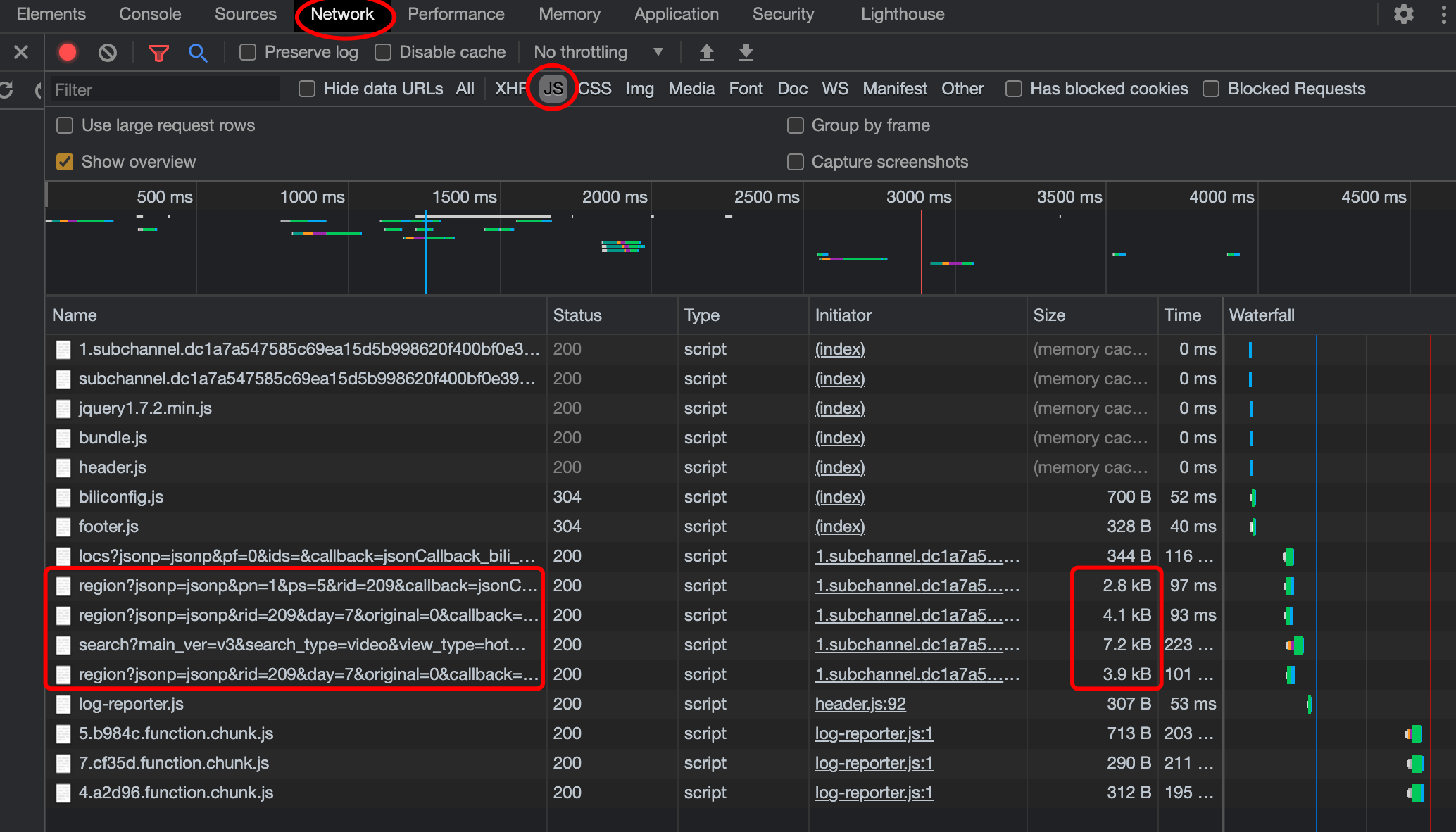 Figure 6 find JS file and narrow the inspection scope
Figure 6 find JS file and narrow the inspection scope
Here, 16 js files are screened out, of which four have a large Size, which is questionable. Let's check them one by one.
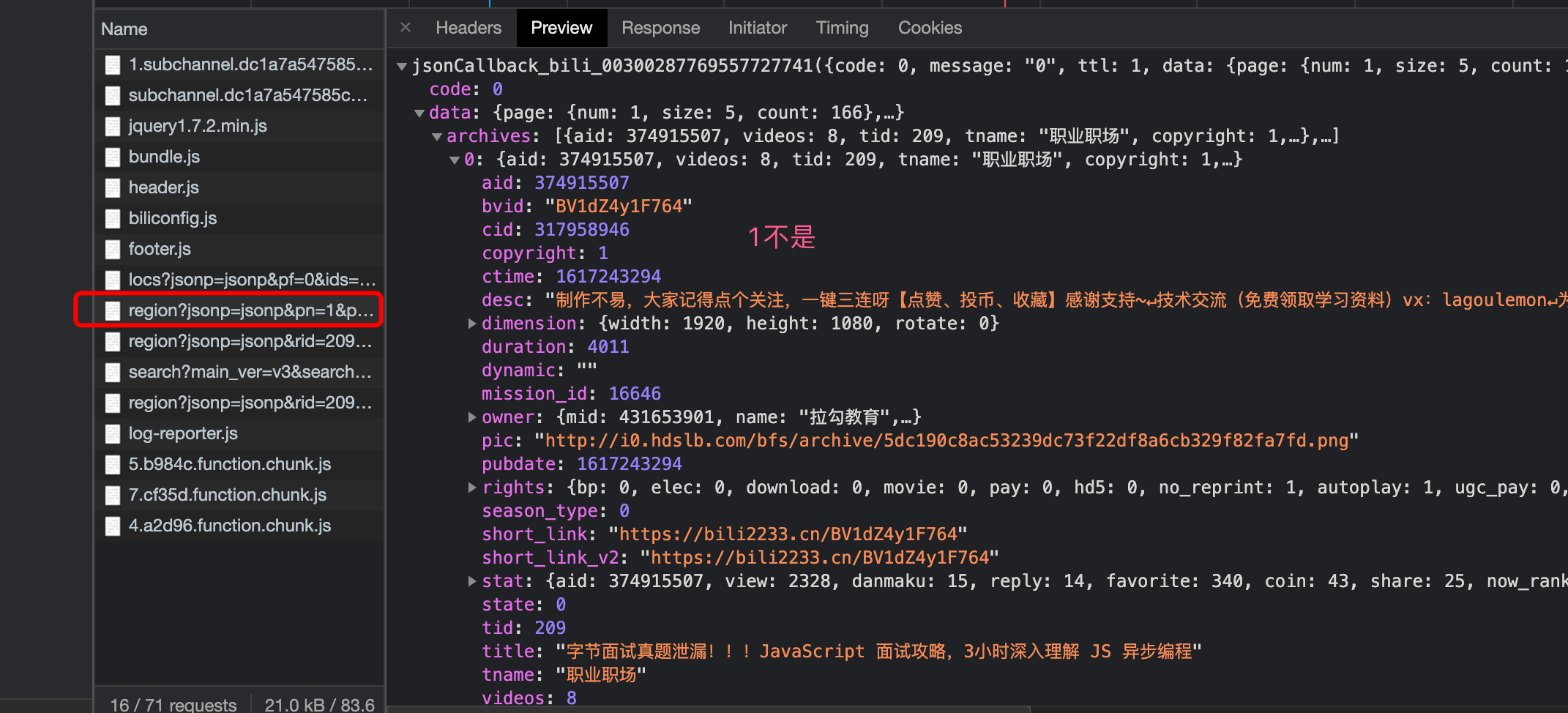 Figure 7. Check possible JS files
Figure 7. Check possible JS files
Do you remember the first title of the video? It doesn't seem to be here, which means this is not what we're looking for. Rule out the first one. We continue to check the second suspicious data.
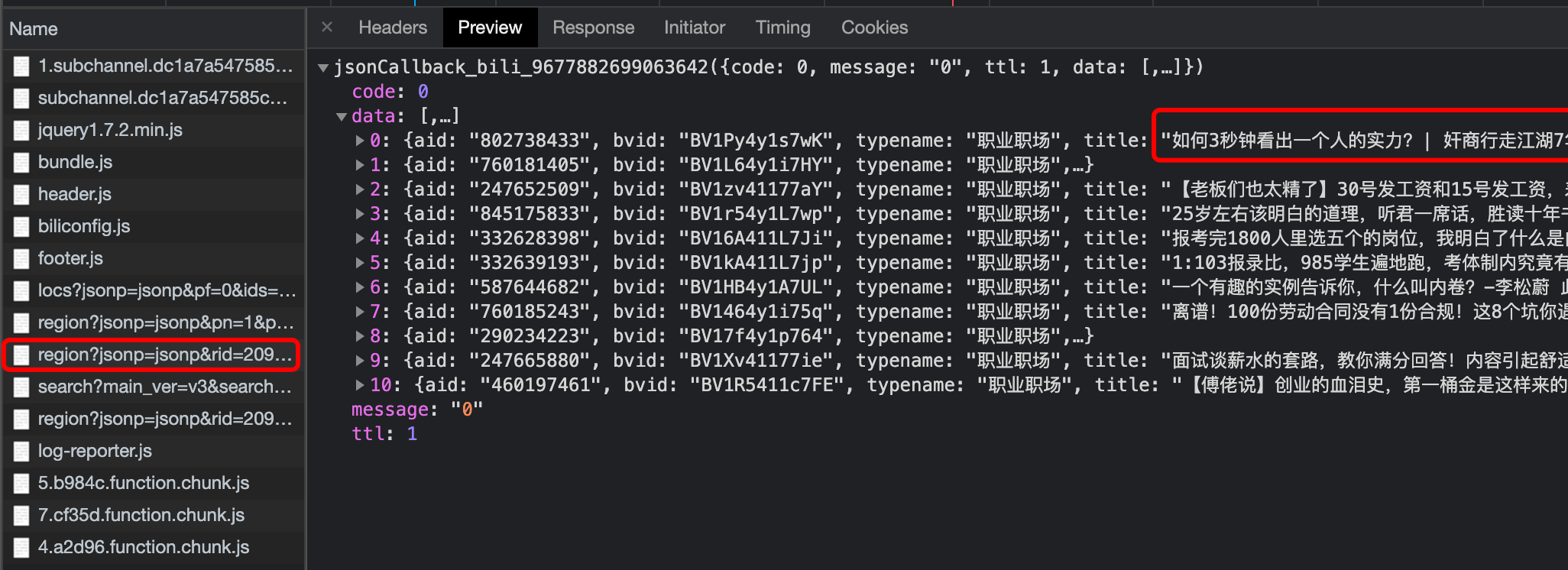 The content in the red box in Figure 8 is consistent with the title of the first video
The content in the red box in Figure 8 is consistent with the title of the first video
Great ~ in this data, the title of the first video we found. But is this the data we need to find?
After checking, we found that there are only 11 pieces of data in this file, but there are actually 20 pieces of data on each page. We are very close to the answer, but we have to continue to look for a little while.
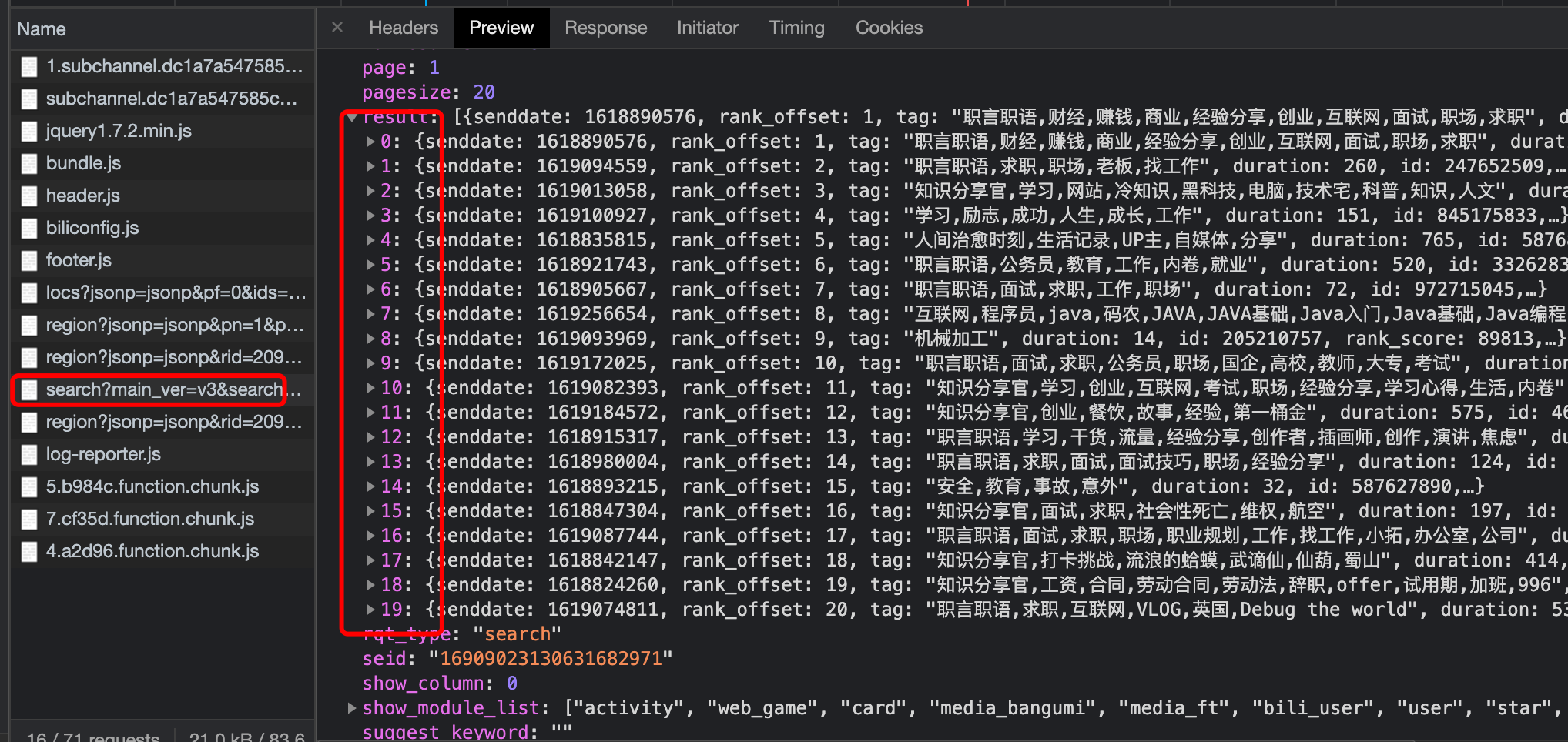 Figure 9 the data quantity and content are consistent with the page information
Figure 9 the data quantity and content are consistent with the page information
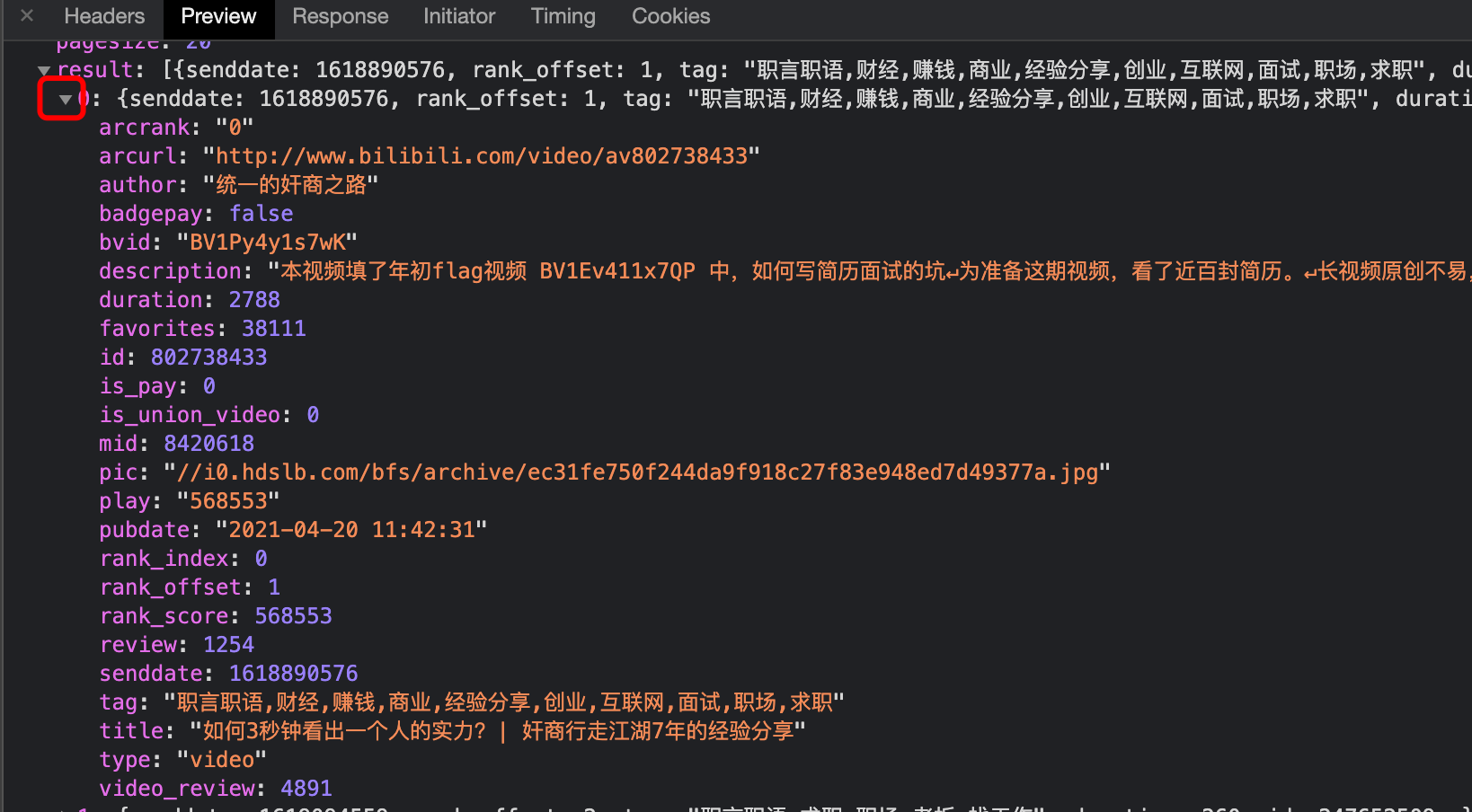 Figure 10 click open triangle to view the trust data
Figure 10 click open triangle to view the trust data
In the third data, both the quantity and content are consistent with the content on the web page. This is the information we are looking for.
[tip] if some websites still find it difficult to find the target data, you can click the button on the next page to see what new requests appear. The data we are looking for must be in these new requests.
3. Find the target link
Switch to the Headers page and copy the url of the request and the value of the user agent
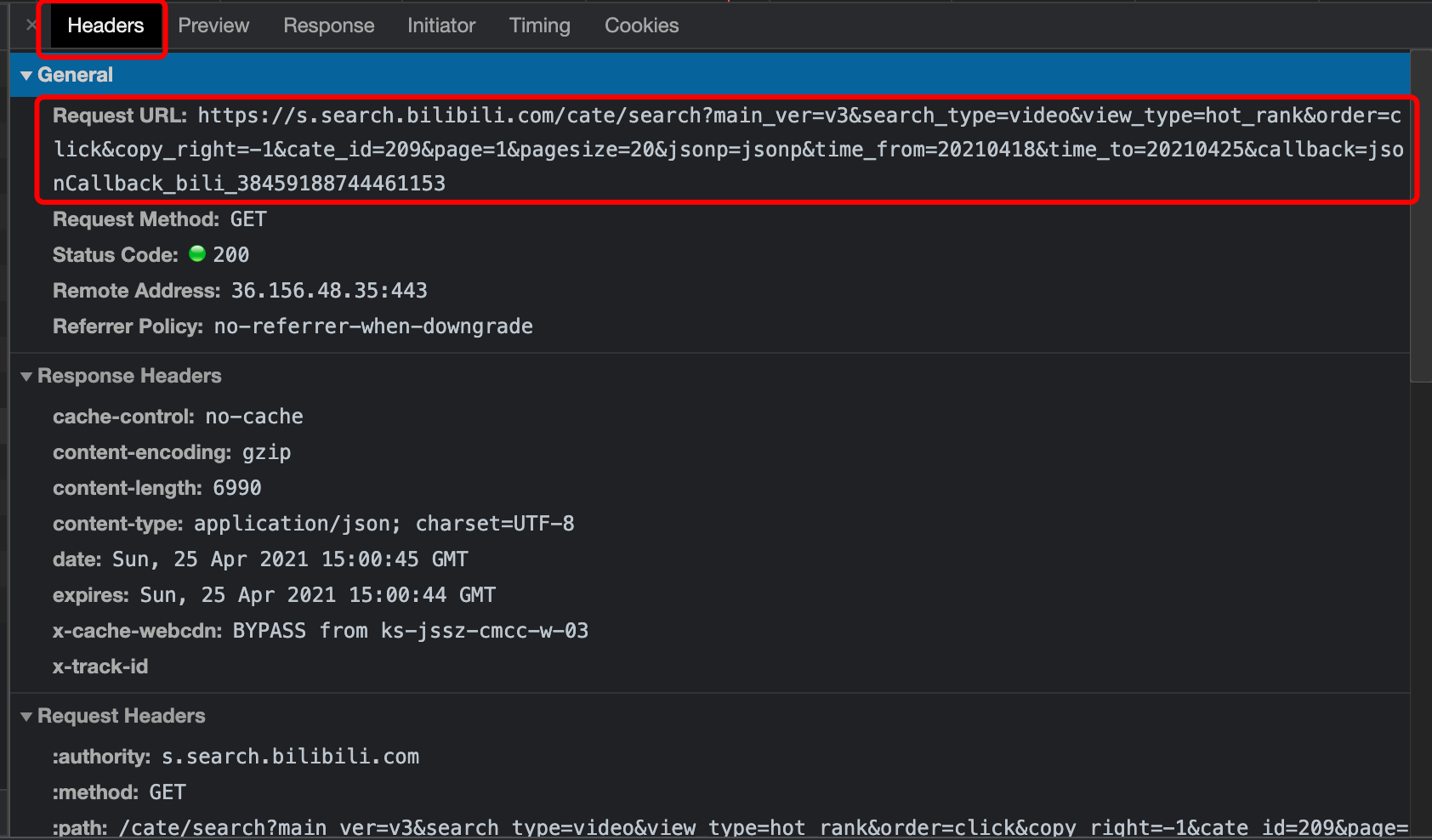 Figure 11 entering the Headers page
Figure 11 entering the Headers page
4. Analyze the url structure
page=1 represents the current page. We can change the value here to grab different pages.
time_ from=20210418&time_ To = 20210425, this is the query time range. We can modify this value if necessary.
Finally, "& callback = jsoncallback_bili_38459188744461153" can be deleted without affecting the capture of data.
Get the data on the current page in python 5
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36'
}
url='https://s.search.bilibili.com/cate/search?main_ver=v3&search_type=video&view_type=hot_rank&order=click©_right=-1&cate_id=209&page=2&pagesize=20&jsonp=jsonp&time_from=20210418&time_to=20210425'
response = requests.get(url,headers=headers)
data = json.loads(response.content) # Convert json to dict
print(data)
# Output (intercepting some data as an example)
{'exp_list': None, 'code': 0, 'cost_time': {'params_check': '0.000225', 'illegal_handler': '0.000003', 'as_response_format': '0.001596', 'as_request': '0.025710', 'deserialize_response': '0.000474', 'as_request_format': '0.000481', 'total': '0.029003', 'main_handler': '0.028654'}, 'show_module_list': ['activity', 'web_game', 'card', 'media_bangumi', 'media_ft', 'bili_user', 'user', 'star', 'video'], 'result': [{'senddate': 1619002527, 'rank_offset': 21, 'tag': 'Knowledge sharing Officer,study,We media,Experience sharing,VLOG,UP main,Photography,dried food,Wildlife Technology Association,Punch in challenge', 'duration': 1199, 'id': 630249948, 'rank_score': 34921, 'badgepay': False, 'pubdate': '2021-04-21 18:55:27', 'author': 'Box court plan', 'review': 180, 'mid': 8542312, 'is_union_video': 0, 'rank_index': 0, 'type': 'video', 'arcrank': '0', 'play': '34921', 'pic': '//i0. hdslb. com/bfs/archive/7210f4290c26007036fb244c306f1cb5fe681365. Jpg ','description': 'many friends have asked me how to join my favorite blogger team. In this video, I interviewed five tool people of millions of bloggers in different partitions to talk to you about their experience. I hope this video can help you know more about the behind the scenes story \ nvideo production: Altria special thanks: Ping Shouhai, a rabbit, guide Yue, near and far, red orange rolling, and the authorization of the bosses behind them ','video_ review': 388, 'is_ pay': 0, 'favorites': 1824, 'arcurl': ' http://www.bilibili.com/video/av630249948 ',' bvid ':' bv1h84y1f7gy ',' title ':' how can I work for my favorite up master? Let's listen to five million bloggers from different regions to share their experience '}, {'senddate': ......, 'show_column': 0, 'rqt_type': 'search', 'numPages': 740, 'numResults': 14782, 'crr_query': '', 'pagesize': 20, 'suggest_keyword': '', 'egg_info': None, 'cache': 0, 'exp_bits': 1, 'exp_str': '', 'seid': '9018545404356211375', 'msg': 'success', 'egg_hit': 0, 'page': 2}
6. Get the data of each comment in python
All comment data is hidden in result, which is a list. Each comment data is stored in the list in the form of a dictionary.
vidinfo_list = [] # Generate an empty list to save the data of all floors
for item in data['result']: # data['result '] get all comment data and read each floor circularly
vidinfo = {} # Generate an empty dictionary to store the data of each floor
vidinfo['title'] = item['title'] # Get the title in each floor
vidinfo['author'] = item['author'] # Get authors on each floor
vidinfo['description'] = item['description'] # Get the video description in each floor
vidinfo['url'] = item['arcurl'] # Get video links on each floor
vidinfo_list.append(vidinfo) # Save information to list
# output
[{'title': 'How can I be a favorite up Main job? Let's listen to 5 million bloggers from different regions to share their experience', 'author': 'Box court plan', 'description': 'Many friends have asked me how to join my favorite blogger team. In this video, I interviewed five tool people of millions of bloggers in different partitions to talk to you about their experience. I hope this video can help you understand more behind the scenes stories\n Video production: Altria Special thanks: Ping Shouhai, a rabbit guide, happy coming and going, red orange rolling and the authorization of the bosses behind them', 'url': 'http://www.bilibili.com/video/av630249948'}, {'title ':' Beiyou graduate student interview Java post, Ali interviewer pays attention to the foundation and asks questions one after another! ',' author ':' childe longlong ',' description ':' the back-end interview video promised to you is coming! ',' URL ':' http://www.bilibili.com/video/av460183222 '}......]
There is also some other useful information in the json file, 'numPages' is the total number of pages. Theoretically, when crawling in batch, we can use it to cycle through the comments of all pages. However, in fact, the anti crawler mechanism of the server will not make it easy for us to achieve our wishes. We need to use some more powerful crawler technologies to break through the restrictions, such as randomly changing request headers, using proxy IP, etc. In the following chapters, we will learn more about these contents.
4, Homework
Climb QQ music leaderboard data. There are different popular music charts under the QQ charts. Each list shows the top 20 song information, which is displayed on the web page using AJAX technology.
For this assignment, we need to complete the following tasks:
1. Find a list you like.
2. Find the correct data source and website through Chrome developer tools.
3. Write a piece of crawler code to crawl out the song_title, rank and singer_name and save them in csv.
4. Documents to be submitted: py file csv file.
5. Obscure technical tips: it doesn't seem difficult to find the target website, but it seems a little long. But the information in the website doesn't seem to be enough. Should we pass some parameters in? We have learned the method of passing, but what parameters should we pass? The editor reports an error, which seems to be due to the wrong style of some parameters in the dictionary. Should it be \ escape. (at present, the videos and articles available on the Internet can't directly solve this task. So you can only rely on yourself. Come on ~ ~!)
 Figure 12 QQ music ranking
Figure 12 QQ music ranking