🐱 Text title generation based on BERT
A good title is based on the ingenious refinement of the article content, which can quickly arouse the interest of readers.
In order to generate news headlines quickly and accurately, this project uses the classic BERT model to automatically complete the generation of news headlines.
- This project refers to Propeller 2.0 application case tutorial - Automatic poetry writing with BERT
📖 0 project background
The purpose of headline news is to make a short sentence to attract readers to read the news. The news articles that users are interested in can usually contain multiple headlines with different keywords. Quickly generating appropriate news headlines can help us media practitioners quickly obtain a large amount of traffic from hot information. In addition, it can also be used to summarize the key information of civil servants in the examination. Therefore, the process automation has a wide application prospect.
🍌 1 data set
lcsts summary data is compiled by Harbin Institute of technology. The data set is created based on the news summary released by news media on microblog. Each short article is about 100 characters and each summary is about 20 characters. A total of 2108915 data

Due to the large amount of data, this project only uses part of the data for training
🍉 2 interpretation of the paper

abstract
BERT (Bidirectional Encoder Representations from Transformers) means Bidirectional Encoder Representations from Transformers. Unlike the recent language representation model, BERT aims to pre train deep two-way representation based on the left and right contexts of all layers. Therefore, the pre trained BERT representation can be fine tuned with only one additional output layer, so as to create the current optimal model for many tasks (such as question answering and language reasoning), without making a lot of modifications to the task specific architecture.
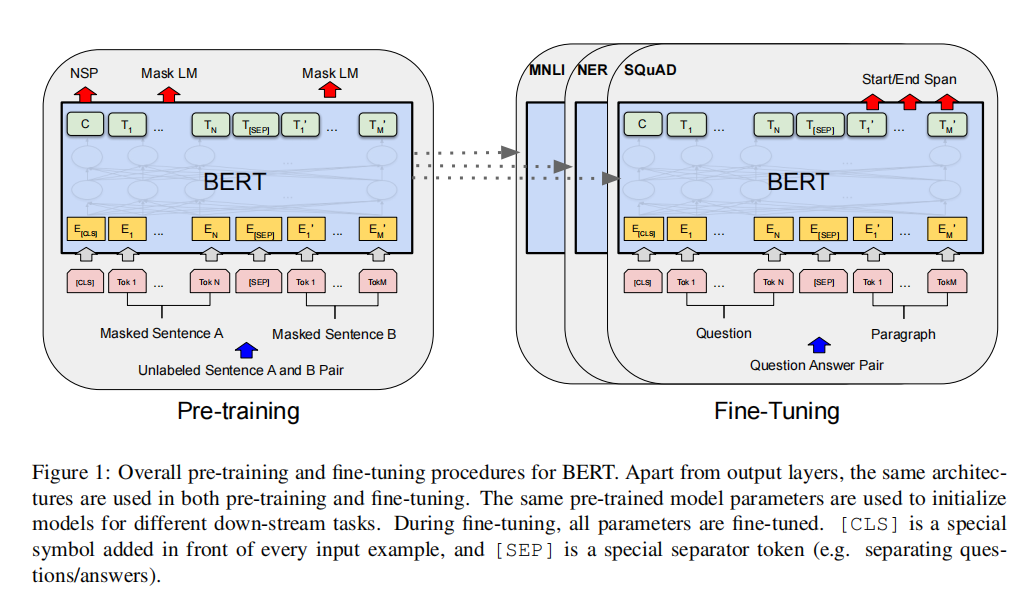
- Bert proposed a new pre training method, which can effectively improve the performance of the pre training model in downstream tasks.
introduce
Language model pre training has been proved to be effective in improving many natural language processing tasks.
There are two existing strategies for applying pre training language representation to downstream tasks: feature-based and fine tuning.
The main limitation of the fine tuning based method is that the standard language model is one-way, which greatly limits the types of architectures that can be used during pre training.
BERT solves the current one-way limitation by proposing a new pre training goal: masked language model (MLM).
The MLM goal allows representation to fuse left and right contexts. In addition to the masking language model, BERT also introduces a "next sentence prediction" task to jointly pre train the representation of text pairs.
The contributions of this paper are as follows:
-
- It proves the importance of two-way pre training to language representation.
-
- It is shown that the amount of pre training representation can eliminate the needs of many heavy engineering task specific architectures.
(BERT is the first representation model based on fine tuning, which achieves the most advanced performance on a large number of sentence level and chunk level tasks)
-
- BERT advanced the highest level of 11 NLP tasks.
Model framework
BERT model architecture is a multi-layer bidirectional Transformer encoder.
In this paper, the size of feedforward / filter is 4H, such as 3072 when H=768 and 4096 when H=1024.
The results are mainly shown in two model sizes:
-
BERTBASE: L=12, H=768, A=12, total parameter = 110M
-
BERTLARGE: L=24, H=1024, A=16, total parameter = 340M
- Note: the BERT converter uses a bidirectional self attention mechanism
Input characterization
For each token, its representation consists of corresponding token embedding, segment embedding and position embedding. The sequence length supported by position representation is up to 512 word blocks.
(if you use the bert pre training model, you can't change it. If you train yourself, you can define it yourself. It doesn't have to follow 512. The original text here is to balance efficiency and performance)
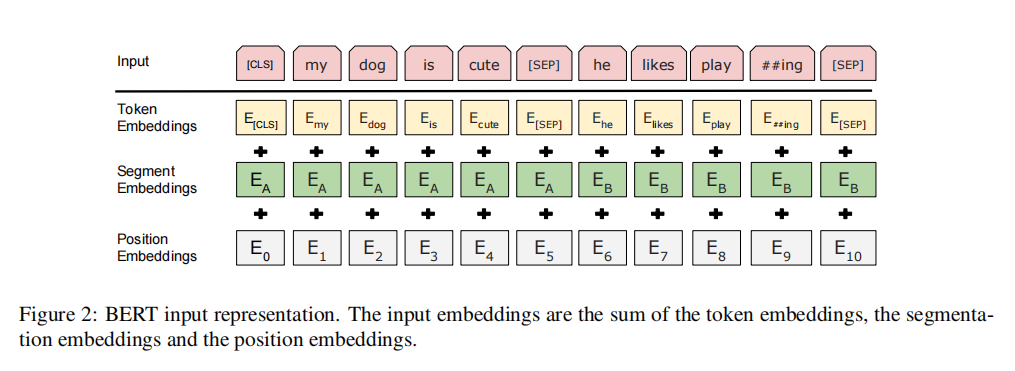
Among them, position embedding is proposed by Transformer to encode the information of different locations.
There are two implementation methods: splicing and summation. See for details Positive embedding in Transformer
Pre training task
The authors use two new unsupervised prediction tasks to pre train BERT
- Masking language model
Randomly mask some parts of the input lexical chunks, and then predict only those blocked lexical chunks. Bert calls this process "masking LM" (MLM).
The specific implementation methods are as follows:
The training data generator randomly selects 15% of the lexical chunks. Then complete the following process:
Instead of always replacing the selected word with [MASK], the data generator will do the following:
- 80% of training data: replace words with [MASK] chunks, for example, [my dog is furry!] [my dog is [MASK]]
- 10% of training data: replace masking words with random words, for example, [my dog is furry!] [my dog is an apple]
- 10% of training data: keep the words unchanged, for example, [my dog is furry!] [my dog is furry!] The purpose of this is to bias the representation towards the actually observed words.
- Next sentence prediction model
In order to train a model for understanding sentence relations, we pre trained a binary next sentence prediction task, which can be easily generated from any monolingual corpus.
The specific implementation method is as follows: select sentences A and B as the pre training samples: 50% of B may be the next sentence of A, and 50% may be random sentences from the corpus
input=[CLS]Men go[MASK]Shop[SEP]He bought a gallon[MASK]milk[SEP] Label= IsNext input=[CLS]man[Mask]Go to the store[SEP]penguin[Mask]It's flying##Shaoniao [SEP] Label= NotNext
summary
BERT uses a more efficient Transformer structure to efficiently obtain the two-way representation information of training data.
The article has done a very detailed ablation experiment. It is suggested that interested students can read the original text in detail.
reference material
[1] https://www.cnblogs.com/guoyaohua/p/bert.html
[2] https://zhuanlan.zhihu.com/p/171363363
[3] https://zhuanlan.zhihu.com/p/360539748
[4] https://arxiv.org/pdf/1810.04805.pdf
🥝 3 model training
# Install required library functions !pip install sumeval
# Decompress data set !unzip -o data/data127041/lcsts_data.zip -d /home/aistudio/work/
Archive: data/data127041/lcsts_data.zip inflating: /home/aistudio/work/lcsts_data.json
import json
f = open('work/lcsts_data.json')
data = json.load(f)
f.close()
# View data
item = data[520]
print('title:',item['title'],'\n Content:',item['content'])
Title: Haikou citizens can take the bus with their bank card Content: Hainan baodaotong Co., Ltd. launched the "ICBC baodaotong joint name", and citizens can take the bus by swiping their bank card. The card not only has the comprehensive financial service function of ICBC debit card, but also has the electronic payment function of baodaotong card. With this joint name card, cardholders can not only take the bus in Haikou City, but also carry out business operations such as swiping card consumption, deposit and withdrawal
from paddlenlp.transformers import BertModel, BertForTokenClassification
import paddle.nn as nn
from paddle.nn import Layer, Linear, Softmax
import paddle
class TitleBertModel(paddle.nn.Layer):
"""
be based on BERT Generation model of pre training model
"""
def __init__(self, pretrained_bert_model: str, input_length: int):
super(TitleBertModel, self).__init__()
bert_model = BertModel.from_pretrained(pretrained_bert_model)
self.vocab_size, self.hidden_size = bert_model.embeddings.word_embeddings.parameters()[0].shape
self.bert_for_class = BertForTokenClassification(bert_model, self.vocab_size)
# Generate a lower triangular matrix to mask the information behind the sentence
self.sequence_length = input_length
# lower_triangle_mask is input_ length * input_ The lower triangular matrix of length (including the main diagonal), which is part of the attention mask (in the forward direction
# The part with 0 in the processing will be processed into an infinitesimal quantity to ensure that the weight of the masked part is approximately equal to 0 when calculating the attention weight). The reason why it is written in the form of lower triangular matrix, and
# transformer's multi head attention calculation mechanism is related, and the details can be learned from relevant papers.
self.lower_triangle_mask = paddle.tril(paddle.tensor.full((input_length, input_length), 1, 'float32'))
def forward(self, token, token_type, input_mask, input_length=None):
# Calculate the attention mask
mask_left = paddle.reshape(input_mask, input_mask.shape + [1])
mask_right = paddle.reshape(input_mask, [input_mask.shape[0], 1, input_mask.shape[1]])
# Enter a valid position in the sentence
mask_left = paddle.cast(mask_left, 'float32')
mask_right = paddle.cast(mask_right, 'float32')
attention_mask = paddle.matmul(mask_left, mask_right)
# Effective position in the calculation of attention mechanism
if input_length is not None:
# The reason why we need to calculate again is that when it is used for reasoning and prediction, the possible input length is not the length set during instantiation. The model here assumes the input during training
# The length is filled to be consistent - this step is not necessary, but it is more convenient to process it into a consistent length (correspondingly, the cost of video memory is increased).
lower_triangle_mask = paddle.tril(paddle.tensor.full((input_length, input_length), 1, 'float32'))
else:
lower_triangle_mask = self.lower_triangle_mask
attention_mask = attention_mask * lower_triangle_mask
# Invalid position set to minimum
attention_mask = (1 - paddle.unsqueeze(attention_mask, axis=[1])) * -1e10
attention_mask = paddle.cast(attention_mask, self.bert_for_class.parameters()[0].dtype)
output_logits = self.bert_for_class(token, token_type_ids=token_type, attention_mask=attention_mask)
return output_logits
# Read pre training model
from paddlenlp.transformers import BertTokenizer
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
[2022-02-08 15:54:15,141] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-base-chinese/bert-base-chinese-vocab.txt
import paddle
import numpy as np
# Custom data reading class
class TitleGenerateData(paddle.io.Dataset):
"""
Construction dataset, inheritance paddle.io.Dataset
Parameters:
data(dict): The title and corresponding text are not encoded
title(str): title
content(str): text
max_len: Maximum length received
"""
def __init__(self, data, tokenizer,max_len = 128,mode='train'):
super(TitleGenerateData, self).__init__()
self.data_ = data
self.tokenizer = tokenizer
self.max_len = max_len
scale = 0.8 # 80% training
if mode=='train':
self.data = self.data_[:int(scale*len(self.data_))]
else:
self.data = self.data_[int(scale*len(self.data_)):]
def __getitem__(self, idx):
item = self.data[idx]
content = item['content']
title = item['title']
token_content = self.tokenizer.encode(content)
token_title = self.tokenizer.encode(title)
token_c, token_typec_c = token_content['input_ids'], token_content['token_type_ids']
token_t, token_typec_t = token_title['input_ids'], token_title['token_type_ids']
if len(token_c) > self.max_len + 1:
token_c = token_c[:self.max_len] + token_c[-1:]
token_typec_c = token_typec_c[:self.max_len] + token_typec_c[-1:]
if len(token_t) > self.max_len + 1:
token_t = token_t[:self.max_len] + token_t[-1:]
token_typec_t = token_typec_t[:self.max_len] + token_typec_t[-1:]
input_token, input_token_type = token_c, token_typec_c
label_token = np.array((token_t + [0] * self.max_len)[:self.max_len], dtype='int64')
# Input fill
input_token = np.array((input_token + [0] * self.max_len)[:self.max_len], dtype='int64')
input_token_type = np.array((input_token_type + [0] * self.max_len)[:self.max_len], dtype='int64')
input_pad_mask = (input_token != 0).astype('float32')
label_pad_mask = (label_token != 0).astype('float32')
return input_token, input_token_type, input_pad_mask, label_token, label_pad_mask
def __len__(self):
return len(self.data)
# Define loss function
class Cross_entropy_loss(Layer):
def forward(self, pred_logits, label, label_pad_mask):
loss = paddle.nn.functional.cross_entropy(pred_logits, label, ignore_index=0, reduction='none')
masked_loss = paddle.mean(loss * label_pad_mask, axis=0)
return paddle.sum(masked_loss)
# Test data reading class
dataset = TitleGenerateData(data,bert_tokenizer,mode='train')
print('=============train dataset=============')
input_token, input_token_type, input_pad_mask, label_token, label_pad_mask = dataset[1]
print(input_token, input_token_type, input_pad_mask, label_token, label_pad_mask)
# View the model structure, define the performance evaluation index and parameters
from paddle.static import InputSpec
from paddlenlp.metrics import Perplexity
from paddle.optimizer import AdamW
net = TitleBertModel('bert-base-chinese', 128)
token_ids = InputSpec((-1, 128), 'int64', 'token')
token_type_ids = InputSpec((-1, 128), 'int64', 'token_type')
input_mask = InputSpec((-1, 128), 'float32', 'input_mask')
label = InputSpec((-1, 128), 'int64', 'label')
label_mask = InputSpec((-1, 128), 'int64', 'label')
inputs = [token_ids, token_type_ids, input_mask]
labels = [label,label_mask]
model = paddle.Model(net, inputs, labels)
model.summary(inputs, [input.dtype for input in inputs])
# Training parameters epochs = 20 context_length = 128 lr = 1e-3
# model training
from paddle.io import DataLoader
from tqdm import tqdm
from paddlenlp.metrics import Perplexity
train_dataset = TitleGenerateData(data,bert_tokenizer,mode='train')
dev_dataset = TitleGenerateData(data,bert_tokenizer,mode='dev')
train_loader = paddle.io.DataLoader(train_dataset, batch_size=128, shuffle=True)
dev_loader = paddle.io.DataLoader(dev_dataset, batch_size=64, shuffle=True)
model = TitleBertModel('bert-base-chinese', context_length)
# Set optimizer
optimizer=paddle.optimizer.AdamW(learning_rate=lr,parameters=model.parameters())
# Set loss function
loss_fn = Cross_entropy_loss()
perplexity = Perplexity()
model.train()
for epoch in range(epochs):
for data in tqdm(train_loader(),desc='epoch:'+str(epoch+1)):
input_token, input_token_type, input_pad_mask, label_token, label_pad_mask = data[0],data[1],data[2],data[3], data[4] # data
predicts = model(input_token, input_token_type, input_pad_mask) # Prediction results
# The calculated loss is equivalent to the loss setting in prepare
loss = loss_fn(predicts, label_token , label_pad_mask)
predicts = paddle.to_tensor(predicts)
label = paddle.to_tensor(label_token)
# Calculating the confusion degree is equivalent to the setting of metrics in prepare
correct = perplexity.compute(predicts, label)
perplexity.update(correct.numpy())
ppl = perplexity.accumulate()
# Back propagation
loss.backward()
# Update parameters
optimizer.step()
# Gradient clearing
optimizer.clear_grad()
print("epoch: {}, loss is: {}, Perplexity is: {}".format(epoch+1, loss.item(),ppl))
# Save the model parameters with the file name Unet_model.pdparams
paddle.save(model.state_dict(), 'work/model.pdparams')
🎖️ 4 model test
import numpy as np
class TitleGen(object):
"""
Define a class that automatically generates text and generate text as required
model: Trained prediction model
tokenizer: Word segmentation coding tool
max_length: The maximum length of generated text must be less than or equal to model Maximum length allowed
"""
def __init__(self, model, tokenizer, max_length=128):
self.model = model
self.tokenizer = tokenizer
self.puncs = [',', '. ', '?', ';']
self.max_length = max_length
def generate(self, head='', topk=2):
"""
Generate titles as required
head (str, list): Text entered
topk (int): From predicted topk Select results from
"""
poetry_ids = self.tokenizer.encode(head)['input_ids']
# Remove the start and end marks
poetry_ids = poetry_ids[1:-1]
break_flag = False
while len(poetry_ids) <= self.max_length:
next_word = self._gen_next_word(poetry_ids, topk)
# For some symbols, such as [UNK], [PAD], [CLS], etc., they have no meaning to the poem after they are generated, so they can be skipped directly
if next_word in self.tokenizer.convert_tokens_to_ids(['[UNK]', '[PAD]', '[CLS]']):
continue
new_ids = [next_word]
if next_word == self.tokenizer.convert_tokens_to_ids(['[SEP]'])[0]:
break
poetry_ids += new_ids
if break_flag:
break
return ''.join(self.tokenizer.convert_ids_to_tokens(poetry_ids))
def _gen_next_word(self, known_ids, topk):
type_token = [0] * len(known_ids)
mask = [1] * len(known_ids)
sequence_length = len(known_ids)
known_ids = paddle.to_tensor([known_ids], dtype='int64')
type_token = paddle.to_tensor([type_token], dtype='int64')
mask = paddle.to_tensor([mask], dtype='float32')
logits = self.model.network.forward(known_ids, type_token, mask, sequence_length)
# The output corresponding to the last word in logits is the probability of the next word
words_prob = logits[0, -1, :].numpy()
# In reverse order of probability, select the first topk words
words_to_be_choosen = words_prob.argsort()[::-1][:topk]
probs_to_be_choosen = words_prob[words_to_be_choosen]
# normalization
probs_to_be_choosen = probs_to_be_choosen / sum(probs_to_be_choosen)
word_choosen = np.random.choice(words_to_be_choosen, p=probs_to_be_choosen)
return word_choosen
# Load the trained model
net = TitleBertModel('bert-base-chinese', 128)
model = paddle.Model(net)
model.load('./work/model')
title_gen = TitleGen(model, bert_tokenizer)
# Using rouge evaluation index
import json
from sumeval.metrics.rouge import RougeCalculator
text_ = 'At 6 o'clock last night, a helicopter crashed into Dongpu reservoir in Hefei'
ref_content = title_gen.generate(head=text_)
print(ref_content)
summary_content = 'The helicopter crashed into a reservoir in Hefei, Anhui Province '
rouge = RougeCalculator(lang="zh")
# Output rouge-1, rouge-2, rouge-l indicators
sum_rouge_1 = 0
sum_rouge_2 = 0
sum_rouge_l = 0
for i, (summary, ref) in enumerate(zip(summary_content, ref_content)):
summary = summary.lower().replace(" ", "")
rouge_1 = rouge.rouge_n(
summary=summary,
references=ref,
n=1)
rouge_2 = rouge.rouge_n(
summary=summary,
references=ref,
n=2)
rouge_l = rouge.rouge_l(
summary=summary,
references=ref)
sum_rouge_1 += rouge_1
sum_rouge_2 += rouge_2
sum_rouge_l += rouge_l
print(i, rouge_1, rouge_2, rouge_l, summary, ref)
print(f"avg rouge-1: {sum_rouge_1/len(summary_content)}\n"
f"avg rouge-2: {sum_rouge_2/len(summary_content)}\n"
f"avg rouge-l: {sum_rouge_l/len(summary_content)}")
🥑 5 Summary
Due to the large amount of data, this project only uses a small amount of data for effect demonstration to ensure the successful operation of the project.
The work of the project is mainly reflected in:
-
The project makes a detailed interpretation of the original text of BERT.
-
The project demonstrates and uses the lcsts summary data set
-
rouge evaluation method is used in the project
-
Fix the Bug of the reference item: when the source data and target data use different MASK processing
If you have any questions, please leave a message in the comment area.