Last month, my tutor asked me to be a little crawler to share the process
requirement analysis
Destination url: AWS Fargate price - serverless container service - AWS cloud service (amazon.com)
You need to crawl the price of Fragate Spot in the web page, but the price is different in different regions, and the price will change every few hours, so you need to crawl regularly.
Store the crawled data into excel to facilitate the later analysis of price changes.
Web page analysis
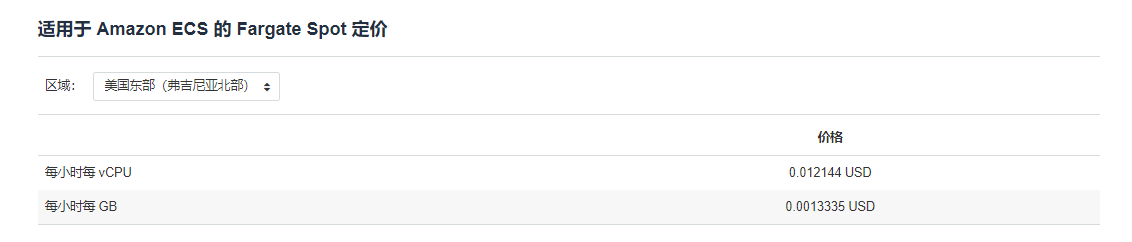
By analyzing the structure of the web page, I can find in the html that the pricce s in different regions are not directly displayed in the html, and will be displayed in the html only after clicking
Check whether it is an asynchronous request and find that there is no asynchronous request, that is, ajax.
Continue to analyze the js function clicked by clicking the button and find that all price s are encrypted in a js file, which is difficult to crack.
Therefore, we can't use simple page analysis to climb data, so we can only use selenium tool (it's actually an automatic testing tool, but it's also OK to climb things)
Related technology
According to the demand and web page structure analysis, the required technology can be determined
Environmental Science:
An Ubuntu ECS (others are OK)
python3
chrome (installed on the server)
Download chromedriver
Third party Library
selenium (web page)
openpyxl (operating excel)
Simple use of related libraries
openpyxl: [python] common methods of openpyxl_ Hurpe CSDN blog
selenium: Introduction and practice of Python+Selenium foundation - brief book (jianshu.com)
Some notes of python + selenium + chrome headless - SegmentFault
deploy
Using selenium (environment deployment) - kaishuai blog Park (cnblogs.com) in Linux
During the deployment process, you will encounter many linux problems, so you need to check the data yourself. It's not difficult
Source code
import datetime
import time
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from openpyxl import Workbook
from openpyxl import load_workbook
import re
def get_driver(url):
# If you start the server, use the following
# driver = webdriver.Remote(
# command_executor='http://127.0.0.1:4444/wd/hub',
# desired_capabilities={'browserName': 'chrome',
# 'version': '2',
# 'javascriptEnabled': True})
option = webdriver.ChromeOptions()
option.add_argument('--headless')
option.add_argument('--disable-gpu') # If this option is not added, sometimes there will be positioning problems
option.add_argument("--start-maximized")
option.add_argument('--window-size=2560, 1440')
chrome = webdriver.Chrome(options=option)
chrome.implicitly_wait(3) # seconds
chrome.get(url)
# print(chrome.get_window_size())
# chrome.maximize_window()
# print(chrome.get_window_size())
# chrome.set_window_size(2560, 1440)
# print(chrome.get_window_size())
return chrome
def get_data(driver):
region_data = []
price_data = []
try:
select = driver.find_element_by_xpath('/html/body/div[2]/main/div[2]/div/div[5]/div/div[1]/div/ul')
region_list = select.find_elements_by_tag_name('li')
except Exception as e:
print(e)
return None, None
else:
print('Number of regions:', len(region_list))
for i in range(23):
select.click()
element = driver.find_element_by_class_name("aws-plc-content")
# print(region_list[i].text)
# print(element.text)
region_data.append(region_list[i].text)
price_data.append(element.text)
# print('---')
# time.sleep(1)
region_list[i].click()
return region_data, price_data
def save(data1, data2):
# Data cleaning
title = []
price_data = []
price_data.append(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
# The title can only be entered once
# for region in data1:
# title.append('')
# title.append(region)
# print(region)
for price in data2:
p = price.split('\n')
price1 = re.search('[\d.]+', p[1])
price2 = re.search('[\d.]+', p[2])
price_data.append(price1.group())
price_data.append(price2.group())
# print(len(title))
print('Data written this time:', len(price_data))
# Start writing data
wb = load_workbook('price.xlsx')
table = wb.active
# table.append(title)
table.append(price_data)
wb.save('price.xlsx')
if __name__ == '__main__':
while True:
url = 'https://aws.amazon.com/cn/fargate/pricing / '# must add https
driver = get_driver(url)
data1, data2 = get_data(driver)
# print(data1)
# print(data2)
if data1 is not None and data2 is not None:
save(data1, data2)
print("This climb is successful!")
time.sleep(3600)
else:
print('This climb failed, 5 min Then climb again')
time.sleep(300)
driver.quit()
# Climb once in 1h
# Eastern United States (Northern Virginia)
# Price
# 0.012144 USD per vcpu per hour
# USD 0.0013335 per GB per hour
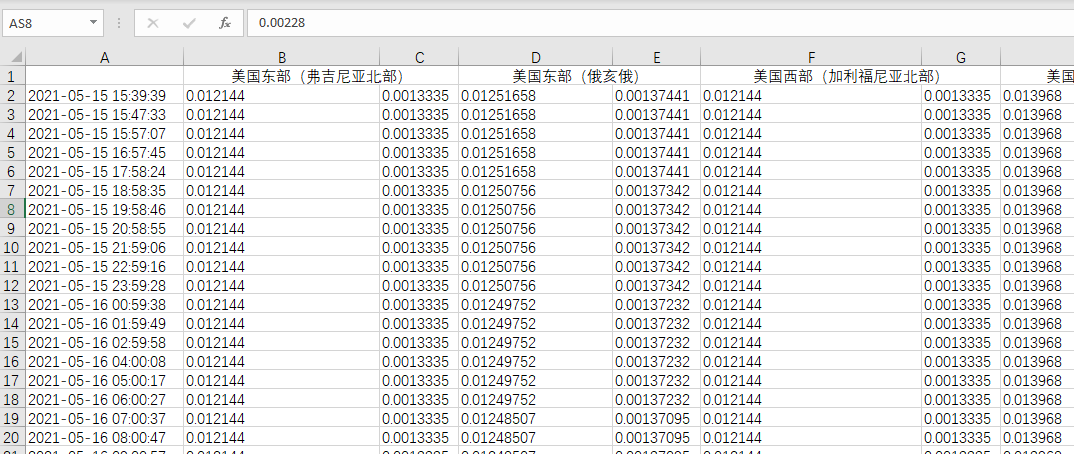
Result display
Finally, I use nginx as a web server to access excel files at any time

You can access it directly in this way, which is more convenient to see whether the crawler is hanging or not (it has been hung several times in the middle, so try catch is added)