Refer to the original website[ https://github.com/pytorch/fairseq/blob/master/examples/bart/README.summarization.md ]
Pre Training Model Download:
Download the pre trained model Bart base. tar: [ https://dl.fbaipublicfiles.com/fairseq/models/bart.base.tar.gz ]
Dataset Download:
Download CNN/DM: http://cs.nyu.edu/~kcho/DMQA / (download story only)
Unzip the two downloaded packages respectively:
tar -xvf cnn_stories.tar tar -xvf dailymail_stories.tar
Directory format at this time:
function:
python make_datafiles.py /Save bart Directory of/cnn/stories /Save bart Directory of/dailymail/stories
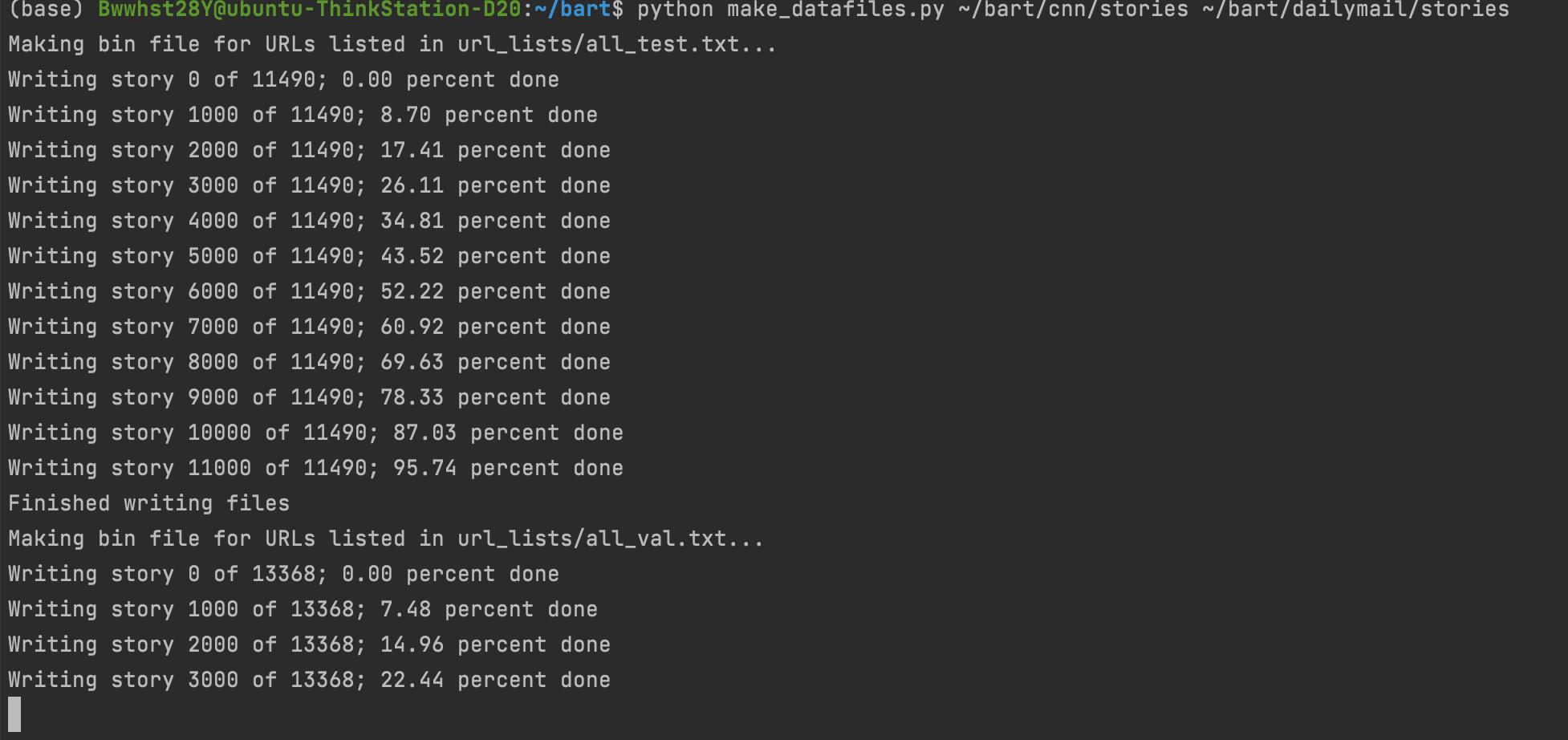
At this time, we will extract the source and target from the url, which represent the original text and summary respectively, and have divided the test set, verification set and training set
target:
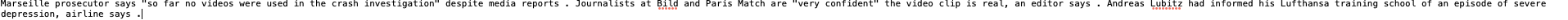
And the corresponding source:

Directory at this time:
Download the required tools:
wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json' wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe' wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt'

After that, we segment the data: (the code of the source website will not find the module. Let's change the execution form of the command line)
First, make sure that the fairseq tool is installed:
git%20clone%20https://github.com/pytorch/fairseq.git
then
The original code will report an error as follows:
for SPLIT in train val
do
for LANG in source target
do
python -m examples.roberta.multiprocessing_bpe_encoder \
--encoder-json encoder.json \
--vocab-bpe vocab.bpe \
--inputs "$TASK/$SPLIT.$LANG" \
--outputs "$TASK/$SPLIT.bpe.$LANG" \
--workers 60 \
--keep-empty;
done
done

After change:
for SPLIT in train val
do
for LANG in source target
do
python fairseq/examples/roberta/multiprocessing_bpe_encoder.py \
--encoder-json encoder.json \
--vocab-bpe vocab.bpe \
--inputs "$TASK/$SPLIT.$LANG" \
--outputs "$TASK/$SPLIT.bpe.$LANG" \
--workers 60 \
--keep-empty;
done
done
Then we divide the data sets into:
fairseq-preprocess \
--source-lang "source" \
--target-lang "target" \
--trainpref "${TASK}/train.bpe" \
--validpref "${TASK}/val.bpe" \
--destdir "${TASK}-bin/" \
--workers 60 \
--srcdict dict.txt \
--tgtdict dict.txt;
So far, we have completed the data preprocessing, and the next step is fine-tuning.
Before introducing fine tuning, here is a Linux tip:
Because machine learning requires training, the training time is usually calculated in hours or even days, and even in months under Card conditions. Because when people and computers can't work all the time, the screen command is introduced
first:
screen -S bart creates a new screen window of bart
then
At this point, we close the ssh window and enter screen -r bart again. We will find that the interface at this time is the one we just entered
So we can start fine tuning:
FINE-TUNE:
TOTAL_NUM_UPDATES=20000
WARMUP_UPDATES=500
LR=3e-05
MAX_TOKENS=2048
UPDATE_FREQ=4
BART_PATH=/bart.base/model.pt
CUDA_VISIBLE_DEVICES=0 fairseq-train cnn_dm-bin \
--restore-file $BART_PATH \
--max-tokens $MAX_TOKENS \
--task translation \
--source-lang source --target-lang target \
--truncate-source \
--layernorm-embedding \
--share-all-embeddings \
--share-decoder-input-output-embed \
--reset-optimizer --reset-dataloader --reset-meters \
--required-batch-size-multiple 1 \
--arch bart_base \
--criterion label_smoothed_cross_entropy \
--label-smoothing 0.1 \
--dropout 0.1 --attention-dropout 0.1 \
--weight-decay 0.01 --optimizer adam --adam-betas "(0.9, 0.999)" --adam-eps 1e-08 \
--clip-norm 0.1 \
--lr-scheduler polynomial_decay --lr $LR --total-num-update $TOTAL_NUM_UPDATES --warmup-updates $WARMUP_UPDATES \
--fp16 --update-freq $UPDATE_FREQ \
--skip-invalid-size-inputs-valid-test \
--find-unused-parameters;

(the fine-tuning process is not very smooth, and the video memory has been hovering on the edge of explosion)
After training, we use the following command to generate a summary, in which ceshi Source is 1: a news copied from CHINA DAILY 2: a news found from the test set (because the summary generated by the original test set will also burst in memory on the server I use, so I chose two examples)
python fairseq/examples/bart/summarize.py \ --model-dir ~/bart/bart.large.cnn \ --model-file model.pt \ --src ~/bart/cnn_dm/ceshi.source \ --out ~/bart/cnn_dm/ceshi.hypo
Final result:
