hive definition:
Hive is a data warehouse tool based on 'Hadoop'. It can map structured data files into a data table, and use SQL like methods to read, write and manage data files. This Hive SQL is called HQL for short. Hive's execution engines can be MR, Spark and Tez.
1. hive can't do data storage. He needs to rely on HDFS or Hbase for data storage.
2. Hive has no computing function. He needs to rely on mapreduce, tez, spark, etc.
3. hive can parse HQL statements into programs such as mapreduce, spark or tez.
hive app:
Used for data warehouse (data statistics and analysis)
Advantages and disadvantages of hive
advantage
Low learning cost: it provides a SQL like query language HQL, so that developers familiar with SQL language do not need to care about details and can get started quickly
Massive data analysis: the bottom layer is based on massive computing to MapReduce
Scalability: the computing / expansion capability is designed for very large data sets (MR as the computing engine and HDFS as the storage system). Hive can freely expand the scale of the cluster without restarting the service in general.
Extensibility: Hive supports user-defined functions. Users can implement their own functions according to their own needs.
Good fault tolerance: HQL can still complete execution if a data node has a problem.
Unified management: provides unified metadata management
shortcoming
Hive's HQL expression ability is limited.
Iterative algorithms cannot be expressed
Hive's efficiency is relatively low
The MapReduce job automatically generated by Hive is usually not intelligent enough
Hive tuning is difficult, and the granularity is coarse
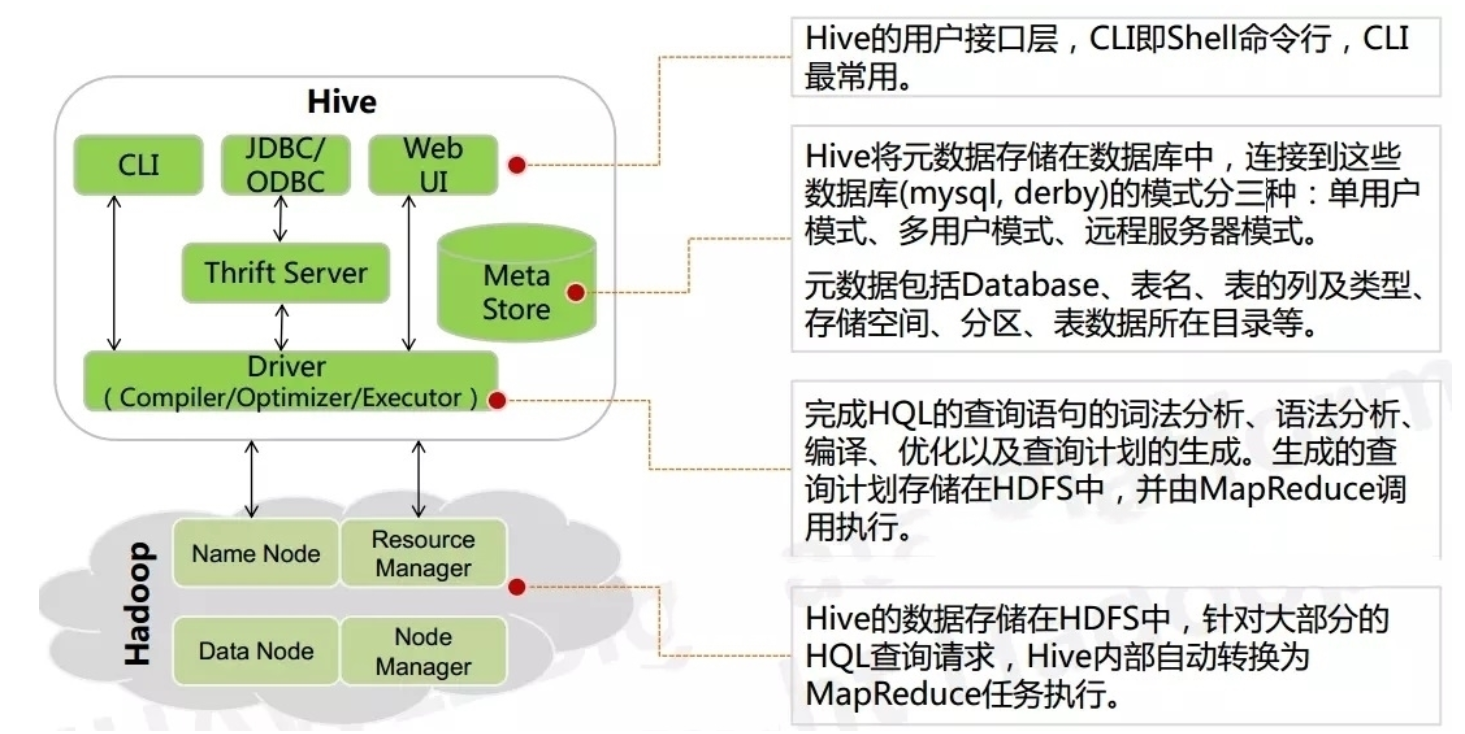
metaStore: library, table, table type, data storage location, field, type, creator, type, partition, bucket and many other information. Metadata is stored in the built-in derby database by default, but mysql is recommended.
Driver (interpreter): convert HQL string into abstract syntax tree AST. This step is generally completed by a third-party tool library, such as antlr; Perform syntax analysis on AST, such as whether the table exists, whether the field exists, and whether the SQL semantics is incorrect.
Compiler: compiles the morphology, syntax and semantics of hql statements (it needs to be associated with metadata). After compilation, an execution plan will be generated.
Optimizer: select a better execution plan and optimize it (reduce unnecessary columns, use partitions, use indexes, etc.).
Executor: submit the optimized execution plan (corresponding code) to the yarn of hadoop for execution.
hive generally provides two services: hiveserver2 (third-party services: jdbc connection, beeline connection, etc.) and Metastore (providing metadata connection).
The difference between hive and relational database
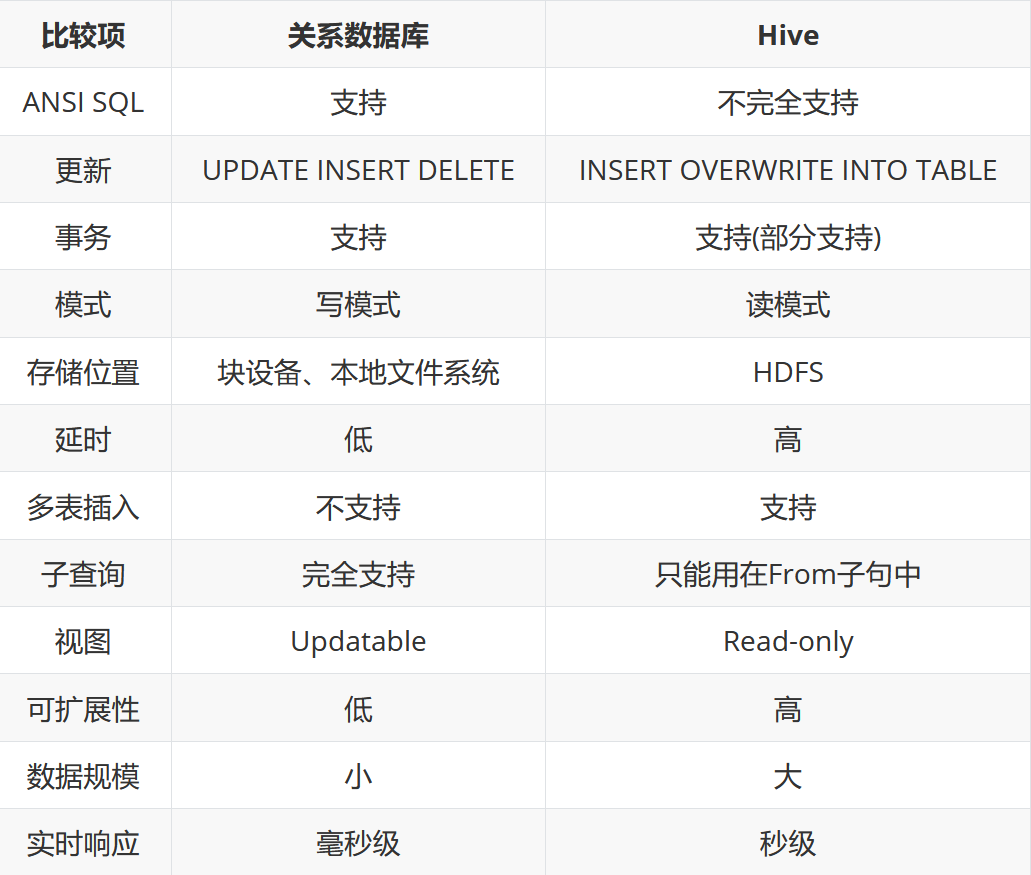 Data formats of hive: TextFile, SequenceFile, RCFile, ORC, Parquet
Data formats of hive: TextFile, SequenceFile, RCFile, ORC, Parquet
hive data update: local update is not supported, and overlay update and append update are supported.
Relationship between Hadoop and hive
1. Hive is based on Hadoop.
2. Hive itself doesn't have many functions. Hive is equivalent to adding a shell to Hadoop, which encapsulates Hadoop once.
3. Hive's storage is based on HDFS, and hive's calculation is based on MapReduce.
Installation and deployment of hive under linux
decompression
[root@hadoop01 ~]# tar -zxvf /home/apache-hive-2.3.7-bin.tar.gz -C /usr/local/ [root@hadoop01 ~]# mv /usr/local/apache-hive-2.3.7-bin/ /usr/local/hive-2.3.7
Configure environment variables
[root@hadoop01 ~]# vi /etc/profile #Add the following contents export HIVE_HOME=/usr/local/hive-2.3.7/ export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin: #Refresh environment variables [root@hadoop01 ~]# source /etc/profile #Check environment variables [root@hadoop01 ~]# which hive /usr/local/hive-2.3.7/bin/hive
to configure
Create hive site in the conf directory XML, and then overwrite the following contents:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- This parameter mainly specifies Hive Data storage directory for -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- This parameter mainly specifies Hive Temporary file storage directory for -->
<property>
<name>hive.exec.scratchdir</name>
<value>/data/hive</value>
</property>
<!--to configure mysql Connection string for-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<!--to configure mysql Connection drive for-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--Configure login mysql User-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--Configure login mysql Password for-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Root123456!</value>
</property>
</configuration> Copy mysql driver package
[root@hadoop01 hive-2.3.7]# cp /home/mysql-connector-java-5.1.28-bin.jar /usr/local/hive-2.3.7/lib/
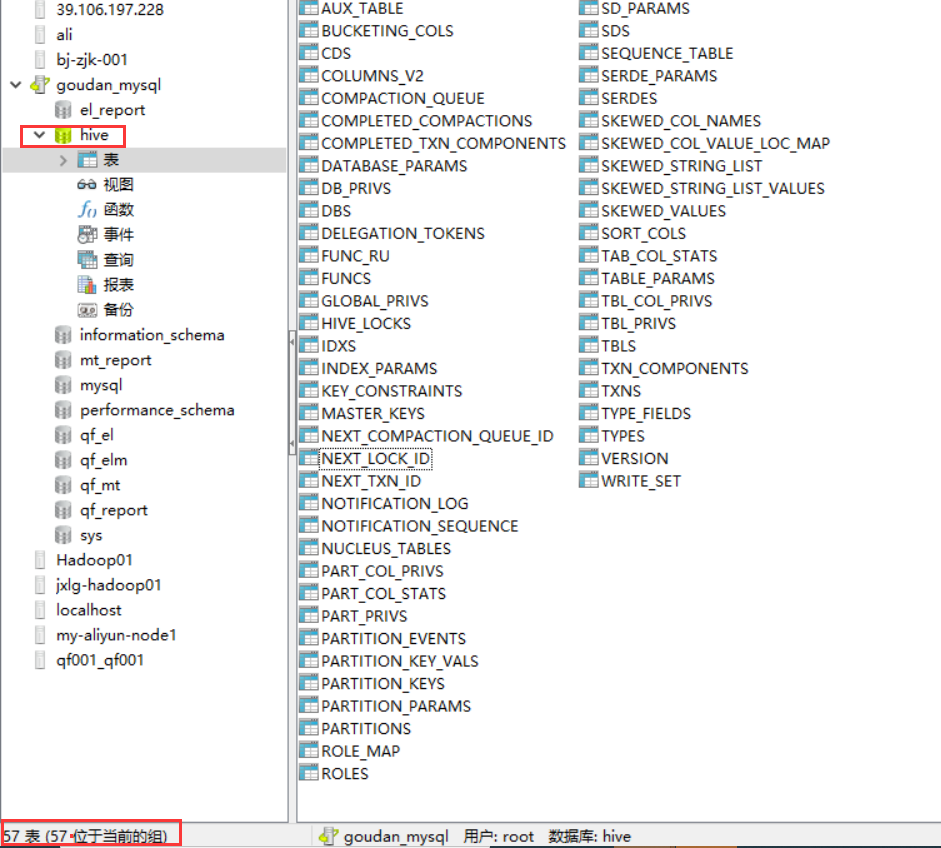
Initialize metadata
[root@hadoop01 hive-2.3.7]# schematool -initSchema -dbType mysql
Initialization, check in navicat, and the table is as follows:
start-up
Conditions: make hadoop and mysql available.
hive --service metastore &
Connect hive
[root@hadoop01 hive-2.3.7]# hive