ShardingJdbc
1, ShardingJdbc overview
1. Overview
Official website: http://shardingsphere.apache.org/index_zh.html
Download address: https://shardingsphere.apache.org/document/current/cn/downloads/
Quick start: https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/

The following words are from the official website:
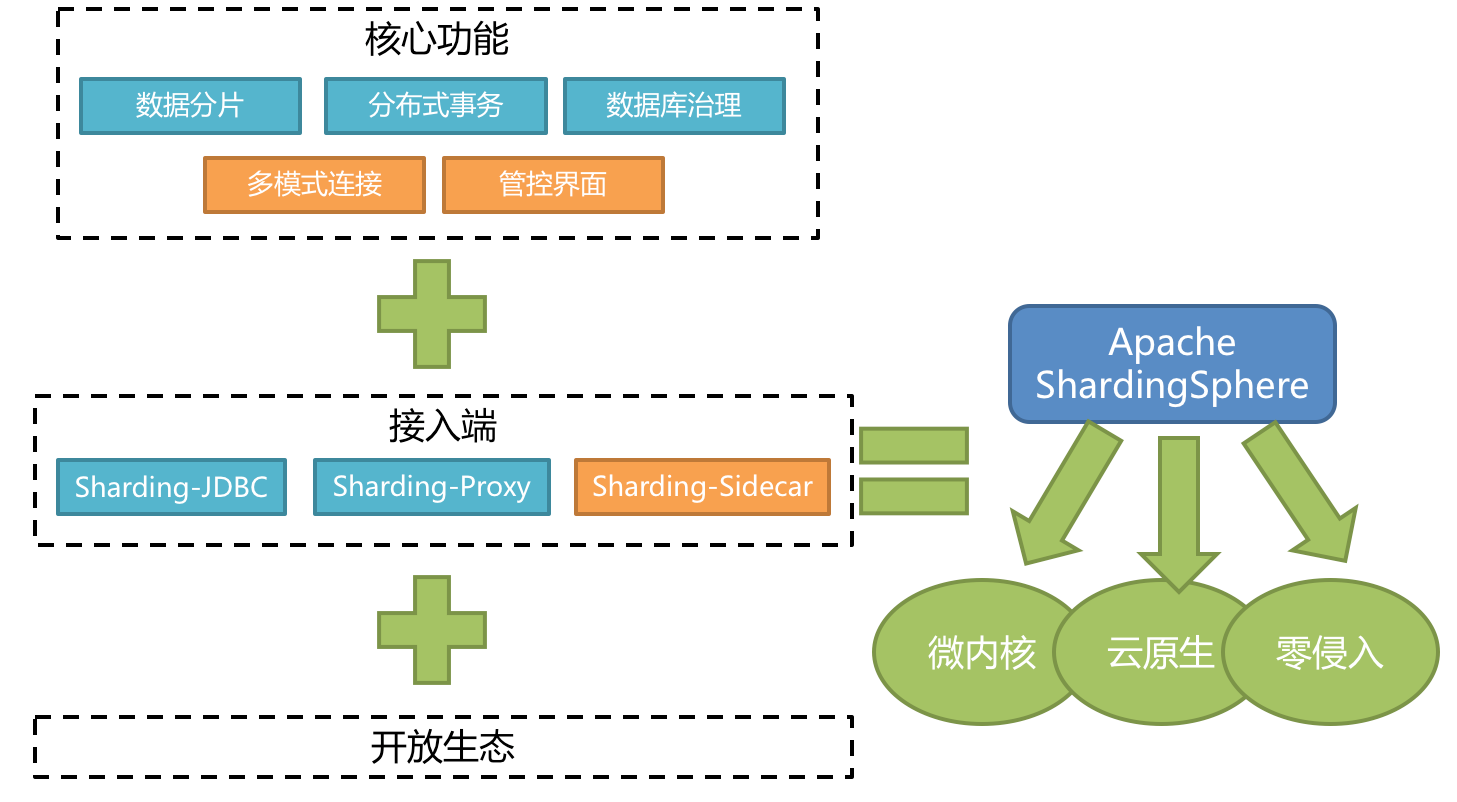
Apache ShardingSphere is an ecosystem composed of a set of open source distributed database solutions. It consists of JDBC Proxy and Sidecar (under planning) are composed of products that can be deployed independently and support mixed deployment. They all provide standardized data level expansion, distributed transaction, distributed governance and other functions, and can be applied to various application scenarios such as Java isomorphism, heterogeneous language, cloud primitives and so on.
Apache ShardingSphere aims to make full and reasonable use of the computing and storage capacity of relational database in distributed scenarios, rather than realizing a new relational database. Relational database still occupies a huge market share today and is the cornerstone of the enterprise's core system. It is difficult to shake in the future. We pay more attention to providing increment on the original basis rather than subversion.
Apache ShardingSphere 5. Version x began to focus on pluggable architecture, and the functional components of the project can be flexibly expanded in a pluggable manner. At present, the functions of data fragmentation, read-write separation, data encryption, shadow database pressure test, and the support of SQL and protocols such as MySQL, PostgreSQL, SQLServer and Oracle are woven into the project through plug-ins. Developers can customize their own unique systems like building blocks. Apache shardingsphere has provided dozens of SPI s as the extension points of the system, which is still increasing.
ShardingSphere became the top project of Apache Software Foundation on April 16, 2020.
2. On renaming
After 3.0, it was changed to ShardingSphere.
3. Understanding shardingjdbc
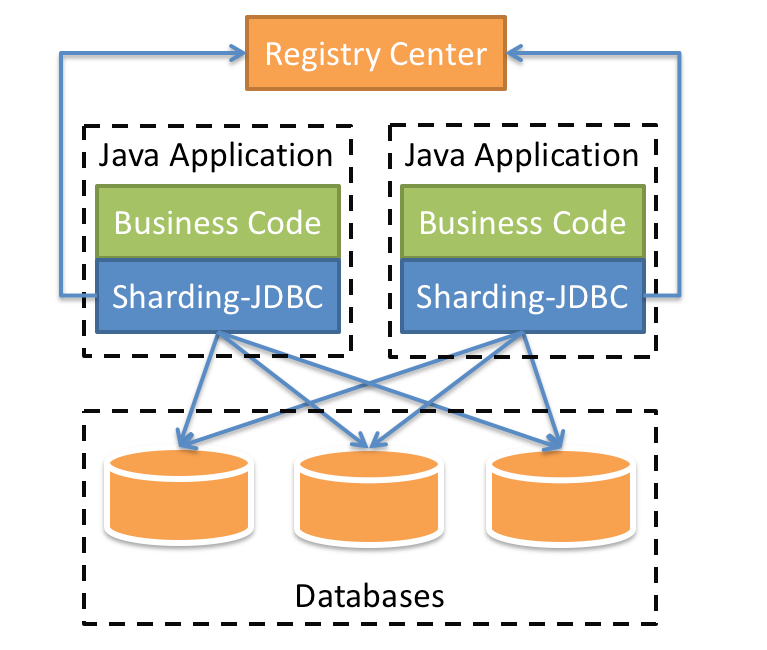
Positioned as a lightweight Java framework, additional services are provided in the JDBC layer of Java. It uses the client to directly connect to the database and provides services in the form of jar package without additional deployment and dependency. It can be understood as an enhanced jdbc driver and is fully compatible with JDBC and various ORM frameworks.
It is applicable to any ORM framework based on JDBC, such as JPA, Hibernate, Mybatis, Spring JDBC Template or directly using JDBC.
Support any third-party database connection pool, such as DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
It supports any database that implements JDBC specification. At present, it supports MySQL, Oracle, SQLServer, PostgreSQL and any database that complies with SQL92 standard.
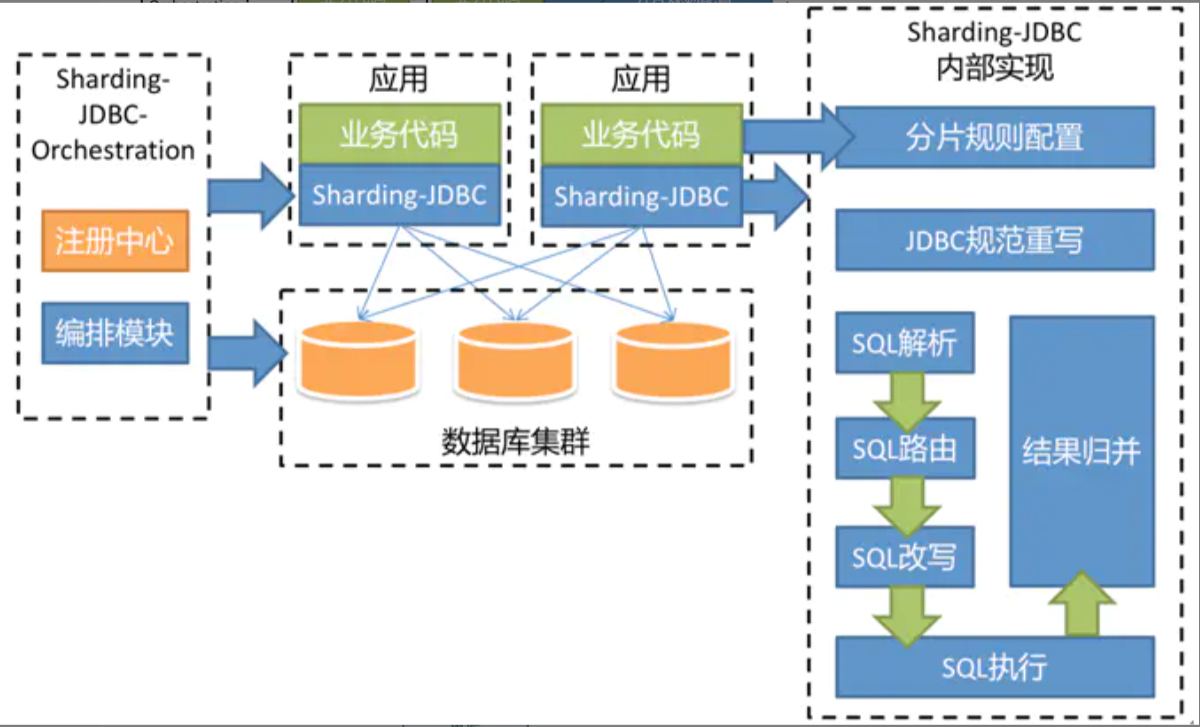
4. Understanding sharding JDBC functional architecture
5. Meet sharding proxy
- It is completely transparent to the application and can be directly used as MySQL/PostgreSQL.
- Applicable to any client compatible with MySQL/PostgreSQL protocol.
6. Comparison of three components
| Sharding-Jdbc | Sharding-Proxy | Sharding-Sidecar | |
|---|---|---|---|
| database | arbitrarily | MYSQL | MYSQL |
| Connection consumption | high | low | low |
| Heterogeneous language | Java only | arbitrarily | arbitrarily |
| performance | Low loss | High loss | Low loss |
| Centralization | yes | no | yes |
| Static entry | nothing | have | nothing |
7. ShardingJdbc hybrid architecture
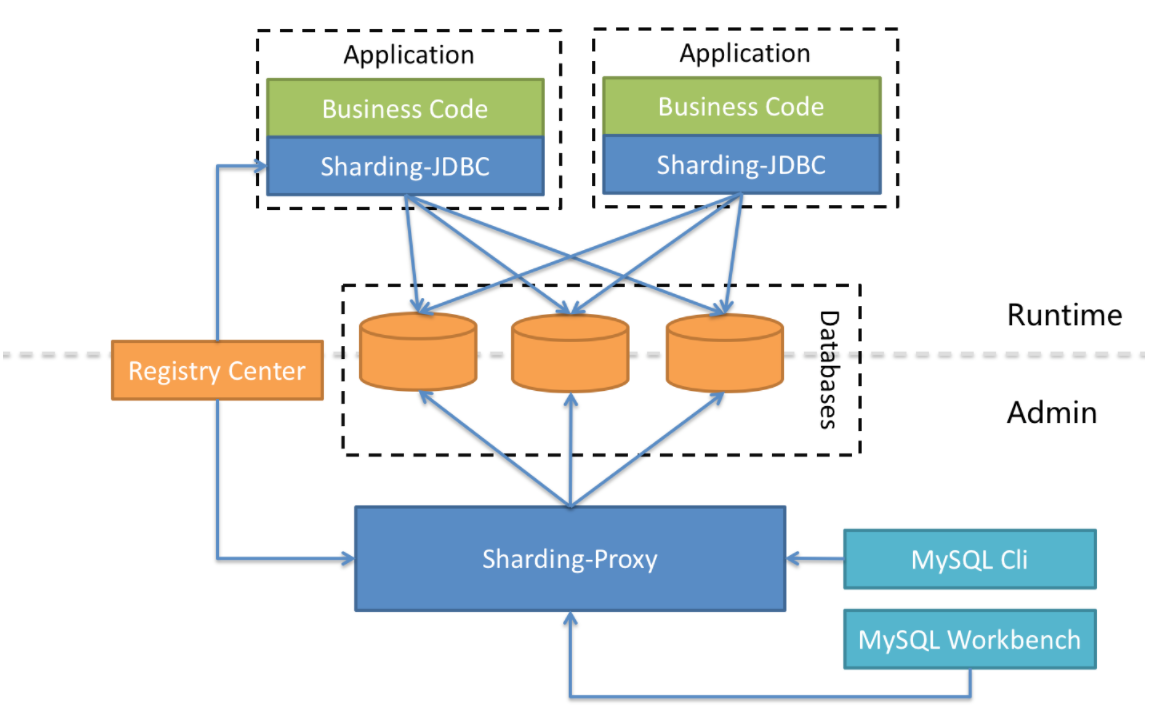
Shardingsphere JDBC adopts a decentralized architecture, which is suitable for High-Performance Lightweight OLTP (connection transaction processing) applications developed in Java; shardingsphere proxy provides static entry and heterogeneous language support, which is suitable for OLAP (connection data analysis) applications and scenarios of management, operation and maintenance of fragmented data bases.
Apache ShardingSphere is an ecosystem composed of multiple access terminals. By mixing shardingsphere JDBC and shardingsphere proxy, and using the same registry to uniformly configure the fragmentation strategy, it can flexibly build application systems suitable for various scenarios, making architects more free to adjust the best system architecture suitable for the current business.
8. Function list of ShardingShpere
- Function list
- Data slicing
- Sub warehouse & sub table
- Read write separation
- Customization of segmentation strategy
- Decentralized distributed primary key
- Distributed transaction
- Standardized transaction interface
- XA strongly consistent transaction
- Flexible transaction
- Database governance
- Distributed governance
- Elastic expansion
- Visual link tracking
- data encryption
9. Analysis of ShardingSphere data slicing kernel
The main processes of data fragmentation of the three ShardingSphere products are completely consistent. The core consists of SQL parsing = > executor optimization = > sql routing = > sql rewriting = > sql execution = > result merging.
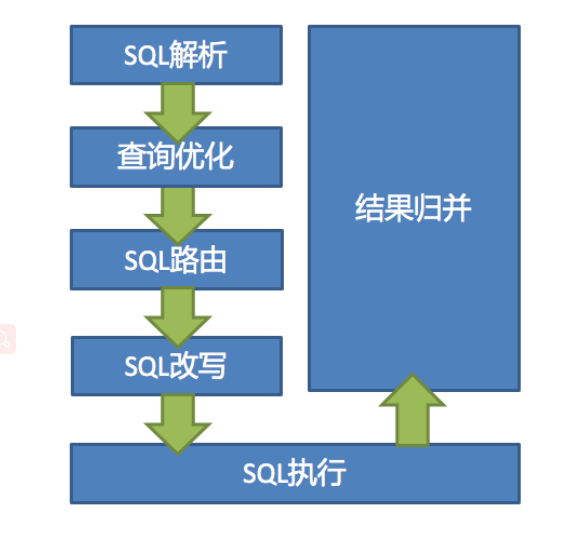
SQL parsing
It is divided into lexical analysis and grammatical analysis. First, the SQL is divided into non separable words through the lexical parser. Then use the syntax parser to understand SQL, and finally extract the parsing context. The parsing context includes tables, selections, sorting items, grouping items, aggregation functions, paging information, query criteria, and markers of placeholders that may need to be modified.
Actuator optimization
Merge and optimize segmentation conditions, such as OR, etc.
SQL routing
Match the partition policy configured by the user according to the resolution context, and generate a routing path. At present, fragment routing and broadcast routing are supported.
SQL rewrite
Rewrite SQL into statements that can be executed correctly in a real database. SQL rewriting is divided into correctness rewriting and optimization rewriting.
SQL execution
Asynchronous execution through a multithreaded actuator.
Result merging
Collect and merge multiple execution results to facilitate output through a unified JDBC interface. Result merging includes stream merging, memory merging and additional merging using decorator mode.
2, ShardingJdbc preparation - install MySQL 5.0 for Linux seven
1. Install mysql using yum or up2date
Download the rpm address of mysql
http://repo.mysql.com/yum/mysql-5.7-community/el/7/x86_64/

Configure Mysql extension source
rpm -ivh http://repo.mysql.com/yum/mysql-5.7-community/el/7/x86_64/mysql57-community-release-el7-10.noarch.rpm
Install mysql using yum or up2date
yum install mysql-community-server -y
Start Mysql and add boot auto start
systemctl start mysqld systemctl stop mysqld systemctl enable mysqld
Log in to the database using the Mysq initial password

>grep "password" /var/log/mysqld.log
> mysql -uroot -pma1S8xjuEA/F
Or one-step approach is as follows
>mysql -uroot -p$(awk '/temporary password/{print $NF}' /var/log/mysqld.log)
Modify database password
The database default password rules must carry upper and lower case letters and special symbols, and the character length is greater than 8, otherwise an error will be reported.
Therefore, when setting a simple password, you need to modify set global validate first_ password_ Policy and_ The value of the length parameter.

mysql> set global validate_password_policy=0; Query OK, 0 rows affected (0.00 sec) mysql> set global validate_password_length=1; Query OK, 0 rows affected (0.00 sec)
Change Password
mysql> set password for root@localhost = password('mkxiaoer');
Query OK, 0 rows affected, 1 warning (0.00 sec)
perhaps
mysql>ALTER USER 'root'@'localhost' IDENTIFIED BY 'new password';
Login test
[root@http-server ~]# mysql -uroot -pmkxiaoer mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec) mysql> exit
Login authorization of visualizer: (if authorization is unsuccessful, please check the firewall)
After completing the above operations, we can't connect with the visual client yet. We need to authorize:
mysql > grant all on *.* to root@'%' identified by 'Database password'; mysql > flush privileges;
After the operation, you can use navicat or sqlylog for remote connection
sqlylog Download: https://sqlyog.en.softonic.com/
3, ShardingJdbc preparation - MySql completes master-slave replication
summary
Master slave replication (also known as AB replication) allows data from one MySQL database server (master server) to be replicated to one or more MySQL database servers (slave servers).
Replication is asynchronous, and the slave does not need a permanent connection to receive updates from the master.
Depending on the configuration, you can replicate all databases in the database, the selected database, or even the selected tables.
1. The advantages of replication in MySQL include:
- Scale out solution - distribute load among multiple slaves to improve performance. In this environment, all writes and updates must be made on the primary server. However, reading can be performed on one or more slave devices. The model can improve the write performance (because the master device is dedicated to updating) and significantly improve the read speed of more and more slave devices.
- Data security - because the data is copied to the slave and the slave can pause the replication process, the backup service can be run on the slave without damaging the corresponding master data.
- Analysis - real time data can be created on the master server, while information analysis can be performed on the slave server without affecting the performance of the master server.
- Remote data distribution - you can use replication to create a local copy of data for a remote site without permanent access to the primary server.
2. How Replication works
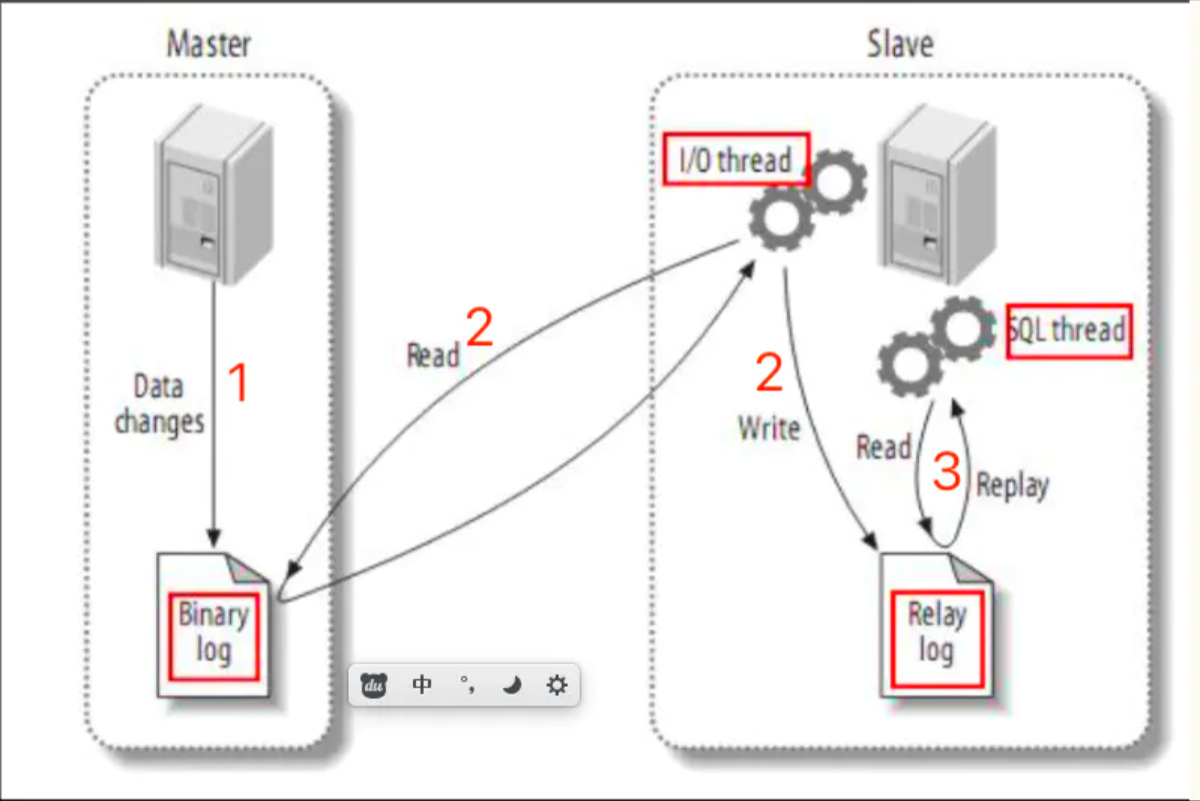
The premise is that the database server as the master server role must open binary logs
Any modification on the master server will be saved in the Binary log through its own I / O thread.
- Start an I/O thread from the server, connect to the main server through the configured user name and password, request to read the binary log, and then write the read binary log to a local real log.
- Open an SQL thread from the server at the same time to regularly check the real log (this file is also binary). If an update is found, immediately execute the updated content on the local database.
Each slave server receives a copy of the entire contents of the master server binary log. - The slave device is responsible for determining which statements in the binary log should be executed.
Unless otherwise specified, all events in the master-slave binary log are executed on the slave.
If desired, you can configure the slave server to handle only events for a specific database or table.
3. The specific configuration is as follows
Master node configuration / etc / my CNF (executed by master node)
> vim /etc/my.cnf [mysqld] ## Be unique in the same LAN server-id=100 ## Enable the binary log function, and you can take any (key) log-bin=mysql-bin ## Replication filtering: databases that do not need to be backed up are not output (mysql libraries are generally not synchronized) binlog-ignore-db=mysql ## The memory allocated for each session is used to store the cache of binary logs during the transaction binlog_cache_size=1M ## Format of master-slave copy (mixed,statement,row, default format is statement) binlog_format=mixed
Slave node configuration / etc / my CNF (executed by slave node)
> vim /etc/my.cnf [mysqld] ## Set up server_id, be unique server-id=102 ## Enable the binary log function for use when Slave is the Master of other Slave log-bin=mysql-slave-bin ## relay_log configure relay log relay_log=edu-mysql-relay-bin ##Replication filtering: databases that do not need to be backed up are not output (mysql libraries are generally not synchronized) binlog-ignore-db=mysql ## If you need to synchronize functions or stored procedures log_bin_trust_function_creators=true ## The memory allocated for each session is used to store the cache of binary logs during the transaction binlog_cache_size=1M ## Format of master-slave copy (mixed,statement,row, default format is statement) binlog_format=mixed ## Skip all errors encountered in master-slave replication or specified types of errors to avoid the interruption of slave side replication. ## For example, the 1062 error refers to the duplication of some primary keys, and the 1032 error is due to the inconsistency between the primary and secondary database data slave_skip_errors=1062
Authorize the slave server on the master server to synchronize permissions (executed on the master node)
Note: execute on the master server
mysql > mysql -uroot -pmaster Password for # Grant the slave server to synchronize the master service mysql > grant replication slave, replication client on *.* to 'root'@'slave Service ip' identified by 'slave Password for the server'; mysql > flush privileges; # View the current MySQL users and their corresponding IP permissions (you can not execute it, just a view) mysql > select user,host from mysql.user;

Query the binlog file name and location of the master service (executed by the master node)
mysql > show master status;

- Log file name: MySQL bin 000002
- Copy location: 2079
Slave is associated with the master node (executed by the slave node)
Enter the slave node:
mysql > mysql -uroot -p you slave Password for
Start binding
mysql> change master to master_host='master The server ip', master_user='root', master_password='master password', master_port=3306, master_log_file='mysql-bin.000002',master_log_pos=2079;
Here, pay attention to the master_log_file and master_log_pos is obtained through the master server through show master status.
View the master-slave synchronization status on the slave node (executed by the slave node)
Start master-slave replication
mysql> start slave; Query OK, 0 rows affected (0.00 sec)
Then view the master-slave synchronization status
mysql> show slave status\G;
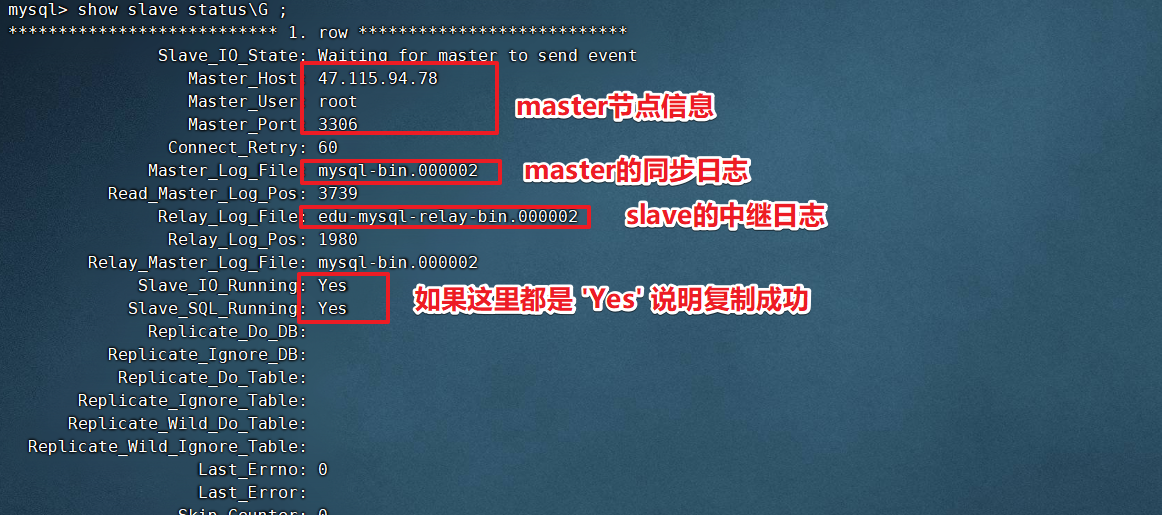
Other commands (executed by slave node)
# Stop replication mysql> stop slave;
Master slave replication test
- Create databases and tables under the master node, or modify, add, and delete records. The synchronization is performed on the master node
- Click to view the slave node information (executed by the slave node)
Remember
During master-slave replication, do not create databases or related operations based on. Then delete it. This will change the pos of master-slave replication and cause replication failure. If such problems occur, check the troubleshooting of common problems in 04-03.
4. Troubleshooting related problems of master-slave replication
1. Master slave replication Connecting problem
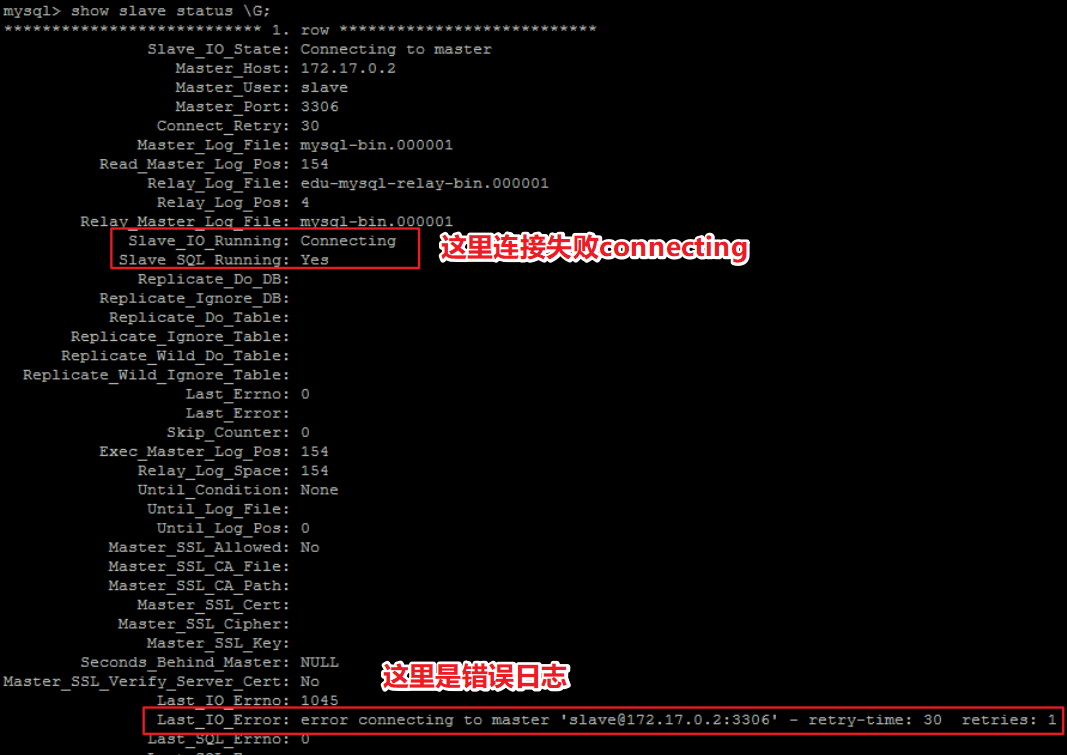
After starting the master-slave replication process with start slave, if the SlaveIORunning is always Connecting, it means that the master-slave replication is always connected. This situation is generally caused by the following reasons. We can use last_ IO_ The error prompt is excluded.
- The network is blocked
Check ip, port - Wrong password
Check that the user created for synchronization and the user password are correct - pos wrong
Check the Position of the Master
2. MYSQL mirror server recovery stopped due to error - Slave_SQL_Running: No
before stop slave,Then execute the prompted statement, and then > stop slave; > set global sql_slave_skip_counter=1; > start slave; > show slave status\G ;
3. Slave from MYSQL server_ IO_ Running: no solution 2
-
Execute on the master node to obtain the log file and post
mysql > show master status;
-
Rebind the slave node
mysql > stop slave; mysql > CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000008', MASTER_LOG_POS=519086591; mysql > start slave;
The reason for this kind of problem is that during master-slave replication, tables are created based on, and then data tables or tables are deleted and operated.
4, ShardingJdbc configuration and read write separation
1. Content outline
- Create a new springboot project
- Introduce relevant sharding dependency, ssm dependency and database driver
- Define and configure application yml
- Define entity, mapper and controller
- Visit the test to see the effect
- Summary
2. Specific implementation steps
1. Create a new springboot project
2. Introduce relevant sharding dependency, ssm dependency and database driver
<properties>
<java.version>1.8</java.version>
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version>
</properties>
<!-- rely on web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- rely on mybatis and mysql drive -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--rely on lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--rely on sharding-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!--Dependent data source druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
3. Define and configure application yml
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# Parameter configuration, display sql
props:
sql:
show: true
# Configure data sources
datasource:
# Give each data source an alias, and the following DS1, DS2 and DS3 can be named arbitrarily
names: ds1,ds2,ds3
# Configure database connection information for each data source of master-ds1
ds1:
# Configure druid data source
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.115.94.78:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure DS2 slave
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure DS3 slave
ds3:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure default data source ds1
sharding:
# The default data source is mainly used for writing. Note that read-write separation must be configured. Note: if it is not configured, the three nodes will be regarded as slave nodes. Errors will occur in adding, modifying and deleting.
default-data-source-name: ds1
# Configure the read-write separation of the data source, but the database must be master-slave replication
masterslave:
# Configure the master-slave name. You can choose any name
name: ms
# Configure the master database to write data
master-data-source-name: ds1
# Configuring slave slave nodes
slave-data-source-names: ds2,ds3
# Configure the load balancing strategy of the slave node and adopt the polling mechanism
load-balance-algorithm-type: round_robin
# Integrate mybatis configuration XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.xuexiangban.shardingjdbc.entity
Note:
# Configure default data source ds1
sharding:
# The default data source is mainly used for writing. Note that read-write separation must be configured
# Note: if it is not configured, the three nodes will be treated as slave nodes, and errors will occur in adding, modifying and deleting.
default-data-source-name: ds1
# Configure the read-write separation of the data source, but the database must be master-slave replication
masterslave:
# Configure the master-slave name. You can choose any name
name: ms
# Configure the master database to write data
master-data-source-name: ds1
# Configuring slave slave nodes
slave-data-source-names: ds2,ds3
# Configure the load balancing strategy of the slave node and adopt the polling mechanism
load-balance-algorithm-type: round_robin
If the above, sharding JDBC will select the data source in a random way. If default data source name is not configured, the three nodes will be treated as slave nodes, and errors will occur in adding, modifying and deleting.
4. Define mapper, controller and entity
entity
package com.xuexiangban.shardingjdbc.entity;
import lombok.Data;
/**
* @author: Learning companion - flying brother
* @description: User
* @Date : 2021/3/10
*/
@Data
public class User {
// Primary key
private Integer id;
// nickname
private String nickname;
// password
private String password;
// nature
private Integer sex;
// nature
private String birthday;
}
mapper
package com.xuexiangban.shardingjdbc.mapper;
import com.xuexiangban.shardingjdbc.entity.User;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.util.List;
/**
* @author: Learning companion - flying brother
* @description: UserMapper
* @Date : 2021/3/10
*/
public interface UserMapper {
/**
* @author Learning companion - flying brother
* @description Save user
* @params [user]
* @date 2021/3/10 17:14
*/
@Insert("insert into ksd_user(nickname,password,sex,birthday) values(#{nickname},#{password},#{sex},#{birthday})")
void addUser(User user);
/**
* @author Learning companion - flying brother
* @description Save user
* @params [user]
* @date 2021/3/10 17:14
*/
@Select("select * from ksd_user")
List<User> findUsers();
}
controller
package com.xuexiangban.shardingjdbc.controller;
import com.xuexiangban.shardingjdbc.entity.User;
import com.xuexiangban.shardingjdbc.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Random;
/**
* @author: Learning companion - flying brother
* @description: UserController
* @Date : 2021/3/10
*/
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/save")
public String insert() {
User user = new User();
user.setNickname("zhangsan"+ new Random().nextInt());
user.setPassword("1234567");
user.setSex(1);
user.setBirthday("1988-12-03");
userMapper.addUser(user);
return "success";
}
@GetMapping("/listuser")
public List<User> listuser() {
return userMapper.findUsers();
}
}
5. Visit the test to see the effect
1: Visit http://localhost:8085/user/save Go all the way to the ds1 master node
2: Visit http://localhost:8085/user/listuser Go all the way to the ds2 and ds3 nodes, and enter by polling.
6. Log view
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-hDTXYcoI-1630364981947)(E: \ note \ Typora \ crazy God \ kuangstudya68d24d6-5202-402f-9e96-26ca7e1fdb71.png)]


7. Summary
Review process
The main processes of data fragmentation of the three ShardingSphere products are completely consistent. The core consists of SQL parsing = > executor optimization = > sql routing = > sql rewriting = > sql execution = > result merging.
SQL parsing
It is divided into lexical analysis and grammatical analysis. First, the SQL is divided into non separable words through the lexical parser. Then use the syntax parser to understand SQL, and finally extract the parsing context. The parsing context includes tables, selections, sorting items, grouping items, aggregation functions, paging information, query criteria, and markers of placeholders that may need to be modified.
Actuator optimization
Merge and optimize segmentation conditions, such as OR, etc.
SQL routing
Match the partition policy configured by the user according to the resolution context, and generate a routing path. At present, fragment routing and broadcast routing are supported.
SQL rewrite
Rewrite SQL into statements that can be executed correctly in a real database. SQL rewriting is divided into correctness rewriting and optimization rewriting.
SQL execution
Asynchronous execution through a multithreaded actuator.
Result merging
Collect and merge multiple execution results to facilitate output through a unified JDBC interface. Result merging includes stream merging, memory merging and additional merging using decorator mode.
3. Other related configurations of Props
acceptor.size: # The number of threads connected by accept is twice the number of cpu cores by default executor.size: #Maximum number of working threads, default: unlimited max.connections.size.per.query: # The maximum number of connections that can be opened for each query. The default is 1 check.table.metadata.enabled: #Whether to check the metadata consistency of the split table at startup. The default value is false proxy.frontend.flush.threshold: # When the proxy service is used, for a single large query, how many network packets are returned once proxy.transaction.type: # By default, the transaction model of LOCAL and proxy allows three values: LOCAL, Xa and BASE. LOCAL has no distributed transaction, XA is a distributed transaction implemented by atomikos, and BASE has not been implemented yet proxy.opentracing.enabled: # Enable opentracing proxy.backend.use.nio: # Whether to use netty's NIO mechanism to connect to the back-end database. The default is False and epoll mechanism is used proxy.backend.max.connections: # If NIO is used instead of epoll, the maximum number of connections allowed per netty client for proxy background connection (note that it is not the database connection limit) is 8 by default proxy.backend.connection.timeout.seconds: #If nio is used instead of epoll, the timeout of proxy background connection is 60s by default
5, MySQL sub database and table principle
1. Why do you want to separate databases and tables
For ordinary machines (4-core 16G), if the MySQL concurrency (QPS+TPS) of a single database exceeds 2k, the system is basically finished. It is best to control the concurrency at about 1k. Here comes a question: why do you want to divide databases and tables?
Sub database and sub table purpose: to solve the problems of high concurrency and large amount of data.
1. In the case of high concurrency, it will cause frequent IO reading and writing, which will naturally cause slow reading and writing, or even downtime. Generally, a single database should not exceed 2k concurrency, except for NB machines.
2. Large amount of data. Mainly due to the implementation of the underlying index, MySQL's index is implemented as B+TREE, and the amount of other data will lead to a very large index tree and slow query. Second, the maximum storage limit of innodb is 64TB.
To solve the above problems. The most common method is to divide the database into tables.
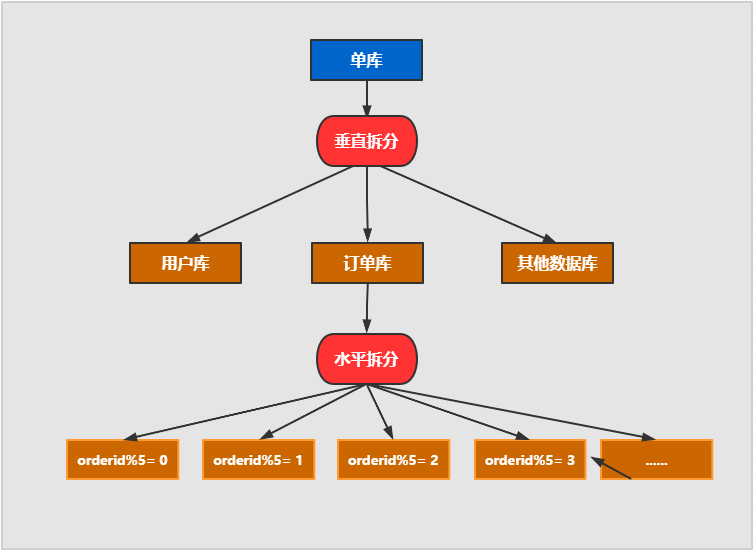
The purpose of database and table splitting is to split a table into N tables, so as to control the data volume of each table within a certain range and ensure the performance of SQL. It is recommended that the data of one table should not exceed 500W
2. Sub database and sub table
It is also divided into vertical split and horizontal split.
**Horizontal split: * * split the data of the same table into different tables in different libraries. It can be split according to time, region, or a business key dimension, or through hash. Finally, specific data can be accessed through routing. The structure of each table after splitting is consistent.
**Vertical split: * * is to split a table with many fields into multiple tables or libraries. The structure of each library table is different, and each library table contains some fields. Generally speaking, it can be split according to business dimensions. For example, the order table can be split into order, order support, order address, order goods, order extension and other tables; You can also split the data according to the cold and hot degree. 20% of the hot fields are split into one table and 80% of the cold fields are split into another table.
3. Non stop database and table data migration
Generally, there is a process to split a database. At first, it is a single table, and then it is slowly split into multiple tables. Then let's see how to smoothly transition from MySQL single table to MySQL sub database and sub table architecture.
1. mysql+canal is used for incremental data synchronization, and the database and table middleware is used to route the data to the corresponding new table.
2. Using the database and table middleware, the full amount of data is imported into the corresponding new table.
3. By comparing single table data with sub database and sub table data, the mismatched data is updated to the new table.
4. After the data is stable, switch the single table configuration to the sub database and sub table configuration.

4. Summary
Vertical splitting: business module splitting, commodity library, user library, and order library
Horizontal split: split the table horizontally (that is, split the table)
Vertical splitting of table: there are too many fields in the table, and the fields are used with different frequencies. (two tables can be split to establish a 1:1 relationship)
6, ShardingJdbc sub database and sub table
1. Method of dividing database and table
**Horizontal split: * * split the data of the same table into different tables in different libraries. It can be split according to time, region, or a business key dimension, or through hash. Finally, specific data can be accessed through routing. The structure of each table after splitting is consistent.
**Vertical split: * * is to split a table with many fields into multiple tables or libraries. The structure of each library table is different, and each library table contains some fields. Generally speaking, it can be split according to business dimensions. For example, the order table can be split into order, order support, order address, order goods, order extension and other tables; You can also split the data according to the cold and hot degree. 20% of the hot fields are split into one table and 80% of the cold fields are split into another table.
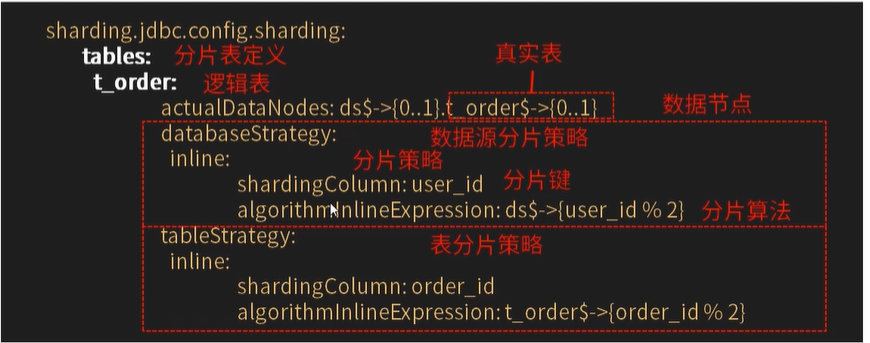
2. Logic table
Logical table refers to the general name of horizontally split database or data table and data structure table. For example, the user data is divided into two tables according to the user id%2: ksd_user0 and ksd_user1. Their logical table name is ksd_user.
The definition method in shardingjdbc is as follows:
spring:
shardingsphere:
sharding:
tables:
# ksd_user logical table name
ksd_user:
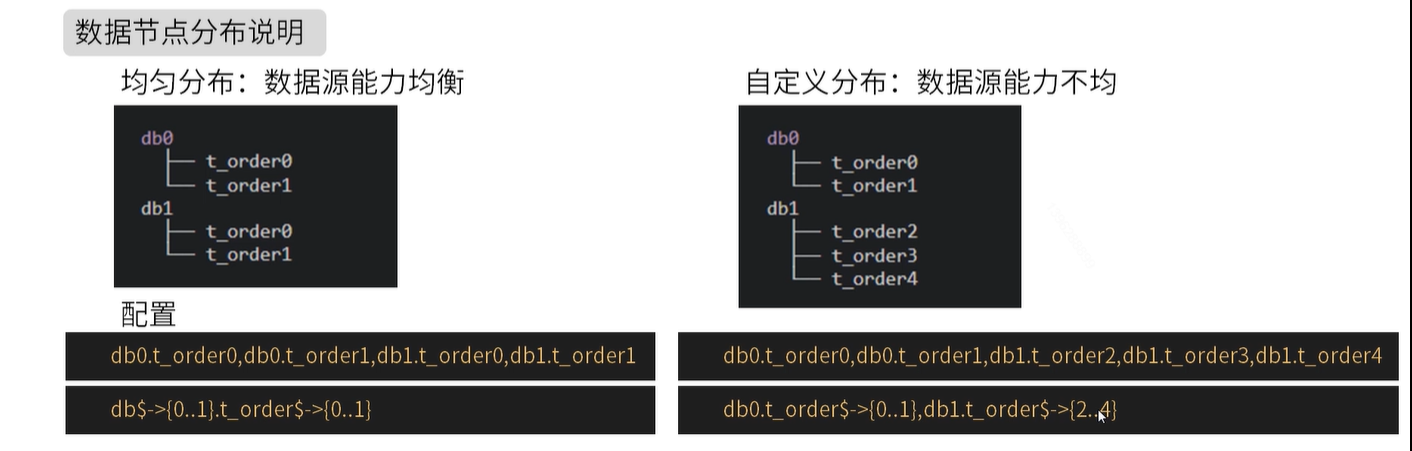
3. Database and table data nodes - actual data nodes
tables:
# ksd_user logical table name
ksd_user:
# Data node: multiple data sources $- > {0.. n} Logical table name $- > {0.. n} same table
actual-data-nodes: ds$->{0..2}.ksd_user$->{0..1}
# Data node: multiple data sources $- > {0.. n} Logical table name $- > {0.. n} is different
actual-data-nodes: ds0.ksd_user$->{0..1},ds1.ksd_user$->{2..4}
# Specifies how a single data source is configured
actual-data-nodes: ds0.ksd_user$->{0..4}
# Manually specify all
actual-data-nodes: ds0.ksd_user0,ds1.ksd_user0,ds0.ksd_user1,ds1.ksd_user1,
Data slicing is the smallest unit. It consists of data source name and data table, such as DS0 ksd_ user0.
The search rules are as follows:
4. Five partition strategies of database and table
There are two types of data source fragmentation:
- Data source fragmentation
- Surface slice
These two are fragmentation rules with different dimensions, but their usable fragmentation strategies and rules are the same. They consist of two parts:
- Slice key
- Partition algorithm
First: none
Corresponding to the non shardingstrategy, SQL will be sent to all nodes for execution without fragmentation policy. This rule has no sub items to configure.
The second: inline line expression time division strategy (core, must be mastered)
Corresponds to inlineshardingstrategy. When using Groovy expression, it supports the = and in fragment operations of SQL statements, and only supports single fragment keys. Simple sharding algorithms can be used through simple configuration to avoid cumbersome Java code opening, such as KSD_ The user ${partition key (data table field) userid% 5} indicates that the ksd_user table is divided into five tables according to the module 5 of a field (userid). The table names are ksd_user0 to ksd_user4. The same is true if the library.
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# Parameter configuration, display sql
props:
sql:
show: true
sharding:
# The default data source is mainly used for writing. Note that read-write separation must be configured. Note: if it is not configured, the three nodes will be regarded as slave nodes. Errors will occur in adding, modifying and deleting.
default-data-source-name: ds0
# Configure rules for split tables
tables:
# ksd_user logical table name
ksd_user:
# Data node: data source $- > {0.. n} Logical table name $- > {0.. n}
actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1}
# Split library strategy, that is, what kind of data is put into which database.
database-strategy:
inline:
sharding-column: sex # Slice field (slice key)
algorithm-expression: ds$->{sex % 2} # Fragment algorithm expression
# Split table strategy, that is, what kind of data is put into which data table.
table-strategy:
inline:
sharding-column: age # Slice field (slice key)
algorithm-expression: ksd_user$->{age % 2} # Fragment algorithm expression
Algorithm expression line expression:
- ${begin... end} indicates the interval range.
- ${[unit1,unit2,..., unitn]} represents the enumeration value.
- If there are multiple consecutive row expressions e x p r e s s s i o n or {expression} or Expression or - > {expression} expression. The final result of the whole expression will be Cartesian combined according to the result of each sub expression.

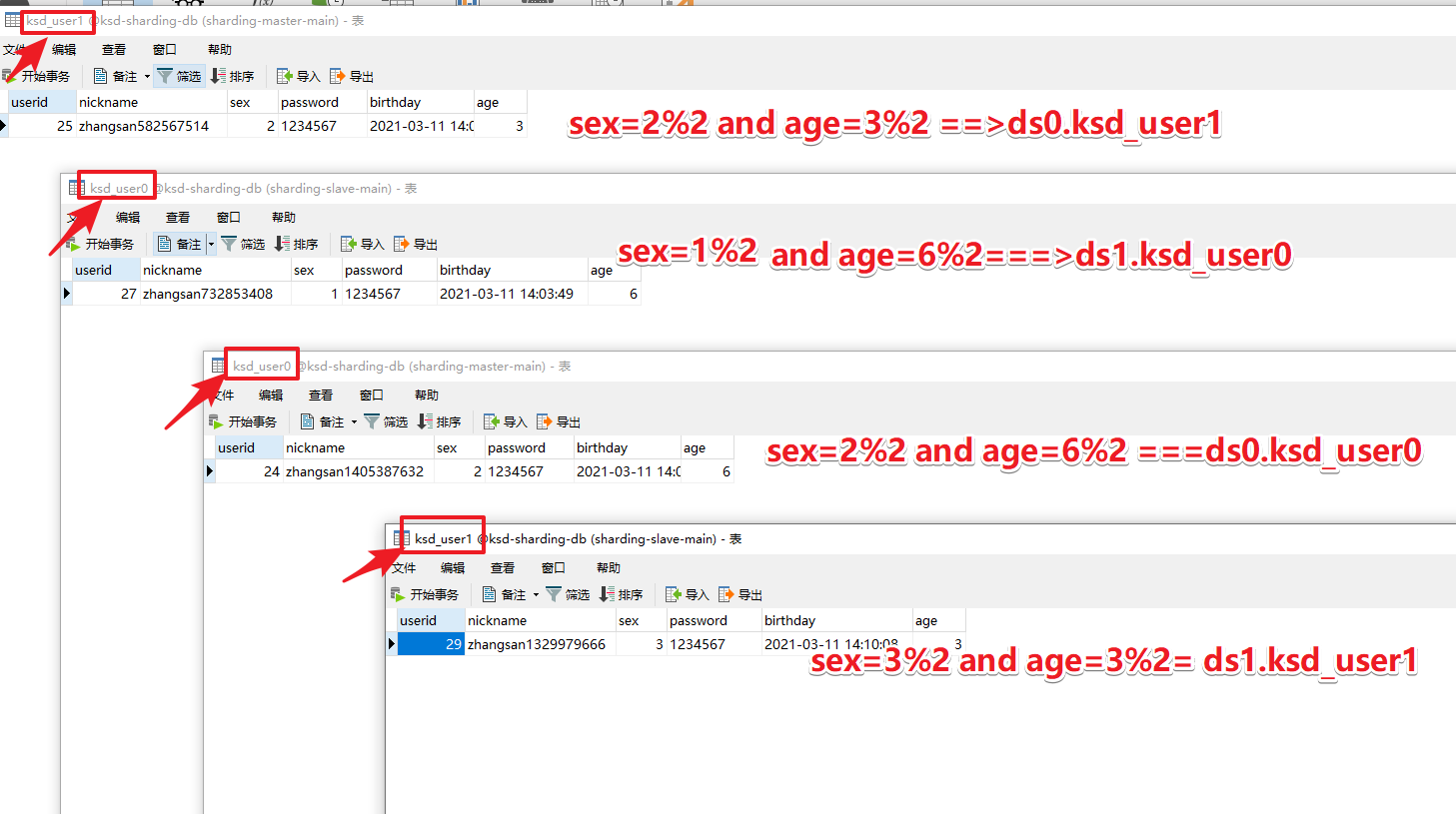
1. The complete case and configuration are as follows
- Prepare two databases ksd_sharding-db. Same name, two data sources ds0 and ds1
- KSD below each database_ User0 and ksd_user1 is enough.
- Database rules: even numbers of gender are put into ds0 library, and odd numbers are put into ds1 library.
- Data table rule: put even age into ksd_user0 library, odd number into ksd_user1 library.
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# Parameter configuration, display sql
props:
sql:
show: true
# Configure data sources
datasource:
# Alias each data source. DS1 and DS1 below can be named arbitrarily
names: ds0,ds1
# Configure database connection information for each data source of master-ds1
ds0:
# Configure druid data source
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.115.94.78:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure DS1 slave
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure default data source ds0
sharding:
# The default data source is mainly used for writing. Note that read-write separation must be configured. Note: if it is not configured, the three nodes will be regarded as slave nodes. Errors will occur in adding, modifying and deleting.
default-data-source-name: ds0
# Configure rules for split tables
tables:
# ksd_user logical table name
ksd_user:
# Data node: data source $- > {0.. n} Logical table name $- > {0.. n}
actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1}
# Split library strategy, that is, what kind of data is put into which database.
database-strategy:
inline:
sharding-column: sex # Slice field (slice key)
algorithm-expression: ds$->{sex % 2} # Fragment algorithm expression
# Split table strategy, that is, what kind of data is put into which data table.
table-strategy:
inline:
sharding-column: age # Slice field (slice key)
algorithm-expression: ksd_user$->{age % 2} # Fragment algorithm expression
# Integrate mybatis configuration XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.xuexiangban.shardingjdbc.entity
The results are as follows:
5. The third method is to divide the database and table according to the actual time and date - according to the standard rules
1. Standard slice - Standard
- Corresponding to stratardshardingstrategy Provides fragment operation support for =, in and between and in SQL statements.
- The stratardshardingstrategy only supports sharding keys. Two slicing algorithms, PreciseShardingAlgorithm and RangeShardingAlgorithm, are provided.
- Precision shardingalgorithm is required. Er, it is used to process the fragments of = and IN
- And RangeShardingAlgorithm are optional and are used to process Betwwen and sharding. If and RangeShardingAlgorithm are not configured, SQL Between AND will be processed according to the full database route.
2. Define the date rule configuration of the slice
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# Parameter configuration, display sql
props:
sql:
show: true
# Configure data sources
datasource:
# Alias each data source. DS1 and DS1 below can be named arbitrarily
names: ds0,ds1
# Configure database connection information for each data source of master-ds1
ds0:
# Configure druid data source
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.115.94.78:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT%2b8
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure DS1 slave
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT%2b8
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure default data source ds0
sharding:
# The default data source is mainly used for writing. Note that read-write separation must be configured. Note: if it is not configured, the three nodes will be regarded as slave nodes. Errors will occur in adding, modifying and deleting.
default-data-source-name: ds0
# Configure rules for split tables
tables:
# ksd_user logical table name
ksd_user:
# Data node: data source $- > {0.. n} Logical table name $- > {0.. n}
actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1}
# Split library strategy, that is, what kind of data is put into which database.
database-strategy:
standard:
shardingColumn: birthday
preciseAlgorithmClassName: com.xuexiangban.shardingjdbc.algorithm.BirthdayAlgorithm
table-strategy:
inline:
sharding-column: age # Slice field (slice key)
algorithm-expression: ksd_user$->{age % 2} # Fragment algorithm expression
# Integrate mybatis configuration XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.xuexiangban.shardingjdbc.entity
3. Define the date rule of the slice
package com.xuexiangban.shardingjdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import sun.util.resources.cldr.CalendarData;
import java.util.*;
/**
* @author: Learning companion - flying brother
* @description: BirthdayAlgorithm
* @Date : 2021/3/11
*/
public class BirthdayAlgorithm implements PreciseShardingAlgorithm<Date> {
List<Date> dateList = new ArrayList<>();
{
Calendar calendar1 = Calendar.getInstance();
calendar1.set(2020, 1, 1, 0, 0, 0);
Calendar calendar2 = Calendar.getInstance();
calendar2.set(2021, 1, 1, 0, 0, 0);
Calendar calendar3 = Calendar.getInstance();
calendar3.set(2022, 1, 1, 0, 0, 0);
dateList.add(calendar1.getTime());
dateList.add(calendar2.getTime());
dateList.add(calendar3.getTime());
}
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {
// Gets the value of the property database
Date date = preciseShardingValue.getValue();
// Gets the name information list of the data source
Iterator<String> iterator = collection.iterator();
String target = null;
for (Date s : dateList) {
target = iterator.next();
// If the data is later than the specified date, it is returned directly
if (date.before(s)) {
break;
}
}
return target;
}
}
4. Test view results
http://localhost:8085/user/save?sex=3&age=3&birthday=2020-03-09 —- ds1
http://localhost:8085/user/save?sex=3&age=3&birthday=2021-03-09 —- ds0
6. Fourth: ShardingSphere - comply with the fragmentation strategy (understand)
- Corresponding interface: HintShardingStrategy. The strategy of sharding through Hint rather than SQL parsing.
- For scenarios where the fragment field is not determined by SQL, but by other external conditions, we can use SQL hint to inject the fragment field flexibly. For example, the database is divided according to the user's login time, primary key, etc., but there is no such field in the database. SQL hint can be used through Java API and SQL annotation. Make the rear sub database and sub table more flexible.

7. Fifth: ShardingSphere - hint fragmentation strategy (understand)
- Corresponds to the ComplexShardingStrategy. It complies with the sharding policy and provides support for the sharding operation of -, in, between and in SQL statements.
- Complex shardingstrategy supports multi sharding keys. Due to the complex relationship between multi sharding keys, it does not carry out too much encapsulation. Instead, it directly transmits the sharding key combination and sharding operator to the sharding algorithm, which is completely implemented by the developer, providing maximum flexibility.

7, ShardingSphere - distributed primary key configuration
1. ShardingSphere - distributed primary key configuration
ShardingSphere provides a flexible way to configure distributed primary key generation strategies. Configure the primary key generation strategy of each table in the partition rule configuration module. The snowflake algorithm is used by default. (snowflake) generates 64bit long integer data. Two configurations are supported
- SNOWFLAKE
- UUID
Remember here: the primary key column cannot grow by itself. The data type is bigint(20)
spring:
shardingsphere:
sharding:
tables:
# ksd_user logical table name
ksd_user:
key-generator:
# List of primary keys,
column: userid
type: SNOWFLAKE
implement
http://localhost:8085/user/save?sex=3&age=3&birthday=2020-03-09
You can see that the new statement has a unique value with userid 576906137413091329. This value is the only value calculated by the snowflake algorithm
2021-03-11 22:59:01.605 INFO 4900 --- [nio-8085-exec-1] ShardingSphere-SQL : Actual SQL: ds1 ::: insert into ksd_user1 (nickname, password, sex, age, birthday, userid) VALUES (?, ?, ?, ?, ?, ?) ::: [zhangsan-70137485, 1234567, 3, 3, 2020-03-09 00:00:00.0, 576906137413091329]

8, ShardingSphere - sub database and sub table - case of month and year
The actual combat is completed according to the month, month, warehouse and table.
1. Policy class
package com.xuexiangban.shardingjdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class YearMonthShardingAlgorithm implements PreciseShardingAlgorithm<String> {
private static final String SPLITTER = "_";
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
String tbName = shardingValue.getLogicTableName() + "_" + shardingValue.getValue();
System.out.println("Sharding input:" + shardingValue.getValue() + ", output:{}" + tbName);
return tbName;
}
}
2,entity
package com.xuexiangban.shardingjdbc.entity;
import lombok.Data;
import java.util.Date;
/**
* @author: Learning companion - flying brother
* @description: User
* @Date : 2021/3/10
*/
@Data
public class Order {
// Primary key
private Long orderid;
// Order No
private String ordernumber;
// User ID
private Long userid;
// Product id
private Long productid;
// Creation time
private Date createTime;
}
3,mapper
package com.xuexiangban.shardingjdbc.mapper;
import com.xuexiangban.shardingjdbc.entity.Order;
import com.xuexiangban.shardingjdbc.entity.UserOrder;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.springframework.stereotype.Repository;
/**
* @author: Learning companion - flying brother
* @description: UserMapper
* @Date : 2021/3/10
*/
@Mapper
@Repository
public interface UserOrderMapper {
/**
* @author Learning companion - flying brother
* @description Save order
* @params [user]
* @date 2021/3/10 17:14
*/
@Insert("insert into ksd_user_order(ordernumber,userid,create_time,yearmonth) values(#{ordernumber},#{userid},#{createTime},#{yearmonth})")
@Options(useGeneratedKeys = true,keyColumn = "orderid",keyProperty = "orderid")
void addUserOrder(UserOrder userOrder);
}
4. The configuration is as follows:
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# Parameter configuration, display sql
props:
sql:
show: true
# Configure data sources
datasource:
# Alias each data source. DS1 and DS1 below can be named arbitrarily
names: ds0,ds1
# Configure database connection information for each data source of master-ds1
ds0:
# Configure druid data source
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.115.94.78:3306/ksd_order_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT%2b8
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# Configure DS1 slave
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/ksd_order_db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT%2b8
username: root
password: mkxiaoer
maxPoolSize: 100
minPoolSize: 5
# Configure default data source ds0
sharding:
# The default data source is mainly used for writing. Note that read-write separation must be configured. Note: if it is not configured, the three nodes will be regarded as slave nodes. Errors will occur in adding, modifying and deleting.
default-data-source-name: ds0
# Configure rules for split tables
tables:
# ksd_user logical table name
ksd_user:
key-generator:
column: id
type: SNOWFLAKE
# Data node: data source $- > {0.. n} Logical table name $- > {0.. n}
actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1}
# Split library strategy, that is, what kind of data is put into which database.
database-strategy:
standard:
shardingColumn: birthday
preciseAlgorithmClassName: com.xuexiangban.shardingjdbc.algorithm.BirthdayAlgorithm
table-strategy:
inline:
sharding-column: age # Slice field (slice key)
algorithm-expression: ksd_user$->{age % 2} # Fragment algorithm expression
ksd_order:
# Data node: data source $- > {0.. n} Logical table name $- > {0.. n}
actual-data-nodes: ds0.ksd_order$->{0..1}
key-generator:
column: orderid
type: SNOWFLAKE
# Split library strategy, that is, what kind of data is put into which database.
table-strategy:
inline:
sharding-column: orderid # Slice field (slice key)
algorithm-expression: ksd_order$->{orderid % 2} # Fragment algorithm expression
ksd_user_order:
# Data node: data source $- > {0.. n} Logical table name $- > {0.. n}
actual-data-nodes: ds0.ksd_user_order_$->{2021..2022}${(1..3).collect{t ->t.toString().padLeft(2,'0')} }
key-generator:
column: orderid
type: SNOWFLAKE
# Split library strategy, that is, what kind of data is put into which database.
table-strategy:
# inline:
# shardingColumn: yearmonth
# algorithmExpression: ksd_user_order_$->{yearmonth}
standard:
shardingColumn: yearmonth
preciseAlgorithmClassName: com.xuexiangban.shardingjdbc.algorithm.YearMonthShardingAlgorithm
# Integrate mybatis configuration XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.xuexiangban.shardingjdbc.entity
5,test
package com.xuexiangban.shardingjdbc;
import com.xuexiangban.shardingjdbc.entity.Order;
import com.xuexiangban.shardingjdbc.entity.User;
import com.xuexiangban.shardingjdbc.entity.UserOrder;
import com.xuexiangban.shardingjdbc.mapper.UserOrderMapper;
import com.xuexiangban.shardingjdbc.service.UserOrderService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Random;
@SpringBootTest
class ShardingJdbcApplicationTests {
@Autowired
private UserOrderService userOrderService;
@Test
void contextLoads() throws Exception {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("1234567");
user.setSex(1);
user.setAge(2);
user.setBirthday(new Date());
Order order = new Order();
order.setCreateTime(new Date());
order.setOrdernumber("133455678");
order.setProductid(1234L);
userOrderService.saveUserOrder(user, order);
}
@Autowired
private UserOrderMapper userOrderMapper;
@Test
public void orderyearMaster() {
UserOrder userOrder = new UserOrder();
userOrder.setOrderid(10000L);
userOrder.setCreateTime(new Date());
userOrder.setOrdernumber("133455678");
userOrder.setYearmonth("202103");
userOrder.setUserid(1L);
userOrderMapper.addUserOrder(userOrder);
}
}
9, Transaction management of ShardingJdbc
1. Application and practice of distributed transaction
Official address: https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/transaction/function/base-transaction-seata/
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/usage/transaction/
Database transactions need to meet the four characteristics of ACID (atomicity, consistency, isolation and persistence).
- Atomicity means that transactions are executed as a whole, either all or none.
- Consistency refers to ensuring that data changes from one consistent state to another.
- Isolation means that when multiple transactions are executed concurrently, the execution of one transaction should not affect the execution of other transactions.
- Durability means that the submitted transaction modification data will be persisted.
In a single data node, transactions are limited to the access control of a single database resource, which is called local transactions. Almost all mature relational databases provide native support for local transactions. However, in the distributed application environment based on microservices, more and more application scenarios require the access to multiple services and their corresponding multiple database resources to be included in the same transaction, so the distributed transaction came into being.
Relational databases provide perfect ACID native support for local transactions. However, in the distributed scenario, it has become a shackle of system performance. How to make the database meet the characteristics of ACID or find corresponding alternatives in distributed scenarios is the key work of distributed transactions.
Local transaction
Let each data node manage its own transactions without starting any distributed transaction manager. They do not have the ability to coordinate and communicate with each other, nor do they know the success of other data node transactions. Local transactions have no performance loss, but they are weak in strong consistency and final consistency.
Two stage submission
The earliest distributed transaction model of XA protocol is the X/Open Distributed Transaction Processing (DTP) model proposed by X/Open international alliance, which is called XA protocol for short.
The distributed transaction based on XA protocol has little business intrusion. Its biggest advantage is that it is transparent to users. Users can use distributed transactions based on XA protocol like local transactions. Xa protocol can strictly guarantee the transaction ACID feature.
Strictly guaranteeing the ACID feature of transactions is a double-edged sword. All required resources need to be locked during transaction execution, which is more suitable for short transactions with definite execution time. For long transactions, the monopolization of data during the whole transaction will lead to the obvious decline of concurrency performance of business systems that depend on hot data. Therefore, in the high concurrency performance first scenario, the distributed transaction based on XA protocol is not the best choice.
Flexible transaction
If a transaction that implements a transaction element of ACID is called a rigid transaction, a transaction based on a BASE transaction element is called a flexible transaction. BASE is the abbreviation of basic availability, flexible state and final consistency.
Basically Available ensures that distributed transaction participants are not necessarily online at the same time.
Soft state allows the system status update to have a certain delay, which may not be perceived by the customer.
However, the final consistency of the system is usually guaranteed by message passing.
In ACID transactions, isolation is highly required. All resources must be locked during transaction execution. The concept of flexible transaction is to move the mutex operation from the resource level to the business level through business logic. By relaxing the requirements for strong consistency, the system throughput can be improved.
Strong consistency transaction based on ACID and final consistency transaction based on BASE are not silver bullets. Their greatest strengths can be brought into play only in the most suitable scenario. The differences between them can be compared in detail in the following table to help developers select technology.

2. Case
1: Import dependencies for distributed transactions
<!--rely on sharding-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
2: Several types of transactions
Local transaction
- Non cross database transactions are fully supported, for example, only sub tables or sub databases, but the routing results are in a single database.
- Cross database transactions caused by logical exceptions are fully supported. For example, in the same transaction, update across two libraries. After the update, throw a null pointer, and the contents of both libraries can be rolled back.
- Cross database transactions caused by network and hardware exceptions are not supported. For example, if two databases are updated in the same transaction, and the first database goes down after the update is completed and before it is committed, only the data of the second database is committed.
Two phase XA transaction
- Supports cross database XA transactions after data fragmentation
- Two stage commit ensures atomicity of operation and strong consistency of data
- After service downtime and restart, transactions in commit / rollback can be recovered automatically
- SPI mechanism integrates the mainstream XA transaction manager, Atomikos by default, and Narayana and Bitronix can be selected
- Both Xa and non XA connection pools are supported
- Provide access terminals for spring boot and namespace
I won't support it:
- After the service is down, restore the data in commit / rollback on other machines
Seata flexible transaction
- Fully supports cross database distributed transactions
- Support RC isolation level
- Transaction rollback via undo snapshot
- Support automatic recovery of committed transactions after service downtime
Dependency:
- Additional Seata server services need to be deployed to coordinate branch transactions
Items to be optimized - ShardingSphere and Seata will parse SQL repeatedly
3: service code writing
package com.xuexiangban.shardingjdbc.service;
import com.xuexiangban.shardingjdbc.entity.Order;
import com.xuexiangban.shardingjdbc.entity.User;
import com.xuexiangban.shardingjdbc.mapper.OrderMapper;
import com.xuexiangban.shardingjdbc.mapper.UserMapper;
import io.shardingsphere.transaction.annotation.ShardingTransactionType;
import io.shardingsphere.transaction.api.TransactionType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
/**
* @author: Learning companion - flying brother
* @description: UserService
* @Date : 2021/3/14
*/
@Service
public class UserOrderService {
@Autowired
private UserMapper userMapper;
@Autowired
private OrderMapper orderMapper;
@ShardingTransactionType(TransactionType.XA)
@Transactional(rollbackFor = Exception.class)
public int saveUserOrder(User user, Order order) {
userMapper.addUser(user);
order.setUserid(user.getId());
orderMapper.addOrder(order);
//int a = 1/0; // If the test is rolled back and submitted uniformly, just comment out this line
return 1;
}
}
test
package com.xuexiangban.shardingjdbc;
import com.xuexiangban.shardingjdbc.entity.Order;
import com.xuexiangban.shardingjdbc.entity.User;
import com.xuexiangban.shardingjdbc.entity.UserOrder;
import com.xuexiangban.shardingjdbc.mapper.UserOrderMapper;
import com.xuexiangban.shardingjdbc.service.UserOrderService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Random;
@SpringBootTest
class ShardingJdbcApplicationTests {
@Autowired
private UserOrderService userOrderService;
@Test
void contextLoads() throws Exception {
User user = new User();
user.setNickname("zhangsan" + new Random().nextInt());
user.setPassword("1234567");
user.setSex(1);
user.setAge(2);
user.setBirthday(new Date());
Order order = new Order();
order.setCreateTime(new Date());
order.setOrdernumber("133455678");
order.setProductid(1234L);
userOrderService.saveUserOrder(user, order);
}
}
10, ShardingJdbc summary
1. Basic specification
- The table must have a primary key. It is recommended to use integer as the primary key
- The use of foreign keys is prohibited. The association and integrity between tables are controlled through the application layer
- At the beginning of table design, the approximate data level shall be considered. If the table record is less than 1000W, single table shall be used as far as possible, and separate tables are not recommended.
- It is recommended to split large fields with low access frequency or fields that do not need to be used as filter criteria into expanded tables (do a good job in vertical table splitting)
- Control the total number of single instance tables, and control the number of sub tables of a single table within 1024.
2. Column design specification
- Correctly distinguish the range of tinyint, int and bigint
- Use varchar(20) to store the phone number, not an integer
- Use int to store ipv4 instead of char(15)
- Use decimal/varchar for the amount involved, and formulate the accuracy
- Instead of designing null fields, use empty characters, because null requires more space and makes indexing and statistics more complex.
3. Index specification
- The unique index uses uniq_ [field name]
- Use idx for non unique indexes_ [field name]
- Indexing on frequently updated fields is not recommended
- It is not necessary to join. If you want to join query, the joined fields must be of the same type and indexed.
- It is recommended that the number of indexes in a single table be controlled within 5. Too many indexes will not only reduce the performance of insert update, but also cause MYSQL index errors and performance degradation
- The number of combined index fields should not exceed 5. Understand the leftmost matching principle of combined index and avoid repeated index construction. For example, you established
(x,y,z) is equivalent to (x),(x,y),(x,y,z)
4. SQL specification
- It is forbidden to use selet and only get the necessary fields. select will increase the consumption of cpu/i0 / memory and bandwidth.
- insert must specify a field. insert into Table values() is prohibited The specified field insertion can ensure that the corresponding application will not be affected when the table result changes.
- Privacy type conversion will invalidate the index and cause a full table scan. (for example, the mobile phone number is not converted into a string during search)
- It is forbidden to use built-in functions or expressions in the query column after where, resulting in failure to hit the index and full table scanning
- Negative queries (! =, not like, no in, etc.) and fuzzy queries beginning with% are prohibited, resulting in failure to hit the index and full table scanning
- To avoid memory overflow caused by directly returning large result sets, segmentation and cursor methods can be adopted.
- When returning the result set, try to use limit paging display.
- Try to create an index on the order by/group by column.
- Large table scanning shall be done on the image library as far as possible
- Prohibit large table join queries and subqueries
- Try to avoid database built-in functions as query conditions
- The application tries to catch SQL exceptions
5. Vertical split of table
Vertical splitting: business module splitting, commodity library, user library, and order library
Horizontal split: split the table horizontally (that is, split the table)
Vertical splitting of table: there are too many fields in the table, and the fields are used with different frequencies. (two tables can be split to establish a 1:1 relationship)
- Divide a table with too many attributes and a table with a large row of data into different database tables. To reduce the size of a single library table.
characteristic: - The structure of each table is inconsistent
- The quantity of each table is the total quantity
- There must be a column associated between tables, usually a primary key
principle:
- The fields with shorter length and higher access frequency are placed in one table, the main table
- Put the fields with long length and low access frequency into a table
- Place frequently accessed fields in a table.
- The union of all tables is full data.
6. How to add fields smoothly
Scenario: during development, it is sometimes necessary to add fields to the table. How to add fields smoothly in the case of large amount of data and separate tables.
-
Directly alter table add column. It is not recommended when there is a large amount of data (write lock will be generated)
alter table ksd_user add column api_pay_no varchar(32) not null comment 'User extended order number'alter table ksd_user add column api_pay_no varchar(32) not null unique comment 'User extended order number'
-
Reserve fields in advance (not elegant: it causes a waste of space, the reserved amount is difficult to control, and the expansibility is poor)
-
Add a new table (add fields), migrate the data of the original table, and rename the new table as the original table.
-
Put in extinfo (cannot use index)
-
Design in advance and use the key/value method to store. When adding new fields, just add a key directly (elegant)
11, Springboot integrates shardingjdbc3 0 and case studies
target
Use sharding JDBC sub database and sub table to master what sharding JDBC is
analysis
What is sharding JDBC
Sharding JDBC provides standardized data fragmentation, distributed transaction and database governance functions. It is positioned as a lightweight Java framework and provides additional services in the JDBC layer of Java. It uses the client to directly connect to the database and provides services in the form of jar package without additional deployment and dependency. It can be understood as an enhanced jdbc driver and is fully compatible with JDBC and various ORM frameworks. It is applicable to any Java based ORM framework, such as JPA, Hibernate, Mybatis, Spring JDBC Template or directly using JDBC.
Database connection pool based on any third party, such as DBCP, C3P0, BoneCP, Druid, HikariCP, etc.
Support any database that implements JDBC specification. Currently, MySQL, Oracle, SQL server and PostgreSQL are supported.
2. Why do you want to slice?
- The traditional solution of centralized storage of data to a single data node has been difficult to meet the massive data scenario of the Internet in terms of performance, availability and operation and maintenance cost.
- In terms of performance, most relational databases use B + tree indexes. When the amount of data exceeds the threshold, the increase of index depth will also increase the IO times of disk access, resulting in the decline of query performance; At the same time, high concurrent access requests also make the centralized database the biggest bottleneck of the system.
- In terms of availability, the service-oriented stateless type can achieve random capacity expansion at a small cost, which will inevitably lead to the final pressure of the system falling on the database. A single data node, or a simple master-slave architecture, has become more and more difficult to bear. The availability of database has become the key of the whole system.
- In terms of operation and maintenance cost, when the data in a database instance reaches above the threshold, the operation and maintenance pressure on DBA will increase. The time cost of data backup and recovery will become more and more uncontrollable with the amount of data. Generally speaking, the data threshold of a single database instance is within 1TB, which is a reasonable range.
- When the traditional relational database can not meet the needs of Internet scenarios, there are more and more attempts to store data in native NoSQL that supports distributed. However, the incompatibility of NoSQL with SQL and the imperfection of ecosystem make them unable to complete a fatal blow in the game with relational database, while the status of relational database is still unshakable.
- According to fragmentation, the data stored in a single database is stored in multiple databases or tables according to a certain dimension, so as to improve the performance bottleneck and availability. The effective means of data fragmentation is to divide the relational database into database and table. Both sub database and sub table can effectively avoid the query bottleneck caused by the amount of data exceeding the acceptable threshold. In addition, the sub database can also be used to effectively disperse the access to a single point of the database; Although split tables can not relieve the pressure on the database, they can provide the possibility to transform distributed transactions into local transactions as much as possible. Once cross database update operations are involved, distributed transactions often complicate the problem. Using multi master and multi slave fragmentation can effectively avoid single point of data, so as to improve the availability of data architecture.
- Splitting the data by database and table to keep the data volume of each table below the threshold, and dredge the traffic to deal with the high traffic is an effective means to deal with the high concurrency and massive data system.
3. Slicing method
Data fragmentation can be divided into vertical fragmentation and horizontal fragmentation.
Vertical splitting is to split different tables into different databases, "Horizontal splitting is to split the same table into different databases (or split a table data into n multiple small tables). Compared with vertical splitting, horizontal splitting does not classify the table data, but distributes it into multiple databases according to certain rules of a certain field, and each table contains part of the data. In short, we can understand the horizontal segmentation of data as * * segmentation according to data rows * *, that is, splitting some data in the table Rows are segmented into one database, while some other rows are segmented into other databases. There are two modes: table splitting and database splitting. This mode improves the stability and load capacity of the system, but the performance of cross database join is poor.
4: Core / working principle of sharding JDBC
The main process of sharding JDBC data fragmentation is composed of SQL parsing → actuator optimization → SQL routing → SQL rewriting → SQL execution → result merging.
SQL parsing
It is divided into lexical analysis and grammatical analysis. First, the SQL is divided into non separable words through the lexical parser. Then use the syntax parser to understand SQL, and finally extract the parsing context. The parsing context includes tables, selections, sorting items, grouping items, aggregation functions, paging information, query criteria, and markers of placeholders that may need to be modified.
SQL parsing is divided into two steps. The first step is lexical parsing, which means splitting SQL.
Example:
select from t_user where id = 1
Lexical analysis:
[select] [] [from] [t_user] [where] [id=1]
The second step is syntax parsing. The syntax parser converts SQL into an abstract syntax tree.
Actuator optimization
Merge and optimize segmentation conditions, such as OR, etc.
SQL routing
Match the partition policy configured by the user according to the resolution context, and generate a routing path. At present, fragment routing and broadcast routing are supported.
For example, if you follow order_ The odd and even numbers of ID are used for data fragmentation. The SQL of a single table query is as follows:
SELECT FROM t_order WHERE order_id IN (1, 2);
Then the result of routing should be:
SELECT FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
SQL rewrite
Rewrite SQL into statements that can be executed correctly in a real database. SQL rewriting is divided into correctness rewriting and optimization rewriting.
Start with the simplest example, if logic SQL Is: SELECT order_id FROM t_order WHERE order_id=1; Suppose this SQL Configure slice key order_id,also order_id=1 In this case, it will be routed to fragment Table 1. So after rewriting SQL Should be: SELECT order_id FROM t_order_1 WHERE order_id=1;
SQL execution
Asynchronous execution through a multithreaded actuator.
Result merging
Collect and merge multiple execution results to facilitate output through a unified JDBC interface. Result merging includes stream merging, memory merging and additional merging using decorator mode.
SharedingJdbc completes the read-write separation of data
target
Use sharing JDBC to complete the database database and table splitting business
step
1: Create a new springboot project
2: Create two databases order1 and order2, and create t respectively_ The address table is as follows:
DROP TABLE IF EXISTS `t_address`; CREATE TABLE `t_address` ( `id` bigint(20) NOT NULL, `code` varchar(64) DEFAULT NULL COMMENT 'code', `name` varchar(64) DEFAULT NULL COMMENT 'name', `pid` varchar(64) NOT NULL DEFAULT '0' COMMENT 'father id', `type` int(11) DEFAULT NULL COMMENT '1 National 2 provinces, 3 cities, 4 counties and districts', `lit` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
**3: Start integrating SpringBoot, * * this method is relatively simple. Just add the sharding JDBC spring boot starter dependency in application The data source is configured in YML, and the fragmentation strategy can be used. This method is simple and convenient. pom.xml
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.0.0</version>
</dependency>
appplication.yml
mybatis:
configuration:
mapUnderscoreToCamelCase: true
spring:
main:
allow-bean-definition-overriding: true
# Sharding JDBC sub database and sub table
sharding:
jdbc:
datasource:
names: ds0,ds1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/order1?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false
username: root
password: root
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/order2?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false
username: root
password: root
config:
sharding:
props:
sql.show: true
tables:
t_user: #t_user table [sub database and sub table]
key-generator-column-name: id # Primary key
actual-data-nodes: ds${0..1}.t_user${0..1} #Data node
database-strategy: #Sub database strategy
inline:
sharding-column: city_id
algorithm-expression: ds${city_id % 2}
table-strategy: #Table splitting strategy
inline:
shardingColumn: sex
algorithm-expression: t_user${sex % 2}
t_address: #t_address table [sub database only]
key-generator-column-name: id
actual-data-nodes: ds${0..1}.t_address
database-strategy:
inline:
shardingColumn: lit
algorithm-expression: ds${lit % 2}
4: Write Vo
package com.itheima.springbootshardingpro.vo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
public class AddressVo {
private Long id;
private String code;
private String name;
private String pid;
private Integer type;
private Integer lit;
}
5: Write Dao
package com.itheima.springbootshardingpro.dao;
import com.itheima.springbootshardingpro.vo.AddressVo;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface IndexDao {
@Options(useGeneratedKeys = true)
@Insert("insert into t_address (code,name,pid,type,lit)values(#{code},#{name},#{pid},#{type},#{lit})")
int insertAddress(AddressVo addressVo);
@Select("select * from t_address order by lit")
List<AddressVo> listAddress();
}
6: Write controller
package com.itheima.springbootshardingpro.web;
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
import com.itheima.springbootshardingpro.dao.IndexDao;
import com.itheima.springbootshardingpro.vo.AddressVo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class IndexController {
@Autowired
private IndexDao indexDao;
@PostMapping("/addAddress")
public int addAddress(AddressVo addressVo){
int row = indexDao.insertAddress(addressVo);
return row;
}
@GetMapping("/listAddress")
public PageInfo<AddressVo> listAddress(@RequestParam(required=false,defaultValue="1")Integer pageNum,
@RequestParam(required=false,defaultValue="5")Integer pageSize){
PageHelper.startPage(pageNum,pageSize);
List<AddressVo> list = indexDao.listAddress();
PageInfo<AddressVo> info = new PageInfo<>(list);
return info;
}
}
hardingpro.dao;
import com.itheima.springbootshardingpro.vo.AddressVo;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Select;
import java.util.List;
@Mapper
public interface IndexDao {
@Options(useGeneratedKeys = true)
@Insert("insert into t_address (code,name,pid,type,lit)values(#{code},#{name},#{pid},#{type},#{lit})")
int insertAddress(AddressVo addressVo);
@Select("select * from t_address order by lit")
List listAddress();
}
**6: to write controller**
```java
package com.itheima.springbootshardingpro.web;
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
import com.itheima.springbootshardingpro.dao.IndexDao;
import com.itheima.springbootshardingpro.vo.AddressVo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class IndexController {
@Autowired
private IndexDao indexDao;
@PostMapping("/addAddress")
public int addAddress(AddressVo addressVo){
int row = indexDao.insertAddress(addressVo);
return row;
}
@GetMapping("/listAddress")
public PageInfo<AddressVo> listAddress(@RequestParam(required=false,defaultValue="1")Integer pageNum,
@RequestParam(required=false,defaultValue="5")Integer pageSize){
PageHelper.startPage(pageNum,pageSize);
List<AddressVo> list = indexDao.listAddress();
PageInfo<AddressVo> info = new PageInfo<>(list);
return info;
}
}
At this point, start the project and use postman to access and insert the interface: