The X-Pack Spark service provides Redis, Cassandra, MongoDB, HBase and RDS storage services with the ability of complex analysis, streaming processing, warehousing and machine learning through external computing resources, so as to better solve user data processing related scenario problems.
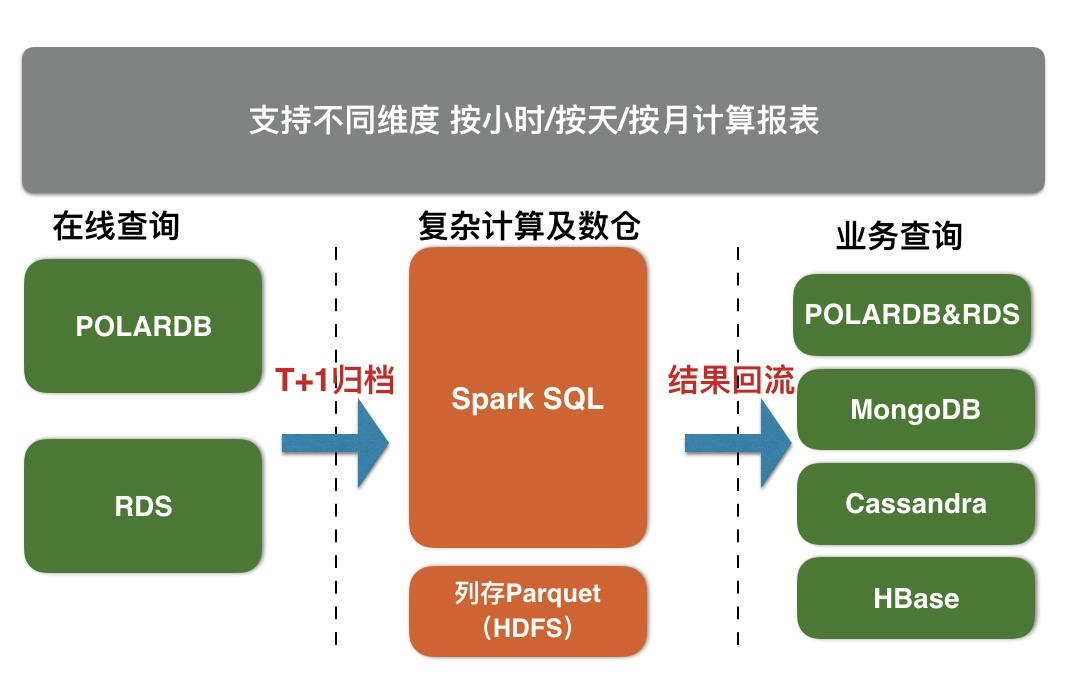
RDS & polardb sub table archiving to X-Pack Spark steps
One click Association of POLARDB to Spark cluster
One key association is mainly to prepare spark to access RDS & polardb.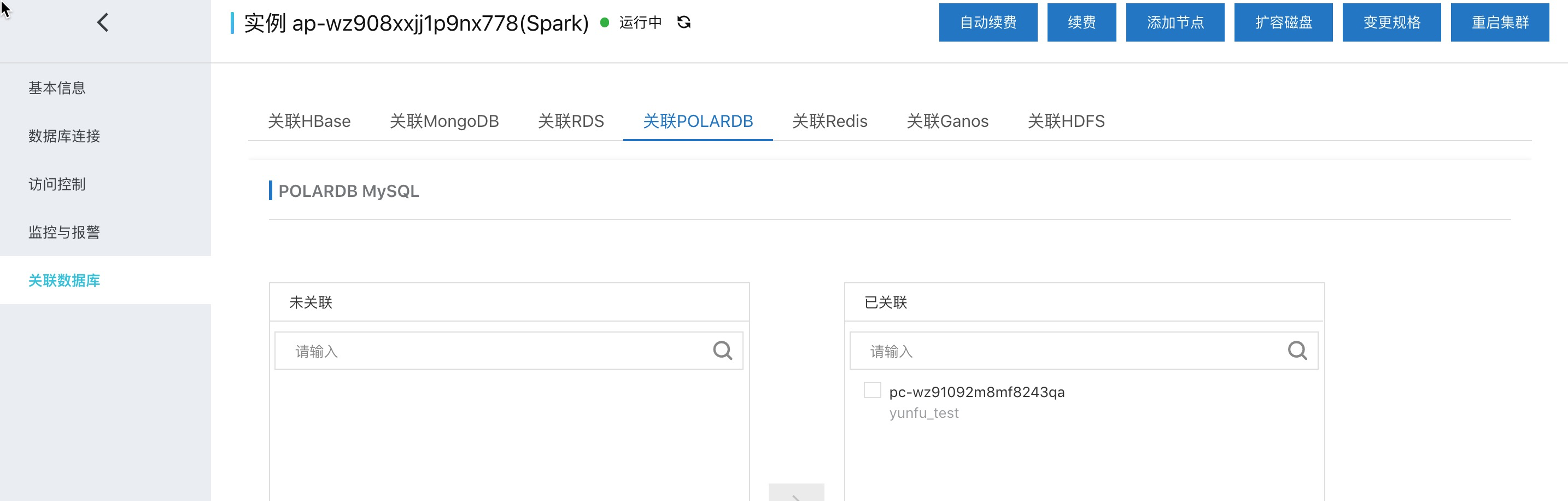
POLARDB table storage
In database 'test1', a table is generated every 5 minutes. Here, it is assumed that the tables' test1 ',' test2 ',' test2 '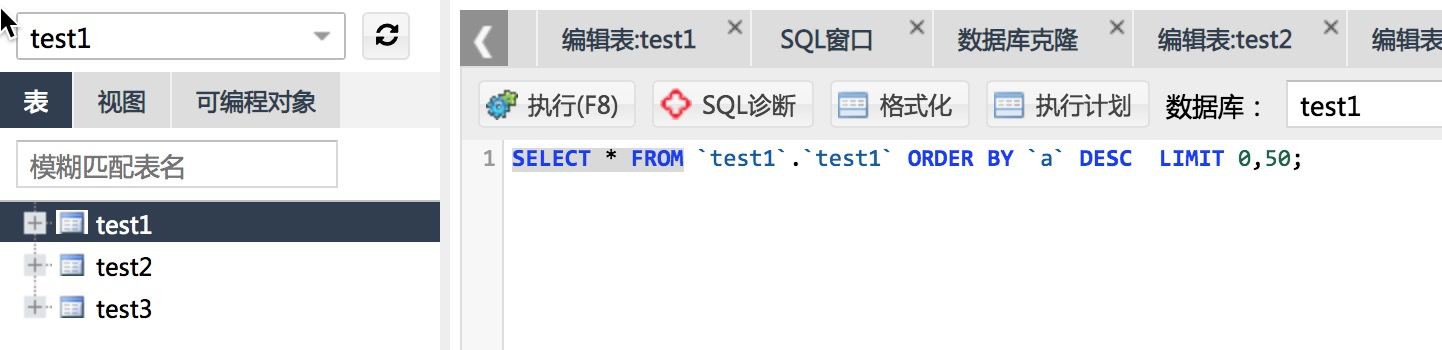
The specific table creation statements are as follows:
*Please swipe left and right
CREATE TABLE `test1` ( `a` int(11) NOT NULL, `b` time DEFAULT NULL, `c` double DEFAULT NULL, PRIMARY KEY (`a`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
Debugging of archiving to Spark
x-pack spark provides interactive query mode support to submit sql, python script and scala code to debug directly in the console.
1. First, create an interactive query session, and add the jar package of MySQL connector.
*Please swipe left and right
wget https://spark-home.oss-cn-shanghai.aliyuncs.com/spark_connectors/mysql-connector-java-5.1.34.jar
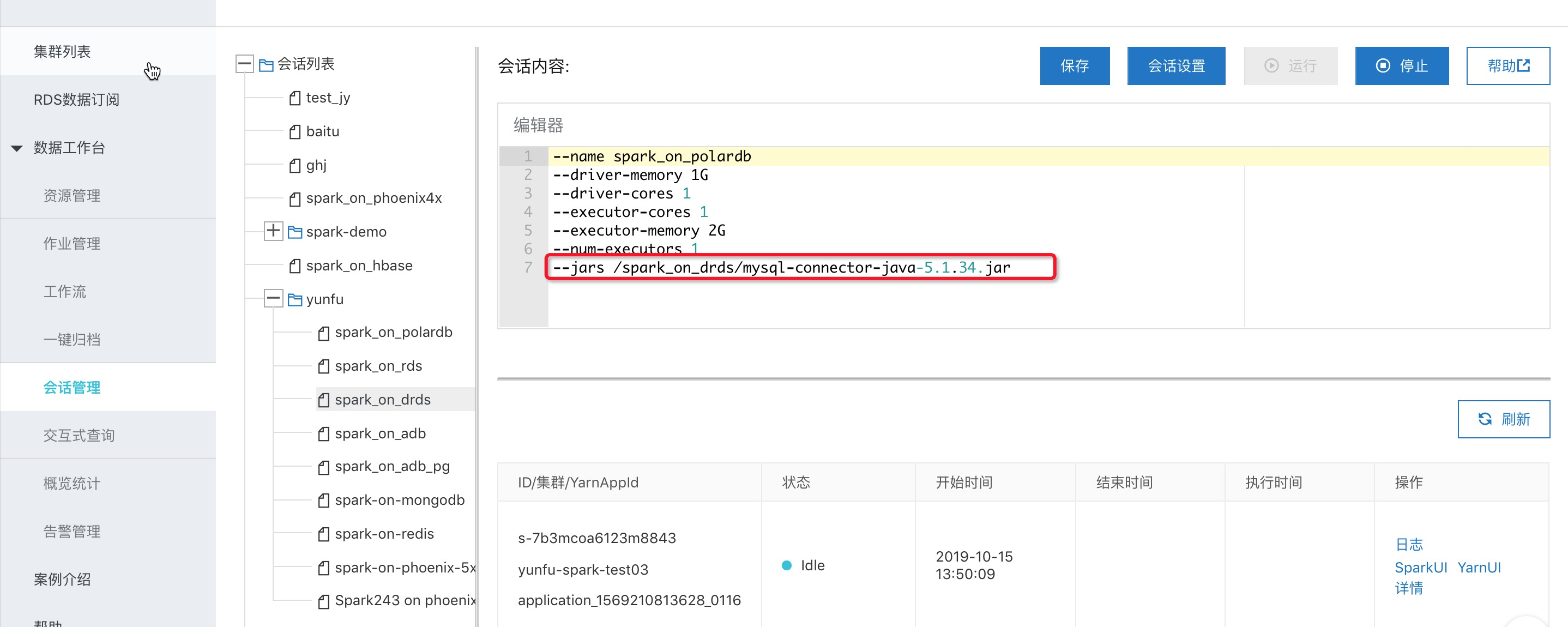
2. Create interactive query
Take pyspark as an example. Here is the code for archiving demo:
*Please swipe left and right
spark.sql("drop table sparktest").show() # Create a spark table, which is divided into three levels: day, hour and minute. The last level minute is used to store a specific 5-minute piece of polardb data. The fields are the same as the types in polardb spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) " "USING parquet PARTITIONED BY (dt ,hh ,mm )").show() #This example creates databse test1 in polldb, which has three tables test1, test2 and test3. Here, we traverse these three tables, and each table stores a 5min partition of spark # CREATE TABLE `test1` ( # `a` int(11) NOT NULL, # `b` time DEFAULT NULL, # `c` double DEFAULT NULL, # PRIMARY KEY (`a`) # ) ENGINE=InnoDB DEFAULT CHARSET=utf8 for num in range(1, 4): #Table name to construct polardb dbtable = "test1." + "test" + str(num) #spark appearance Association polardb corresponding table externalPolarDBTableNow = spark.read \ .format("jdbc") \ .option("driver", "com.mysql.jdbc.Driver") \ .option("url", "jdbc:mysql://pc-xxx.mysql.polardb.rds.aliyuncs.com:3306") \ .option("dbtable", dbtable) \ .option("user", "name") \ .option("password", "xxx*") \ .load().registerTempTable("polardbTableTemp") #Generate the partition information of the spark table to be written to the polldb table data this time (dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num)) #Execute import data sql spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) " "select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show() #Delete the catalog of the polardb table of the temporary spark map spark.catalog.dropTempView("polardbTableTemp") #View the partition and statistics data, which are mainly used for test verification. The actual running process can be deleted spark.sql("show partitions sparktest").show(1000, False) spark.sql("select count(*) from sparktest").show()
Production on filing operation
Interactive query is positioned as temporary query and debugging. It is recommended to run production jobs in the way of spark jobs, using document reference. Take the pyspark job as an example: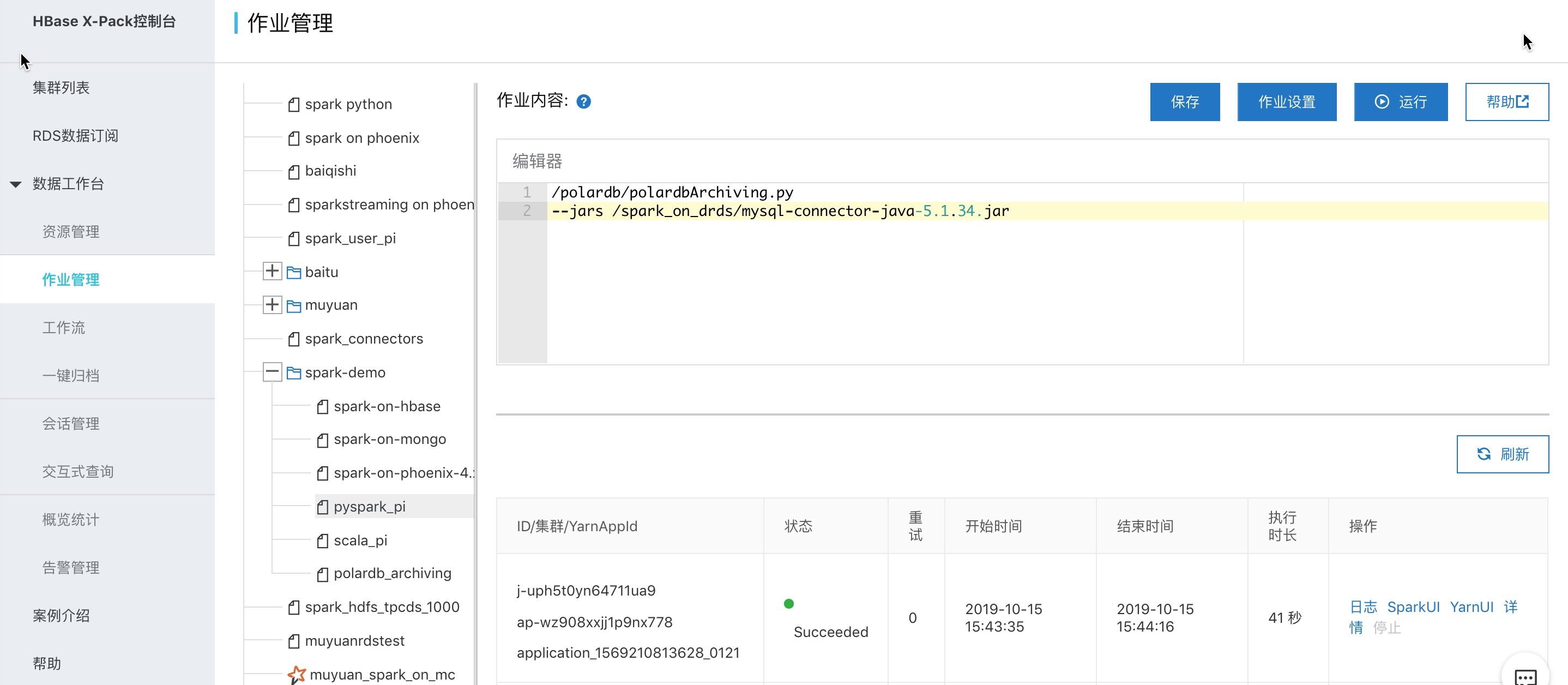
/The content of polardb / polardbacchiving.py is as follows:
*Please swipe left and right
# -*- coding: UTF-8 -*- from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession \ .builder \ .appName("PolardbArchiving") \ .enableHiveSupport() \ .getOrCreate() spark.sql("drop table sparktest").show() # Create a spark table, which is divided into three levels: day, hour and minute. The last level minute is used to store a specific 5-minute piece of polardb data. The fields are the same as the types in polardb spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) " "USING parquet PARTITIONED BY (dt ,hh ,mm )").show() #This example creates databse test1 in polldb, which has three tables test1, test2 and test3. Here, we traverse these three tables, and each table stores a 5min partition of spark # CREATE TABLE `test1` ( # `a` int(11) NOT NULL, # `b` time DEFAULT NULL, # `c` double DEFAULT NULL, # PRIMARY KEY (`a`) # ) ENGINE=InnoDB DEFAULT CHARSET=utf8 for num in range(1, 4): #Table name to construct polardb dbtable = "test1." + "test" + str(num) #spark appearance Association polardb corresponding table externalPolarDBTableNow = spark.read \ .format("jdbc") \ .option("driver", "com.mysql.jdbc.Driver") \ .option("url", "jdbc:mysql://pc-.mysql.polardb.rds.aliyuncs.com:3306") \ .option("dbtable", dbtable) \ .option("user", "ma,e") \ .option("password", "xxx*") \ .load().registerTempTable("polardbTableTemp") #Generate the partition information of the spark table to be written to the polldb table data this time (dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num)) #Execute import data sql spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) " "select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show() #Delete the catalog of the polardb table of the temporary spark map spark.catalog.dropTempView("polardbTableTemp") #View the partition and statistics data, which are mainly used for test verification. The actual running process can be deleted spark.sql("show partitions sparktest").show(1000, False) spark.sql("select count(*) from sparktest").show() spark.stop()
Scan QR code below
Learn more about the X-Pack Spark computing service

What do you want to buy?
Alibaba cloud database double 11 burst
This shopping list is for you!
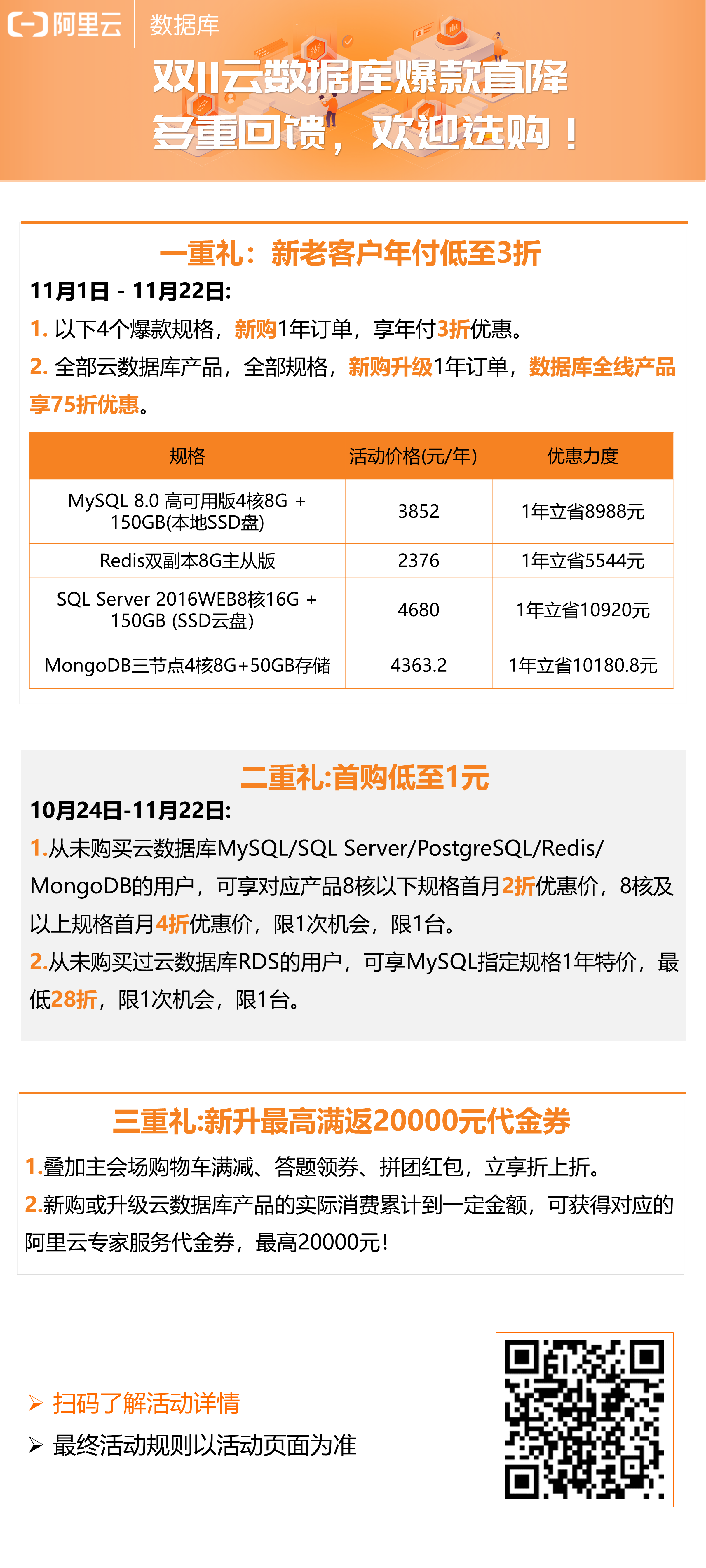
Double 11 benefits! Come to Kangkang first. How to buy the cheapest ECS? It's not easy to join the group to buy the ECS with the specified configuration. It's only 86 yuan / year. Open the group and enjoy the new triple gift: 1111 red bag + share millions of cash + 31% cash back. You have to buy the list of pop ups. You have to smoke the iPhone 11 Pro, sweater, T-shirt and so on. Try your luck on the horse https://www.aliyun.com/1111/2019/home?utm_content=g_1000083110
https://www.aliyun.com/1111/2019/home?utm_content=g_1000083110
This is the original content of yunqi community, which can not be reproduced without permission.