GraphQL is not only a query language for API, but also a runtime to meet your data query. GraphQL provides an easy to understand and complete description of the data in your API, so that the client can accurately obtain the data it needs without any redundancy. It also makes it easier for the API to evolve over time and can be used to build powerful developer tools.
-- from https://graphql.cn
For query, more often, the data is in the structured database. The API service queries the database through ORM, and the API provides external calls with different URLs; Imagine if we pass ADO Net to access the database, how can we fully adapt to the flexible query mode of graphql through one statement? This is a difficult point. You can only query all the data sets and let graphql filter the data you need in memory. In this way, a large number of data sets will soon occupy all the memory. It is not advisable. Of course, the way of writing sql directly like dapper is not enough.
At this time, the advantages of EF are revealed. In fact, EF itself is used by background programmers and encapsulates the function of converting Linq expressions to sql, so that background programmers don't have to care about sql statements; Here, if you can connect GraphQL and Linq, you can realize the GraphQL interface, and the background development becomes easier; Just in time, the sky makes a pair. GraphQL meets EF, making the two "seamless".
Michael Staib did the same and brought HotChocolate. The following is a case of GraphQL+EF(sql server).
Add Nuget package
HotChocolate.AspNetCore
HotChocolate.Data
HotChocolate.Data.EntityFramework
using HotChocolate;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
namespace GraphQLDemo01
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddPooledDbContextFactory<AdventureWorks2016Context>(
(services, options) => options
.UseSqlServer(Configuration.GetConnectionString("ConnectionString"))
.UseLoggerFactory(services.GetRequiredService<ILoggerFactory>()))
.AddGraphQLServer()
.AddQueryType<Query>()
.AddFiltering()
.AddSorting()
.AddProjections();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseRouting();
app.UseEndpoints(endpoints =>
{
endpoints.MapGraphQL();
});
}
}
}
The case database is AdventureWorks, the official demo database of sql server. Each query method becomes very simple. You only need to return the corresponding entity set, but the return value must be iqueryabl < >. It is this feature that makes GraphQL and EF fit so well. A paging is added to the feature. Considering the large amount of data, HotChocolate brings paging very considerate. The entity class and Context generated by AdventureWorks will not be displayed.
using System.Linq;
using HotChocolate;
using HotChocolate.Data;
using HotChocolate.Types;
namespace GraphQLDemo01
{
public class Query
{
[UseDbContext(typeof(AdventureWorks2016Context))]
[UseOffsetPaging]
[UseProjection]
[UseFiltering]
[UseSorting]
public IQueryable<Product> GetProducts([ScopedService] AdventureWorks2016Context context)
{
return context.Products;
}
[UseDbContext(typeof(AdventureWorks2016Context))]
[UsePaging]
[UseProjection]
[UseFiltering]
[UseSorting]
public IQueryable<Person> GetPersons([ScopedService] AdventureWorks2016Context context)
{
return context.People;
}
}
}
Use the products whose color is red and sort by listPrice
{
products(where: { color:{ eq:"Red"} } order:[{listPrice:ASC}]) {
items{
productId
name
listPrice
}
}
}
Using paging to query person
{
persons( order: [{ businessEntityId: ASC }] after:"MTk="){
pageInfo{
hasNextPage
hasPreviousPage
startCursor
endCursor
}
nodes{
businessEntityId
firstName
middleName
lastName
emailAddresses{
emailAddressId
emailAddress1
modifiedDate
}
}
edges{
cursor
node{
businessEntityId
}
}
}
}
Use offsetpaging to query products
{
products( order: [{ productId: ASC }] skip:40 take:20){
pageInfo{
hasNextPage
hasPreviousPage
}
items{
productId
name
}
}
}
If you track the sql statements of these queries, you will find that the generated sql will limit the query range, which can improve the memory utilization. Of course, the credit lies in EF, which is not what GraphQL needs to do. This is also ADO Net and dapper classes are matched with GraphQL.
With the same GrapQL, the following figure is the statement of dapper querying the Product table.
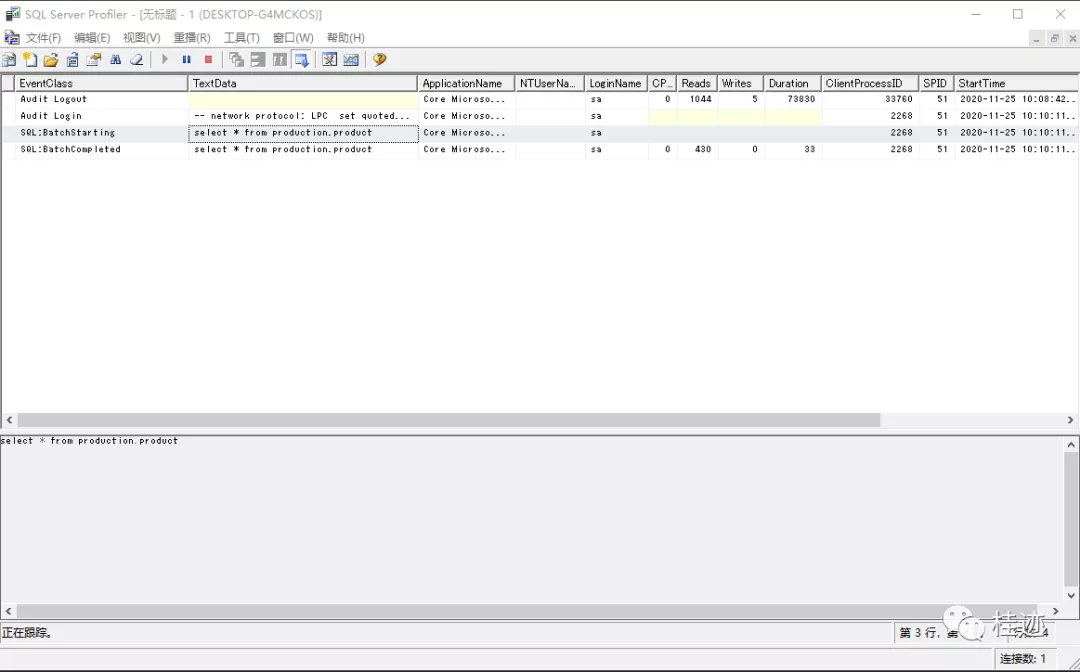
The following figure shows the statement generated by EF. The statement generated by EF is more accurate.

