All requirements of this time come from: https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
preface
This job is to crawl the information about python's relevant positions on the pull hook network. Through crawling the data such as position id, city, full name of the company, welfare treatment, work place, education requirements, work type, release time, position name, salary, working years, etc., and analyzing the data, we can get the corresponding conclusion.
Web crawler
1. Proxy IP
Before crawling data, we can consider using proxy ip for crawling, so here I write a piece of code to check the validity of ip. Here I use Free agent ip Test. However, in the test, I found that the available free proxy ip is very few, and the timeliness is relatively short, which is not very convenient to use, so if there are special crawler needs, people can consider using paid ip.
The test agent ip timeliness code is as follows:
import requests import random proxies = {'http': ''} def loadip(): url='https: // proxy.horocn.com / api / proxies?order_id = 3JXK1633928414619951 & num = 20 & format = text & line_separator = win & can_repeat = yes' req=requests.get(url) date=req.json() ipdate2=date['msg'] global ipdate ipdate.extend(ipdate2) print(ipdate) def getproxies(): b=random.choice(ipdate) d = '%s:%s' % (b['ip'], b['port']) global proxies proxies['http']=d global msg msg=b loadip() getproxies() print(proxies)
2. Pull the hook to search for crawlers in python related positions
After testing the proxy IP address, we can start to formally crawl the information about the relevant positions of the pull hook python. The crawler code of the relevant position web page of pull hook is as follows:
(Note: IP below_ The proxy IP in list should be invalid by now, so if you want to use the proxy IP, you need to find a new proxy IP.)
1 # encoding: utf-8 2 import json 3 import requests 4 import xlwt 5 import time 6 import random 7 8 def GetUserAgent(): 9 ''' 10 Function: random access HTTP_User_Agent 11 ''' 12 user_agents=[ 13 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 14 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", 15 "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 16 "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", 17 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", 18 "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", 19 "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", 20 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", 21 "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", 22 "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", 23 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", 24 "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", 25 "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", 26 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", 27 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", 28 "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", 29 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", 30 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", 31 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", 32 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", 33 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER", 34 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", 35 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)", 36 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", 37 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", 38 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", 39 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", 40 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", 41 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", 42 "Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5", 43 "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre", 44 "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0", 45 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", 46 "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10" 47 ] 48 user_agent = random.choice(user_agents) 49 return user_agent 50 51 # Get the json Object, traverse to obtain company name, welfare, work location, education requirements, work type, release time, position name, salary, working years 52 def get_json(url, datas): 53 user_agent = GetUserAgent() 54 ip_list = [ 55 {"http":"http://138.255.165.86:40600"}, 56 {"http":"http://195.122.185.95:3128"}, 57 {"http":"http://185.203.18.188:3128"}, 58 {"http":"http://103.55.88.52:8080"} 59 ] 60 proxies=random.choice(ip_list) 61 my_headers = { 62 "User-Agent": user_agent, 63 "Referer": "https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=", 64 "Content-Type": "application/x-www-form-urlencoded;charset = UTF-8" 65 } 66 time.sleep(5) 67 ses = requests.session() # obtain session 68 ses.headers.update(my_headers) # to update 69 ses.proxies.update(proxies) 70 71 cookie_dict = dict() 72 ses.cookies.update(cookie_dict) 73 74 ses.get( 75 "https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=",headers=my_headers) 76 time.sleep(5) 77 content = ses.post(url=url, data=datas) 78 result = content.json() 79 info = result['content']['positionResult']['result'] 80 info_list = [] 81 for job in info: 82 information = [] 83 information.append(job['positionId']) # Position correspondence ID 84 information.append(job['city']) # Position corresponding city 85 information.append(job['companyFullName']) # Full name of company 86 information.append(job['companyLabelList']) # fringe benefits 87 information.append(job['district']) # Workplace 88 information.append(job['education']) # Education requirements 89 information.append(job['firstType']) # Type of work 90 information.append(job['formatCreateTime']) # Release time 91 information.append(job['positionName']) # Job title 92 information.append(job['salary']) # salary 93 information.append(job['workYear']) # Working years 94 info_list.append(information) 95 # Make a list object json Code conversion of format,among indent Parameter set indent value to 2 96 # print(json.dumps(info_list, ensure_ascii=False, indent=2)) 97 # print(info_list) 98 return info_list 99 100 101 def main(): 102 page = int(input('Please enter the total number of pages you want to capture:')) 103 # kd = input('Please enter the position keyword you want to capture:') 104 # city = input('Please enter the city you want to capture:') 105 106 info_result = [] 107 title = ['post id', 'city', 'Full name of company', 'fringe benefits', 'Workplace', 'Education requirements', 'Type of work', 'Release time', 'Job title', 'salary', 'Working years'] 108 info_result.append(title) 109 for x in range(56, page + 1): 110 url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' 111 # Request parameters, pn Parameter is the number of pages, kd Parameter is position key 112 datas = { 113 'first': 'false', 114 'pn': x, 115 'kd': 'python', 116 } 117 try: 118 info = get_json(url, datas) 119 info_result = info_result + info 120 print("The first%s Page normal collection" % x) 121 except Exception as msg: 122 print("The first%s There is a problem with the page" % x) 123 124 # establish workbook,Namely excel 125 workbook = xlwt.Workbook(encoding='utf-8') 126 # Create table,The second parameter is used to confirm the same cell Can cells reset values 127 worksheet = workbook.add_sheet('lagoupy', cell_overwrite_ok=True) 128 for i, row in enumerate(info_result): 129 # print(row) 130 for j, col in enumerate(row): 131 # print(col) 132 worksheet.write(i, j, col) 133 workbook.save('lagoupy.xls') 134 135 136 if __name__ == '__main__': 137 main()
Data analysis
After executing the above crawler code, we can get a lagoupy.xls In the file, the result of our crawler is stored, and a total of 2640 pieces of data are crawled, as shown in the figure below.

1. Data preprocessing
Because not all of the data we crawl down is what we want, or some data needs to be processed before it can be used, data preprocessing is essential.
① Delete duplicate values
If there are duplicate records in the data, and the number of duplicates is large, it is bound to have an impact on the results, so we should first deal with duplicate values. open lagoupy.xls File, select the column data of position id, select data - > delete duplicate value, delete the duplicate value. After deleting the duplicate value, we can find that the data has changed from the original 2641 to 2545.
② Filter invalid data
Because some data is not useful for our data analysis, we can not use this part of data. The publishing time here is invalid data, so we can delete this column directly.
③ Processing data
Because the salary column in the crawled data is similar to 15k-30k data, and such data can not meet our analysis needs, we need to carry out the salary column data Column operation , split the salary column into the minimum wage and the maximum wage. Then we can use the minimum wage and the maximum wage to calculate the average wage, and add the average wage as a new column to the data table.
After the above three steps, we can finally get a data preprocessed lagoupy.xls After preprocessing, the number of our data has changed from 2640 to 2544, as shown in the figure below.

2. Data analysis
① Education requirements
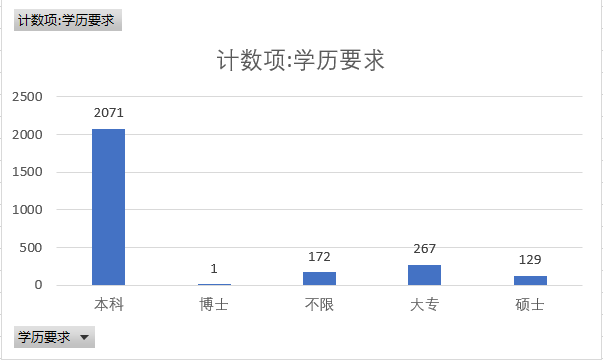
According to the statistics, most of python's education requirements are undergraduate and junior college, among which 2071 are undergraduate.
② Type of work
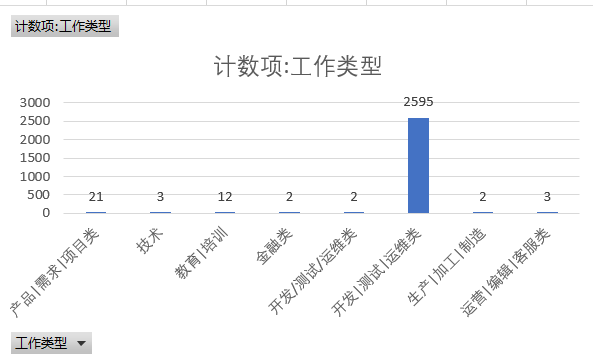
We roughly divide python related work into eight categories, namely, product requirements, project, technology, education, training, finance, development, testing, operation and maintenance, production, processing, manufacturing, operation, editing, customer service. Among them, the development, testing, operation and maintenance type of work has an absolute advantage.
③ Work city
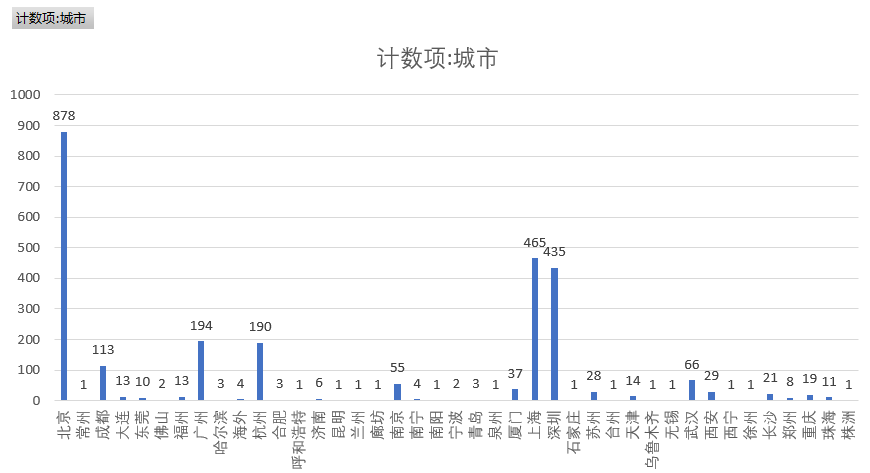
According to the statistics of the demand for python related jobs in each city, we can see from the figure below that six cities, Beijing, Shanghai, Shenzhen, Guangzhou, Hangzhou and Chengdu, have relatively large demand for python related industries.
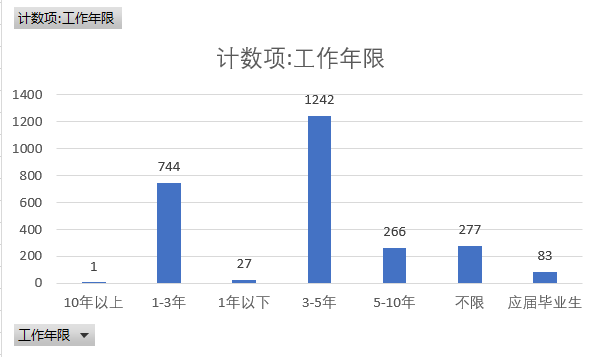
④ Working years
Based on the statistics of the working years of python related positions, we can find that the majority of the enterprises' working experience requirements are 3-5 years and 1-3 years.
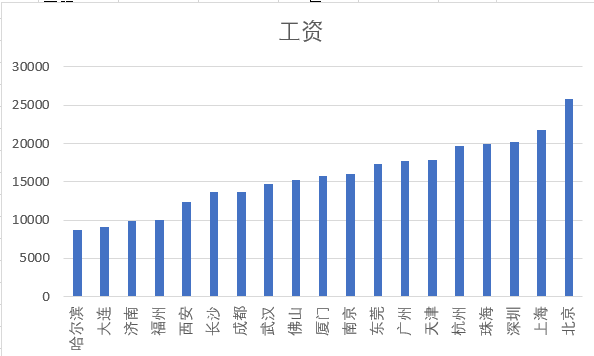
⑤ Cities and wages: higher wages in more developed cities
As can be seen from the figure below, there is a certain relationship between cities and wages. In developed cities such as Beijing, Shanghai, Guangzhou and Shenzhen, the wages of python related positions are higher.
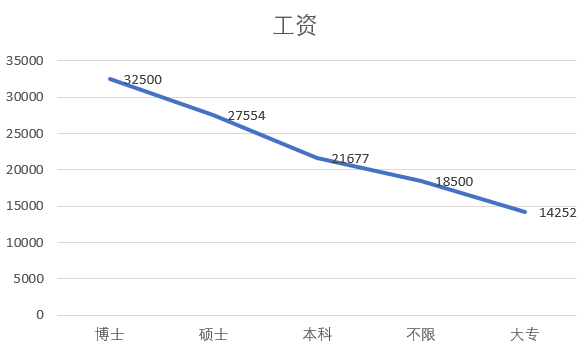
⑥ Education and salary: the higher the education, the higher the salary
It can be seen from the figure that the higher the education level, the higher the salary. Because there is only one data for doctoral degree, there may be some errors in the analysis results due to insufficient data.
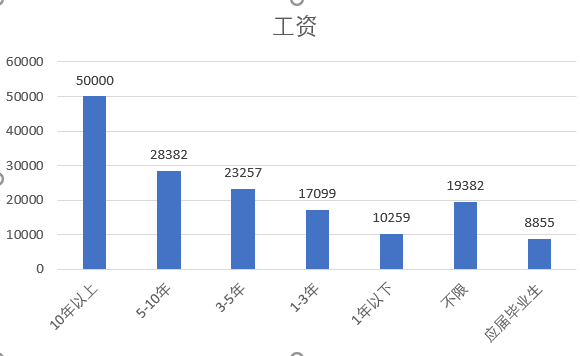
⑦ Working years and wages - the longer the working years, the higher the wages
It can be seen from the figure that the longer the working life, the higher the salary. Because there is only one piece of data for more than 10 years, there may be some deviation for the data of more than 10 years of work experience.
⑧ Benefits
First of all, let's create a new one fuli.txt To paste the benefits column into the fuli.txt And save as shown in the following figure.
Second, we are right fuli.txt Conduct word frequency statistics, and save the results generated by word frequency statistics as fuli.csv Documents. The statistical code of the word frequency of welfare treatment is as follows:
1 # -*- coding: utf-8 -*- 2 import jieba # Load deactivation table 3 import pandas as pd 4 from wordcloud import WordCloud 5 import matplotlib.pyplot as plt 6 7 # decompose 8 article = open("fuli.txt", "r", encoding='utf-8').read() 9 jieba.add_word('Five risks and one fund') 10 jieba.add_word('Seven risks and one fund') 11 jieba.add_word('Six risks and one fund') 12 jieba.add_word('Paid annual leave') 13 jieba.add_word('Many beauties') 14 jieba.add_word('Handsome man') 15 jieba.add_word('Double pay at the end of the year') 16 jieba.add_word('achievement bonus') 17 jieba.add_word('the stock option') 18 jieba.add_word('Flat management') 19 jieba.add_word('Flexible work') 20 jieba.add_word('Management specification') 21 jieba.add_word('Post promotion') 22 jieba.add_word('Skills training') 23 jieba.add_word('Holiday gifts') 24 jieba.add_word('Paid annual leave') 25 jieba.add_word('Regular physical examination') 26 jieba.add_word('Communication allowance') 27 jieba.add_word('Good leadership') 28 jieba.add_word('Annual tourism') 29 jieba.add_word('Transportation subsidy') 30 jieba.add_word('Year end dividend') 31 jieba.add_word('Three big meals') 32 jieba.add_word('Large development space') 33 jieba.add_word('Lunch allowance') 34 jieba.add_word('rapid growth') 35 jieba.add_word('Good development prospect') 36 jieba.add_word('Special bonus') 37 jieba.add_word('Free shuttle') 38 jieba.add_word('Three big meals') 39 jieba.add_word('Technology bull') 40 words = jieba.cut(article, cut_all=False) # Statistical word frequency 41 stayed_line = {} 42 for word in words: 43 if len(word) == 1: 44 continue 45 else: 46 stayed_line[word] = stayed_line.get(word, 0) + 1 47 48 print(stayed_line) # sort 49 xu = list(stayed_line.items()) 50 # print(xu) 51 52 #Deposit to csv In file 53 pd.DataFrame(data=xu).to_csv("fuli.csv",encoding="utf_8_sig")
After executing the above code, we can generate a fuli.csv File, as shown in the figure below.
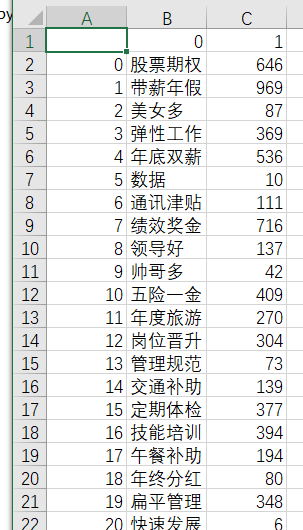
Based on the generated fuli.csv File usage WordArt Benefits Generate Chinese word cloud , as shown in the figure below, we can find that the most frequently mentioned terms in the benefits of python related posts are paid annual leave, stock option, performance bonus, double pay at the end of the year, holiday gift, skill training, regular physical examination, five insurances and one bonus, etc.
