1, About Flink
1. First meet Flink
Flink originated from the stratosphere project. Stratosphere was a research project jointly carried out by three universities in Berlin and some other universities in Europe from 2010 to 2014. In April 2014, the code of stratosphere was copied and donated to the Apache Software Foundation. The initial members participating in this incubation project were the core developers of stratosphere system, In December 2014, Flink became the top project of Apache Software Foundation.
In German, Flink means fast and dexterous. The project uses the color pattern of a squirrel as the logo, not only because the squirrel has the characteristics of fast and dexterous, but also because the squirrel in Berlin has a charming reddish brown. Flink's squirrel logo has a lovely tail, and the color of the tail echoes the logo color of the Apache Software Foundation, that is, This is an Apache style squirrel.
The concept of Flink project is: "Apache Flink is an open source streaming framework for distributed, high-performance, ready to use and accurate streaming applications".
Apache Flink is a framework and distributed processing engine for stateful computing of unbounded and bounded data streams. Flink is designed to run in all common cluster environments and perform calculations at memory execution speed and any size.
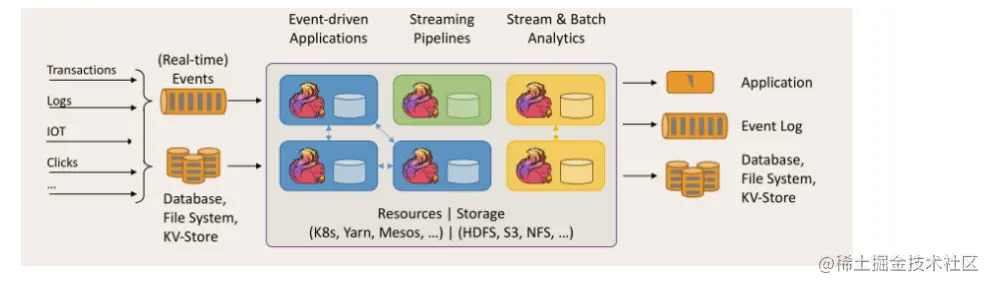
2. Important features of Flink
2.1 event driven
Event driven application is a kind of application with state. It extracts data from one or more event streams and triggers calculation, state update or other external actions according to the incoming events. A typical example is that almost all message queues represented by kafka are event driven applications.
The difference is SparkStreaming micro batch, as shown in the figure:

Event driven:
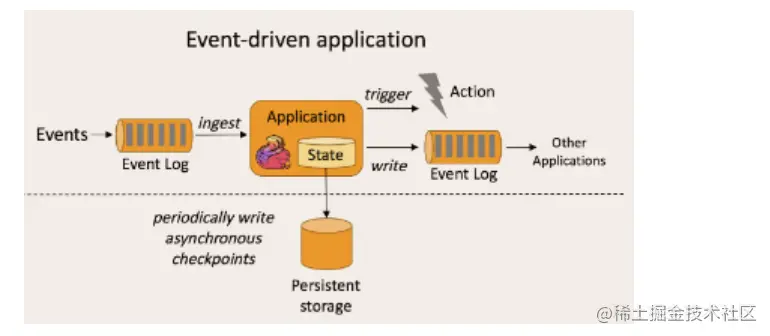
2.2 world view of flow and batch
Batch processing is characterized by being bounded, persistent and large. It is very suitable for computing work that needs to access a full set of records. It is generally used for off-line statistics.
Stream processing is characterized by unbounded and real-time. It does not need to perform operations on the whole data set, but on each data item transmitted through the system. It is generally used for real-time statistics.
In spark's world view, everything is composed of batches. Offline data is a large batch, while real-time data is composed of infinite small batches.
In the world view of flink, everything is composed of streams. Offline data is a bounded stream, and real-time data is a unbounded stream, which is the so-called bounded stream and unbounded stream.
Unbounded data stream: unbounded data streams have a beginning but no end. They will not terminate and provide data when they are generated. Unbounded streams must be processed continuously, that is, events must be processed immediately after acquisition. For unbounded data flow, we cannot wait for all data to arrive, because the input is unbounded and will not be completed at any point in time. Processing unbounded data usually requires obtaining events in a specific order, such as the order in which events occur, so that the integrity of the results can be inferred.
Bounded data flow: bounded data flow has a clearly defined start and end. It can be processed by obtaining all data before performing any calculation. It does not need to be obtained in order to process bounded flow, because bounded data sets can always be sorted. The processing of bounded flow is also called batch processing.

The biggest advantage of this stream oriented architecture is that it has very low latency.
2.3 layered api
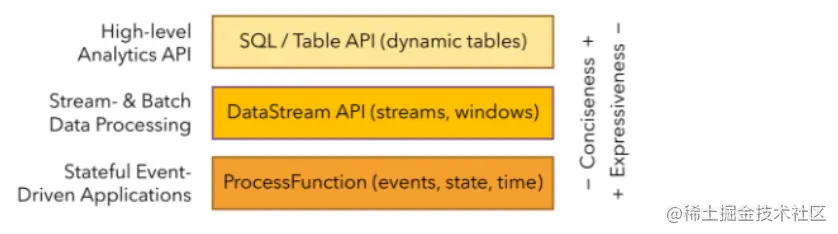
Flink several modules
- Flink Table & SQL
- Flink Gelly
- Flink CEP
2, Get started quickly
1. Build maven project FlinkTutorial
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
Copy code2. Batch wordcount
public static void main(String[] args) throws Exception {
// Create execution environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Read data from file
String inputPath = "word.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// The data set is processed, expanded according to space word segmentation, and converted into (word,1) binary for statistics
inputDataSet.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : value.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}).groupBy(0) // Group by word in the first position
.sum(1) // Sum the data at the second position
.print();
}
Copy code3. Stream processing wordcount
public static void main(String[] args) throws Exception {
// Creating a streaming environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Use the parameter tool tool to extract configuration items from program startup parameters
ParameterTool parameterTool = ParameterTool.fromArgs(args);
// nc -lk 7777
// --host hadoop102 --port 7777
String hostname = parameterTool.get("host", "hadoop102");
int port = parameterTool.getInt("port", 7777);
DataStream<String> inputDataSet = env.socketTextStream(hostname, port);
// Conversion calculation based on data flow
inputDataSet.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : value.split(" ")) {
out.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0)
.sum(1)
.print();
// Perform tasks
env.execute();
}