1 replication and multiplexing
1.1 case requirements
Flume-1 is used to monitor file changes. Flume-1 passes the changes to Flume-2, which is responsible for storing them
To HDFS. At the same time, Flume-1 passes the changes to Flume-3, which is responsible for outputting them to the local file system.
1.2 demand analysis: single data source multi export case (selector)
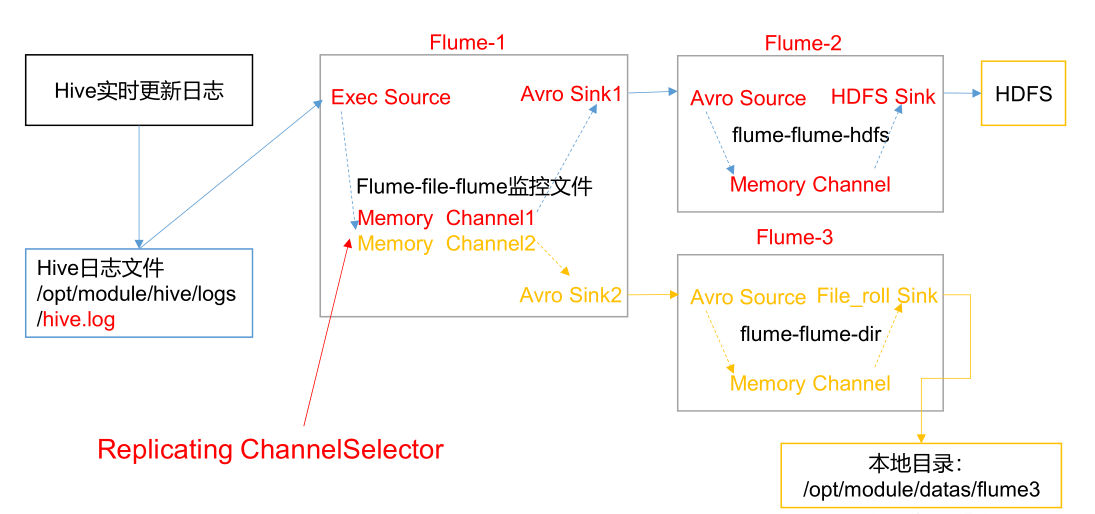
1.3 implementation steps
(1) Preparatory work
Create the group1 folder in the / opt/module/flume/job directory
[bigdata@hadoop102 job]$ cd group1/
Create the flume3 folder in the / opt / module / data / directory
[bigdata@hadoop102 datas]$ mkdir flume3
(2) Create flume-file-flume.conf
Configure one source, two channel s and two sink s to receive log files and send them to flume flume respectively-
hdfs and flume flume dir.
Edit profile
[bigdata@hadoop102 group1]$ vim flume-file-flume.conf
Add the following
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Copy data flow to all channel s a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink # avro on sink side is a data sender a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
(3) Create flume-flume-hdfs.conf
Configure the Source of the superior Flume output, which is the Sink to HDFS.
Edit profile
[bigdata@hadoop102 group1]$ vim flume-flume-hdfs.conf
Add the following
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source # avro on the source side is a data receiving service a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9820/flume2/%Y%m%d/%H #Prefix of uploaded file a2.sinks.k1.hdfs.filePrefix = flume2- #Scroll folders by time a2.sinks.k1.hdfs.round = true #How many time units to create a new folder a2.sinks.k1.hdfs.roundValue = 1 #Redefine time units a2.sinks.k1.hdfs.roundUnit = hour #Use local timestamp a2.sinks.k1.hdfs.useLocalTimeStamp = true #How many events are accumulated to flush to HDFS once a2.sinks.k1.hdfs.batchSize = 100 #Set the file type to support compression a2.sinks.k1.hdfs.fileType = DataStream #How often do I generate a new file a2.sinks.k1.hdfs.rollInterval = 30 #Set the scroll size of each file to about 128M a2.sinks.k1.hdfs.rollSize = 134217700 #File scrolling is independent of the number of events a2.sinks.k1.hdfs.rollCount = 0 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
(4) Create flume-flume-dir.conf
Configure the Source of the superior Flume output. The output is Sink to the local directory.
Edit profile
[bigdata@hadoop102 group1]$ vim flume-flume-dir.conf
Add the following
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/data/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
Tip: the output local directory must be an existing directory. If the directory does not exist, a new directory will not be created
Record.
(5) Execution profile
Start the corresponding flume processes respectively: flume flume dir, flume flume HDFS, flume file flume.
[bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea3 --conf-file job/group1/flume-flume-dir.conf [bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea2 --conf-file job/group1/flume-flume-hdfs.conf [bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea1 --conf-file job/group1/flume-file-flume.conf
(6) Start Hadoop and Hive
[bigdata@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [bigdata@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [bigdata@hadoop102 hive]$ bin/hive hive (default)>
(7) Check data on HDFS
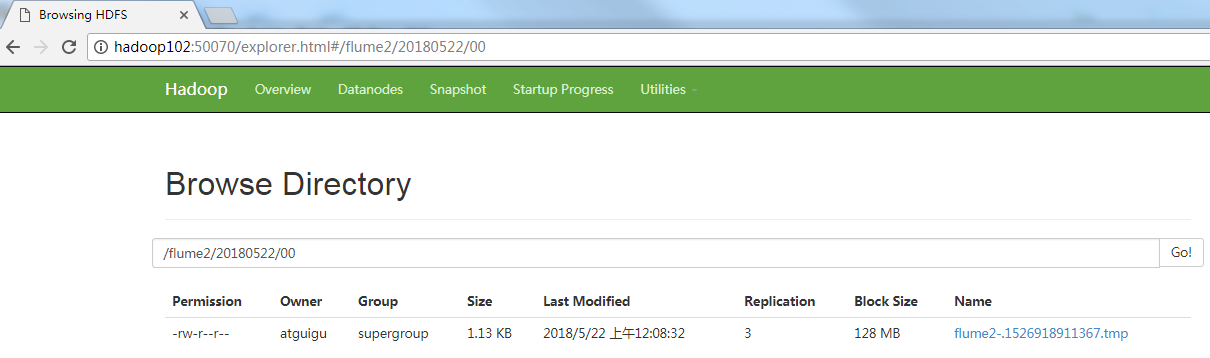
(8) Check the data in the / opt / module / data / flume3 directory
[bigdata@hadoop102 flume3]$ ll Total consumption 8 -rw-rw-r--. 1 bigdata bigdata 5942 5 June 22 00:09 1526918887550-3
2 load balancing and failover
2.1 case requirements
Flume1 is used to monitor a port. The sink in the sink group is connected to Flume2 and Flume3 respectively. FailoverSinkProcessor is used to realize the function of failover.
2.2 requirements analysis: failover cases
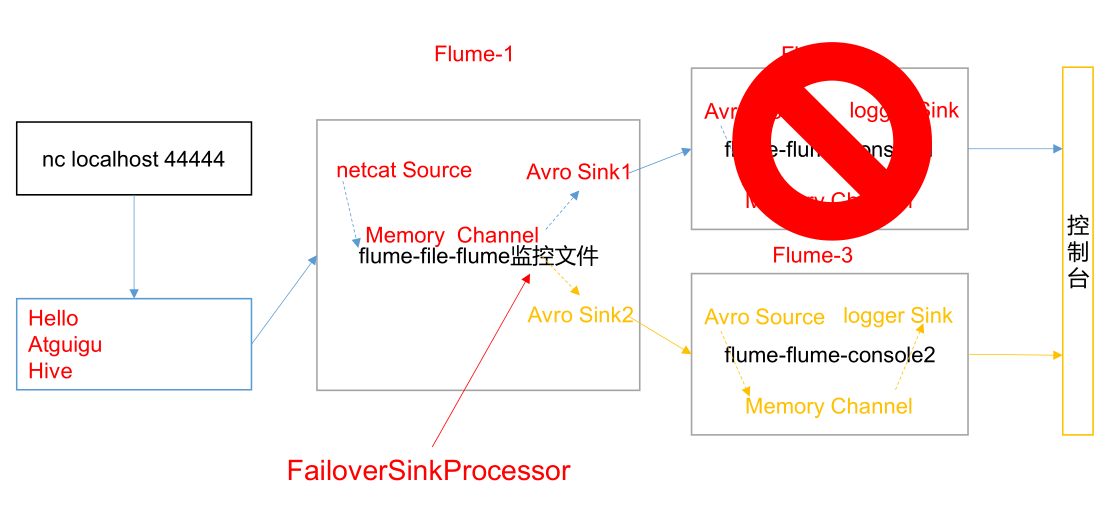
2.3 implementation steps
(1) Preparatory work
Create the group2 folder in the / opt/module/flume/job directory
[bigdata@hadoop102 job]$ cd group2/
(2) Create flume-netcat-flume.conf
Configure 1 netcat source, 1 channel and 1 sink group (2 sinks) to transport to
flume-flume-console1 and flume-flume-console2.
Edit profile
[bigdata@hadoop102 group2]$ vim flume-netcat-flume.conf
Add the following
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
(3) Create flume-flume-console1.conf
Configure the Source of the superior Flume output, which is to the local console.
Edit profile
[bigdata@hadoop102 group2]$ vim flume-flume-console1.conf
Add the following
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
(4) Create flume-flume-console2.conf
Configure the Source of the superior Flume output, which is to the local console.
Edit profile
[bigdata@hadoop102 group2]$ vim flume-flume-console2.conf
Add the following
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
(5) Execution profile
Open the corresponding configuration files: flume-flume-console2, flume-flume-console1, flume netcat flume.
[bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea3 --conf-file job/group2/flume-flume-console2.conf - Dflume.root.logger=INFO,console [bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea2 --conf-file job/group2/flume-flume-console1.conf - Dflume.root.logger=INFO,console [bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea1 --conf-file job/group2/flume-netcat-flume.conf
(6) Use the netcat tool to send content to port 444 of this machine
$ nc localhost 44444
(7) View the console print logs of Flume2 and Flume3
(8) Kill flume2 and observe the printing of Flume3 console.
Note: use JPS -- l ml to view the e Flume process.
3 polymerization
3.1 case requirements
Flume-1 monitoring file / opt/module/group.log on Hadoop 102, Flume-2 on Hadoop 103 monitors the data flow of a port, flume-1 and Flume-2 send the data to Flume-3 on Hadoop 104, and Flume-3 prints the final data
To the console.
3.2 demand analysis: multi data source summary case
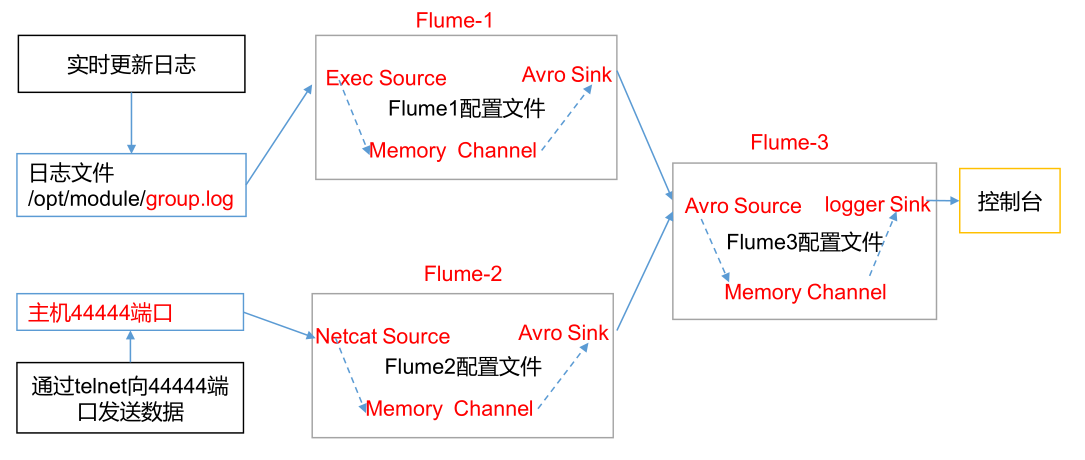
3.3 implementation steps
(1) Preparatory work
Distribute Flume
[bigdata@hadoop102 module]$ xsync flume
Create one in / opt/module/flume/job directory of Hadoop 102, Hadoop 103 and Hadoop 104
group3 folder.
[bigdata@hadoop102 job]$ mkdir group3 [bigdata@hadoop103 job]$ mkdir group3 [bigdata@hadoop104 job]$ mkdir group3
(2) Create flume1-logger-flume.conf
Configure Source to monitor hive.log file and configure Sink to output data to the next level Flume.
Edit the configuration file on Hadoop 102
[bigdata@hadoop102 group3]$ vim flume1-logger-flume.conf
Add the following
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/group.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop104 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
(3) Create flume2-netcat-flume.conf
Configure the Source monitoring port 444 data flow, and configure the Sink data to the next level Flume:
Edit the configuration file on Hadoop 103
[bigdata@hadoop102 group3]$ vim flume2-netcat-flume.conf
Add the following
# Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = hadoop103 a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hadoop104 a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
(4) Create flume3 -- flume -- logger.conf
Configure the source to receive the data streams sent by flume1 and flume2, and finally sink to the control after merging
Stage.
Edit the configuration file on Hadoop 104
[bigdata@hadoop104 group3]$ touch flume3-flume-logger.conf [bigdata@hadoop104 group3]$ vim flume3-flume-logger.conf
Add the following
# Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop104 a3.sources.r1.port = 4141 # Describe the sink # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
(5) Execution profile
Open the corresponding configuration files: flume3-flume-logger.conf, flume2-netcat-flume.conf, flume1-logger-flume.conf.
[bigdata@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --namea3 --conf-file job/group3/flume3-flume-logger.conf - Dflume.root.logger=INFO,console [bigdata@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --namea2 --conf-file job/group3/flume1-logger-flume.conf [bigdata@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --namea1 --conf-file job/group3/flume2-netcat-flume.conf
(6) Add content to group.log in / opt/module directory on Hadoop 103
[bigdata@hadoop103 module]$ echo 'hello' > group.log
(7) Send data to port 444 on Hadoop 102
[bigdata@hadoop102 flume]$ telnet hadoop102 44444
(8) Check data on Hadoop 104
