Zeppelin is an open source Apache incubation project. It is a basic web notebook tool that supports interactive data analysis. Through plug-in access to various interpreter s, users can complete interactive query in specific language or data processing back-end, and quickly realize data visualization.
Zeppelin: query and analyze data and generate reports
Spark: it provides Zeppelin with a background data engine. It is a computing model based on RDD (elastic distributed data set). If a large number of polar data can be processed in a distributed manner, a large number of data sets are first split and calculated separately, and then the calculated results are combined.
1, Environmental preparation
1. Uninstall and install JDK
Since OpenJDK is installed by default in CentOS, which does not meet our requirements, we need to uninstall it first and then reinstall the Oracle version of JDK.
1.1. Query java version: rpm -qa|grep java
1.2. Uninstall openjdk: Yum - y remove Java XXX openjdk XXX
JDK download address of Oracle version: https://download.oracle.com/otn/java/jdk/8u311-b11/4d5417147a92418ea8b615e228bb6935/jdk-8u311-linux-x64.rpm
rpm install jdk
rpm -ivh jdk-8u311-linux-x64.rpm
View installed version
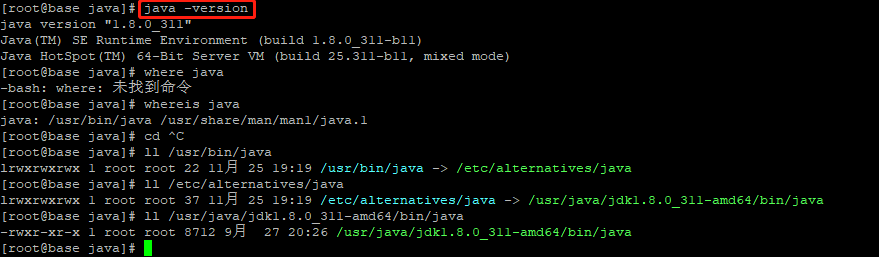
Add to environment variable
vim /etc/profile export JAVA_HOME=/usr/java/jdk1.8.0_311-amd64 export JAVA_BIN=/usr/java/jdk1.8.0_311-amd64/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar export PATH=$PATH:$JAVA_HOME/bin # Save and exit, execute the following command to make the environment variable take effect immediately source /etc/profile
two Change hostname
192.168.0.61 hostnamectl set-hostname master 192.168.0.64 hostnamectl set-hostname slave01 192.168.0.65 hostnamectl set-hostname slave02 # Configure hosts(IP and hostname mapping) vim /etc/hosts 192.168.0.61 master 192.168.0.64 slave01 192.168.0.65 slave02
3. Synchronization time
ntpdate cn.pool.ntp.org
4. Turn off the firewall and selinux
vi /etc/selinux/config take SELINUX=enforcing Change to SELINUX=disabled After setting, you need to restart to take effect systemctl stop firewalld systemctl disable firewalld
five scala installation ()
Download Scala3-3.1.0 package
tar -zxf scala3-3.1.0.tar.gz -C /usr/local/ mv scala3-3.1.0 scala3
vim /etc/profile export PATH=$PATH:$JAVA_HOME/bin:/usr/local/scala3/bin # Save and exit, execute the following command to make the environment variable take effect immediately source /etc/profile
Check whether the installation is successful

6. Create hadoop user
useradd hadoop password hadoop
Switch user hadoop
su hadoop
7. Configure ssh keyless certificate
ssh-keygen -t rsa ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub master ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub slave01 ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub slave02
The above steps should be performed on each virtual machine
2, Hadoop installation and deployment
hadoop Download
Index of /hadoop/common/hadoop-3.3.1
https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
Unzip the installation package
tar -zxf hadoop-3.3.1.tar.gz -C /data/java-service/ cd /data/java-service/ mv hadoop-3.3.1/ hadoop # Create dfs related directories mkdir -p dfs/name mkdir -p dfs/data mkdir -p dfs/namesecondary
Configure environment variables
vim /etc/profile # hadoop export HADOOP_HOME=/data/java-service/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # Save and exit, execute the following command to make the environment variable take effect immediately source /etc/profile
Enter the hadoop configuration file directory to start parameter configuration
one Modify the configuration file core-site.xml
cp core-site.xml core-site.xml.cp
For detailed parameters, please refer to: https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoop-common/core-default.xml
The following contents are added to < configuration > < / configuration >
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>NameNode URI.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>Size of read/write buffer used inSequenceFiles.</description>
</property>two Modify the configuration file hdfs-site.xml
cp hdfs-site.xml hdfs-site.xml.cp
For detailed parameters, please refer to: http://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
The following contents are added to < configuration > < / configuration >
vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
<description>The secondary namenode http server address andport.</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/java-service/hadoop/dfs/name</value>
<description>Path on the local filesystem where the NameNodestores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/java-service/hadoop/dfs/data</value>
<description>Comma separated list of paths on the local filesystemof a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///data/java-service/hadoop/dfs/namesecondary</value>
<description>Determines where on the local filesystem the DFSsecondary name node should store the temporary images to merge. If this is acomma-delimited list of directories then the image is replicated in all of thedirectories for redundancy.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>3. Modify the configuration file mapred-site.xml
cp mapred-site.xml mapred-site.xml.cp
For detailed parameters, please refer to: https://hadoop.apache.org/docs/r3.3.1/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
The following contents are added to < configuration > < / configuration >
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>Theruntime framework for executing MapReduce jobs. Can be one of local, classic oryarn.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>MapReduce JobHistoryServer IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>MapReduce JobHistoryServer Web UI host:port</description>
</property>4. Modify the configuration file yarn-site.xml
cp yarn-site.xml yarn-site.xml.cp
Default configuration link: http://hadoop.apache.org/docs/r3.3.1/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
The following contents are added to < configuration > < / configuration >
vim yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>The hostname of theRM.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduceapplications.</description>
</property>5. vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_311-amd64
6. vim workers
slave01 slave02
7. Change log write permission
chown hadoop:hadoop -R /data/java-service/hadoop/logs/
eight Copy the hadoop directory to the two Slave nodes
scp -r /data/java-service/hadoop root@slave01:/data/java-service/ scp -r /data/java-service/hadoop root@slave02:/data/java-service/
The two nodes also need to configure the environment variable / etc/profile
Error message
1. ERROR: Cannot set priority of namenode process
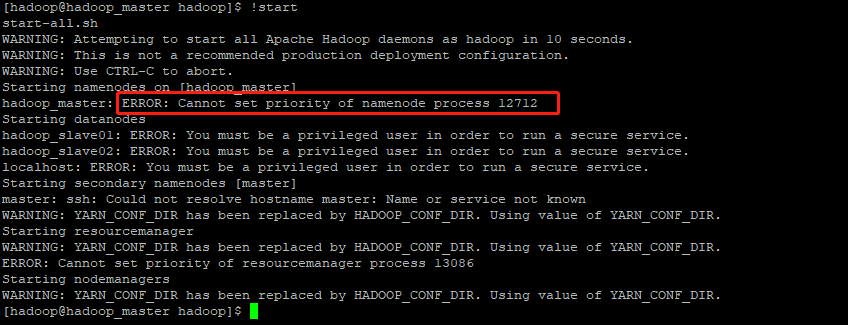
1. Does not contain a valid host:port authority
Repair: according to the investigation result, the hostname of the host is illegal, so it is modified to not contain '.' / '' Illegal characters such as.
2.Directory /data/java-service/hadoop/dfs/name is in an inconsistent state

Permission issue chown -R hadoop:hadoop / data/java-service/hadoop/dfs
Relevant data for error reporting and debugging:
ubuntu 18.04 configuring Hadoop 3.1.1 some problem records_ ygd11 column - CSDN blog
hadoop error: Does not contain a valid host:port authority - Damo Chuiyang - blog Park