1 insufficient spark streaming
In 2016, Apache Spark launched the Structured Streaming project, a new stream computing engine based on Spark SQL, which allows users to write high-performance stream processing programs as easily as writing batch programs.
Structured Streaming is not a simple improvement to Spark Streaming, but a new streaming engine developed by learning from the experience and lessons in the development of Spark SQL and Spark Streaming, as well as the feedback of many customers in Spark community and Databricks. It is committed to providing a unified high-performance API for batch and stream processing. At the same time, in this new engine, it is also easy to implement some functions that are difficult to implement in Spark Streaming before, such as EventTime support, stream stream join (new functions in 2.3.0), millisecond delay (Continuous Processing to be added in 2.3.0).
Spark Streaming is a streaming system developed by Apache Spark based on RDD in the early stage. Users use DStream API to write code, supporting high throughput and good fault tolerance. The main model behind it is Micro Batch, which is to cut the data flow into small batch tasks with equal time interval.
Structured Streaming is a redesigned new streaming engine added in Spark 2.0. Its model is very concise and easy to understand. Logically speaking, the data source of a stream is a growing dynamic table. With the passage of time, new data is continuously added to the end of the table. Users can use Dataset/DataFrame or SQL to query the dynamic data source in real time.
file: http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html
Spark Streaming will receive the data from the real-time data source and cut it into many small batches, which are then executed by the Spark Engine to produce a result stream composed of many small batches.

In essence, this is a micro batch processing method, which processes stream data with the idea of batch. This design makes Spark Streaming limited in the face of complex streaming scenarios.
What are the shortcomings of Spark Streaming? The main points are as follows:
- First point: use Processing Time instead of Event Time
- Processing Time is the time when the data arrives at Spark for processing, and Event Time is the attribute of the data,
Generally, it indicates the time when the data is generated from the data source. - For example, in IoT, the sensor generates a piece of data at 12:00:00, and then transmits the data to Spark at 12:00:05,
Then the Event Time is 12:00:00 and the Processing Time is 12:00:05. - Spark Streaming is a micro batch mode based on DStream model, Simply put, it is to process the stream data of a small time period (for example, 1s) to the current batch data. If you want to count some data statistics of a time period, there is no doubt that Event Time should be used. However, because the data cutting of Spark Streaming is based on Processing Time, it is particularly difficult to use Event Time.
- The second point: Complex, low-level api
- The API provided by DStream (Spark Streaming data model) is similar to that of RDD, which is very low level;
- When writing Spark Streaming program, it is essentially to construct DAG execution diagram of RDD, and then
Spark Engine is running. This leads to a problem that DAG may be due to the uneven level of developers
To the great difference in execution efficiency;
- Third point: reason about end-to-end application
- End to end refers to direct input to out, such as Kafka accessing Spark Streaming and then exporting to HDFS;
- DStream can only ensure that its consistency semantics is exactly once, and input is connected to Spark
The semantics of Streaming and spark Streaming output to external storage often needs to be guaranteed by users themselves;
- The fourth point: the batch flow code is not unified
- Although batch flow is originally two systems, it is really necessary to unify the two systems. Sometimes it is necessary to integrate the two systems
Processing logic runs on batch data;
Although Streaming encapsulates RDD, it is still a little work to completely convert DStream code into RDD
Quantity, not to mention that Spark batch processing now uses dataset / dataframe API;
There has been no standardized model for streaming computing that can deal with various scenarios until Google published The
Thesis of Dataflow Model( https://yq.aliyun.com/articles/73255 ). Google open source Apache Beam project
The goal is basically the implementation of Dataflow model. At present, it has become the top project of Apache, but it is not widely used in China.
Apache Flink is used more in China, because Ali vigorously promotes Flink and even spends 700 million yuan to acquire Flink's parent company.
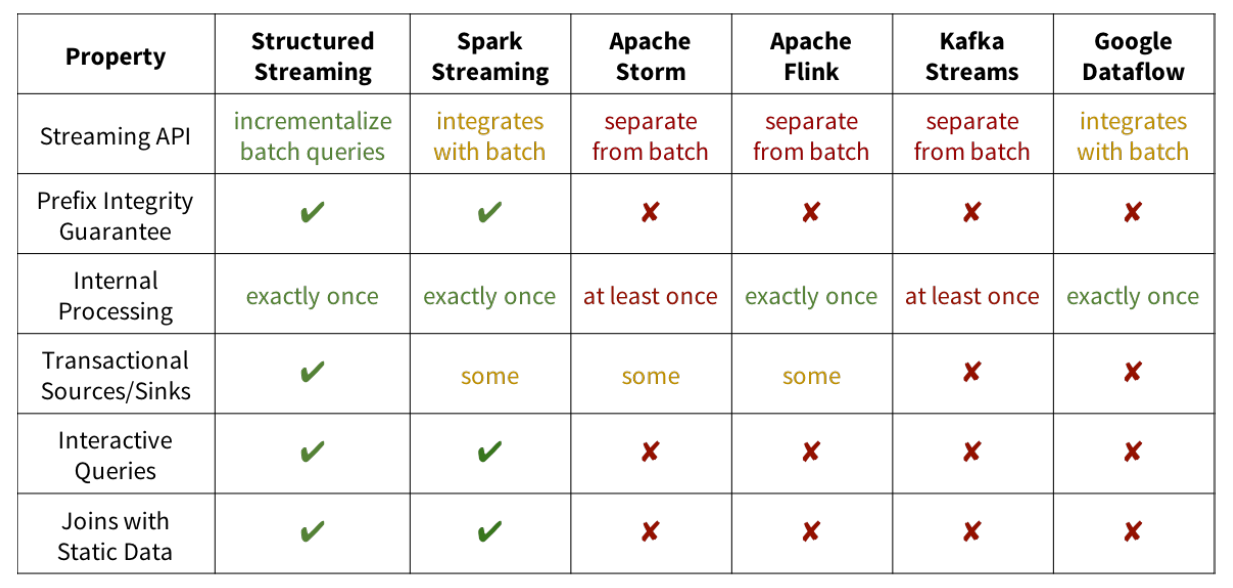
Using Yahoo's streaming benchmark platform, the system is required to read the ad Click event and add it to an ad campaign according to the activity ID
In the static table and output the activity count in the 10 second event time window. Compared Kafka streams 0.10 2,Apache Flink1.2.1 and spark 2.3 0, with 5 C3 in one 2 * 2 clusters of large Amazon EC2 working nodes and one master node (the hardware condition is 8 virtual cores and 15GB memory).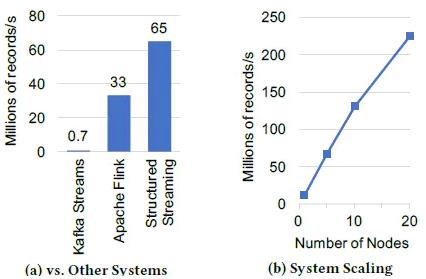
Figure (a) above shows the maximum stable throughput of each system (throughput before backlog). Flink can reach 33 million, while
Structured Streaming can reach 65 million, almost twice as much as Flink. This performance comes entirely from Spark SQL's built-in
Perform optimization, including storing data in a compact binary file format and code generation.
2 Structured Streaming overview
Perhaps it is a reference to the Dataflow model, or heroes think alike. Spark released a new flow computing model in version 2.0
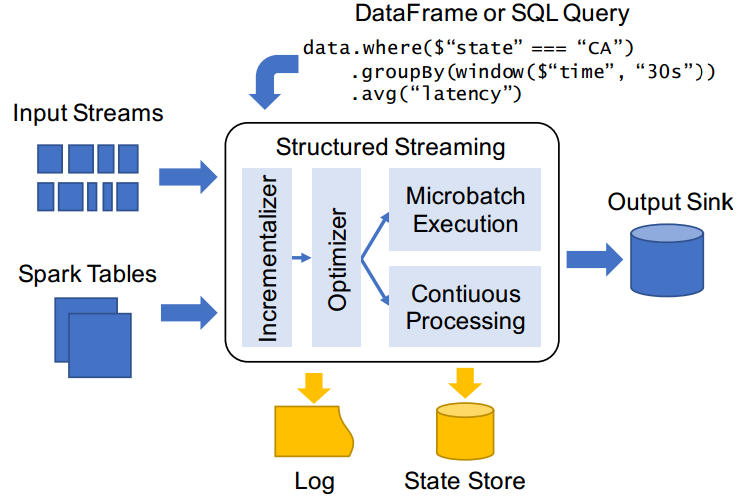
API: Structured Streaming. Structured Streaming is a scalable and fault-tolerant stream processing engine based on Spark SQL Engine. It unifies the programming model of flow and batch, can use the same way as static data batch processing to write flow computing operations, and supports event based computing_ Time window processing logic. As the data continues to arrive, the Spark engine will perform these operations in an incremental manner and continuously update the settlement results.

2.1 module introduction
Structured Streaming was introduced in Spark version 2.0 in 2016. The design idea refers to the ideas of many other systems, such as distinguishing between processing time and event time, using relational execution engine to improve performance, etc. At the same time, better integration with other Spark components is also considered.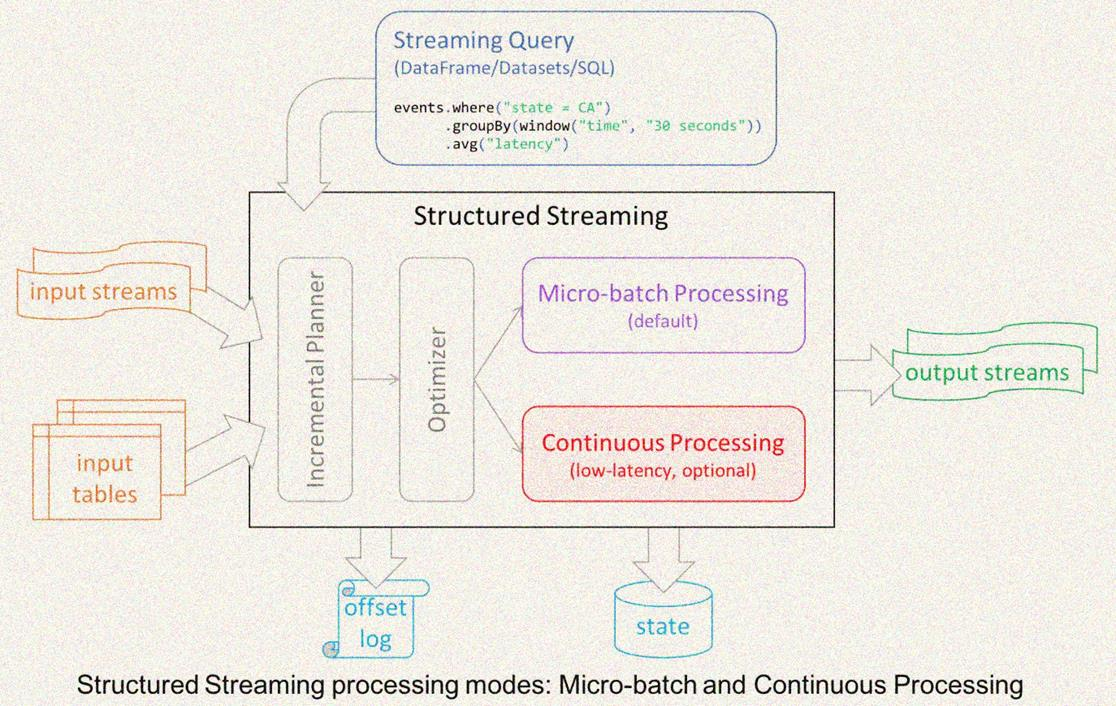
The significant differences between Structured Streaming and other systems are as follows:
- Point 1: Incremental query model
- Structured Streaming will continuously execute incremental queries on the new streaming data. At the same time, the code writing method is exactly the same as the batch API (based on Dataframe and Dataset API), and these APIs are very simple.
- Point 2: Support for end-to-end application
- Structured Streaming and built-in connector make the end-to-end program very simple to write, and "correct by default". The data source and sink satisfy the "exactly once" semantics, so that we can better integrate with external systems on this basis.
- Point 3: reuse Spark SQL execution engine
- Spark SQL execution engine has done a lot of optimization work, such as execution plan optimization, codegen, memory management, etc. This is also one reason why Structured Streaming achieves high performance and high throughput.
1.2. 2 core design
In 2016, Spark launched the Structured Streaming module in version 2.0. The core design is as follows:
- First point: Input and Output
- Structured Streaming has many built-in connector s to ensure the input data source and output sink to ensure the exactly once semantics.
- Prerequisites for implementing exactly once semantics:
- The Input data source must be replay able, such as Kafka, so that it can be re read when the node crash es
Take input data. Common data sources include Amazon Kinesis, Apache Kafka and file system. - Output sink must support idempotent writing, which is easy to understand. If output does not support idempotent writing, the consistency semantics is at least once. In addition, for some sink, structured streaming also provides atomic writing to ensure the exact once semantics.
- Supplement: idempotency: the definition of idempotency in HTTP/1.1: one and multiple requests for a resource should have the same result for the resource itself (except for network timeout). That is, any multiple execution of the resource will have the same impact on the resource itself as one execution. Idempotency is a commitment of the system service to the outside world (instead of implementation), it promises that as long as the interface is called successfully, the impact of multiple external calls on the system is consistent. Services declared as idempotent will think that external call failure is normal, and there will be retries after failure.
- Second point: Program API
- The Structured Streaming code completely reuses the batch API of Spark SQL, that is, query one or more streams or table s.

- The result of query is result table, which can be output to external storage in many different modes (append: append, update: update, complete).
- In addition, Structured Streaming also provides some API s specific to Streaming processing: trigger, watermark and stateful operator.
- Third point: Execution Engine
- Reuse Spark SQL execution engine;
- Structured Streaming uses a micro batch mode similar to Spark Streaming by default, which has many advantages
Such as dynamic load balancing, re expansion, error recovery, and retry by straggler (straggler refers to tasks that execute significantly slower than other tasks); - It provides a continuous processing mode based on the traditional long running operator;
- Point 4: Operational Features
- Using wal and State storage, developers can achieve centralized rollback and error recovery FailOver.
2.3 programming model
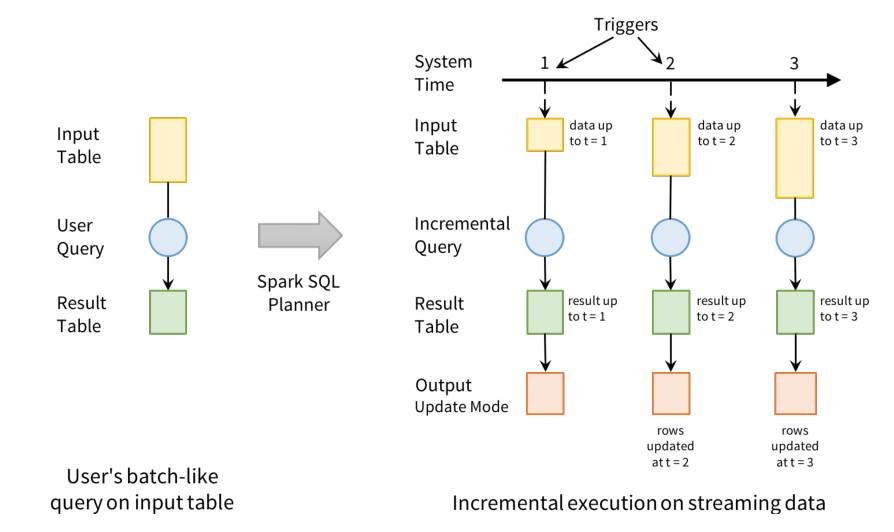
Structured Streaming treats streaming data as a growing table, and then uses the same set of API s as batch processing, both based on DataSet/DataFrame. As shown in the figure below, by understanding the streaming data as a growing table, you can manipulate the streaming data like the static data of the operation batch.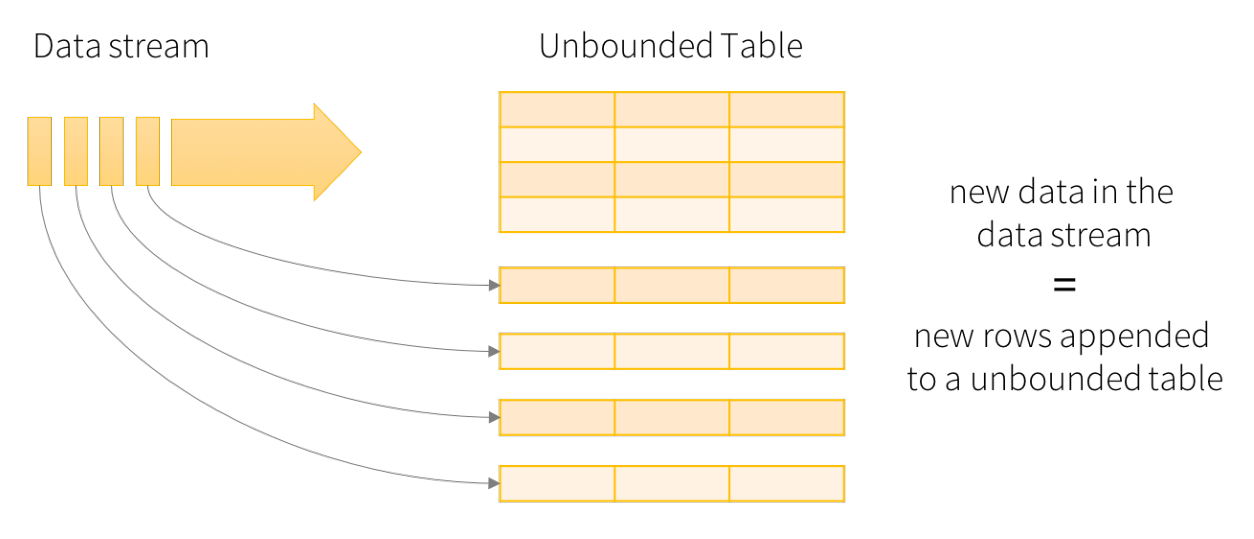
In this model, there are mainly the following components:
- Part I: Input Table (Unbounded Table), the abstract representation of streaming data, which has no limited boundary and table
Increasing data; - Part II: Query: incremental Query of Input Table. As long as there is data in the Input Table, Query analysis is performed immediately (by default) and then output (similar to micro batch processing in SparkStreaming);
- Part III: Result Table, the Result Table generated by Query;
- Part IV: Output, Result Table Output, Output results according to the set Output mode OutputMode;
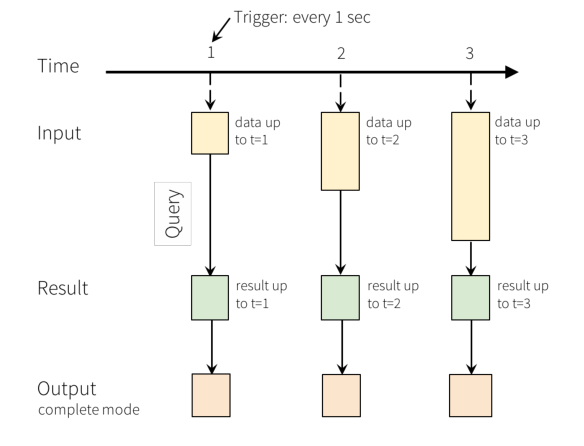
The core idea of Structured Streaming is to treat the data arriving in real time as an unbounded table that is constantly appended. Each data item arriving at the stream is like a new row in the table, which is attached to the unbounded table, and the stream is calculated by batch query of static structured data.
In the WordCount case of word frequency statistics, the schematic diagram of Structured Streaming real-time data processing is as follows, and the meanings of each line are as follows: - The first line indicates that data is continuously received from the TCP Socket, using [nc -lk 9999];
- The second line represents the time axis, and data processing is carried out every 1 second;
- The third row can be regarded as "input unbound table". When new data arrives, it will be added to the table;
- The fourth row, the final wordCounts, is the result table. After the new data arrives, the Query is triggered to output the result;
- Line 5: when new data arrives, Spark will execute an "incremental" query and update the result set; this example is set to CompleteMode, so all data will be output to the console every time;
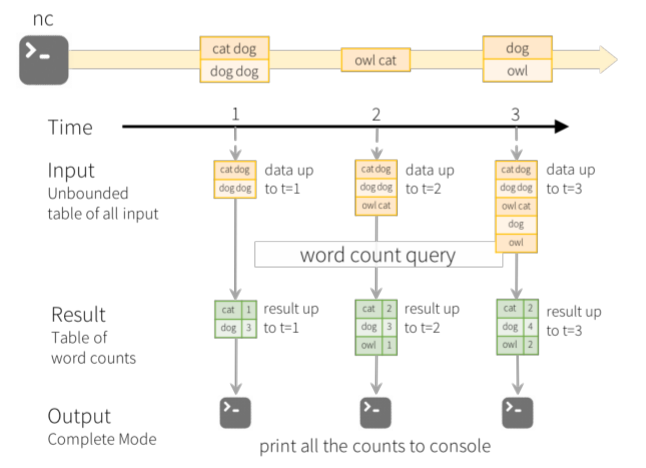
Description of real-time data processing in the figure above: - First, in the first second, the data arriving at this time are "cat dog" and "dog dog", so the result set cat=1dog=3 in the first second can be obtained and output to the console;
- Second, in the second second second, the data arriving is "owl cat". At this time, a row of data "owl cat" is added to the "unbound table"
Line word count to query and update the result set. The result set in the second second second is cat=2 dog=3 owl=1, which is output to the console; - Third, in the third second, the data arriving are "dog" and "owl". At this time, two lines of data "dog" and "owl" are added to the "unbound table"
"Owl", execute word count query and update the result set. The result set in the third second is cat = 2, dog = 4, owl = 2; When using Structured Streaming to process real-time data, it will be responsible for integrating the newly arrived data with historical data, completing correct calculation operations, and updating the Result Table.
3 introduction case: WordCount
The entry case is basically the same as that of SparkStreaming: read data from TCP Socket in real time (using nc), count WordCount in real time, and output the results to the Console.
file: http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#quick-example
3.1 function demonstration
Run the WordCount program of word frequency statistics and consume data from TCP Socket. The screenshot of the official demonstration is as follows: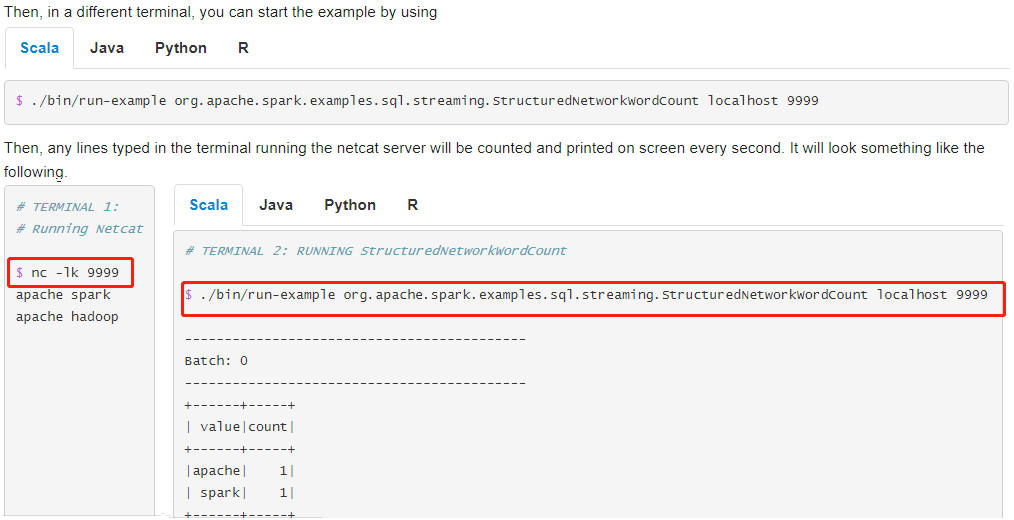
Demonstrate the steps to run the case:
- Step 1: open the Terminal and run NetCat. The command is nc -lk 9999
- Step 2: open another Terminal and execute the following command
# Official entry case operation: word frequency statistics /export/server/spark/bin/run-example \ --master local[2] \ --conf spark.sql.shuffle.partitions=2 \ org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount \ node1.itcast.cn 9999 # test data spark hadoop spark hadoop spark hive spark spark spark spark hadoop hive
After sending the data, the final statistical output results are as follows: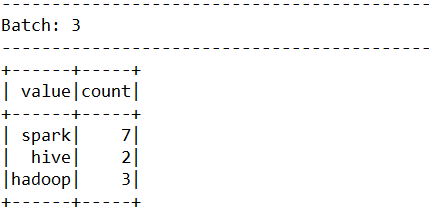
3.2 Socket data source
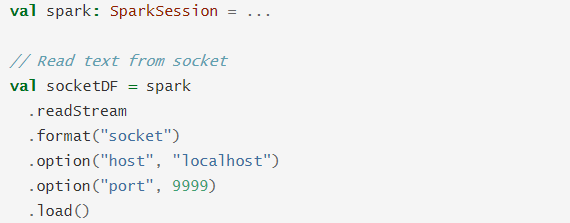
Read UTF8 text data from Socket. It is generally used for testing. The nc -lk port number is used to send data to the port monitored by the Socket. It is used for testing. There are two parameters:
- Parameter 1: host, host name, parameter must be specified
- Parameter 2: port, port number, must be specified
Examples are as follows:
3.3 Console receiver
Print the result data to the console or standard output, which is usually used for testing or Bedug. The three output modes OutputMode (Append, Update and Complete) are supported, and the two parameters can be set:
- Parameter 1: numRows, how many pieces of data to print, the default is 20;
- Parameter 2: truncate. If the value string of a column is too long, whether to intercept it. The default value is true. Intercept the string;
Examples are as follows:
3.4 programming
It can be considered that Structured Streaming = SparkStreaming + SparkSQL, the streaming data processing uses the SparkSQL data structure, and the application entry is SparkSession. Compare the programming of SparkSQL and SparkStreaming:
- Spark Streaming: the streaming data is divided into many batches according to the time interval (BatchInterval). Each Batch of data is encapsulated in RDD, and the underlying RDD data is used to build the streaming context real-time consumption data;
- Structured Streaming is a part of the SparkSQL module. It processes streaming data and constructs SparkSession objects,
Specify to read Stream data and save Stream n data. Specific syntax format:
- Load data: read static data [spark.read] and streaming data [spark.readStream]
- Save data save: save static data [ds/df.write] and streaming data [DS / DF. Writestream] word frequency statistics cases: consume streaming data from TCP Socket, make word frequency statistics, and print the results on the Console.
First, program entry SparkSession,Load streaming data: spark.readStream Second, data encapsulation Dataset/DataFrame When analyzing data, it is recommended to use DSL Programming, calling API,Rarely used SQL mode Third, start streaming application and set Output Results related information start Method to start the application
The complete case code is as follows:
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery}
import org.apache.spark.sql.{DataFrame,SparkSession}
/**
* Use Structured Streaming to read data from TCP Socket in real time, make word frequency statistics, and print the results to the console.
*/
object StructuredWordCount{
def main(args:Array[String]):Unit={
// TODO: building a SparkSession instance object
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions","2") // Set the number of Shuffle partitions
.getOrCreate()
// Import implicit transformations and function libraries
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: 1. Read data from TCP Socket
val inputStreamDF:DataFrame=spark.readStream
.format("socket")
.option("host","node1.itcast.cn").option("port",9999)
.load()
/*
root
|-- value: string (nullable = true)
*/
//inputStreamDF.printSchema()
// TODO: 2. Business analysis: word frequency statistics WordCount
val resultStreamDF:DataFrame=inputStreamDF
.as[String] // Convert DataFrame to Dataset for operation
// Filter data
.filter(line=>null!=line&&line.trim.length>0)
// Split word
.flatMap(line=>line.trim.split("\\s+"))
.groupBy($"value").count() // Group by word, aggregate
/*
root
|-- value: string (nullable = true)
|-- count: long (nullable = false)
*/
//resultStreamDF.printSchema()
// TODO: 3. Set Streaming application output and startup
val query:StreamingQuery=resultStreamDF.writeStream
// TODO: set the output mode: Complete means to output all the result data in the ResultTable
// .outputMode(OutputMode.Complete())
// TODO: set the output mode: Update means to output the updated result data in the ResultTable
.outputMode(OutputMode.Update())
.format("console")
.option("numRows","10").option("truncate","false")
// For streaming applications, start is required
.start()
// The streaming query waits for the streaming application to terminate
query.awaitTermination()
// Wait for all tasks to finish running before stopping
query.stop()
}
}
Different output modes (OutputMode) can be set. When set to Complete, the result table will be displayed in the ResultTable
All data are output; When set to Update, only the updated data in the result table is output.
4 DataStreamReader interface
From Spark 2.0 to Spark 2.4, there are currently four data sources supported, of which Kafka data source is widely used, and other data sources are mainly used to develop test programs.
file: http://spark.apache.org/docs/2.4.5/structured-streaming-programming-guide.html#input-sources

In Structured Streaming, use SparkSession#readStream to read streaming data, return DataStreamReader object, specify information related to reading data source, and declare as follows:
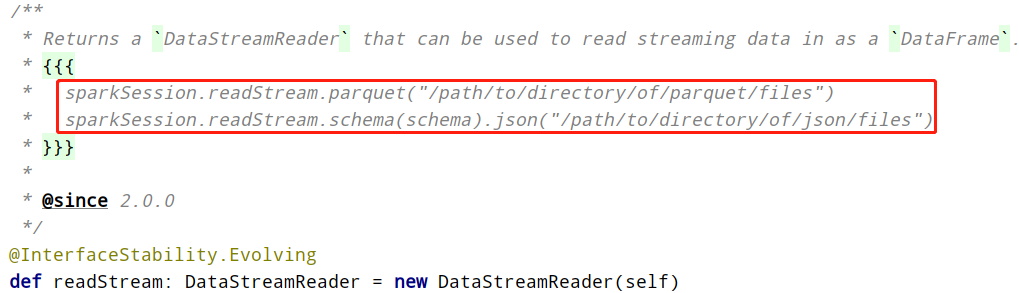
Viewing the methods in DataStreamReader, you can find that they are basically the same as those in DataFrameReader, and the coding is more convenient to load streaming data.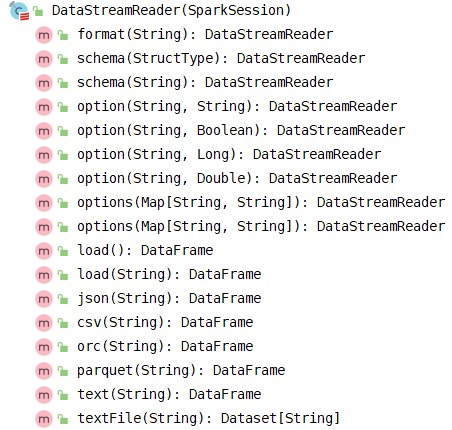
5 file data source
Read the files written in the directory as a data stream. The supported file formats are: text, csv, json, orc and parquet. You can set relevant optional parameters:

The pseudo code for loading data from the file data source is as follows:
val streamDF = spark
.readStream
// Schema must be specified when creating a streaming source DataFrame.
.schema(schema)
// Maximum number of files per trigger
.option("maxFilesPerTrigger",100)
// Whether to calculate the latest file first. The default is false
.option("latestFirst",value = true)
// Whether to check only the name. If the name is the same, it will not be regarded as an update. The default is false
.option("fileNameOnly",value = true)
.csv("*.csv")
Demo example: monitor a directory, read csv format data, and count the hobby ranking of people under the age of 25.
- test data
jack;23;running charles;32;basketball tom;28;football lili;24;running bob;20;swimming zhangsan;32;running lisi;28;running wangwu;24;running zhaoliu;26;swimming honghong;28;running`
- Business implementation code, monitoring Windows system directory [D: / data]
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery}
import org.apache.spark.sql.types.{IntegerType,StringType,StructType}
import org.apache.spark.sql.{DataFrame,Dataset,Row,SparkSession}
/**
* Use Structured Streaming to read file data from the directory: count the hobby ranking of people younger than 25 years old
*/
object StructuredFileSource{
def main(args:Array[String]):Unit={
// Building a SparkSession instance object
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// Set the number of Shuffle partitions
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// Import implicit transformations and function libraries
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: read CSV format data from file system, monitoring directory
// Data sample - > Jack, 23, running
val csvSchema:StructType=new StructType()
.add("name",StringType,nullable=true)
.add("age",IntegerType,nullable=true)
.add("hobby",StringType,nullable=true)
val inputStreamDF:DataFrame=spark.readStream
.option("sep",";")
.option("header","false")
// Specify schema information
.schema(csvSchema)
.csv("file:///D:/datas/")
// Analyze data according to business needs: make statistics on the hobby ranking of people under the age of 25
val resultStreamDF:Dataset[Row]=inputStreamDF
// Less than 25 years old
.filter($"age"< 25)
// Group statistics according to hobbies
.groupBy($"hobby").count()
// Sort by word frequency in descending order
.orderBy($"count".desc)
// Set Streaming application output and startup
val query:StreamingQuery=resultStreamDF.writeStream
// For streaming application output, set the output mode
.outputMode(OutputMode.Complete())
.format("console")
.option("numRows","10")
.option("truncate","false")
// For streaming applications, start is required
.start()
// The querier waits for the streaming application to terminate
query.awaitTermination()
query.stop() // Wait for all tasks to finish running before stopping
}
}
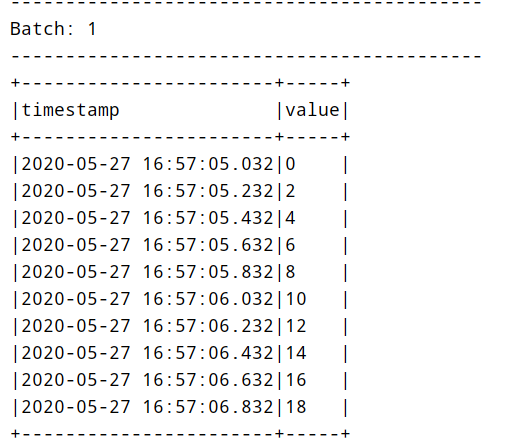
6 Rate source
Generate data at the specified number of rows per second. Each output row contains two fields: timestamp and value. Among them, timestamp is a time type containing information allocation, and value is a Long type (counting messages starting from 0 as the first line). This source is used for testing and benchmarking. The optional parameters are as follows:

The demonstration example code is as follows:
import org.apache.spark.sql.streaming.{OutputMode,StreamingQuery,Trigger}
import org.apache.spark.sql.{DataFrame,SparkSession}
/**
* Data source: Rate Source, which generates data at the specified number of rows per second. Each output row contains a timestamp and value.
*/
object StructuredRateSource{
def main(args:Array[String]):Unit={
// Building a SparkSession instance object
val spark:SparkSession=SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// Set the number of Shuffle partitions
.config("spark.sql.shuffle.partitions","2")
.getOrCreate()
// Import implicit transformations and function libraries
import spark.implicits._
import org.apache.spark.sql.functions._
// TODO: real time consumption data from Rate data source
val rateStreamDF:DataFrame=spark.readStream
.format("rate")
.option("rowsPerSecond","10") // Number of data generated per second
.option("rampUpTime","0s") // Generation interval of each data
.option("numPartitions","2") // Number of partitions
.load()
/*
root
|-- timestamp: timestamp (nullable = true)
|-- value: long (nullable = true)
*/
//rateStreamDF.printSchema()
// 3. Set Streaming application output and startup
val query:StreamingQuery=rateStreamDF.writeStream
// Set output mode: Append means that new data is output in Append mode
.outputMode(OutputMode.Append())
.format("console")
.option("numRows","10")
.option("truncate","false")
// For streaming applications, start is required
.start()
// The streaming query waits for the streaming application to terminate
query.awaitTermination()
// Wait for all tasks to finish running before stopping
query.stop()
}
}
Run the application and randomly generate the data. The screenshot is as follows: