The core of Spark is based on the same abstract Resilient Distributed Datasets (RDD), which enables the components of Spark to integrate seamlessly and complete big data processing in the same application
1. Basic concepts of RDD
RDD is the most important abstract concept provided by spark. It is a special data set with fault-tolerant mechanism. It can be distributed on the nodes of the cluster to carry out various parallel operations in the way of functional operation set
RDD can be understood as a collection of distributed objects, which is essentially a read-only collection of partition records. Each RDD can be divided into multiple partitions, and each partition is a data set fragment. Different partitions of an RDD can be saved to different nodes in the cluster, so parallel computing can be carried out on different nodes in the cluster.
Elasticity:
Storage elasticity: automatic switching between memory and disk
Fault tolerant resilience: data loss can be recovered automatically
Computational flexibility: computational error retry mechanism
Elasticity of slicing: it can be sliced again as needed
Distributed:
Data is stored on different nodes of the big data cluster
Dataset:
RDD encapsulates computing logic and does not save data
Data abstraction:
RDD is an abstract class, which needs the concrete implementation of subclasses
Immutable:
RDD encapsulates the computing logic and cannot be changed. If you want to change, you can only generate a new RDD. The computing logic is encapsulated in the new RDD (directed acyclic graph DAG)
Divisible:
Implement parallel computing
2. Core attributes of RDD
Partition list
There is a partition list in RDD data structure, which is used for parallel computing when executing tasks. It is an important attribute to realize distributed computing
Partition calculation function
Spark uses partition function to calculate each partition during calculation
Dependencies between RDD S
RDD is the encapsulation of computing models. When multiple computing models need to be combined in requirements, it is necessary to establish dependencies on multiple RDDS
Partition manager (optional)
When the data is KV type data, you can customize the partition of the data by setting the divider
Preferred location (optional)
When calculating data, you can select different node locations for calculation according to the status of the calculation node
3. Working principle of RDD
1) start the Yan cluster environment
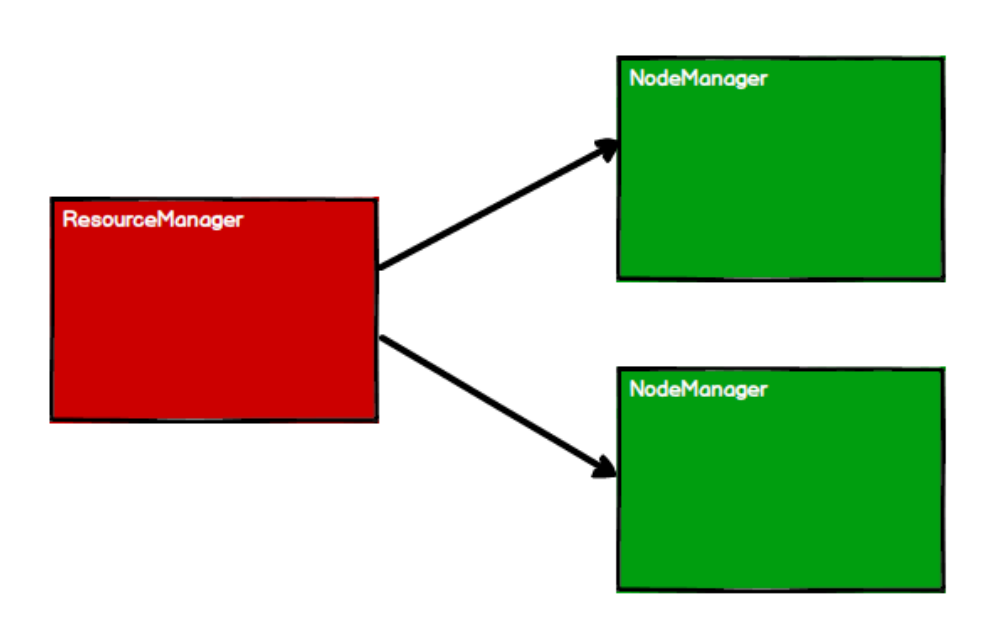
2) Spark creates scheduling nodes and computing nodes by applying for resources
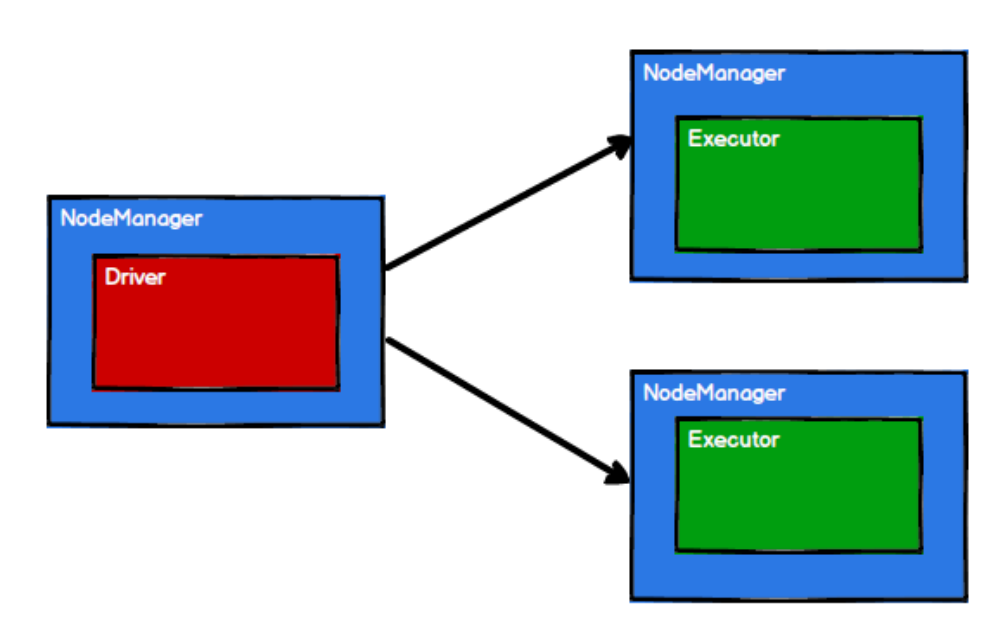
3) Spark framework divides the computing logic into different tasks according to the requirements
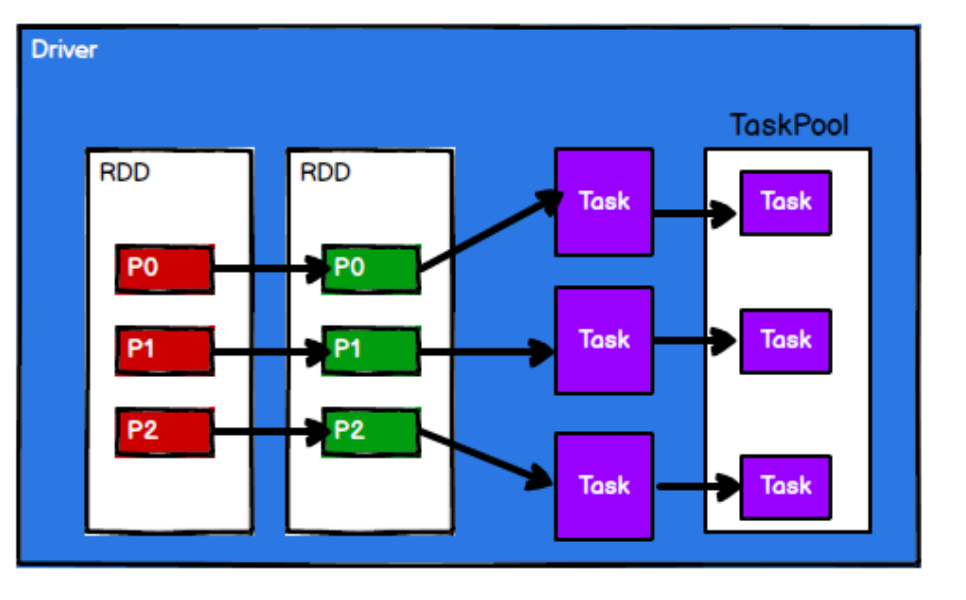
4) the scheduling node sends the task to the corresponding computing node for calculation according to the status of the computing node
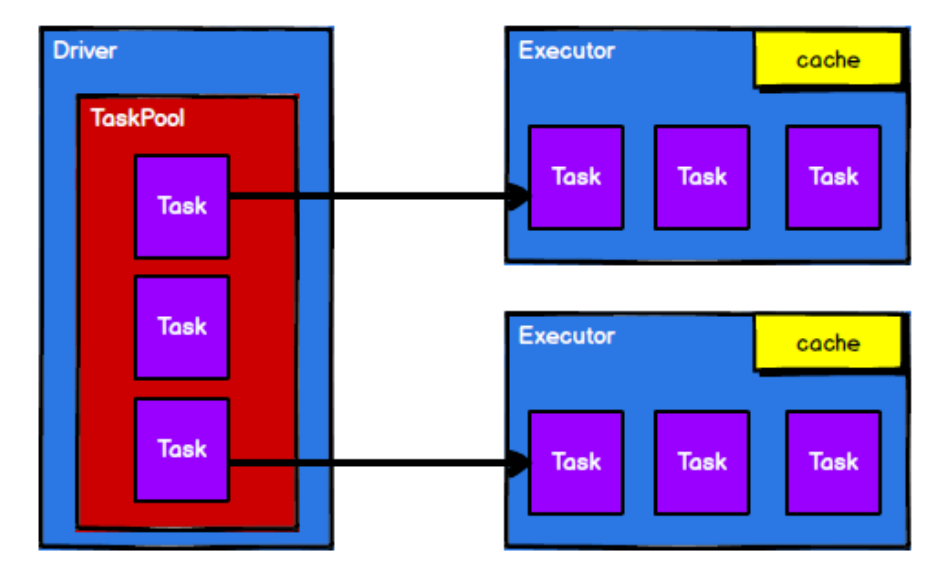
It can be seen from the above process that RD is mainly used for logical encapsulation in the whole process, and generates tasks and sends them to the Executor node for calculation
4.RDD creation
There are four ways to create RDD S in Spark:
1) Create RDD from collection (memory)
Spark mainly provides two methods for creating RDD S from collections: parallelize and makeRDD
val conf = new SparkConf().setMaster("local[*]").setAppName("test1")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1, 2, 3, 4))
val rdd2 = sc.makeRDD(List(1, 2, 3, 4))
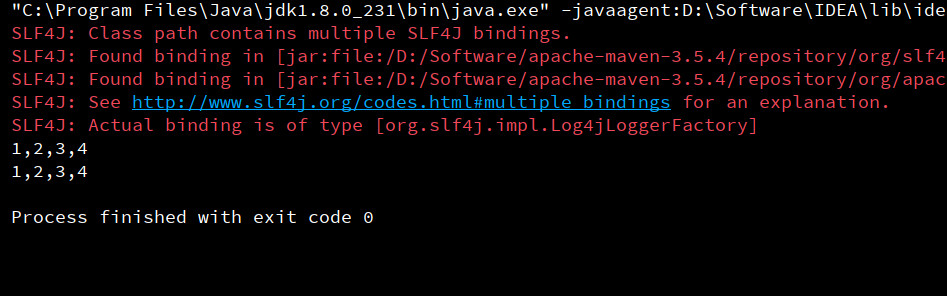
println(rdd1.collect().mkString(","))
println(rdd2.collect().mkString(","))
sc.stop()In terms of the underlying code implementation, the makeRDD method is actually the parallelize method
/** Distribute a local Scala collection to form an RDD.
*
* This method is identical to `parallelize`.
* @param seq Scala collection to distribute
* @param numSlices number of partitions to divide the collection into
* @return RDD representing distributed collection
*/
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
2) Create RDD from external storage (file)
RDD S are created from data sets of external storage systems, including local file systems and all data sets supported by Hadoop, such as HDFS, HBase, etc
val conf = new SparkConf().setMaster("local[*]").setAppName("test1")
val sc = new SparkContext(conf)
val rdd = sc.textFile("file:///D:\\Study\\13_spark\\cha01\\file\\tweets.txt")
rdd.collect().foreach(println)
sc.stop()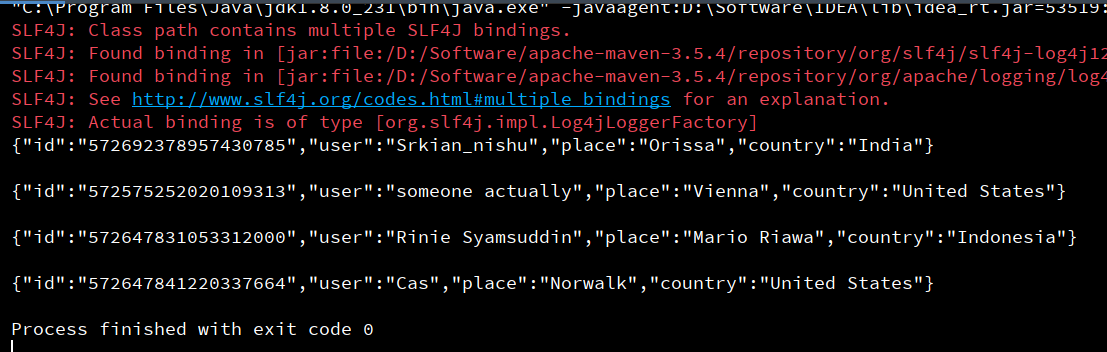
3) Create from other RDD S
It mainly generates a new RDD after an RDD operation
4) Create RDD directly (new)
RDD is directly constructed by using new, which is generally used by Spark framework itself
5.RDD operator
Value type
1)map
Function: returns a new RDD, which is composed of each input element converted by func function
Requirement: create an RDD and make each element * 2 form a new RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val listRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5))
//4. Each number is doubled
val rsRdd: RDD[Int] = listRdd.map(_ * 2)
//5. Print
rsRdd.foreach(println(_))
}
}
2)mapPartitions
It is similar to map, but runs independently on each fragment of RDD. Therefore, when running on an RDD of type T, the function type of func must be iterator [t] = > iterator [u]. Assuming that there are N elements and M partitions, the map function will be called N times, while mapPartitions will be called M times. One function will process all partitions at once.
Requirement: create an RDD and make each element * 2 form a new RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val listRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5))
//4. Each number is doubled
val rsRdd: RDD[Int] = listRdd.mapPartitions(i=>{i.map(_*2)})
//5. Print
rsRdd.foreach(println)
}
}
3)mapPartitionsWithIndex(func)
Similar to mapPartitions, but func takes an integer parameter to represent the index value of the partition. Therefore, when running on an RDD of type T, the function type of func must be (int, interlator [t]) = > iterator [u];
Requirement: create an RDD so that each element forms a tuple with its partition to form a new RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD for 2 partitions
val listRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 2)
//4. Each number is doubled
val rsRdd: RDD[(Int, Int)] = listRdd.mapPartitionsWithIndex((index, item) => {
item.map((index, _))
})
//5. Print
rsRdd.foreach(println)
}
}
4)flatMap(func)
Each element in the collection is manipulated and then flattened.
Requirement: extract the elements in the set according to '
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD for 2 partitions
val listRdd: RDD[String] = sc.makeRDD(List("Hello World","Hello Spark"))
//4. Flattening
val rsRdd: RDD[String] = listRdd.flatMap(_.split(" "))
//5. Print
rsRdd.foreach(println)
}
}
5)glom
Function: form each partition into an array to form a new RDD type [array [t]]
Requirements: create an RDD with three partitions and put the data of each partition into an array
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD S for 3 partitions
val listRdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8), 3)
//4,glom
val rsRdd: RDD[Array[Int]] = listRdd.glom()
//5. Print
rsRdd.foreach(item => {
println(item.mkString(","))
})
}
}
6)groupBy
Grouping: grouping according to the return value of the incoming function. Put the value corresponding to the same key into an iterator.
Requirement: create an RDD and group it with the value of 2 according to the element module.
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val listRdd: RDD[Int] = sc.makeRDD(1 to 20)
//4. Grouping
val rsRdd: RDD[(Int, Iterable[Int])] = listRdd.groupBy(_%2)
//5. Print
rsRdd.foreach(t=>println(t._1,t._2))
}
7)filter
Function: filtering. Returns a new RDD, which is composed of input elements whose return value is true after being calculated by func function.
Requirement: create an RDD, filter out the number with 2 and the remainder is 0
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val listRdd: RDD[Int] = sc.makeRDD(1 to 10)
//4. Filter
val rsRdd: RDD[Int] = listRdd.filter(_%2==0)
//5. Print
rsRdd.foreach(println)
}
}
8)distinct
De duplication partition
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val listRdd: RDD[Int] = sc.makeRDD(List(1,2,1,2,1,2))
//4. Save results with 2 partitions
val rsRdd: RDD[Int] = listRdd.distinct(2)
//5. Print
rsRdd.foreach(println)
}
}
9)repartition(numPartitions)
Repartition: randomly shuffle all data through the network according to the number of partitions.
Requirement: create an RDD with 4 partitions and repartition it
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create Rdd for 4 partitions
val listRdd: RDD[Int] = sc.makeRDD(1 to 10, 4)
println("repartition before:" + listRdd.partitions.size)
//4. Repartition
val rsRdd: RDD[Int] = listRdd.repartition(2)
//5. Print
println("repartition after:" + rsRdd.partitions.size)
}
}
10)sortBy(func,[ascending], [numTasks])
effect; Use func to process the data first and sort according to the processed data comparison results. The default is positive order.
Requirements: create an RDD and sort according to different rules
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create Rdd for 4 partitions
val listRdd: RDD[Int] = sc.makeRDD(1 to 10)
//4. Ascending order
val sortAsc: Array[Int] = listRdd.sortBy(x => x).collect()
println(sortAsc.mkString(","))
//5. Descending order
val sortDesc: Array[Int] = listRdd.sortBy(x => x, false).collect()
println(sortDesc.mkString(","))
}
}
Double Value type interaction
1) union(otherDataset)
Function: returns a new RDD after combining the source RDD and the parameter RDD
Requirements: create two RDD S and combine them
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create 2 list s
val list1: RDD[Int] = sc.makeRDD(1 to 2)
val list2: RDD[Int] = sc.makeRDD(2 to 4)
//4. Union level
val rsRdd: Array[Int] = list1.union(list2).collect()
//5. Print
rsRdd.foreach(println)
}
}
2)subtract (otherDataset)
Difference set, a function for calculating the difference. Remove the same elements in two RDDS, and different RDDS will be retained. Create two RDDS and find the difference set between the first RDD and the second RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create 2 list s
val list1: RDD[Int] = sc.makeRDD(1 to 10)
val list2: RDD[Int] = sc.makeRDD(5 to 10)
//4. Union level
val rsRdd: Array[Int] = list1.subtract(list2).collect()
//5. Print
rsRdd.foreach(println)
}
}
3)intersection(otherDataset)
Intersection: find the intersection between the source RDD and the parameter RDD and return a new RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create 2 list s
val list1: RDD[Int] = sc.makeRDD(1 to 10)
val list2: RDD[Int] = sc.makeRDD(5 to 10)
//4. Intersection
val rsRdd: Array[Int] = list1.intersection(list2).collect()
//5. Print
rsRdd.foreach(println)
}
}
Key value type
1)groupByKey
groupByKey also operates on each key, but only generates a sequence.
Requirement: wordcount
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create list
val list: RDD[String] = sc.makeRDD(List("Hello World","Hello Scala","Spark Spark Spark"))
//4,wordcount
val mapRdd: RDD[(String, Int)] = list.flatMap(_.split(" ")).map((_,1))
//5,groupByKey
val groupByKeyRdd: RDD[(String, Iterable[Int])] = mapRdd.groupByKey()
groupByKeyRdd.foreach(println)
//6. Aggregate
val wcRdd: RDD[(String, Int)] = groupByKeyRdd.map(t=>(t._1,t._2.size))
wcRdd.foreach(println)
}
}
2)reduceByKey
Call on a (K,V) RDD and return a (K,V) RDD. Use the specified reduce function to aggregate the values of the same key. The number of reduce tasks can be set through the second optional parameter.
Requirement: wordcount
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create list
val list: RDD[String] = sc.makeRDD(List("Hello World","Hello Scala","Spark Spark Spark"))
//4. Flattening
val mapRdd: RDD[(String, Int)] = list.flatMap(_.split(" ")).map((_,1))
//5,wordcount
val reduceMapRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_+_)
//6. Print
reduceMapRdd.foreach(println)
}
}
3)sortByKey([ascending], [numTasks])
Function: when called on a (K,V) RDD, K must implement the Ordered interface and return a (K,V) RDD sorted by key
Create a pairRDD and sort according to the positive and reverse order of key s
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create list
val listRdd: RDD[(Int, Int)] = sc.makeRDD(List((1, 3), (1, 2), (1, 4), (2, 3), (3, 6), (3, 8)))
//4. Ascending order
val sortAsc: Array[(Int, Int)] = listRdd.sortByKey(true).collect()
println("Ascending order:" + sortAsc.mkString(","))
//5. Descending order
val sortDesc: Array[(Int, Int)] = listRdd.sortByKey(false).collect()
println("Descending order:" + sortDesc.mkString(","))
}
}
4)join(otherDataset, [numTasks])
Call on RDDS of types (K,V) and (K,W) to return the RDD of (K,(V,W)) of all element pairs corresponding to the same key
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
val r1: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val r2: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rsRdd: Array[(Int, (String, String))] = r1.join(r2).collect()
rsRdd.foreach(println)
}
}
Action operator
1) reduce, function: gather all elements in RDD through func function, first aggregate data in partitions, and then aggregate data between partitions.
Requirement: create an RDD and aggregate all elements to get the result.
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 5)
//4,reduce
val rs: Int = rdd.reduce(_+_)
//5. Results
println(rs)
}
}
2) collect()
In the driver, all elements of the dataset are returned as an array.
Create an RDD and collect the RDD content to the Driver side for printing
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val lisrRdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
val ints: Array[Int] = lisrRdd.collect()
println(ints.mkString(","))
}
}
3) count()
Returns the number of elements in the RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10)
val rddCount: Long = rdd.count()
println(rddCount)
}
}
4)first()
Returns the first element in the RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10)
//4. Returns the first element in the RDD
val firstNum: Int = rdd.first()
println(firstNum)
}
}
5) take(n)
Returns an array of the first n elements of an RDD
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10)
val top3: Array[Int] = rdd.take(3)
top3.foreach(println)
}
}
6) takeOrdered(n)
Returns an array of the first n elements sorted by the RDD
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[Int] = sc.makeRDD(List(5, 3, 2, 1, 7, 6))
val top3: Array[Int] = rdd.takeOrdered(3)
println(top3.mkString(","))
}
7)countByKey()
For RDD S of type (K,V), a (K,Int) map is returned, indicating the number of elements corresponding to each key.
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[(Int, Int)] = sc.makeRDD(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)))
//4. Statistics key
val countKey: collection.Map[Int, Long] = rdd.countByKey()
//5. Print
println(countKey)
}
}
8)foreach
object SparkRdd {
def main(args: Array[String]): Unit = {
//1. Create local spark profile
val config: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//2. Create Spark context object
val sc = new SparkContext(config)
//3. Create RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5))
rdd.foreach(println)
}
}