introduction
I believe everyone has been exposed to containers when learning JavaSE. Generally, containers in Java can be divided into four categories: Map, List, Queue and Set containers. In the process of use, such containers as ArrayList and HashMap are often used, but the problem is that these containers will have thread safety problems in the concurrent environment. Therefore, when we use containers in a multithreaded environment, we generally use Vector and HashTable to replace the previous ArrayList and HashMap, or convert containers to thread safe through the following methods provided by Collections:
// Convert a List to a thread safe List Collections.synchronizedList(new ArrayList<E>()); // Convert a Set to a thread safe Set Collections.synchronizedSet(new HashSet<E>()); // Convert a map to a thread safe map Collections.synchronizedMap(new HashMap<K,V>());
However, regardless of the above method, the bottom layer is to ensure thread safety by adding the synchronized keyword modification to all methods. But the problem is: Although the thread safety problem is solved, it is guaranteed through the synchronized object lock. Therefore, when multiple threads operate the container at the same time, they need to block the queue, and the performance is worrying!
For example, feel it intuitively:
Map map = new HashMap<String,Object>();
Map syncMap = Collections.synchronizedMap(map);
T1 Thread: syncMap.put("Bamboo","panda");
T2 Thread: syncMap.get("xxx");
ok ~, in this case, assuming that T1 and T2 threads execute concurrently, T1 and T2 threads cannot execute at the same time, because T2 thread needs to wait until T1 thread put s to release the lock resources before it can obtain the lock resources for get operation. Why? As follows:
// Collections class → synchronizedMap method
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
// Encapsulates the incoming insecure map into a synchronized map object
return new SynchronizedMap<>(m);
}
// Collections class → SynchronizedMap internal class
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private final Map<K,V> m; // Incoming thread unsafe container
final Object mutex; // Object lock
// Synchronized map construction method
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this; // Object lock is this (current instance object lock)
}
// Only after the synchronized package is used outside, the original get method is called again
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
// Only after the synchronized package is used outside, the original put method is called again
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
// ..........
}
obvious. It can be seen from the above source code that when a thread wants to operate a container, it must first obtain the instance lock of the current container object. ok ~, then the Vector and HashTable will not be expanded. The principle is roughly the same, because all methods in the two classes are modified with the synchronized keyword.
If you don't know much about synchronized, you can refer to the previous article:< Analysis of the implementation principle of Synchronized keyword>
After JDK1.5, in the JUC concurrent package, three series of concurrent containers are introduced: blocking queue container, write time replication container and segmentation container. Next, we analyze the simple use of the three types of containers step by step from the implementation principle.
1, Blocking queue container
The biggest difference between a blocking queue and an ordinary queue is that it supports the blocking addition and blocking pop-up of elements in the queue, that is, when adding elements to the queue, if the queue is full, the thread currently adding elements will block until an element pops up in the queue, and the element will be added to the queue. The blocking pop-up is the same as if the queue were full If the column is empty, it will block until there are elements in the queue. There are mainly two types of blocking queues in JUC: one-way blocking queue and two-way blocking queue. The JUC package corresponds to BlockingQueue and BlockingDeque interfaces respectively. The overview of queues in Java is as follows:
- 1. BlockingQueue one-way FIFO first in first out blocking queue:
- ① ArrayBlockingQueue: bounded queue supported by array structure
- ② LinkedBlockingQueue: an optional bounded queue supported by a linked list structure
- ③ PriorityBlockingQueue: an unbounded priority queue supported by the minimum binary heap (priority heap) structure
- ④ DelayQueue: a time-based scheduling queue supported by the minimum binary heap (priority heap) structure
- ⑤ Synchronous queue: a synchronous blocking exchange queue (with only one element) that implements the simple aggregation mechanism
- ⑥ LinkedTransferQueue: unbounded queue supported by linked list structure (superset composed of 1 - ②, 1 - ⑤ and 3 - ① advantages)
- ⑦ DelayWorkQueue: customized unbounded priority queue of timed thread pool supported by minimum binary heap (priority heap) structure
- 2. BlockingDeque bidirectional blocking queue:
- ① LinkedBlockingDeque: optional bidirectional bounded queue supported by linked list structure
- 3. Other queues (non blocking queues):
- ① Concurrent linkedqueue: a concurrent unbounded queue supported by a linked list structure
- ② PriorityQueue: unbounded queues are supported by the minimum binary heap (priority heap) structure
- ③ Concurrent linked deque: concurrent bidirectional unbounded queue supported by linked list structure
- ④ ArrayDeque: bidirectional bounded queue supported by array structure
The above is the queue container provided in Java. Briefly explain the nouns: bounded, unbounded, unidirectional and bidirectional:
- Bounded: a fixed length can be set for the representative queue. When the number of elements in the queue reaches the maximum length of the queue, it cannot be listed
- Unbounded: the length of the queue does not need to be set. If memory allows, elements can be added until overflow. The default length is Integer.MAX_VALUE, which is equivalent to infinity for users
- One way: a queue that follows the first in first out FIFO principle
- Bidirectional: the queue of elements can be inserted / popped at both ends. The stack structure can be realized by using bidirectional queue
The above differences between different types of queues are mainly reflected in the different storage structures and operations on elements, but the principles of blocking operations are similar. Blocking queues in Java are implemented from the BlockingQueue interface, including the BlockingDeque interface, and inherit from the BlockingQueue interface. Therefore, let's take a brief look at the definition of the BlockingQueue interface:
public interface BlockingQueue<E> extends Queue<E> {
// If the queue is not full, insert the element e into the end of the queue, and return true if the insertion is successful,
// If the queue is full, throw the IllegalStateException
boolean add(E e);
// If the queue is not full, insert the element e into the end of the queue, and return true if the insertion is successful
boolean offer(E e);
// If the queue is not full, insert the element e into the end of the queue, and return true if the insertion is successful,
// If the queue is full, it is blocked until free space appears within the specified waiting time
// If the element has not been inserted into the queue beyond the specified time, it returns (in response to thread interruption)
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
// Insert the element at the end of the queue. If the queue is full, it will block and wait all the time
void put(E e) throws InterruptedException;
// Get and remove the header element of the queue. If there is no element, block the wait,
// Wake up and wait for the thread to perform the operation until a thread adds an element
E take() throws InterruptedException;
// Get and remove the header element of the queue, block the waiting element within the specified waiting time,
// If the element has not been obtained beyond the specified time, it returns (in response to thread interruption)
E poll(long timeout, TimeUnit unit) throws InterruptedException;
// If a specified element is removed from the queue, true will be returned if the removal is successful. If there is no such element, false will be returned
boolean remove(Object o);
// Gets the remaining available vacancies in the queue
// Assuming that the queue length is 10 and there are 3 elements, calling this method returns 7
int remainingCapacity();
// Check whether the specified element exists in the queue. If it exists, it returns true; otherwise, it returns false
public boolean contains(Object o);
// Get all available elements from the queue at once
int drainTo(Collection<? super E> c);
// Gets the specified number of available elements from the queue at one time
int drainTo(Collection<? super E> c, int maxElements);
}
Generally speaking, the methods in the blocking queue can be divided into three categories: Add / delete query. When using the blocking queue, the queue container is generally operated through these three methods. Of course, put/take operations are also called production / consumption, add / pop-up, add / obtain, etc. in some places, but the meanings are the same. Next, let's look at a simple use case of blocking queue:
public class BlockingQueueDemo {
// Create a blocking queue container
private static ArrayBlockingQueue<String> arrayBlockingQueue
= new ArrayBlockingQueue<String>(5);
// LinkedBlockingQueue linkedBlockingQueue = new LinkedBlockingQueue();
// PriorityBlockingQueue priorityBlockingQueue = new PriorityBlockingQueue();
// DelayQueue delayQueue = new DelayQueue();
// SynchronousQueue synchronousQueue = new SynchronousQueue();
// LinkedTransferQueue linkedTransferQueue = new LinkedTransferQueue();
// LinkedBlockingDeque linkedBlockingDeque = new LinkedBlockingDeque();
public static void main(String[] args) {
//Create producer and consumer tasks
Producer producerTask = new Producer(arrayBlockingQueue);
Consumer consumerTask = new Consumer(arrayBlockingQueue);
// Producer thread group
Thread T1 = new Thread(producerTask, "T1");
Thread T2 = new Thread(producerTask, "T2");
// Consumer thread group
Thread Ta = new Thread(consumerTask, "Ta");
Thread Tb = new Thread(consumerTask, "Tb");
T1.start();
T2.start();
Ta.start();
Tb.start();
}
// producer
static class Producer implements Runnable {
private BlockingQueue<String> blockingQueue;
private Producer(BlockingQueue<String> b) {
this.blockingQueue = b;
}
@Override
public void run() {
for (; ; )
producer();
}
private void producer() {
String task = "Bamboo-" + UUID.randomUUID().toString();
try {
blockingQueue.put(task);
System.out.println(Thread.currentThread().getName()
+ "Production task:" + task);
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//consumer
static class Consumer implements Runnable {
private BlockingQueue<String> blockingQueue;
private Consumer(BlockingQueue<String> b) {
this.blockingQueue = b;
}
@Override
public void run() {
for (; ; )
consumer();
}
private void consumer() {
try {
Thread.sleep(200);
String task = blockingQueue.take();
System.out.println(Thread.currentThread().getName()
+ "Consumption task:" + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/* *
* Execution results:
* T1 Production task: bamboo -f1ae18fc-de1c-49f2-b9c0-3b3c45ae2931
* Tb Consumption task: bamboo -46b45b67-4a1b-481a-80eb-3627d0c56a15
* T2 Production task: bamboo -46b45b67-4a1b-481a-80eb-3627d0c56a15
* Ta Consumption task: bamboo -f1ae18fc-de1c-49f2-b9c0-3b3c45ae2931
* .........
* */
}
The above code is a producer consumer case. Using the blocking queue to implement this case is much simpler than the previous wait/notify and condition. Add the task to the queue through the put() method to complete the production task, and obtain the task from the queue through the take() method to complete the consumption task. When the elements in the queue are full, the producer blocks and stops production, and when the queue is empty, Consuming threads will block and wait until a new task arrives.
In the above case, the blocking queue ArrayBlockingQueue is used to complete the producer consumer case, while other blocking queues will not be demonstrated, and the use methods are almost similar. ok ~, after a brief understanding of the use of blocking queues, continue to look at its implementation.
1.1. Principle analysis of ArrayBlockingQueue
Let's take a look at the internal members of ArrayBlockingQueue:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// ArrayBlockingQueue constructor: Specifies the queue length
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
// Constructor: specify queue length and fair mode
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
// Array structure of internal storage elements
final Object[] items;
// Record the subscript of the obtained element (take, poll, peek, remove methods are all used)
int takeIndex;
// Record the subscript of the added element (put, offer and add methods are all used)
int putIndex;
// The number of elements in the current queue
int count;
// ReentrantLock lock lock object that controls concurrency
final ReentrantLock lock;
// The condition object that controls the thread that gets the element
private final Condition notEmpty;
// The condition object that controls the thread that adds the element
private final Condition notFull;
// Iterator objects
transient Itrs itrs = null;
}
ArrayBlockingQueue internally uses an array member items to store all queue elements. It uses three values: takeIndex, putIndex and count to record the array location of added and obtained elements and the number of elements in the queue. At the same time, it internally uses ReentrantLock to solve the problem of line security, and uses two Condition objects: notEmpty and notFull to control the "write" thread and "read" Thread blocking. At the same time, it should be noted that the blocking operation of ArrayBlockingQueue is implemented based on ReentrantLock and Condition. Therefore, when creating ArrayBlockingQueue queue queue object, it can also be specified as fair / unfair mode. Therefore, fair mode means that the line blocked first must operate the queue first. ok ~, let's first look at the implementation of the put() method:
// ArrayBlockingQueue class → put() method
public void put(E e) throws InterruptedException {
// Check whether the element is null. If it is null, a null pointer exception will be thrown
checkNotNull(e);
// Gets the ReentrantLock member lock object
final ReentrantLock lock = this.lock;
// Responsive interrupt acquisition lock
lock.lockInterruptibly();
try {
// If the queue element is full
while (count == items.length)
// Block the thread currently adding the element
notFull.await();
// If the queue element is not full, perform the add operation
enqueue(e);
} finally {
// Release lock
lock.unlock();
}
}
The implementation of ArrayBlockingQueue.put() method is relatively simple. The overall execution process is as follows:
- ① Judge whether the element is null, and throw a null pointer exception if it is null
- ② Obtain lock resources (to ensure the safety of container operation in the case of multithreading)
- ③ Judge whether the queue is full. If it is full, the current execution thread will be blocked
- ④ If it is not full, enqueue(e) is called; Method
Next, let's continue to look at the ArrayBlockingQueue.enqueue() method:
// ArrayBlockingQueue class → enqueue() method
private void enqueue(E x) {
// Gets the items array member of the storage element
final Object[] items = this.items;
// Place the element at the putIndex subscript position of the array
items[putIndex] = x;
// For putIndex+1, if = array length after + 1, it will be reset to 0
if (++putIndex == items.length)
putIndex = 0;
// Record the value of the queue element count+1
count++;
// Wake up the thread waiting to get the queue element
notEmpty.signal();
}
Generally speaking, the logic is not complicated. In the ArrayBlockingQueue.enqueue() method, first get the array member items that store the queue elements, then insert the subscript position through the queue recorded by the member putIndex, put the elements in the input parameter at that position, then update the putIndex and count members, and wake up the thread blocking waiting to get the elements. However, it is worth noting that when the putIndex of the member inserted into the subscript in the record queue increases and becomes equal to the length of the array, the putIndex will be reset to 0. The reason is also very simple, because if it is not set to 0, the subscript will be out of bounds the next time the element is inserted.
ok ~, then let's look at the implementation of the take() method:
// ArrayBlockingQueue class → take() method
public E take() throws InterruptedException {
// Gets the member ReentrantLock lock object
final ReentrantLock lock = this.lock;
// Responsive interrupt acquisition lock
lock.lockInterruptibly();
try {
// If the queue is empty
while (count == 0)
// Block the thread currently getting the element through the condition object
notEmpty.await();
// If the queue is not empty, get the element
return dequeue();
} finally {
// Release lock
lock.unlock();
}
}
ArrayBlockingQueue.take() is the same as the previous ArrayBlockingQueue.put()
Compared with the method of inserting queue elements, the writing method is generally the same, except that the previous put() determines whether the queue is full, and if it is full, it blocks the current thread, while the current take() method determines whether the queue is empty, and if it is empty, it blocks the current thread of obtaining elements. Next, look at the ArrayBlockingQueue.dequeue() method:
// ArrayBlockingQueue class → dequeue() method
private E dequeue() {
// Gets the member array items of the storage queue element
final Object[] items = this.items;
@SuppressWarnings("unchecked")
// Gets the element in the array where the subscript is taseIndex
E x = (E) items[takeIndex];
// Clear elements at this location after getting
items[takeIndex] = null;
// + 1 for takeIndex
if (++takeIndex == items.length)
// If takeIndex = array length, set takeIndex to 0
takeIndex = 0;
// Record the number of queue elements count-1
count--;
// Also update the elements in the iterator
if (itrs != null)
itrs.elementDequeued();
// Wake up the thread of the add operation when an element is removed
notFull.signal();
// return
return x;
}
The logic of ArrayBlockingQueue.dequeue() method is also relatively simple, as follows:
- ① Gets the array member of the storage queue element
- ② Get the element at this location according to the queue subscript of takeIndex record
- ③ Empty the element data on the array subscript takeIndex
- ④ Update the values of the member takeIndex and count
- ⑤ Synchronously updates the element data in the iterator
- ⑥ Returns the obtained queue element object
So far, the principle analysis of adding / obtaining elements of the whole ArrayBlockingQueue blocking queue has been completed. Because the underlying layer of ArrayBlockingQueue adopts the principle of array as the storage structure, it is not difficult to analyze the source code. It is worth noting that the blocking in ArrayBlockingQueue is implemented based on ReentrantLock and Condition. ReentrantLock is used to ensure thread safety, and Condition is used to complete the blocking operation of adding / obtaining elements. ok ~, then let's analyze the implementation principle of another blocking queue: LinkedBlockingQueue.
For small partners who are not clear about the principle of Condition, please refer to the previous article:< (5) Deeply analyze the implementation principle of concurrent AQS exclusive lock reentrant lock and Condition>
1.2 principle analysis of LinkedBlockingQueue
The implementation principle of blocking queue is actually relatively simple. You can understand the implementation process of the blocking principle of queue by understanding the multi Condition waiting Condition principle of ReentrantLock. As for other types of blocking queues in Java, the implementation of blocking is almost the same. The difference lies in the different underlying storage structures and subtle differences in operation methods. Next, we will analyze A blocking queue: the implementation principle of LinkedBlockingQueue. LinkedBlockingQueue is an interesting queue container because it adopts the idea of separation of read and write, which improves the overall throughput of the container. Let's take a brief look at its internal members:
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// Constructor: queue length can be specified
public LinkedBlockingQueue(int capacity) {
// If the specified queue length is 0 or less, an exception is thrown
if (capacity <= 0) throw new IllegalArgumentException();
// Assign the passed in specified length to the capacity member
this.capacity = capacity;
// Initialize an empty node as the queue header node
last = head = new Node<E>(null);
}
// Constructor: if no length is specified, the default is Integer.MAX_VALUE
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
// LinkedBlockingQueue class → Node internal class
static class Node<E> {
// The current node stores the element itself
E item;
// Successor node of the current node
Node<E> next;
// constructor
Node(E x) { item = x; }
}
// The length of the queue (you can specify the length, which defaults to Integer.MAX_VALUE)
private final int capacity;
// Atomic counter: records the number of elements in the queue
private final AtomicInteger count = new AtomicInteger();
// The head node of the queue (internal linked list)
transient Node<E> head;
// Tail node of queue (internal linked list)
private transient Node<E> last;
// Read lock: this lock is used when a thread obtains an element from a queue
private final ReentrantLock takeLock = new ReentrantLock();
// When getting the element, the queue is empty, and the thread joins the condition queue to wait
private final Condition notEmpty = takeLock.newCondition();
// Write lock: this lock is used when a thread adds elements to a queue
private final ReentrantLock putLock = new ReentrantLock();
// When adding an element, the queue is full, and the thread joins the condition queue and waits
private final Condition notFull = putLock.newCondition();
}
As mentioned above, because LinkedBlockingQueue is a queue container based on the linked list structure, a one-way linked list is built through the internal class of Node. At the same time, AtomicInteger atomic class is used to record the number of elements in the queue. Head and last point to the head and tail of the queue respectively. At the same time, takeLock and putLock are used to control the read-write concurrent access of the queue container.
OK ~, next look at the put() method:
// LinkedBlockingQueue class → put() method
public void put(E e) throws InterruptedException {
// If the element is null, a null pointer exception is thrown
if (e == null) throw new NullPointerException();
int c = -1;
// Encapsulate the element to be added as a node node
Node<E> node = new Node<E>(e);
// Get the write lock
final ReentrantLock putLock = this.putLock;
// Gets the number of elements in the current queue
final AtomicInteger count = this.count;
// Responsive interrupt locking
putLock.lockInterruptibly();
try {
// If the queue is full
while (count.get() == capacity) {
// Suspend current thread
notFull.await();
}
// If the queue is not full, the encapsulated node node is added to the queue
enqueue(node);
// Update the count counter and get the count value before update
c = count.getAndIncrement();
// If the queue is not full
if (c + 1 < capacity)
// Wake up the next add thread to perform the element addition operation
notFull.signal();
} finally {
// Release lock
putLock.unlock();
}
// If the queue was empty before the update, an element is now added
// It means there must be data in the queue
// Then wake up the thread waiting to get the element
if (c == 0)
// Wake up the take thread if an element exists
signalNotEmpty();
}
// LinkedBlockingQueue class → enqueue() method
private void enqueue(Node<E> node) {
// Add the new node to the tail of the linked list
last = last.next = node;
}
As shown in the above source code, it is not difficult to find that the principle of adding elements to LinkedBlockingQueue and ArrayBlockingQueue is roughly the same. The difference is that LinkedBlockingQueue will wake up other threads in the waiting queue to perform the addition operation after adding elements, but the previous ArrayBlockingQueue will not. Why?
Because LinkedBlockingQueue uses two different locks to add and acquire elements, and the previous ArrayBlockingQueue uses the same lock to add and acquire elements, only one add / acquire operation is allowed to execute in ArrayBlockingQueue at the same time. Therefore, ArrayBlockingQueue will wake up the take thread after adding and the put thread after acquiring. In linkedblock Kingqueue is different. Two completely different locks are used, that is, the read / write of LinkedBlockingQueue is completely separated, and each uses its own lock for concurrency control. The threads adding elements and obtaining elements will not produce mutual exclusion, so this is why one thread will continue to wake up other threads waiting in the queue after adding elements. At the same time, this This approach can also greatly improve the throughput of the container.
ok ~, you can refer to the comments in the source code for the overall workflow of the put() method. Next, let's look at the implementation of the take() method:
// LinkedBlockingQueue class → take() method
public E take() throws InterruptedException {
E x;
int c = -1;
// Get the number of elements in the queue and the read lock
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
// Responsive interrupt locking
takeLock.lockInterruptibly();
try {
// If the queue is empty, suspend the current thread
while (count.get() == 0) {
notEmpty.await();
}
// If the queue is not empty, get the element
x = dequeue();
// Update the count member and get the count value before update
c = count.getAndDecrement();
// If there are still elements in the queue
if (c > 1)
// Wake up other threads waiting on the queue to continue the get operation
notEmpty.signal();
} finally {
// Release lock
takeLock.unlock();
}
// If the queue was full before, an element pops up now
// It means that there is a vacancy in the current queue, then wake up and add the thread
if (c == capacity)
signalNotFull();
return x;
}
// LinkedBlockingQueue class → dequeue() method
private E dequeue() {
// Get queue header node
// Because the head node is empty
// Therefore, the first node with data in the queue is:
// Successor node of head node
Node<E> h = head;
// Gets the successor node of the head node
Node<E> first = h.next;
h.next = h; // It is convenient for GC to empty the reference information
// Change the successor node of the head node into a head node
head = first;
// Gets the element data stored on the successor node
E x = first.item;
// Short the data of the successor node of the header node to change the successor node into a header node
first.item = null;
// Return the obtained data
return x;
}
Briefly describe the implementation process of LinkedBlockingQueue.take() method:
- ① Obtain the take lock and judge whether the queue is empty. If it is empty, suspend the current thread
- ② If it is not empty, the element information stored in the queue header node is removed and obtained
- ③ Update the count and obtain the count value before the update to judge whether there are still elements in the queue. If so, wake up other threads to continue execution
- ④ Judge whether the previous queue is full. If it is full, an element pops up, indicating that the queue is empty, then wake up the add thread
So far, the put/take principle of LinkedBlockingQueue has been analyzed. The biggest difference between LinkedBlockingQueue and ArrayBlockingQueue is that the underlying layer of LinkedBlockingQueue uses a one-way linked list structure and double locks. For simplicity, I call it "read lock" and "write lock", but don't be misled. This "read lock" is not a real read lock, Because if it is only a read operation, it does not need to be locked, and the take method of the queue needs to remove the element after reading the element, so it also involves a write operation. Naturally, it also needs to be locked to ensure thread safety. To be exact, what I call a "read / write lock" actually refers to a "take/put" lock.
OK ~, we will not continue to analyze other blocking queues, because the principle and implementation of internal blocking are roughly the same. The difference is that the internal data storage structure is different. If you are interested, you can read its source code implementation. The source code of the queue is not complex on the premise of understanding the data structure.
2, Copy container on write
In the introduction at the beginning of this article, it was mentioned that there will be thread safety problems for some commonly used containers in multi-threaded environment. Therefore, when it is necessary to ensure thread safety, Vector, HashTable or Collections.synchronizedXXX are generally used instead. Such methods can indeed ensure thread safety, but at the beginning of the article, we have already analyzed the defects of these methods: limited performance and poor concurrent throughput. In order to solve this problem, a new type of container is provided in the JUC package: copy on write container, which uses the idea of separation of read and write to improve the concurrent throughput of the container.
Copy on write container: copy on write container is a commonly used optimization idea in the field of computer programming. This idea is adopted in many system designs, such as Fork parent-child process data synchronization in Linux. The child process does not copy the data of the parent process when it is created, For the data that needs to be used, there is only a reference to the data address stored in the parent process. Each time the data is read from the parent process through the reference address, and the real copy action occurs when the data needs to be modified in the child process, copying a copy of the data in the parent process, After modification, change the pointer to the parent process data to the copy data. Of course, copy on write is actually the product of lazy loading and lazy loading. In the JUC package, there are mainly two kinds of copy containers on write: CopyOnWriteArrayList and CopyOnWriteArraySet. When using these two containers, the read operation will not be locked. When writing, the lock will be obtained first, and then a copy of the original data will be copied for modification. After modification, the original reference point will be modified.
ok ~, we will not elaborate on the use of CopyOnWriteArrayList and CopyOnWriteArraySet, because these two containers correspond to ArrayList and HashSet, and the use method is the same. Next, it analyzes the specific implementation process of write time copy container from the perspective of source code.
2.1 principle analysis of CopyOnWriteArrayList
CopyOnWriteArrayList is stored based on the array structure. The class structure is as follows:
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
// ReentrantLock exclusive lock: used to ensure thread safety
final transient ReentrantLock lock = new ReentrantLock();
// volatile modified array: used to store data. volatile ensures reading visibility
private transient volatile Object[] array;
// Packaging method of array
final void setArray(Object[] a) {
array = a;
}
// Constructor 1: initializing an array of length 0
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
//Constructor 2: the input parameter is a Collection collection object
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
// If the incoming Collection object is a COWL object, copy the data directly
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
// If not
else {
// Converts a Collection Object to an Object array
elements = c.toArray();
// If no array is returned after calling toArray()
if (elements.getClass() != Object[].class)
// Once again, convert the data of your copy set into an array
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
// Assign to array member
setArray(elements);
}
// Constructor 3: the input parameter is an array object
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
// COWIterator inner class: iterator. The iterator is not fail fast
static final class COWIterator<E> implements ListIterator<E> {
private final Object[] snapshot;
// Omit other codes
}
// COWSubList inner class: sublist. The same function as the sublist of ArrayList
private static class COWSubList<E> extends AbstractList<E>
implements RandomAccess{}
// Inner class of COWSubListIterator: iterator of sublist.
private static class COWSubListIterator<E> implements ListIterator<E> {}
}
ok, simply look at the internal members of CopyOnWriteArrayList. The ReentrantLock exclusive lock is used to ensure the security of the overall write operation of the container. It uses an Object type array modified by volatile keyword to store data. At the same time, CopyOnWriteArrayList has three internal classes: its own iterator, sub list and iterator class of sub list. It is worth noting that:
The iterator of CopyOnWriteArrayList is not fail fast, which means that when a thread traverses a CopyOnWriteArrayList object through the iterator, another thread writes to the container, which will not affect the thread traversing the container using the iterator. In the ArrayList container we often use, the iterator is fail fast. When one thread uses the iterator to traverse the data and the other performs modification, the iterator thread will throw an exception of ConcurrentModifyException.
Then, analyze the common methods in CopyOnWriteArrayList. First, look at the get(i) method:
// CopyOnWriteArrayList class → get() method
public E get(int index) {
return get(getArray(), index);
}
// CopyOnWriteArrayList class → get() overloaded method
private E get(Object[] a, int index) {
return (E) a[index];
}
The implementation of the get() method is clear at a glance. There is nothing to say, but to return the element data with the specified subscript of the array. Next, continue to look at the methods of modifying (writing) operations:
// CopyOnWriteArrayList class → set() method
public E set(int index, E element) {
// Get the lock object and lock it
final ReentrantLock lock = this.lock;
lock.lock();
try {
// Get the array member of the internal storage data: array
Object[] elements = getArray();
// Gets the original data of the specified subscript in the array
E oldValue = get(elements, index);
// If you specify the subscript position, the original stored data is different from the new data
if (oldValue != element) {
// Gets the length of the array
int len = elements.length;
// Copy a new array object
Object[] newElements = Arrays.copyOf(elements, len);
// Modifies the element at the specified subscript position to the specified data
newElements[index] = element;
// Change the reference of the member array from the original array to the new array
setArray(newElements);
} else {
// If the subscript position is specified, the original stored data is the same as the new data
// Do not make any changes
setArray(elements);
}
// Returns the value of the original subscript position
return oldValue;
} finally {
// Release lock / unlock
lock.unlock();
}
}
// CopyOnWriteArrayList class → add() method
public void add(int index, E element) {
// Acquire / lock
final ReentrantLock lock = this.lock;
lock.lock();
try {
// Get the array member of the internal storage data: array
Object[] elements = getArray();
int len = elements.length;
// If the specified subscript position exceeds the length of the array or is less than 0, an exception is thrown
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
// Create a new array object
Object[] newElements;
// The subscript position of the calculation insertion is in the middle of the array and at the end of the array
int numMoved = len - index;
// If it is at the end of the array, copy the original array with length + 1, leaving a space
if (numMoved == 0)
newElements = Arrays.copyOf(elements, len + 1);
// If you want to insert data in the middle of the array
else {
// First create a new array with length len+1
newElements = new Object[len + 1];
// Then copy all the data in the old array
// However, the position with index is empty
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index, newElements, index + 1,
numMoved);
}
// Set the data to be added to the index subscript position of the array
newElements[index] = element;
// Change the reference of the member array from the original array to the new array
setArray(newElements);
} finally {
// Release lock / unlock
lock.unlock();
}
}
// CopyOnWriteArrayList class → remove() method
public E remove(int index) {
// Acquire / lock
final ReentrantLock lock = this.lock;
lock.lock();
try {
// Copy the original array
Object[] elements = getArray();
// Gets the length of the array and the value to be removed from the array
int len = elements.length;
E oldValue = get(elements, index);
// Calculates whether the position to be removed is at the end of the array or in the middle of the array
int numMoved = len - index - 1;
// If at the end of the array
if (numMoved == 0)
// When copying an array, the last element is not copied
// Change the reference point again after the copy is complete
setArray(Arrays.copyOf(elements, len - 1));
// If the position to be removed is in the middle of the array
else {
// Create a new array with the original length of - 1
Object[] newElements = new Object[len - 1];
// When copying data, you can not copy the elements at the specified location
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
// Change the reference point of the member array
setArray(newElements);
}
// Returns the removed value
return oldValue;
} finally {
// Release lock / unlock
lock.unlock();
}
}
The three common write methods of CopyOnWriteArrayList are listed above: set(), add(), and remove(). Their execution processes are described below:
- The set() method is a direct replacement method. For example, if there is data in the specified subscript position, the previous data will be overwritten. This method needs to pass two parameters. The first parameter is the subscript position and the second parameter is the data itself to be set. The following is the execution process of the set method:
- ① After locking, obtain the original array and the original value of the specified subscript
- ② Judge whether the original value is the same as the new value. If it is the same, no modification will be made
- ③ When the old value is different from the new value, first copy the element data in the original array, then modify the data at the specified subscript position to the new value, and finally point the reference of the array member to the new array and release the lock
- ④ Returns the old value with the specified subscript replaced
- The parameters of the add() method and the set() method are the same, but the difference is that the add method does not replace the old value before the specified subscript position, but inserts the new value into the array. The execution process is as follows:
- ① Obtain array data and array length after locking
- ② Judge whether the subscript position of the data to be inserted exceeds the array length + 1 or is less than 0. If so, an exception will be thrown
- ③ Determine whether the subscript position of the data to be inserted is in the middle of the array or at the end of the array
- ④ If it is inserted at the last position, first create a new array with a length of + 1, copy all the data of the original array, add the data to be inserted to the last position of the array, and finally point the reference of the array member to the new array and release the lock
- ⑤ If the subscript position to be inserted is in the middle of the array, a new array with a length of + 1 will be created first, and all the data of the original array will be copied. However, the specified subscript position will be empty during copying, and then the data to be inserted will be added to the position. Finally, point the reference of the array member to the new array and release the lock
- The remove() method is a method to remove the data in the container. This method needs to pass in the subscript position to be removed. The execution process is as follows:
- ① After locking, obtain the original array data and its length, and obtain the original value of the specified subscript
- ② Determine whether the subscript position of the data to be deleted is in the middle of the array or at the end of the array
- ③ If it is at the last position of the array, the last element will not be copied when copying the array data. After that, point the reference of the array member to the new array and release the lock
- ④ If the subscript to be deleted is in the middle of the array, first create a new array with a length of - 1. At the same time, when copying the data, do not copy the element data at the specified subscript position. After that, point the reference of the array member to the new array and release the lock
OK ~, so far, the principle analysis of the three commonly used modification methods has been completed. The process is not complicated, but the more interesting ones are:
In fact, the removal methods in CopyOnWriteArrayList, such as remove, do not delete the element data of the specified subscript, or the removal methods in CopyOnWriteArrayList do not delete at all, but just "omit" the data of the specified subscript when copying data for a new array.
At the same time, because write operations use the same lock object for concurrency control, thread safety problems can also be avoided.
2.2 principle analysis of CopyOnWriteArraySet
As for the CopyOnWriteArraySet container, we will no longer analyze its internal implementation. Why? Let's look at its internal members. As follows:
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
implements java.io.Serializable {
// Structure of internal data storage
private final CopyOnWriteArrayList<E> al;
// constructor
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
}
Obviously, CopyOnWriteArraySet is actually implemented based on CopyOnWriteArrayList, so when we understand the principle and implementation of CopyOnWriteArrayList, we naturally understand the container CopyOnWriteArraySet.
2.3 copy container summary during CopyOnWrite writing
The advantages of the write time replication container are obvious. It makes full use of the idea of separation of read and write, improves the overall concurrent throughput of the container, and avoids the concurrent modificationexception thrown by concurrent modification. However, there are two fatal defects:
- ① Memory usage problem. Because the CopyOnWrite container copies a new array every time it is modified, the memory consumption is high when the array data is too large.
- ② Data inconsistency. The CopyOnWrite container ensures the final consistency. One thread is performing the modification operation and the other thread is performing the read operation. The read thread cannot see the latest data. Even if the setArray() method is changed to a new array after the modification operation is performed, the original read thread cannot see the latest data. Because the reading thread does not directly access the member array when performing the read operation, but obtains the array data in the form of the getArray() method. After the execution of the getArray() method, the reference obtained by the thread reading the data is already the address of the old array. After that, even modifying the direction of the member array will not affect the access of get.
It is also worth noting that when CopyOnWrite writes, the replication container only improves the throughput of read operations, and the write operations of the whole container are still based on the same exclusive lock to ensure thread safety. Therefore, if frequent write operations are required, the CopyOnWrite container is not suitable. At the same time, the performance will be degraded due to the memory and time overhead caused by replication.
3, Lock segmented container
The concept of lock segmented container is easy to understand. It means that a container is divided into different regions for operation. When operating in different regions, each lock resource is used to obtain / release locks to ensure thread safety. It was mentioned in the introduction that HashMap is thread unsafe. If you want to use it in multi-threaded situations, you need to use container operations such as HashTable. However, this kind of container is inefficient because it is a lock to control concurrency. In the concurrent package, a new container, concurrent HashMap, is introduced, which uses lock segmentation technology to improve the overall concurrent throughput of the container. However, before analyzing the implementation of concurrent HashMap, let's briefly talk about the principle of HashMap. The overall elaboration idea will be divided into three steps:
- ① Implementation principle of HashMap
- ② Discussion on the principle of concurrent HashMap in JDK1.7
- ③ Principle and implementation process of ConcurrentHashMap in JDK1.8
3.1 analysis of HashMap implementation principle
HashMap is a container based on hash table structure. The bottom layer is based on array + one-way linked list structure. The array length is 16 by default. The position of each array subscript is used to store the head node of each linked list. Each node of the linked list is an Entity object in JDK1.7, which is composed of three elements: key, value and next down pointer. The structure is roughly as follows:
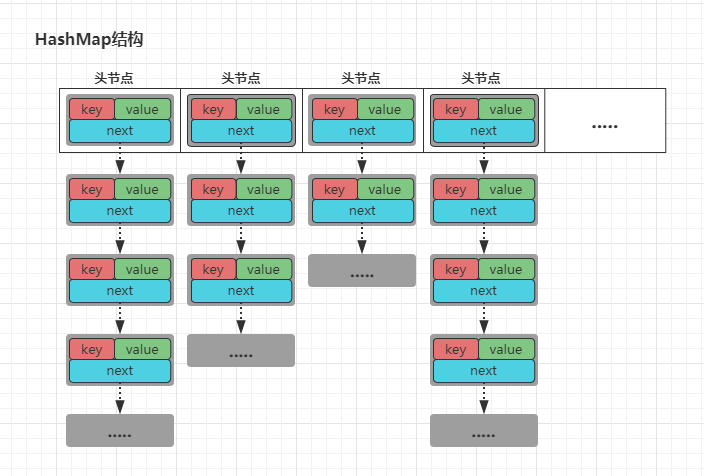
As shown in the figure above, in HashMap, the structure uses the form of array + one-way linked list to store data (each position of the array is also referred to as "bucket"), and the array structure is used to store the head node of each linked list. If there is data on the subscript position after calculation, it is appended to the tail of the linked list.
The principle and implementation of put() in HashMap:
- ① First, the key value is encapsulated as a node object
- ② Call the hashcode() method to calculate the hash value of the key
- ③ The hash value is converted into a specific subscript value through the hash algorithm
- ④ Store the key value data according to the calculated subscript position. However, it will be judged whether the subscript has data before storage:
- If not: store the data in the subscript position of the array as the chain header node
- If yes: the key value will be compared with the key value of each node in the linked list. If it is the same, it will be overwritten. If it is all different, the data will be added to the head of the linked list using the header interpolation method (jdk1.8 is followed by the tail interpolation method, which is added to the tail of the linked list)
HashMap's get() principle and Implementation:
- ① Call the hashcode() method to calculate the hash value of the key and calculate the specific subscript value
- ② Quickly locate a position in the array through the subscript value, and first judge whether there is data in the position:
- If not: indicates that the linked list does not exist at this location, null is returned directly
- If yes: the key value will be compared with the key value of each node in the linked list. If the key value is the same, the data of the node will be obtained and returned. If there is no node with the same key value after traversing the whole linked list, null will also be returned
Note: HashMap overrides the equals() method because equals() compares memory addresses by default. After rewriting, it compares key values in HashMap.
The principle and implementation of resize() expansion of HashMap:
- Preconditions: default capacity = 16, load factor = 0.75, threshold = capacity * load factor
- Capacity expansion condition: when the number of elements in the array container reaches the threshold, the capacity expansion action will occur
- Implementation process of capacity expansion:
- ① When the capacity reaches the threshold, create a new array twice the length and call the transfer() method to migrate the data
- ② Traverse all elements (header nodes) of the original old array, cycle each linked list according to each header node, and use header interpolation to transfer the data to the new array
Note: in 1.7, header insertion is used, so it is easy to cause dead loop and data loss in multi-threaded environment.
Differences between HashMap before and after JDK1.7:
| Comparison item | JDK1.7 front | JDK1.8 rear |
|---|---|---|
| Node type | Entry | Node/TreeNode |
| storage structure | Array + unidirectional linked list | Array + one-way linked list / red black tree |
| Insertion mode | Head insertion | Tail interpolation |
| Expansion opportunity | Expansion before insertion | Insert before expanding |
| Hash algorithm | 4th bit operation + 5th exclusive or | 1 bit operation + 1 XOR |
| Insertion mode | Array + unidirectional linked list | Array + one-way linked list / red black tree |
In JDK1.8, when the length of the linked list is greater than 8, the linked list structure will be transformed into a red black tree structure. But the premise is: when the array length is less than 64, if the length of a linked list is greater than 8, it means that the data hash conflict in the current array is serious. In this case, the red black tree conversion will not occur directly. Instead, the array will be expanded first, and then the data will be hashed and distributed again. Therefore, the real condition for converting the linked list to the red black tree is that the linked list will be transformed into the red black tree structure only when the array length has exceeded 64 and the number of elements in the linked list exceeds the default setting (8).
3.2 discussion on the principle of ConcurrentHashMap before JDK1.7
As mentioned earlier, using HashMap in a multithreaded environment is thread unsafe, and using thread safe HashTable is very inefficient. Therefore, ConcurrentHashMap was born. Lock segmentation technology was adopted in ConcurrentHashMap to realize finer grained concurrency control, so as to improve container throughput. Next, we can also take a look at its storage structure.
In JDK1.7, ConcurrentHashMap is implemented in the form of Segment array + HashEntry array + one-way linked list. The Segment inherits ReentrantLock, so the Segment object can also be used as a lock resource in ConcurrentHashMap. The structure is as follows:
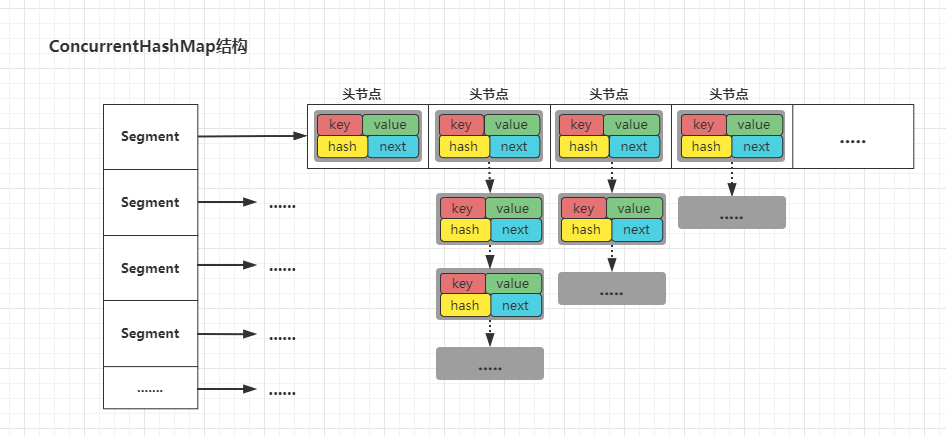
As mentioned above, each Segment of the ConcurrentHashMap is equivalent to a HashTable container. The length of Segment array is 16 by default, but the number of segments can be specified during creation. It must be a power of 2. If it is not a power of 2, it will be self optimized. When writing data, it will be locked in segments, and each Segment will not affect each other. When a thread reads data, it will not lock, but if a data is modified while reading, it will be locked again. However, it is worth noting that:
In each Segment (Segment object) of ConcurrentHashMap, there is a counter: the volatile modified count variable. Count represents the total amount of data of all linked lists in all HashEntry arrays in each Segment. In addition, there is a modCount counter in each Segment, which records the number of write operations in the current Segment. It is mainly used to judge whether there is a change operation in the Segment during cross Segment operation.
Principle and implementation of ConcurrentHashMap.put() before JDK1.7:
- ① Calculate the hash value according to the key value of the data, locate the specific segment position through the hash value, and check whether the segment is empty:
- Null: initialize the segment
- Not null: navigate to a specific segment location
- ② Obtain the lock resource of the segment, and then calculate the specific index (bucket) of the data stored in the HashEntry array in the segment according to the hash value
- ③ According to the calculated array index, the data is encapsulated into nodes and stored in this location. However, it will be judged whether the subscript has data before storage:
- No: store the data in the subscript position of the array to become the chain header node
- Yes: first judge whether the key value of the current data is the same as that of each node in the linked list:
- Same: replace previous data
- Difference: use the head interpolation method to insert the node into the head of the linked list (tail interpolation after 1.7)
- ④ Update the count value and release the lock
As mentioned earlier, the length of the Segment array of ConcurrentHashMap is 16 by default (customizable length), and the Segment inherits the role of ReentrantLock as a lock. In this way, it can be deduced that the default length of ConcurrentHashMap is 16 segments (customizable larger length), which means that 16 threads are allowed to write to the container at the same time in the most ideal state. But why is it the most ideal state? Because hash conflicts may occur, resulting in the data to be written by two threads located in the same Segment, it is often difficult to maximize the maximum throughput of the container in practical applications.
PS: neither key=null nor value=null is allowed in ConcurrentHashMap.
Principle and implementation of ConcurrentHashMap.get() before JDK1.7:
- ① Calculate the hash value according to the key value of the data, and locate the specific segment position through the hash value
- ② Thirdly, locate the specific array position in the segment according to the hash value, and obtain the header node stored in the array position
- ③ Traverse the entire linked list according to the head node, and judge whether the passed in key value is the same as the key value of each node:
- Same: return the value stored in this node
- All different: return null
- ④ If the key value is the same, but the read value is still null, it will be locked and read again
Why is it necessary to lock and reread when the key value is the same and the value is null? Because value=null is not allowed in ConcurrentHashMap, when there is a key but value is null, the data may be temporarily null due to instruction rearrangement, so it needs to be locked and re read once.
Principle and implementation of ConcurrentHashMap.size() before JDK1.7:
The size() in the ConcurrentHashMap needs to involve the entire container, and the number of elements in all segments needs to be counted. So how to achieve it?
- ① First record the modCount values of all segments and count the sum
- ② count the total number of record elements in all segments
- ③ After the statistics are completed, judge whether the modCount recorded before is the same as the modCount in each segment now:
- Same: it means that there is no write operation before and after statistics, and the total count of all segments is directly returned
- Difference: it means that the write operation has occurred before and after the statistics, and then execute step ① ② ③ again (three times at most)
- ④ If the write operation occurs before and after the sum of three statistics, the lock of all segments of the container is counted and returned
ok ~, so far, the principle analysis of ConcurrentHashMap before JDK1.7 is completed. Next, let's take a look at the implementation after 1.7.
3.3. Source code analysis of ConcurrentHashMap in JDK1.8
In JDK1.8, ConcurrentHashMap abandons the previous bloated implementation of Segment array + HashEntry array + one-way linked list, and adopts the lighter keyword Node array + linked list + red black tree + CAS+Synchronized. Let's take a look at the members of ConcurrentHashMap, as follows:
// Node node array. The element to be stored at each position in the array is the head node of each linked list transient volatile Node<K,V>[] table; // The table used for transition during capacity expansion. During capacity expansion, the node will be temporarily transferred to this array private transient volatile Node<K,V>[] nextTable; // Counter value = baseCount + each counter cell [i]. Value. So baseCount is only part of the counter private transient volatile long baseCount; // This value is stored differently in different cases, mainly in the following cases: // 1. When the array is not newly created, temporarily store the value of the capacity of the array // 2. When the array is being created, the member is - 1 // 3. When the array is normal, store the threshold // 4. When the array is expanded, the high 16bit stores a unique tag value corresponding to the old capacity, and the low 16bit stores the number of threads for expansion private transient volatile int sizeCtl; //It is used during capacity expansion. Under normal conditions, it is 0. It is the capacity at the beginning of capacity expansion, which represents the upper bound of the index of the next capacity expansion task private transient volatile int transferIndex; //Counter cell is matched with an exclusive lock private transient volatile int cellsBusy; //Counter cells are also part of the counter private transient volatile CounterCell[] counterCells; // There are three special node hash values. The normal hash value of a node is a positive number > = 0 // This node is the forwarding node during capacity expansion. This node holds the reference of the new table static final int MOVED = -1; // Represents that this node is a red black tree node static final int TREEBIN = -2; // This node is a placeholder node and does not contain any actual data static final int RESERVED = -3;
ok ~, the above are some members of ConcurrentHashMap. Next, let's look at their node types. The nodes of ConcurrentHashMap are slightly complex, as follows:
- Node: if the structure of a subscript position (bucket) of the array is a one-way linked list, all data will be encapsulated as node nodes and added to the linked list. The value and next pointers of node class are modified by volatile to ensure the visibility of write operations
- TreeNode: if the structure of a subscript position (bucket) of the array is a red black tree structure, the nodes stored in the bucket are of TreeNode type
- TreeBin: the encapsulation of TreeNode, which is used as the root node on the array subscript. However, TreeBin is not the real root node, and the root node is the root member encapsulated in it. The advantage of this packaging is that the root node of the red black tree may change at any time with the balanced rotation operation. Therefore, if the TreeNode is directly used as the root node, the members of the array will often change, and the array members will not change if encapsulated with TreeBin
- ForwardingNode: the forwarding node during capacity expansion. This node holds the reference of the new table
- ReservationNode: a placeholder node that does not contain any actual data
PS: the timing of converting the ConcurrentHashMap of 1.8 and the HashMap of 1.8 to the red black tree is the same: when the array capacity > = 64 and the length of a single linked list > = 8, the subscript position (bucket) will be converted from the linked list structure to the red black tree structure
3.3.1. Source code analysis of ConcurrentHashMap.put() in JDK1.8
put() method is the core of the whole ConcurrentHashMap, and it also involves many aspects: container initialization, insertion operation, capacity expansion, counting statistics, etc. next, analyze its implementation principle from the perspective of source code:
// ConcurrentHashMap class → put() method
public V put(K key, V value) {
// Call its internal putVal() method
return putVal(key, value, false);
}
// ConcurrentHashMap class → putVal() method
final V putVal(K key, V value, boolean onlyIfAbsent) {
// Check whether key and value are empty
if (key == null || value == null) throw new NullPointerException();
// Calculate a new hash value based on the original hash value of the key
int hash = spread(key.hashCode());
// Represents the number of nodes in a location (bucket)
int binCount = 0;
// Start traversing the entire table array (Node array)
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// If the array is not initialized
if (tab == null || (n = tab.length) == 0)
// Initialize the array
tab = initTable();
// If the subscript position calculated from the hash value is null
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// The CAS mechanism is used to encapsulate the existing data into a Node node, which is inserted into the location to become the head Node
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
// When inserting into an empty bucket (empty box), it does not need to be locked and cannot be locked (analyzed later)
break;
}
// If the calculated subscript position is not empty, but the hash value of the node is MOVED
// The bucket representing the current position is performing capacity expansion
else if ((fh = f.hash) == MOVED)
// The current thread performs a capacity expansion operation
tab = helpTransfer(tab, f);
// If the calculated subscript position is not empty and the hash value is not MOVED
else {
V oldVal = null;
// Lock the element (header node) at the subscript position of the array as the lock resource
synchronized (f) {
// After locking is successful, check whether f is the head node again
if (tabAt(tab, i) == f) {
// If the hash value > = 0, it represents a normal node
if (fh >= 0) {
// binCount=1
binCount = 1;
// Traverse the entire linked list according to the head node, and binCount+1 for each traversal
for (Node<K,V> e = f;; ++binCount) {
K ek;
// If the key of the node is the same as the passed in key
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
// Replace old value with new value
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
// Stop traversal operation
break;
}
// If no node with the same key value is found in the whole linked list
Node<K,V> pred = e;
// Find the tail of the linked list
if ((e = e.next) == null) {
// Encapsulate the incoming data as a Node and insert it into the tail of the linked list
pred.next = new Node<K,V>(hash, key,
value, null);
// Stop the linked list traversal operation after the insertion is completed
break;
}
}
}
// If the header node is a TreeBin type
// The structure representing the current position has changed to a red black tree structure
else if (f instanceof TreeBin) {
Node<K,V> p;
// When binCount=2, binCount is fixed to 2 in red black tree structure
binCount = 2;
// Call the putTreeVal method with the passed in K, V and hash values as parameters
// The putTreeVal method may return two results:
// ① If no Node with the same key is found in the whole tree, the new Node insertion returns null
// ② Find the node with the same key and return the original value
// If a node with the same key value is found
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
// Replace old value with new value
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// If bincount= 0, which means that the current thread must have performed a write operation
if (binCount != 0) {
// If the number of linked list nodes reaches 8
if (binCount >= TREEIFY_THRESHOLD)
// Perform capacity expansion or linked list to red black tree
treeifyBin(tab, i);
// If this put operation is only a new value for an old value, the old value is returned
if (oldVal != null)
return oldVal;
break;
}
}
}
// If this put is an insert operation, the size will increase by 1
addCount(1L, binCount);
// And returns null
return null;
}
ok, the above is the source code implementation of the ConcurrentHashMap.put method. The execution process is as follows:
- ① Judge whether the passed key and value values are empty, and throw a null pointer exception if they are empty
- ② Calculate the new hash value according to the hashCode value of the key
- ③ If the entire array is empty, it means that the container has not been initialized, and the initialization operation is performed
- ④ Locate the calculated hash value to the specific subscript position of the array, and judge whether the position is empty
- Empty: indicates that the bucket does not have a header node, then the CAS mechanism is used to encapsulate the current data as a node and add it to the location
- Not null: judge whether the hash value of the head node of the current position (bucket) is MOVED
- Yes: it means that the current position (bucket) is in the capacity expansion stage, and the current thread helps to expand the capacity
- No: it means that the current position (bucket) is in the normal stage and is ready to execute the put operation
- ⑤ The head node is used as the lock resource to perform the lock operation. After the lock is successful, judge whether the head node is removed again. If not, execute the put operation
- ⑥ Judge whether the hash value of the header node is > = 0. If it is true, it means that the current node is an ordinary chain header node, and binCount=1
- ⑦ Start traversing the whole linked list according to the pointer of the head node, and judge whether the passed key value is the same as the key value of the node in the linked list:
- Same: represents the same key value. Replace the old value with the new value and return the old value
- Difference: encapsulate the data into a node object, insert it into the tail of the linked list using the tail insertion method, and return null
- Note: when traversing the linked list, binCount will be + 1 for each node traversed
- ⑧ If the type of the head node is TreeBin, the structure representing the current position (bucket) has changed into a red black tree, binCount=2
- ⑨ Call putTreeVal() method to find the whole tree and check whether there are nodes with the same key value:
- Yes: return the old value, execute the operation of replacing the old value with the new value externally, and return the old value
- No: encapsulate the data into a tree node, insert it into the red black tree, and return null
- ⑩ Judge whether binCount > = 8. If yes, it means that the current linked list is too long. Call treeifBin method to expand or treelize
- ⑪ Judge whether this put operation is a new value for an old value:
- Yes: returns the old value
- No: it means that it is an insert operation. For size+1, null is returned
Note:
① Why use CAS mechanism to add elements without locking when the calculated subscript position (bucket) element is empty?
Because the concurrencthashmap after 1.8 implements the locking mechanism based on the synchronized keyword, while the synchronized is locked based on the object. If the subscript position element is empty, it means that there is no header node, so it cannot be locked based on the header node. Therefore, it can only be added through the CAS mechanism to add the first data to the subscript position into the header node.
② binCount: in the case of linked list structure, when traversing the linked list, binCount will increase by 1 for each node traversed, while in the case of red black tree structure, binCount will remain 2. Why?
Because the final function of binCount is to judge whether the current location is expanded or trealized, and only in the case of linked list structure, it needs to be expanded or trealized.
③ After the treeifBin() method is called, the tree will not occur directly. Instead, it will first judge whether the array length of the current ConcurrentHashMap has been > = 64. If it is less than this length, the expansion operation will occur instead of the linked list to red black tree operation.
At this point, the execution of the entire ConcurrentHashMap.put method ends.
3.3.2. Source code analysis of ConcurrentHashMap.get() in JDK1.8
No more nonsense. Let's start with the source code, as follows:
public V get(Object key) {
// Define relevant local variables
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// Calculate the new hash value through the hashcode of the key
int h = spread(key.hashCode());
// If the array is not empty, the array has been initialized, and the calculated specific subscript position is not empty
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// Judge whether the key of the header node is the same as the passed in key
if ((eh = e.hash) == h) {
// If it is the same, the value stored in the header node is returned directly
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// If the hash value of the header node is less than 0, it means that the current position (bucket) is in a special state. There are three types:
// ① It is a ForwardingNode node: it is currently in capacity expansion and needs to be forwarded to nextTable for lookup
// ② It is a TreeBin node: it represents that the current position is a red black tree structure, and binary search is required
// ③ It is a ReservationNode node: it represents that the current slot is null before it is a placeholder node, so null is returned directly
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// If the head node is a normal node, the whole linked list is traversed according to the next pointer
while ((e = e.next) != null) {
// Compare whether the key values in each node are the same. If they are the same, the value value in the node is returned
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
// If no node with the same key value is found in the linked list, null is returned
return null;
}
The source code execution process of the ConcurrentHashMap.get method is as follows:
- ① Calculate the new hash value from the passed in key value
- ② Judge whether the array inside the map is empty, whether it has been initialized, and whether the location (bucket) of the key is empty
- ③ Judge the calculated bucket position and whether the head node is the data to be found. If so, directly return the value of the head node
- ④ Judge whether the hash value of the header node is less than 0. If less than 0, it means that the current position (bucket) is in a special state. There are three cases:
- It is a ForwardingNode node: it is currently in capacity expansion and needs to be forwarded to nextTable for lookup
- It is a TreeBin node: it represents that the current position is a red black tree structure, and binary search is required
- It is a ReservationNode node: it represents that the current slot is null before it is a placeholder node, so null is returned directly
- ⑤ If the head node is an ordinary linked list node, traverse the entire linked list according to the head node to determine whether the key s in each node are the same:
- Same: return the value in the corresponding node
- Traverse the entire linked list and find the node with the same key value, which means there is no such data and returns null
ok ~, here the execution of the get method is also finished.
3.3.3 summary of ConcurrentHashMap in JDK1.8
In contrast, 1.8 discards the previous bulky structure of Segment array + HashEntry array + one-way linked list to implement ConcurrentHashMap. In 1.8, the storage structure is implemented in the way of array + linked list + red black tree. At the same time, in terms of locking mechanism, it was locked by Segment object before, but in 1.8, Use the synchronized keyword to lock the elements at each position of the array. Theoretically, the length of the array in ConcurrentHashMap will determine how many lock objects there are. When the array subscript position of a key after hash calculation is empty and cannot be locked based on the header node, it is added through CAS lockless mechanism. However, because ConcurrentHashMap still implements high throughput in the form of segmentation, there will be some deviation in the data when cross Segment operations are involved, such as the size() method.
ConcurrentHashMap is an unordered container. When you want to achieve orderly storage, will there be a container such as ConcurrentTreeMap? The answer is No. if you need to implement sorting, you have to use ConcurrentSkipListMap. ConcurrentSkipListMap is a container based on jump table. If you are interested, you can also study its implementation principle. In addition, there are other concurrent containers, such as ConcurrentSkipListSet, ConcurrentLinkedQueue, ConcurrentLinkedDeque, etc. (not segmented containers, but concurrent containers).
4, Summary
Previously, we mentioned three types of concurrent containers: blocking queue container, write time replication container and lock segmentation container. Each type of container has many implementations, and the biggest difference lies in its internal storage structure. Each type of container has its own advantages and disadvantages, such as the singleness of blocking queue, the memory overhead of replication on write, the inconsistent data of segmented containers, etc. Therefore, in the actual development, it is more necessary to select the appropriate concurrent container according to the business scenario.