1, Introduction to blocking queue
Queue is often used to solve production consumer problems. Queue interface and some general abstract methods are defined in Java
public interface Queue<E> extends Collection<E> {
// Adding an element returns true after adding successfully. If the queue is full, an exception will be thrown
boolean add(E e);
//If an element is added, it returns true if the addition is successful. If the queue is full, it returns false
boolean offer(E e);
// Delete and return the first element of the queue. If the queue is empty, an exception will be thrown
E remove();
// Remove and return the queue head element. If the queue is empty, null is returned
E poll();
// Returns the first element of the queue, but does not remove it. If the queue is empty, an exception is thrown
E element();
// Returns the first element of the queue, but does not remove it. If the queue is empty, null is returned
E peek();
}
The above list is only the general methods of ordinary queues. The blocking Queue BlockingQueue in Java inherits the Queue interface, adds two abstract methods with blocking function, and provides two overloaded methods that can be blocked, offer() and poll:
As can be seen from the definition of blocking method below, InterruptedException exception will be thrown for any method that will be blocked
public interface BlockingQueue<E> extends Queue<E> {
// Add elements. When the queue is full, the insertion thread will be blocked until the queue is full
void put(E e) throws InterruptedException;
// Remove and return elements. When the queue is empty, the thread getting elements will be blocked until the queue is not empty
E take() throws InterruptedException;
// You can specify the timeout for threads to be blocked when adding elements
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
// You can specify the timeout for the thread to be blocked when getting the element
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
}
The common methods of BlockingQueue are summarized as follows:
| method | Throw exception | Returns a specific value | block | Specify blocking time |
|---|---|---|---|---|
| Join the team | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| Out of the team | remove() | poll() | take() | poll(time,unit) |
| Get team leader element | element() | peek() | I won't support it | I won't support it |
In addition to the characteristics of blocking, blocking queue has another important characteristic: capacity, which is divided into bounded and unbounded. There is no absolute sense of boundlessness, but this boundary is very large and can put many elements. Take LinkedBlockingQueue as an example. Its capacity is integer MAX_ Value, which is a very large number. We usually think it is unbounded. There are also some blocking queues that are bounded, such as ArrayBlockingQueue. If the maximum capacity is reached, it will not be expanded. So once it's full, you can't put any more data in it.
BlockingQueue is also thread safe. It can ensure the thread safety of producers and consumers in the case of multithreading. CAS and ReentrantLock are mostly used to ensure thread safety. Business code does not need to pay attention to the problem of multithreading safety, but can directly put or take it into the queue, as shown in the figure:
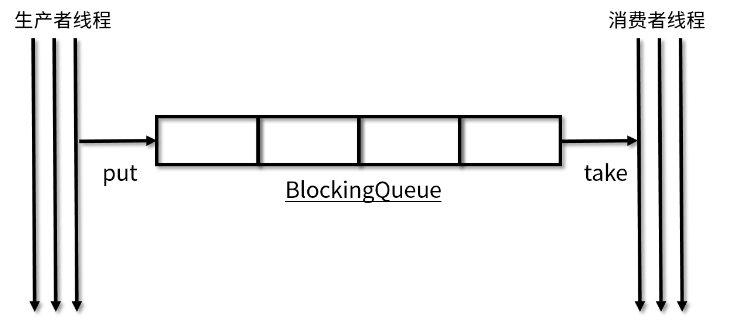
At the same time, the blocking queue also starts the function of resource isolation. In complex services, after the completion of service A, you only need to throw the results into the queue. You don't need to care about the next steps. Service B will obtain tasks from the queue to execute the corresponding services, which realizes the decoupling between services and improves security.
Here are some common blocking queues and some core source codes
2, Analysis of common blocking queues and core source code
2.1 ArrayBlockingQueue
ArrayBlockingQueue is a typical bounded thread safe blocking queue. Its capacity needs to be specified during initialization. Its internal elements are stored in an array. Take put() method as an example, ReentrantLock is used to ensure thread safety, and blocking and wake-up are carried out through the two conditions notEmpty and notFull of the condition queue
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
final Object[] items;
int takeIndex;
int putIndex;
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
// Lock to ensure thread safety
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// Use while instead of if to prevent false wakeups
while (count == items.length)
// The queue is full and the producer is blocked
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
// If you add an element, after the queue is full, it will be set to 0 by putIndex, which is the implementation of a typical ring array
if (++putIndex == items.length)
putIndex = 0;
count++;
// Condition queue to synchronize queue and wake up thread
notEmpty.signal();
}
}
Because the put() and take() methods of ArrayBlockingQueue use ReentrantLock for synchronization, and only one method can be executed, the performance will be poor in the case of high concurrency.
Thinking: why does ArrayBlockingQueue adopt the method of double pointer ring array?
For an ordinary array, a shift operation is required when deleting array elements, resulting in its time complexity of O(n). However, for a double pointer ring array, there is no need to shift, and only two pointers need to be moved respectively.
2.2 LinkedBlockingQueue
LinkedBlockingQueue is a blocking queue based on linked list. By default, the size of the blocking queue is integer MAX_ Value. Because this value is very large, LinkedBlockingQueue is also called unbounded queue, which means that it has almost no boundaries. The queue can grow dynamically with the addition of elements, but if there is no remaining memory, the queue will throw an OOM error. Therefore, in order to avoid the machine load or full memory caused by too large queue, we suggest to manually transfer the size of a queue when using it.
LinkedBlockingQueue is internally implemented by a single linked list. You can only get elements from the head and add elements from the tail. LinkedBlockingQueue adopts the lock separation technology of two locks to realize that entering and leaving the queue do not block each other. Both adding elements and obtaining elements have independent locks, that is, LinkedBlockingQueue is read-write separated, and read-write operations can be executed in parallel.
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
static class Node<E> {
E item; // Element content
Node<E> next; // Next element node single linked list structure
Node(E x) { item = x; }
}
// Initialization capacity, default integer MAX_ VALUE
private final int capacity;
// The number of elements. Because of the lock separation of read and write operations, thread safe count variables are used here
private final AtomicInteger count = new AtomicInteger();
// The chain header itself does not store element information, and its item is null
transient Node<E> head;
// End of list element
private transient Node<E> last;
// Obtain the lock of the element and separate the lock to improve the efficiency
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();
// Add lock for element
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFull = putLock.newCondition();
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// Using the put lock, it can be interrupted
putLock.lockInterruptibly();
try {
// The queue is full, blocking the producer thread
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);
// Return old value
c = count.getAndIncrement();
// There may be many threads blocking on the condition of notFull, and notFull will wake up when the element is fetched. Here, you don't have to wait until the element is fetched
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// The queue was empty before. Now, after adding an element, you can directly wake up the thread that gets the element
if (c == 0)
signalNotEmpty();
}
}
Comparison between LinkedBlockingQueue and ArrayBlockingQueue
- ArrayBlockingQueue uses one exclusive lock, and reads and writes are not separated, while linkedblockingqueue uses two exclusive locks. Read and write operations are separated, and the performance is better
- The queue size is different. ArrayBlockingQueue is bounded. The initialization must specify the size, while LinkedBlockingQueue can be bounded or unbounded (Integer.MAX_VALUE). For the latter, when the addition speed is faster than the removal speed, problems such as memory overflow may occur in the case of unbounded.
- Different from data storage containers, ArrayBlockingQueue uses arrays as data storage containers, while LinkedBlockingQueue uses linked lists with Node nodes as connection objects.
- Because ArrayBlockingQueue adopts the storage container of array, no additional object instance will be generated or destroyed when inserting or deleting elements, while LinkedBlockingQueue will generate an additional Node object. This may have a great impact on GC when it is necessary to process large quantities of data efficiently and concurrently for a long time.
2.3 LinkedBlockingDeque
LinkedBlockingDeque is an enhancement to LinkedBlockingQueue. Its top-level interface is Deque, which defines richer methods to operate the queue. It can be seen from the method name. These methods break the inherent rules of queue first in first out and provide API s that can operate from the beginning or the end
public interface Deque<E> extends Queue<E> {
void addFirst(E e);
void addLast(E e);
boolean offerFirst(E e);
boolean offerLast(E e);
E removeFirst();
E removeLast();
E pollFirst();
E pollLast();
E getFirst();
E getLast();
E peekFirst();
E peekLast();
}
The BlockingDeque interface inherits Deque and provides several blocking methods
public interface BlockingDeque<E> extends BlockingQueue<E>, Deque<E> {
void putFirst(E e) throws InterruptedException;
void putLast(E e) throws InterruptedException;
E takeFirst() throws InterruptedException;
E takeLast() throws InterruptedException;
}
LinkedBlockingDeque implements the BlockingDeque interface, which records elements through a two-way linked list and ensures thread safety through a ReentrantLock. This class can be regarded as the combination and enhancement of ArrayBlockingQueue and LinkedBlockingQueue
public class LinkedBlockingDeque<E>
extends AbstractQueue<E>
implements BlockingDeque<E>, java.io.Serializable {
static final class Node<E> {
E item;
Node<E> prev;
Node<E> next;
Node(E x) {
item = x;
}
}
transient Node<E> first;
transient Node<E> last;
private transient int count;
private final int capacity;
final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
private final Condition notFull = lock.newCondition();
public LinkedBlockingDeque() {
this(Integer.MAX_VALUE);
}
public void putFirst(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
while (!linkFirst(node))
notFull.await();
} finally {
lock.unlock();
}
}
private boolean linkFirst(Node<E> node) {
// Over capacity, return directly
if (count >= capacity)
return false;
Node<E> f = first;
node.next = f;
first = node;
if (last == null)
last = node;
else
f.prev = node;
++count;
// Wake up the blocked thread to get the element
notEmpty.signal();
return true;
}
}
2.4 SynchronousQueue
SynchronousQueue is a BlockingQueue without buffer. The insertion operation put() of the producer thread into the element must wait for the removal operation take() of the consumer. Its model is as follows:
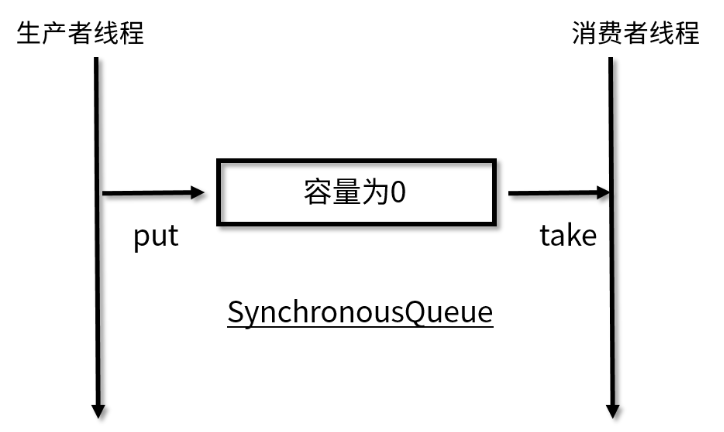
As shown in the above figure, the biggest difference of SynchronousQueue is that its capacity is 0, and there is no place to cache elements, which leads to blocking every time an element is added until a thread comes to get the element; Similarly, the same is true for fetching elements. The thread fetching elements will also be blocked until a thread adds elements.
Because SynchronousQueue does not need to hold elements and its function is to pass directly, it is very suitable for exchange in transitive scenarios. Producer threads and consumer threads synchronously transfer some information, transactions or tasks
A common scenario of synchronous queue is in executors In newcachedthreadpool(), because the number of producer requests (creating tasks) is uncertain, and these requests need to be processed in time, using SynchronousQueue to allocate a consumer thread to each producer thread is the most efficient way. The thread pool will create new threads as needed (new tasks arrive). If there are idle threads, they will be reused. After the threads are idle for 60s, they will be recycled.
The following analyzes its implementation principle in combination with the source code:
The SynchronousQueue internal abstract class transferer provides the method transfer() for task transfer, which contains the logic of thread blocking and wake-up. Transferer has two implementation classes TransferQueue and TransferStack, which can be understood as two ways to store blocked threads: queue and stack. According to the characteristics of the two, they can be divided into fair and unfair implementations. Queue meets the characteristics of FIFO (first in, first out), so it is a fair implementation; The stack meets the characteristics of LIFO (last in first out), so it is an unfair implementation.
The following construction method of SynchronousQueue provides fair and unfair options. The default is non fair implementation
public SynchronousQueue() {
this(false);
}
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
Next, take TransferQueue as an example to briefly analyze the operations of elements entering and leaving the queue. put() and take() of SynchronousQueue will call the transfer() method to add or obtain elements
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
Let's analyze the transfer() method of TransferQueue. Before analyzing this method, take a look at its internal class QNode. QNode is used in TransferQueue to record elements and blocked threads. UNSAFE is also used to obtain the offset between elements and the next node, and modify the corresponding value directly through CAS. There are many CAS methods in QNode, which are not listed here.
static final class TransferQueue<E> extends Transferer<E> {
static final class QNode {
// Pointer to the next node
volatile QNode next; // next node in queue
// Element content
volatile Object item; // CAS'ed to or from null
// Blocked thread
volatile Thread waiter; // to control park/unpark
// It is used to add elements, and it is used to distinguish the element type. It is false
final boolean isData;
// Modify the next node through CAS (multi thread safety)
boolean casNext(QNode cmp, QNode val) {
return next == cmp &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Offset of QNode property
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
// Calculate the offset of the attribute in the QNode class according to the Unsafe class
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = QNode.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
// Head node
transient volatile QNode head;
// Tail node
transient volatile QNode tail;
// During initialization, a node with null element and false data type is created, and the head and tail nodes point to this node
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}
// Calculate the offset of the head and tail nodes and modify it directly through CAS (ensure thread safety)
private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
private static final long tailOffset;
private static final long cleanMeOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = TransferQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
cleanMeOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("cleanMe"));
} catch (Exception e) {
throw new Error(e);
}
}
}
The general internal structure of TransferQueue has been introduced above. Next, we will focus on the implementation of the transfer() method,
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
// Wait for initialization to complete
if (t == null || h == null) // saw uninitialized value
continue; // spin
// Null or current node
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
// To prevent other threads from modifying, judge again here
if (t != tail) // inconsistent read
continue;
// If there are nodes behind the current tail node, the latter nodes will be modified to tail nodes through CAS
if (tn != null) { // lagging tail
advanceTail(t, tn);
continue;
}
// If timeout blocking is required, but the timeout time is less than 0 (blocking is not allowed), null is returned directly
// Interrupt the thread in the put or take method and throw an interrupt exception
if (timed && nanos <= 0) // can't wait
return null;
// Create a node and add it to the tail node through CAS. This node can be the node that takes the element or the node that adds the element
if (s == null)
s = new QNode(e, isData);
if (!t.casNext(null, s)) // failed to link in
continue;
// After the new node is added, it is modified as the tail node through CAS
advanceTail(t, s); // swing tail and wait
// Spin blocking threads are highlighted below
Object x = awaitFulfill(s, e, timed, nanos);
// If the returned node is the current node, it means that the node has been cancelled and cleared directly
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
if (!s.isOffList()) { // not already unlinked
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { // complementary-mode
// The queue is not empty, and the new node type is inconsistent with the node type in the queue (indicating that the thread can be awakened)
QNode m = h.next; // node to fulfill
// In order to ensure thread safety, judge the spin again
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
// If the m node has been processed by another thread, the spin of the head node is modified here
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
}
// The current thread modifies the header node and blocks the thread node from leaving the queue
advanceHead(h, m); // successfully fulfilled
// Wake up the blocked thread of m node
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
There is an important method awaitFulfill in transfer(), which will do spin blocking
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// The number of spins is calculated according to the number of cores of the processor
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// If the current thread is interrupted, modify the item attribute of the S node to the current node
//Then, when judging whether the node is cancelled, you can directly judge whether its item value is the current node
if (w.isInterrupted())
s.tryCancel(e);
// Returns when the node is cancelled
Object x = s.item;
if (x != e)
return x;
// Cancel after timeout
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
// Spin. After a certain number of times, fill the waiter attribute of the S node as the current thread, and then block it
// At this point, the content of a node is complete
if (spins > 0)
--spins;
else if (s.waiter == null)
s.waiter = w;
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
2.5 PriorityBlockingQueue
PriorityBlockingQueue is an unbounded array based priority blocking queue. Although it is unbounded, it can specify the initialization capacity of the array during initialization. Its unbounded is based on its dynamic capacity expansion.
If the initialization capacity is not specified, its default capacity is 11 and the maximum capacity is integer MAX_ VALUE - 8
private static final int DEFAULT_INITIAL_CAPACITY = 11;
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
public PriorityBlockingQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityBlockingQueue(int initialCapacity) {
this(initialCapacity, null);
}
At the same time, PriorityBlockingQueue is a priority queue. Every time it goes out of the queue, it will return the elements with the highest or lowest priority. Its construction method provides a custom Comparator comparator. By default, it uses natural ascending order.
It can also be seen from the following construction method that the thread safety of the queue is guaranteed by ReentrantLock. At the same time, it should be noted that PriorityBlockingQueue cannot guarantee the order of elements with the same priority
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
this.comparator = comparator;
this.queue = new Object[initialCapacity];
}
If PriorityBlockingQueue simply uses array operation to sort the removal of inserted elements, its performance will be very low, and it uses the maximum and minimum heap to insert or remove data. The size heap is only a logical operation mode, and its storage structure is still array
Complete binary tree: a binary tree in which all rows are full except the last row, and all leaf nodes in the last row are sorted from left to right
Binary heap: a special binary tree with certain constraints on the basis of complete binary tree. According to different constraints, binary reactor can be divided into two types: large top reactor and small top reactor.
The maximum and minimum heap meet the following characteristics:
- Maximum heap: the key value of the root node is the largest of all heap nodes
- Minimum heap: the key value of the root node is the smallest of all heap nodes
The following figure shows the minimum binary stack:
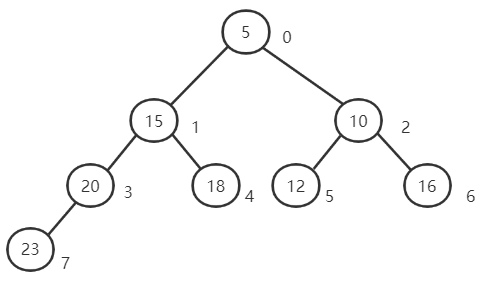
The maximum and minimum heap indicates the index position from top to bottom and from left to right. The number in the lower right corner of the figure above indicates the index subscript of the element in the array
In the maximum and minimum binary heap, element position adjustment may be involved when inserting or removing elements. In the binary heap, the subscripts of its parent node and left and right nodes can be easily calculated by using the subscript index of the element (take the element with index subscript t as an example):
Parent node: P (T) = (t-1) > > > 1 < = > (t-1) / 2
Left node: l (T) = T < < 1 + 1 < = > t * 2 + 1
Right node: R (T) = T < < 1 + 2 < = > t * 2 + 2
Here's how to add and remove elements in combination with the source code
Because the PriorityBlockingQueue is an unbounded queue, the thread does not need to be blocked when adding elements. If the capacity is not enough, it can be expanded
public void put(E e) {
offer(e); // never need to block
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
// Lock to ensure thread safety
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
// If the current capacity has been reached, expand the capacity
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null)
// Note that if the comparator is not executed, the element class must implement the Comparable interface
siftUpComparable(n, e, array);
else
// When a comparator is specified, it is used for comparison
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
// After adding an element, wake up the blocked thread to get the element directly
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
The code for capacity expansion is as follows. tryGrow() method implements CAS + spin to realize thread safe capacity expansion in the while loop body of offer() method
private void tryGrow(Object[] array, int oldCap) {
// Release the lock and expand the capacity through CAS
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
// If the original capacity is less than 64, the capacity will be doubled and then + 2. Otherwise, the capacity will be directly tripled
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
// The capacity cannot exceed the maximum
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
// When other threads are expanding, the current thread will give up the CPU
if (newArray == null) // back off if another thread is allocating
Thread.yield();
lock.lock();
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
The core methods are the two methods of siftUpComparable() and siftUpUsingComparator(). These two methods are the core methods of binary stacking. Take siftUpUsingComparator() as an example
This is a while loop, which performs the floating operation of elements. Each time, it obtains the parent node of the current node and compares it with the inserted element. If the comparison result meets the structure of the maximum and minimum heap, it will exit the loop directly. Otherwise, it will be transposed and continue to compare until the conditions are met
private static <T> void siftUpUsingComparator(int k, T x, Object[] array,
Comparator<? super T> cmp) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (cmp.compare(x, (T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = x;
}
The code to get the element is as follows. Because the thread to get the element will be blocked, this method will throw an interrupt exception
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null)
// Block if there are no elements
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}
private E dequeue() {
// Index subscript of the last element
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
E result = (E) array[0];
// Take out the last element
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
private static <T> void siftDownUsingComparator(int k, T x, Object[] array,
int n,
Comparator<? super T> cmp) {
if (n > 0) {
int half = n >>> 1;
while (k < half) {
// The first time you come in, you get two nodes in the second layer for comparison
int child = (k << 1) + 1;
Object c = array[child];
int right = child + 1;
// If the left node is compared with the right node and meets the comparison conditions, the value of the right node is taken as the value compared with the last node
if (right < n && cmp.compare((T) c, (T) array[right]) > 0)
c = array[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = x;
}
}
2.6 DelayQueue
DelayQueue is a blocking queue that supports delay acquisition elements. PriorityQueue is used internally to store elements. At the same time, the elements must implement the Delayed interface. The getDelay() method of the interface can return the delay time. The method parameter is the time tool class TimeUnit
When getting elements, the elements can be extracted from the queue only when the delay time is up.
Characteristics of delay queue: it is not first in first out, but sorted according to the length of delay time. The next task to be executed is at the top of the queue.
Since the queue element must implement the Delayed interface, which inherits from the Comparable interface, the element class also needs to implement the compareTo() method, so there is no need to create an additional Comparator object when creating the queue, and the element itself has the ability of sorting.
An element class is defined below
class DelayObject implements Delayed {
private String name;
private long time; //Delay Time
public DelayObject(String name, long delayTime) {
this.name = name;
this.time = System.currentTimeMillis() + delayTime;
}
@Override
public long getDelay(TimeUnit unit) {
long diff = time - System.currentTimeMillis();
return unit.convert(diff, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed obj) {
if (this.time < ((DelayObject) obj).time) {
return -1;
}
if (this.time > ((DelayObject) obj).time) {
return 1;
}
return 0;
}
}
Using Demo:
//Instantiate a DelayQueue
BlockingQueue<DelayObject> blockingQueue = new DelayQueue<>();
//Add two element objects to the DelayQueue. Note that the delay time is different
blockingQueue.put(new DelayObject("lizhi", 1000 * 10)); //Delay 10 seconds
blockingQueue.put(new DelayObject("linan", 1000 * 30)); //Delay 30 seconds
// Take out lizhi
DelayObject lizhi = blockingQueue.take();
// Take out linan
DelayObject linan = blockingQueue.take();
Let's take a look at the structure of DelayQueue. ReentrantLock is used to ensure thread safety. Elements need to be blocked. PriorityQeue is used for storage at the bottom. This is a priority queue. It is the same as PriorityBlockingQueue above, but it has no blocking function
private final transient ReentrantLock lock = new ReentrantLock(); private final PriorityQueue<E> q = new PriorityQueue<E>(); private final Condition available = lock.newCondition();
Let's take a look at the specific put() and take()
public void put(E e) {
offer(e);
}
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
// Lock to ensure thread safety
lock.lock();
try {
// Call PriorityQueue to add elements
// It is basically consistent with the logic of PriorityBlockingQueue
q.offer(e);
// If there is only one element in the current queue, wake up the blocked thread
if (q.peek() == e) {
leader = null;
available.signal();
}
return true;
} finally {
lock.unlock();
}
}
The following is the take() method, which is more complex than the put() method
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// Locking ensures thread safety. Since the thread may be blocked, it can be interrupted here
lock.lockInterruptibly();
try {
for (;;) {
// Take out the first element of the queue. If not, directly block the current thread
E first = q.peek();
if (first == null)
available.await();
else {
// If the delay time has expired, take out the element directly
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return q.poll();
first = null; // don't retain ref while waiting
// If a thread is already blocking, let the current thread block directly
if (leader != null)
available.await();
else {
// If there is no thread blocking, record the current thread, and then let the current thread block. The blocking time is equal to the delay time of the nearest element
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
// After the current thread is awakened, reset the leader and then spin
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
// If the leader is empty and there are still elements in the queue, wake up the next blocked thread
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
Application scenario of delay queue * *:**
- Order timeout closing: cancel the order if there is no payment within the specified time after placing the order
- Asynchronous SMS notification: send SMS to the user after 60S after the takeout order is successfully placed
- Close idle connections: in the connection pool, some non core connections are closed after being idle for a period of time
3, Select the appropriate blocking queue
We are more exposed to the use of blocking queues in threads. There are many kinds of thread pools. Different kinds of thread pools will choose their own blocking queues according to their own characteristics.
- FixedThreadPool (the same is true for SingleThreadExecutor) selects LinkedBlockingQueue
- CachedThreadPool selects SynchronousQueue
- ScheduledThreadPool (the same is true for SingleThreadScheduledExecutor) selects the delay queue
Note: the blocking queue used in the ScheduledThreadPool is not a DelayQueue, but a user-defined DelayedWorkQueue
Generally, the appropriate blocking queue is selected from the following dimensions
-
function
For example, whether the blocking queue is needed to help us sort, such as prioritization, delayed execution, etc. If this is necessary, you must select a blocking queue with sorting ability, such as priority blocking queue.
-
capacity
Whether there are storage requirements or just "direct delivery". When considering this point, we know that some of the blocking queues described above have fixed capacity, such as ArrayBlockingQueue; Some default to unlimited capacity, such as LinkedBlockingQueue; Some do not have any capacity, such as synchronous queue; For DelayQueue, its fixed capacity is integer MAX_ VALUE. Therefore, the capacity of different blocking queues varies greatly. We need to calculate the appropriate capacity according to the number of tasks, so as to select the appropriate blocking queue.
-
Capacity expansion
Because sometimes we can't accurately estimate the size of the queue at the beginning, because the business may have peak and trough periods. If one capacity is fixed at the beginning, it may not be able to cope with all situations, and it is also inappropriate. Dynamic capacity expansion may be required. If we need dynamic capacity expansion, we cannot select ArrayBlockingQueue because its capacity is determined when it is created and cannot be expanded. On the contrary, even after the initial capacity is specified, the PriorityBlockingQueue can be automatically expanded if necessary. Therefore, we can select the appropriate queue according to whether we need to expand the capacity.
-
Memory structure
We have analyzed the source code of ArrayBlockingQueue and found that its internal structure is in the form of "array". Unlike it, the LinkedBlockingQueue is internally implemented with a linked list, so we need to consider that ArrayBlockingQueue has no "nodes" required by the linked list and has higher space utilization. So if we have performance requirements, we can consider this problem from the perspective of memory structure.
-
performance
From the perspective of performance. For example, because LinkedBlockingQueue has two locks, its operation granularity is finer. When the degree of concurrency is high, its performance will be better than that of ArrayBlockingQueue with only one lock. In addition, the performance of synchronous queue is often better than other implementations because it only needs "direct delivery" and does not need stored procedures. If our scenario needs to be delivered directly, we can give priority to synchronous queue.