1, Three ways of weight removal
-
1.HashSet
Use the features of HashSet in java that cannot be repeated to remove duplicates. The advantage is easy to understand. Easy to use.
Disadvantages: large memory consumption and low performance. -
2.Redis de duplication
Use Redis's set for de duplication. The advantage is that it is fast (Redis itself is fast), and the de duplication will not occupy the resources of the crawler server, and can handle data crawling with a larger amount of data.
Disadvantages: Redis server needs to be prepared, which increases the cost of development and use. -
3. Bloom filter
Weight removal can also be achieved using Bloom filters. The advantage is that the memory occupied is much smaller than using HashSet, and it is also suitable for de duplication of a large amount of data.
Disadvantages: there is the possibility of misjudgment. If there is no duplication, duplication may be determined, but duplicate data must be determined.
2, Introduction to bloom filter
Bloom filter was proposed by Burton Howard Bloom in 1970. It is a probabilistic data structure of space effective, which is used to judge whether an element is in the set. It is often used in the black-and-white list method of spam filtering and the URL duplication module of crawler.
The hash table can also be used to determine whether elements are in the set, but the bloom filter only needs 1 / 8 or 1 / 4 of the spatial complexity of the hash table to complete the same problem. The bloom filter can insert elements, but cannot delete existing elements. The more elements, the greater the false positive rate, but it is impossible to miss the false positive.
Principle:
The bloom filter requires a bit group (similar to bitmap) and K mapping functions (similar to Hash table). In the initial state, all bits of the bit group array with length m are set to 0.
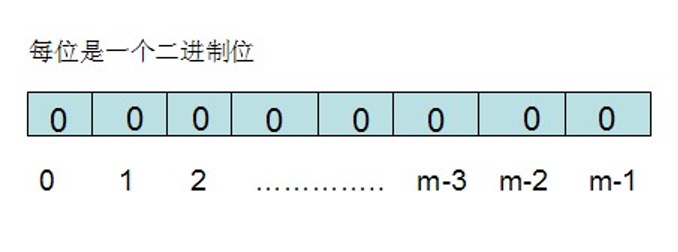
For the set S={S1,S2... Sn} with n elements, map each element Sj (1 < = J < = n) in the set s to k values {g1,g2... gk} through K mapping functions {f1,f2,... fk}, and then set the corresponding array[g1],array[g2]... array[gk] in the bit group array to 1:
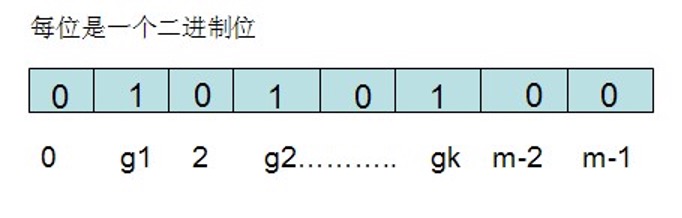
If you want to find out whether an element item is in s, you can get k values {g1,g2... gk} through the mapping function {f1,f2,... fk}, and then judge whether array[g1],array[g2]... array[gk] are all 1. If all are 1, the item is in s, otherwise the item is not in S.
Bloom filter will cause some misjudgment, because the values obtained by mapping several elements in the set happen to include g1,g2,... gk. In this case, misjudgment may be caused, but the probability is very small.
3, Implementation of Bloom filter
//Bloom filter
public class BloomFilter {
/* BitSet Initial allocation of 2 ^ 24 bit s */
private static final int DEFAULT_SIZE = 1 << 24;
/* The seeds of different hash functions should generally take prime numbers */
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37 };
private BitSet bits = new BitSet(DEFAULT_SIZE);
/* Hash function object */
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// Mark the url into bits
public void add(String str) {
for (SimpleHash f : func) {
bits.set(f.hash(str), true);
}
}
// Judge whether it has been marked by bits
public boolean contains(String str) {
if (StringUtils.isBlank(str)) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(str));
}
return ret;
}
/* Hash function class */
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
// Hash function, using a simple weighted sum hash
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}