preface
- 🏀 Hello, I'm BXuan, a sophomore of software engineering who loves programming and basketball
- 📚 Recently, we are preparing for the blue bridge provincial competition in April. This chapter will talk with you about the hash table! If the text is wrong, please point out and forgive me.
- 🏃 It's not hard to give up, but it must be cool to insist.
📗 Knowledge points
- The concept of Hash
- Construction method
- Conflict handling
📗 concept
Hash technology is used to store records in a continuous storage space, which is called hash table. Understood by mathematical relationship, it is the mapping relationship between X and Y, that is, Y=F(X).
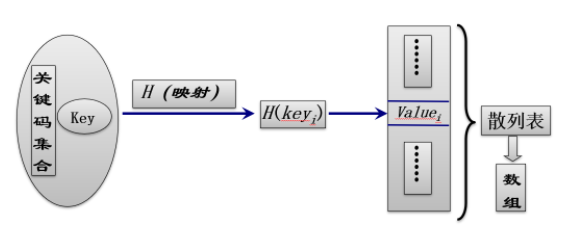
📗 reflection
-
Is hashing just a search technique?
It is both a storage technology and a hash technology.
-
Is hashing a complete storage structure?
Hash only locates the record through the Key of the record, and does not fully express the logical relationship between records, that is, the Key value can be deduced through the Key, but the Key can not be deduced through the corresponding value of the Key (i.e. the value at the position). Therefore, the Key and value stored in hash are not asymmetric. Therefore, hash is mainly a search oriented storage structure.
📗 Hash table
I Defects of hash table
Hash tables are not suitable for all demand scenarios, so what are the situations where they are not suitable?
-
Hash technology is generally not suitable for use when multiple records are allowed to have the same key.
Because in this case, there are usually conflicts, which will reduce the search efficiency and do not reflect the advantages of high hash table search efficiency.
And if it must be used in this case, we also need to find ways to eliminate conflicts, which will take a lot of time, so we will lose the advantage of O(1) time complexity. Therefore, in the case of a large number of conflicts, we will abandon the hash table. -
The hash method is also not suitable for range lookup, such as the following two cases.
-
Find the maximum or minimum value
Because the value of hash table is similar to that of function, a variable of mapping function can only correspond to one value. It does not know other values, nor can it find the maximum and minimum values. RMQ (interval maximum value problem) can be solved by ST algorithm, tree array and line segment tree.
-
It is also impossible to find records within a certain range
For example, it is impossible to find the number of numbers less than N. The reason is that a variable of the mapping function can only correspond to one value and does not know other values.
II Key problems of hash technology
When using hash table, we have two key technical problems to solve:
- How to design a simple, uniform and high storage utilization hash function?
- How to deal with conflicts and how to take appropriate methods to solve conflicts.
① How to design and implement hash function
When building hash functions, we need to adhere to two principles:
-
simple
- Hash function should not have a large amount of calculation, otherwise it will reduce the search efficiency.
-
Uniform:
- Function values should be evenly distributed in the address space as far as possible, so as to ensure the effective utilization of storage space and reduce conflicts.
🙇♂️ Implementation of hash function
1. Direct addressing method
Hash function is a linear function of Key mapping, such as:
H(key)=a∗key+b
eg:

If the set of keys is known and is [11,22,33,66,88,44,99]
H(key)=11∗key+0
Disadvantages:
- We see this set and think that they are multiples of 11 before we think of this Hash function. In normal use, we generally do not know the Key value set in advance, so we use it less.
Scope of application:
- Know the key in advance. The key set is small, continuous and not discrete.
2. Division and remainder method
You will find that there are many identical H(K), which is a conflict, because only one number can be placed in a position, and two values correspond to one position here, which is not allowed.
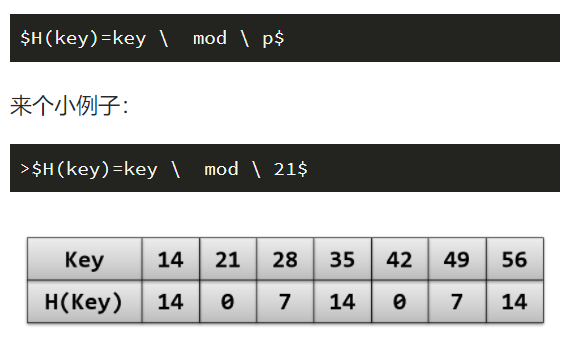
This method is the most commonly used method. The key of this method is how to select P to make the utilization rate higher and the conflict rate lower. Generally, we will select the maximum prime number closest to the table length and less than or equal to the table length.
Disadvantages:
- Improper selection of P will increase the conflict rate.
Scope of application:
- The division and remainder method is the simplest and most commonly used method to construct hash function, and does not require to know the distribution of key codes in advance.
3. Digital analysis
For example, I convert all my sets into hexadecimal numbers, and select several evenly distributed bits to form a hash address according to the distribution of key codes in each bit. Or use N-digit hexadecimal number to observe the digital distribution of each bit and select the hash address with uniform distribution.
eg:
First, consider one bit as the hash function, and it is found that there are many conflicts. When selecting two bits, the combination of hundred bits and ten bits is the most appropriate, evenly distributed and without conflict.
Of course, we are talking about a specific real column of this method. Since it is called digital analysis method, only different analysis of different data can write more suitable H(x).
4. Square middle method
5. Folding method
② Handling of conflicts
🙋♀️ Open Hashing
open hashing is also called zipper method, and separate chaining is called chain address method. In short, it means that once the hash address obtained from the key code conflicts, it will find the next empty hash address and store the record.
How to find the next empty hash address:
1. Linear detection method
When a conflict occurs, the empty hash address is searched successively from the next position of the conflict position.
For the key value key, let H(key)=d and the length of the closed hash table is m, then in case of conflict, the formula for finding the next hash address is:
Hi=(H(key)+di) MOD m(di=1,2,...,m−1)
Accumulation phenomenon:
In the process of dealing with conflicts, non synonyms compete for the same hash address.
eg:
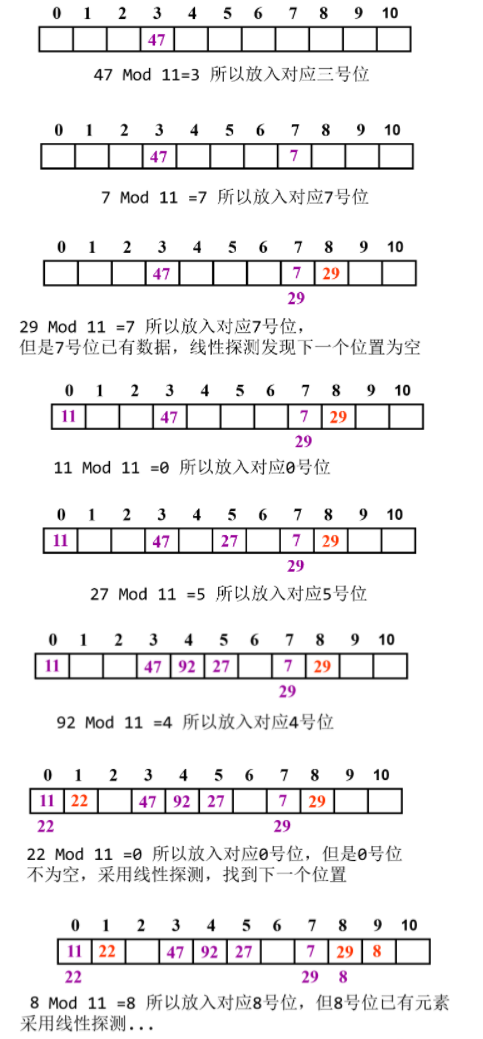
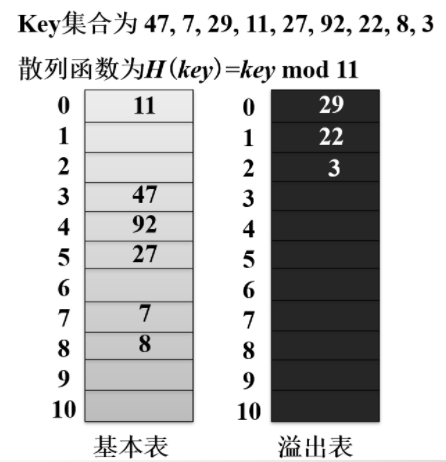
The Key set is 47, 7, 29, 11, 27, 92, 22, 8, 3.
The P value is 11, Hash mapping is carried out, and the linear detection method is used to deal with the conflict.
2. Secondary detection method
That is, when a conflict occurs, the formula for finding the next hash address is:
Hi=(H(key)+di)
Where (di = 1, - 1, 2, - 2,..., q, - q and q ≤ m/2)
3. Random detection method
In case of conflict, the displacement of the next hash address is a random sequence, that is, the formula for finding the next hash address is:
Hi=(H(key)+round)
Where round is a random number
4. Re hash method
Note: the hash table obtained by using the open addressing method to deal with conflicts is called a closed hash table.
🙋♂️ Closed Hashing
closed hashing is also known as open addressing method. Open addressing method covers the following two implementation methods;
1. Zipper method (chain address method)
All records with the same hash address, i.e. items with the same Key value, are dropped into a linked list, and the storage position of the head pointer of each linked list is the position corresponding to the Key value.
eg:
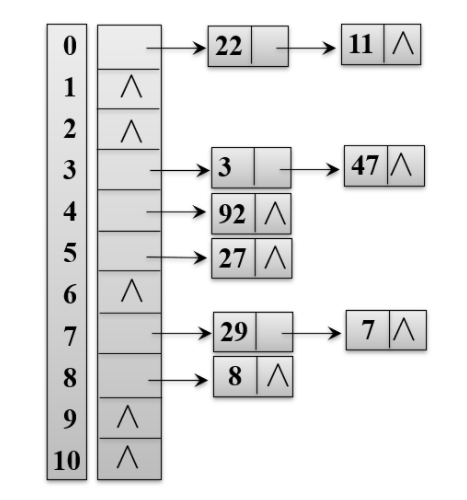
2. Establish public spillover areas
The hash table contains two parts: the basic table and the overflow table (usually the overflow table and the basic table are the same size), and the conflicting records are stored in the overflow table.
When searching, if it is found in the basic table, it will return success. If it is not found, it will be searched in the overflow area in order. Note that this is no longer a mapping, but a sequential search. It is also placed in order.
🚀 Real problem consolidation
1, Frey's language
Problem description
Fri, the little inventor, wants to create a new language. As we all know, it is very difficult to invent a language. First of all, you have to overcome a difficulty, that is, there are a large number of words to deal with. Now fri asks you to help him write a program to judge whether there are two repeated words.
Enter description
On the first line, enter N to represent the total number of words created.
From line 2 to line N+1, enter N words.
1 < = n < = 10 ^ 4, ensure that the total input amount of string does not exceed 10 ^ 6.
Output description
Output only one line. If there is a duplicate word, it will output the duplicate word. If there is NO duplicate word, it will output NO. multiple duplicate words will output the first one.
Operational limits
- Maximum running time: 1s
- Maximum running memory: 512M
Input / output example
Example 1
Input: 6 1fagas dsafa32j lkiuopybncv hfgdjytr cncxfg sdhrest Output: NO
Example 2
Input: 5 sdfggfds fgsdhsdf dsfhsdhr sdfhdfh sdfggfds Output: sdfggfds
Code example 1:
The following code is the answer given by the system, but it cannot pass normally on the blue bridge built-in system (possibly due to the system). There is no problem with the logical structure!
package E_lanqiao;
import java.util.Scanner;
// 1: No package required
// 2: Class name must be Main and cannot be modified
/**\
*
*@Description
*@author BXuan Email:ybxuan2002@163.com
*@version
*@date 2022 March 5, 2014 2:26:36 PM
*
*/
public class Main {
// 1. You need to create a hash table and a public overflow area first
static final int h = 12582917;
static String[] Value = new String[h];
static String[] upValue = new String[h];
static int upValueCount = 0;
// 2. Define Hash list function
private static int Hx(String s) {
int n = s.length();
int sum1=0;
for (int i = 0; i < n; i++){
sum1 = sum1 * 131%h + (s.charAt(i)-'a'+1)%h;
}
return (sum1+h)%h;
}
// 3. Define query function
private static boolean isAt(String s) {
int n = Hx(s);
if(Value[n] == null) {
return false;
}else if(Value[n].equals(s)) {
return true;
}else {
for(int i = 0;i < upValueCount;i++) {
if(upValue[n].equals(s)) {
return true;
}
return false;
}
}
return false;
}
// 4. Define insert query hash function
private static boolean in(String s) {
// Enter the Hx function to query the position where the string should be inserted
int n=Hx(s);
if(Value[n]==null) {
Value[n]=s;
return true;
}
else if(Value[n].equals(s)) return false;
else {
for(int i=0;i<upValueCount;i++)
if(upValue[n].equals(s)) return false;
upValue[upValueCount++]=s;
return true;
}
}
// 5. Main function
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
//Enter your code here
int N = scan.nextInt();
boolean isRight = false;
String ans = "NO";
for(int i = 0;i < N;i++) {
String wordString = scan.next();
if(isRight) {
continue;
}
if(isAt(wordString)) {
isRight = true;
ans = wordString;
}else {
// Store string in hash table
in(wordString);
}
}
System.out.println(ans);
scan.close();
}
}
Code example 2:
The following code is implemented using java's built-in hash table class, which can run normally and pass.
package E_lanqiao;
import java.util.HashSet;
import java.util.Scanner;
// 1: No package required
// 2: Class name must be Main and cannot be modified
/**
*
*@Description
*@author BXuan Email:ybxuan2002@163.com
*@version
*@date 2022 March 5, 2013 3:26:02 PM
*
*/
public class Main {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
//Enter your code here
HashSet<String> hashSet = new HashSet<String>();
int N = scan.nextInt();
scan.nextLine();// Absorb line feed
int temp = N;
String ansString = "NO";
while(temp > 0) {
String string = scan.next();
if(!(hashSet.add(string))) {
ansString = string;
}
temp--;
}
if(hashSet.size() == N) {
System.out.println("NO");
}else {
System.out.println(ansString);
}
scan.close();
}
}
👏 Summary
There are many contents of hash table in this chapter, and its implementation method and processing method are also complex. It is necessary to clarify the logic and think slowly in order to master it best. Go, go, go!