Hello, ladies and gentlemen. Today I share another practical article with you. I hope you can like it.
Appetizer
Recently, I received a new demand to upload about 2G video files. I tried it with the OSS of the test environment. It takes more than ten minutes to upload. Considering the company's resources, I resolutely gave up the scheme.
When it comes to uploading large files, the first thing I think of is all kinds of online disks. Now everyone likes to upload their collected small movies to the online disk for storage. The network disk generally supports the functions of breakpoint continuous transmission and file second transmission, which reduces the restrictions of network fluctuation and network bandwidth on files, greatly improves the user experience and makes people love it.
Speaking of this, let's first understand these concepts:
- File segmentation: split large files into small files, upload / download small files, and finally assemble small files into large files;
- Breakpoint continuation: on the basis of file segmentation, each small file is uploaded / downloaded by a separate thread. In case of network failure, you can continue to upload / download the unfinished part from the part that has been uploaded / downloaded, instead of uploading / downloading from the beginning;
- File transfer in seconds: the file already exists in the resource server. When others upload, the URI of the file is directly returned.
RandomAccessFile
We usually use IO streams such as FileInputStream, FileOutputStream, FileReader and FileWriter to read files. Today, let's learn about RandomAccessFile.
It is an independent class that directly inherits Object. In the underlying implementation, it implements DataInput and DataOutput interfaces. This class supports random reading of files. Random access to files is similar to large byte arrays stored in the file system.
Its implementation is based on the file pointer (a cursor or an index pointing to an implicit array). The file pointer can be read through the getFilePointer method or set through the seek method.
When inputting, read bytes from the file pointer and make the file pointer exceed the read bytes. If you write an output operation that exceeds the current end of the implicit array, the array will be extended. There are four modes to choose from:
- r: Open the file in read-only mode. IOException will be thrown if write operation is performed;
- rw: open the file by reading and writing. If the file does not exist, try to create the file;
- rws: open the file by reading and writing, and each update of file content or metadata is required to be synchronously written to the underlying storage device;
- rwd: open the file by reading and writing, and each update of the file content is required to be synchronously written to the underlying storage device;
In rw mode, buffer is used by default. Only the cache is full or RandomAccessFile is used Close() writes to the file only when the stream is closed.
API
1. void seek(long pos): set the offset of the file pointer when reading or writing next time. In other words, specify the location of the file data to be read next time.
The offset can be set outside the end of the file. The file length can be changed by writing only after the offset is set beyond the end of the file;
2. native long getFilePointer(): returns the cursor position of the current file;
3. native long length(): returns the length of the current file;
4. Reading method
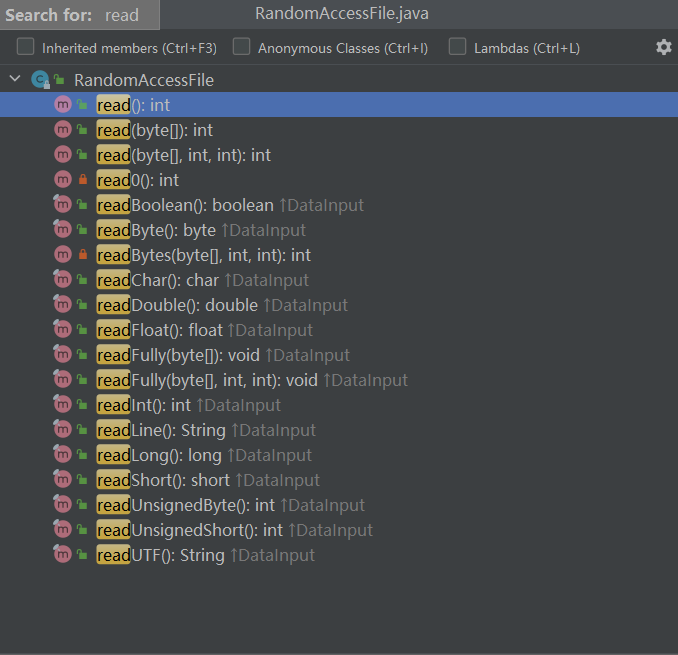
5. Writing method
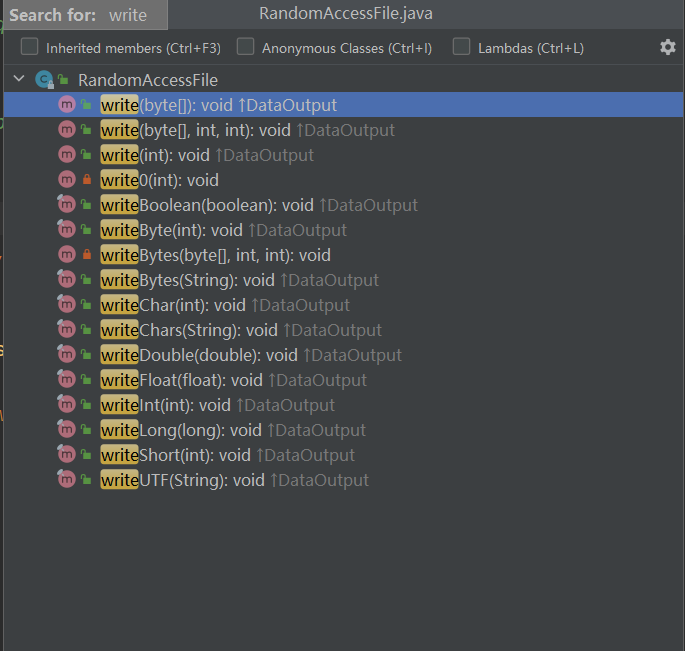
6. Readfull (byte [] b): this method is used to fill the buffer B with the contents of the text. If the buffer B cannot be filled, the process of reading the stream will be blocked. If it is found to be the end of the stream, an exception will be thrown;
7. FileChannel getChannel(): returns the unique FileChannel object associated with this file;
8. int skipBytes(int n): try to skip the input of N bytes and discard the skipped bytes;
Most functions of RandomAccessFile have been implemented by jdk1 The NIO memory mapping file of 4 is replaced, that is, the file is mapped to memory before operation, eliminating frequent disk io.
main course
Sum up experience and forge ahead: too many source codes were pasted in the previous practical articles, which affected the reading feelings of your little partners. After the boss's advice, some key codes will be displayed for your appreciation. The source code can be obtained in the background.
File blocking
File blocking needs to be processed at the front end, which can be processed by using powerful js library or ready-made components. You need to determine the size and number of blocks, and then specify an index value for each block.
In order to prevent the blocking of the uploaded file from being confused with other files, the md5 value of the file is used to distinguish. This value can also be used to verify whether the file exists on the server and the upload status of the file.
- If the file exists, directly return the file address;
- If the file does not exist but has upload status, that is, some blocks are uploaded successfully, the block index array that has not been uploaded is returned;
- If the file does not exist and the upload status is empty, all blocks need to be uploaded.
fileRederInstance.readAsBinaryString(file);
fileRederInstance.addEventListener("load", (e) => {
let fileBolb = e.target.result;
fileMD5 = md5(fileBolb);
const formData = new FormData();
formData.append("md5", fileMD5);
axios
.post(http + "/fileUpload/checkFileMd5", formData)
.then((res) => {
if (res.data.message == "file already exist") {
//The file already exists. Don't go back to the partition. Directly return the file address to the foreground page
success && success(res);
} else {
//There are two cases when the file does not exist. One is to return data: null, which means it has not been uploaded, and the other is data:[xx, xx] which pieces have not been uploaded
if (!res.data.data) {
//There are still a few films that have not been uploaded. Continue at breakpoint
chunkArr = res.data.data;
}
readChunkMD5();
}
})
.catch((e) => {});
});
Before calling the upload interface, the slice method is used to get the block of the corresponding position of the index in the file.
const getChunkInfo = (file, currentChunk, chunkSize) => {
//Get the file fragment under the corresponding subscript
let start = currentChunk * chunkSize;
let end = Math.min(file.size, start + chunkSize);
//Block files
let chunk = file.slice(start, end);
return { start, end, chunk };
};
After that, the upload interface is uploaded.
Breakpoint continuous transmission, file second transmission
The back-end is developed based on spring boot and uses redis to store the status and address of uploaded files.
If the file is completely uploaded, return to the file path; Partial upload returns the block array that has not been uploaded; If it has not been uploaded, a prompt message will be returned.
When uploading blocks, two files will be generated, one is the file body and the other is a temporary file. The temporary file can be regarded as an array file, and each block is allocated a byte with a value of 127.
Two values are used to verify the MD5 value:
- File upload status: if the file has been uploaded, it will not be empty. If the file has been uploaded completely, it will be true, and some uploads will return false;
- File upload address: if the file is completely uploaded, the file path is returned; Some uploads return to the temporary file path.
/**
* MD5 of verification file
**/
public Result checkFileMd5(String md5) throws IOException {
//File upload status: this value must exist as long as the file has been uploaded
Object processingObj = stringRedisTemplate.opsForHash().get(UploadConstants.FILE_UPLOAD_STATUS, md5);
if (processingObj == null) {
return Result.ok("The file has not been uploaded");
}
boolean processing = Boolean.parseBoolean(processingObj.toString());
//When the complete file upload is completed, it is the file path. If it is not completed, it returns the temporary file path (the temporary file is equivalent to an array, and each block is allocated a byte with a value of 127)
String value = stringRedisTemplate.opsForValue().get(UploadConstants.FILE_MD5_KEY + md5);
//Complete file upload is true, and incomplete file upload returns false
if (processing) {
return Result.ok(value,"file already exist");
} else {
File confFile = new File(value);
byte[] completeList = FileUtils.readFileToByteArray(confFile);
List<Integer> missChunkList = new LinkedList<>();
for (int i = 0; i < completeList.length; i++) {
if (completeList[i] != Byte.MAX_VALUE) {
//Fill in with blanks
missChunkList.add(i);
}
}
return Result.ok(missChunkList,"Part of the file was uploaded");
}
}
Speaking of this, you will certainly ask: when all the blocks of the file are uploaded, how can we get the complete file? Next, let's talk about block merging.
Block upload and file consolidation
As mentioned above, we use the md5 value of the file to maintain the relationship between blocks and files. Therefore, we will merge blocks with the same md5 value. Since each block has its own index value, we will insert the blocks into the file as an array according to the index to form a complete file.
When uploading in blocks, it should correspond to the block size, block quantity and current block index of the front end for file merging. Here, we use disk mapping to merge files.
//Both read and write operations are allowed RandomAccessFile tempRaf = new RandomAccessFile(tmpFile, "rw"); //It returns the only channel of file in nio communication FileChannel fileChannel = tempRaf.getChannel(); //Write the slice data slice size * which slice gets the offset long offset = CHUNK_SIZE * multipartFileDTO.getChunk(); //Fragment file size byte[] fileData = multipartFileDTO.getFile().getBytes(); //Map the area of the file directly to memory MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, offset, fileData.length); mappedByteBuffer.put(fileData); // release FileMD5Util.freedMappedByteBuffer(mappedByteBuffer); fileChannel.close();
Every time a block upload is completed, you also need to check the file upload progress to see whether the file upload is completed.
RandomAccessFile accessConfFile = new RandomAccessFile(confFile, "rw");
//Mark the segment as true to indicate completion
accessConfFile.setLength(multipartFileDTO.getChunks());
accessConfFile.seek(multipartFileDTO.getChunk());
accessConfFile.write(Byte.MAX_VALUE);
//completeList checks whether all are completed. If all are in the array (all fragments are uploaded successfully)
byte[] completeList = FileUtils.readFileToByteArray(confFile);
byte isComplete = Byte.MAX_VALUE;
for (int i = 0; i < completeList.length && isComplete == Byte.MAX_VALUE; i++) {
//And operation. If some parts are not completed, isComplete is not byte MAX_ VALUE
isComplete = (byte) (isComplete & completeList[i]);
}
accessConfFile.close();
Then update the file upload progress to Redis.
//Update the status in redis: if true, it proves that all the large files have been uploaded
if (isComplete == Byte.MAX_VALUE) {
stringRedisTemplate.opsForHash().put(UploadConstants.FILE_UPLOAD_STATUS, multipartFileDTO.getMd5(), "true");
stringRedisTemplate.opsForValue().set(UploadConstants.FILE_MD5_KEY + multipartFileDTO.getMd5(), uploadDirPath + "/" + fileName);
} else {
if (!stringRedisTemplate.opsForHash().hasKey(UploadConstants.FILE_UPLOAD_STATUS, multipartFileDTO.getMd5())) {
stringRedisTemplate.opsForHash().put(UploadConstants.FILE_UPLOAD_STATUS, multipartFileDTO.getMd5(), "false");
}
if (!stringRedisTemplate.hasKey(UploadConstants.FILE_MD5_KEY + multipartFileDTO.getMd5())) {
stringRedisTemplate.opsForValue().set(UploadConstants.FILE_MD5_KEY + multipartFileDTO.getMd5(), uploadDirPath + "/" + fileName + ".conf");
}
}
Reply to break to get the complete source code!
That's all for today. If you have different opinions or better idea s, please contact ah Q. add ah q and join the technical exchange group to participate in the discussion!