Reading and writing data files
- Text file read
- csv file read
- Definition
- Basic read
- Read by list index
- Give the contents read by reader to namedtuple
- Give the dictionary what you read
- Writing csv file
- JSON file processing
- json introduction
- Dictionary table converted to json data
- Return json string as python's dictionary table
- json document operation
- Difference between dict and json types: true/false, different writing methods of null
- Reading excel file
Text file read
Illustrate with examples
Put the operations of different files in different directories,
Right click in project to add a directory
If it's just a pure file and there's no package concept, select directory directly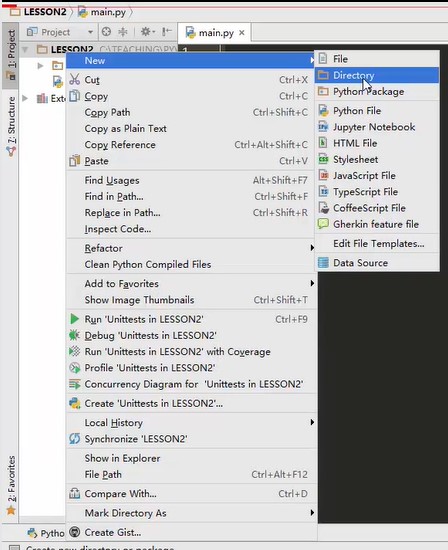
Create a txt file directory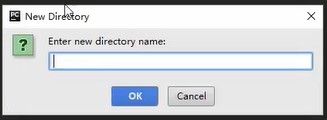
This way, no "init" files are created in the directory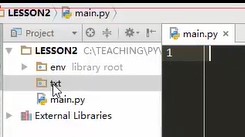
Put the operation files in the txt directory, and different files operate in different directories
Right click on the txt directory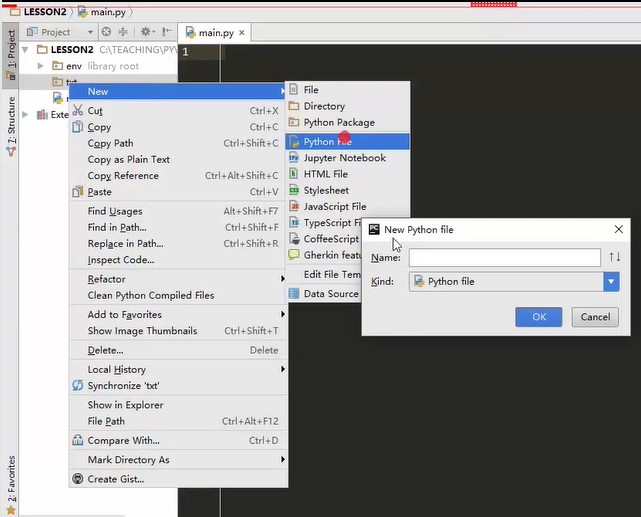
Add a run.py file. It has nothing to do with the original main.py file. It can be operated directly in txt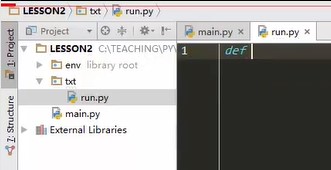
# Define a function in which you can write a string description of a document. In this way, if you want to view the help of this function, you can write help TXT? Writer () to see the information about this function def txt_writer() """Writing file""" with open('data.txt','w',encoding='utf8') as f # Write to the context to release the handle / resource automatically. f is the file handle. What to write next f.write('Superior class\n') #Write is to write one line. Write multiple lines to put them in a list. Use the writelines method lines = ['Address: Beijing\n', 'QQ:95001678\n', 'Website:http://uke.cc'] f.writelines(lines) #The writelines method writes the list lines to a collection # Write a function on it. The running script will not execute. You need to write a main function if __name__ == '__main__' # This code snippet is commonly used, which has been integrated in pycharm, and can be used to help generate quickly. Write main and press tab. txt_writer()
Run the above code and create the data.txt file in the txt directory. The result is as follows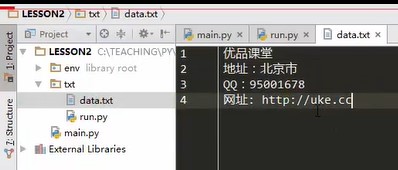
Read:
def txt_writer() """Writing file""" with open('data.txt','w',encoding='utf8') as f f.write('Superior class\n') lines = ['Address: Beijing\n', 'QQ:95001678\n', 'Website:http://uke.cc'] f.writelines(lines) def txt_read() """read file""" with open('data.txt','r',encoding='utf8') as f #The next read can traverse it or use readlines to read it into a collection for line in f #f is an iterator. Read is to read all text at once as a whole, and read lines is to read each line into a list print(line,end=' ') #Print will automatically add / N after each line, and the content of the previous file will also add / N, so the printed result may be two line breaks in the middle. In this way, the / n that comes with the print is replaced with null if __name__ == '__main__' # This code snippet is commonly used, which has been integrated in pycharm, and can be used to help generate quickly. Write main and press tab. txt_writer()
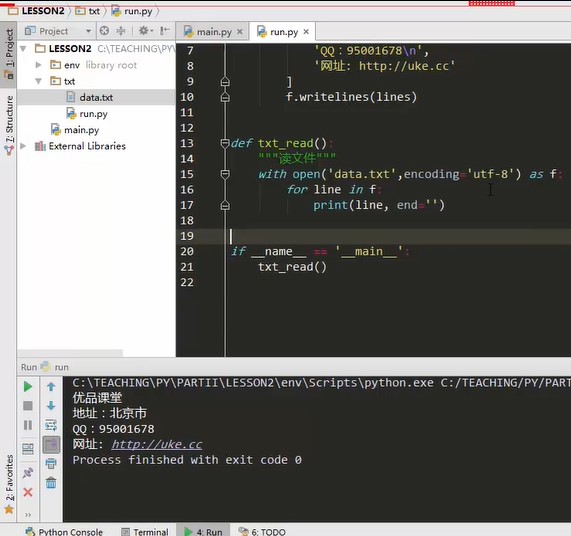
The actual development involves the data exchange of different data sources, with a large amount of data, such as exporting information from the database, or downloading some xsml or Json formats from the Internet. If these files are replaced with. txt files, later parsing and reading are troublesome, because there is no semantic label or meaning in them.
Consider other formats
Data exchange between different language framework platforms is common, including csv,
csv file read
Definition
csv:
c. comma, s, separate, v, value
Comma separated values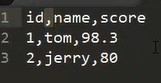
tsv
tab separated values
This kind of file is essentially a text file, with the suffix of csv/tsv, but with semantic labels. Commas distinguish different fields, different lines and different columns
- Where do csv files come from
The data comes from the input and output of the program, maybe a database export
For example, export the data of a table from the database, turn it into csv, put it under my project, and operate on it
Create a directory first
Import the files in the database into the csv directory in csv format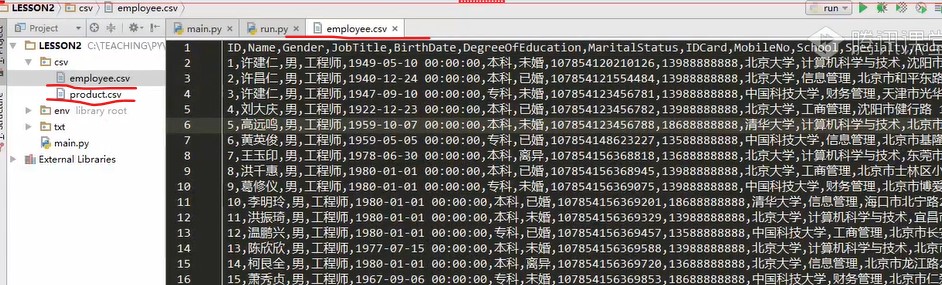
Create a new run.py file in the csv directory to process the csv file
Basic read
reader method basic read
- csv file read
csv file operations do not use third-party packages / libraries, but are available in built-in modules
The two classes under the CSV package, reader and write, and the product.csv file are iterative
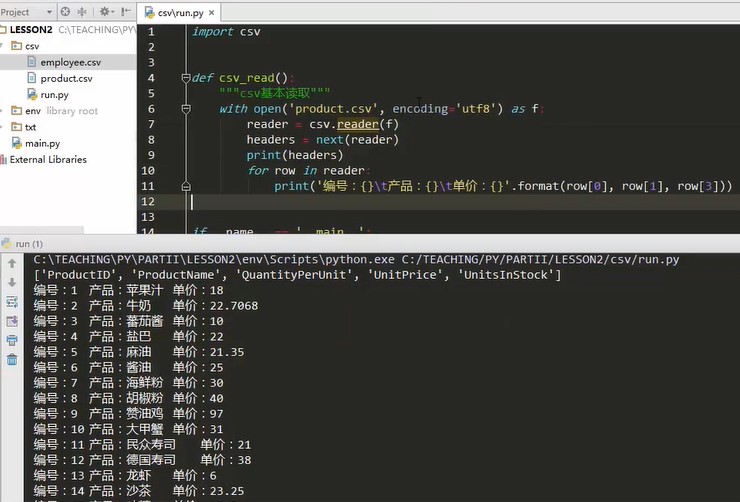
import csv def csv_read(): """csv Basic read""" with open('product.csv',encoding='utf8') as f # The two classes under the CSV package, reader and write, and the product.csv file are iterative reader = csv.reader(f) #Next, print out the first line. Because it is an iterator, the iterator can use for traversal headers = next(reader) #Next global function, traversing the first line. After the first line is traversed, the pointer will not go back. The first line can no longer be traversed. The next traversal starts directly from the second line print(heardes) for row in reader print(row) if __name__ == '__main__' csv_read()
Operation error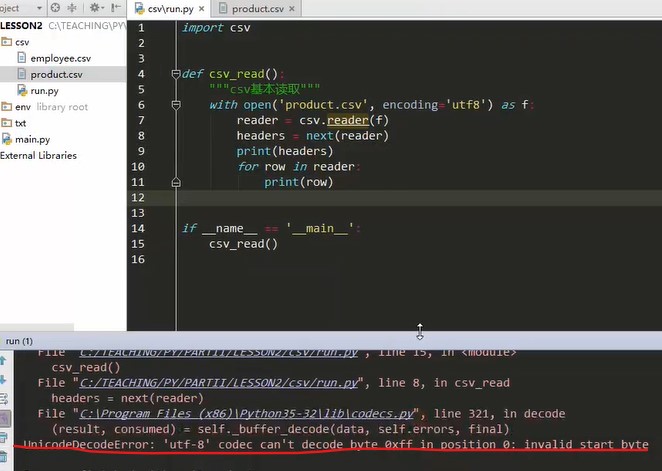
Coding problem:
Open product.csv to see what its essential encoding is
Pycharm will prompt what the code is, the lower right corner of pycharm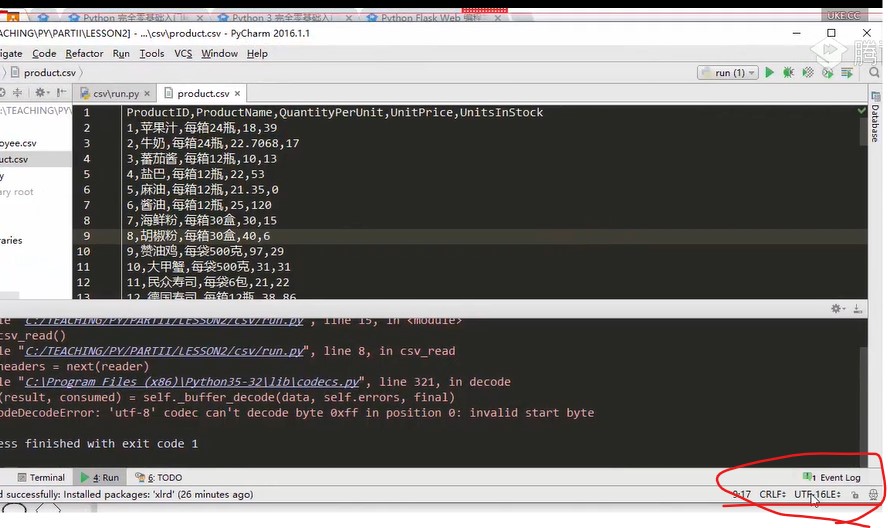
Change it here,
Click utf16 in the lower right corner to convert it to utf8,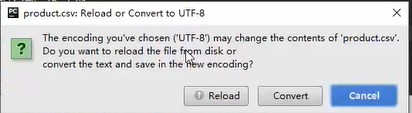
Convert, convert to utf8
Rerun code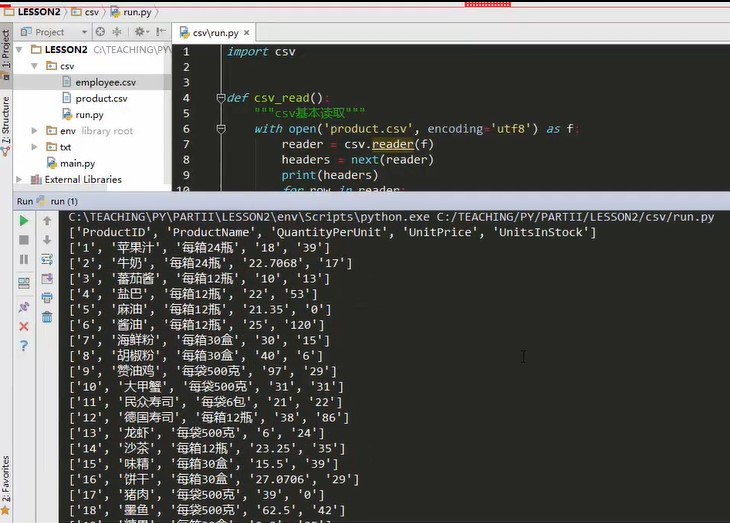
It is to make a list of each line and print it out. In this way, the list information can be retrieved at will
A row is a list
For example, print a line of information, or format it,
Read by list index
The reader read result itself is a list
- Print the following string result:
import csv def csv_read(): """csv Basic read""" with open('product.csv',encoding='utf8') as f reader = csv.reader(f) # headers = next(reader) print(heardes) for row in reader # A row is a list. Print a string result print('number:{}\t product:{}\t Unit Price:{}'.format(row[0],row[1],row[3])) if __name__ == '__main__' csv_read()
At the database level, the top row is from the database column header, but when it comes to the csv file, it becomes text, which has nothing to do with the following. In the actual operation, you want the id to correspond with the following information one by one. You can use name.tuple to find the tuple named by name. The above words are index, easy to make mistakes.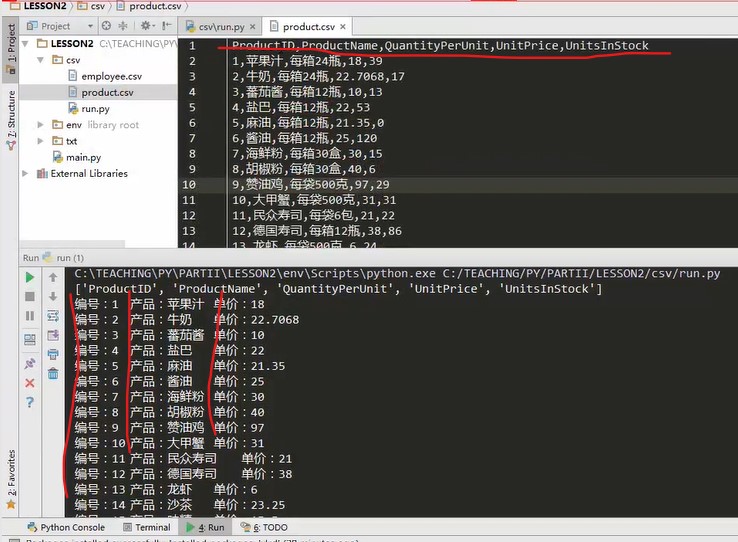
Give the contents read by reader to namedtuple
- namedtuple to map a column name
In actual operation, you want the id to correspond with the following information one by one. You can use the named tuple to find the tuple by name.
namedtuple is equivalent to defining a simple class, that is, defining an object,
import csv from collections import namedtuple def csv_read(): """csv Basic read""" with open('product.csv',encoding='utf8') as f reader = csv.reader(f) # headers = next(reader) print(heardes) for row in reader # Give this object a name, and don't worry about forgetting it. def csv_read_by_namedtuple(): """read csv And use namedtuple Mapping column names""" with open('product.csv',encoding='utf8') as f reader = csv.reader(f) headers = next(reader) #Separate the first line, or print the first line as data. List the headers and read the first row. Next, define a namedtuple object #Row = namedtuple('Row',['productID','Product'] ) # name object, defined by namedtuple, is called Row. Give him a list later. What the list later gives him is the final object, the assumed member of this class. As I have just read it, there is no need to write it one by one in the headers. The heardes is a list, and the headers list is assigned to the Row = namedtuple('Row',headers) # The columns read in the headers will be used as the name of Row. Next, put each column of data in its ID field. For example, put apple juice on the product name field. The declared row tuple is an object, just a framework structure with a label. When a Row of data is obtained, it has a value. Every Row traversed creates an instance, which uses the declared Row structure, and then one-to-one correspondence between the traversed Row and the structure label. This is what we do in the following cycle. for r in Reader #Above is the declaration of a tuple, which is equivalent to a class. Now it is equivalent to creating an instance of a class. Create instance to pass value row = Row(*r) #Give him the list information r read just now. Method parameter passing, tuple or list can be unpacked with asterisk * and each column in the list will be automatically mapped to each column corresponding to the header headers in Row. roe is equal to Row creating his instance and unpacking R's information to it. print(row) print('number:{}\t product:{}\t Unit Price:{}'.format(row[0],row[1],row[3])) if __name__ == '__main__' csv_read_by_namedtuple()
Explain and declare Row, Row = namedtuple('Row ', headers), traverse the content in Row, for r in Row:
As an object, the declared row tuple is just a framework structure with labels, and then when a Row of data is obtained, there is value. Every Row traversed creates an instance, which uses the declared Row structure, and then one by one corresponds the traversed Row with the structure label. Do it in the following cycle
This is it.
Run result, print out is the type of Row object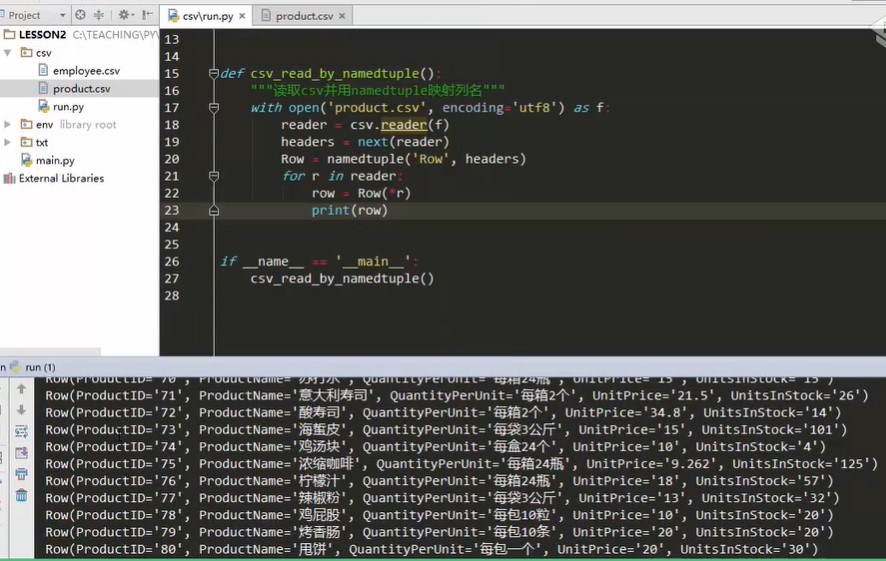
- namedtuple, you can click its result just like using the instance of the class. When printing, you write a row to save trouble. You can do whatever you want.
For example: with formatting,
It doesn't take into account the column number when using it, just like using an instance of a class,
import csv from collections import namedtuple def csv_read(): """csv Basic read""" with open('product.csv',encoding='utf8') as f reader = csv.reader(f) # headers = next(reader) print(heardes) for row in reader def csv_read_by_namedtuple(): """read csv And use namedtuple Mapping column names""" with open('product.csv',encoding='utf8') as f reader = csv.reader(f) headers = next(reader) Row = namedtuple('Row',headers) for r in Reader row = Row(*r) print('{} -> {} -> {}'.format(row.ProductID,row.ProductName,row.UnitPrice) print('number:{}\t product:{}\t Unit Price:{}'.format(row[0],row[1],row[3])) if __name__ == '__main__' csv_read_by_namedtuple()
Give the dictionary what you read
Dictionary table's own reading method, csv.DictReader()
7. dictionary table
mport csv from collections import namedtuple def csv_read_by_dict(): """read csv To the dictionary table""" with open('product.csv',encoding='utf8') as f reader = csv.DictReader(f) # Use csv.reader(f), always as a list to wrap, as a dictionary table with dictreader method for row in reader #Each row is a dictionary table, which is traversed print(row) print('{} -> {} ->{}'.format(row['ProductID'],row.get('ProductName','Not filled'},row.get{'UnitPrice',0.0}
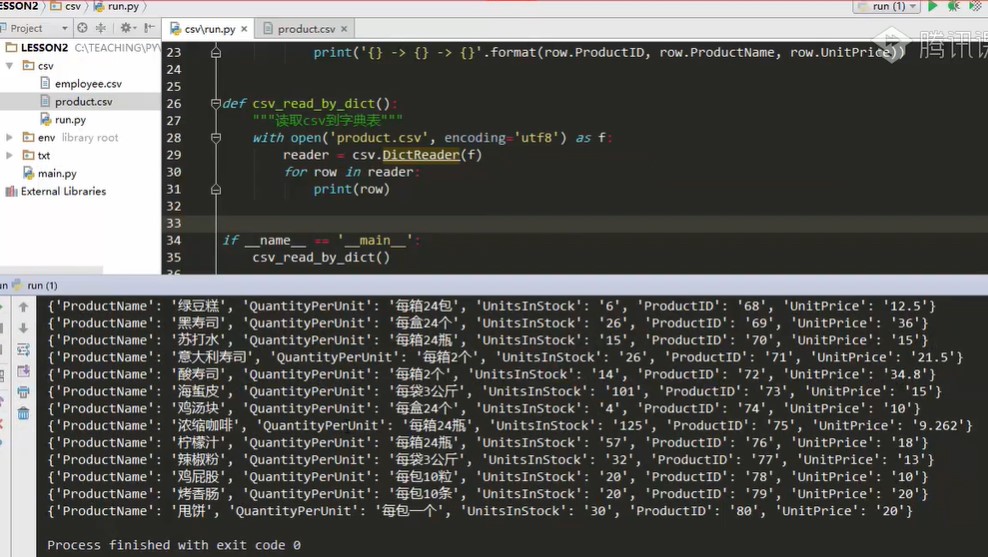
This is to treat the comma separated text in the text file as a python object, and then to get each column, you can operate.
Operation result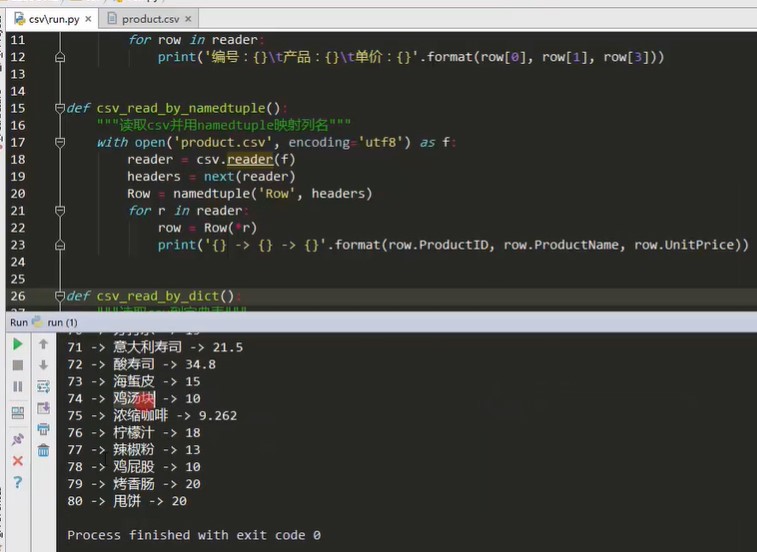
Different data structures call different methods
Writing csv file
Read file through reader
Write file through writer
The data processed in python is saved as a csv file.
Do not take the file name as the same as the existing module name of python, otherwise when importing a module, python cannot figure out which one to import.
For example, if the file name here is csv_script.py, named csv.py, because the. Py file itself is both a script and a module, an error will occur when writing code import csv in csv.py.
Do not define the names of python built-in modules or third-party modules that already exist.
Write the contents of the list
import csv def csv_write() """Write in csv file""" #Similar to text files, the operation is to find a context object named f through the open method. Before writing, prepare the data, and organize the data from outside into python data structure. If there is a header, put the header in the headers list headers = ['number'.'curriculum','lecturer'] #Head, head. Next, there are several pieces of data, similar to rows / columns in the database. The most typical one is tuple rows = [(1,'Python','Eason'), (2,'C#','Eason'), (3,'Django','Eason'), (4,'.NET','Eason')] #The header is placed in a list, multiple tuples are placed in a row, one tuple has three columns, corresponding to the above, and multiple tuples are placed in one list. #Now there are two data structures: one is a single row and multiple columns, one is a list, and two is multiple rows. Tuple is suitable for describing the rows in the data table. The rows returned by the database read-write operation python are also tuple #Data can be assigned, ctrl+d in pycharm #Next, write them to a file. Instead of writing to an existing file, create a with open('my_course.csv','w',encoding='utf8') as f # with is not necessary, but it can complete the creation, reading and writing, and closing. After the code is written, it will automatically close #The contents of the header and the bottom are written on the top. Next, the writer should be constructed writer = csv.writer(f) #Next, write the file to the writer after the csv package to help writer.writerow(headers) #Write method, write a line, write the header first, writer.writerows(rows) #Write multiple lines in the list, if __name__ == '__main__' csv.write()
Operation result: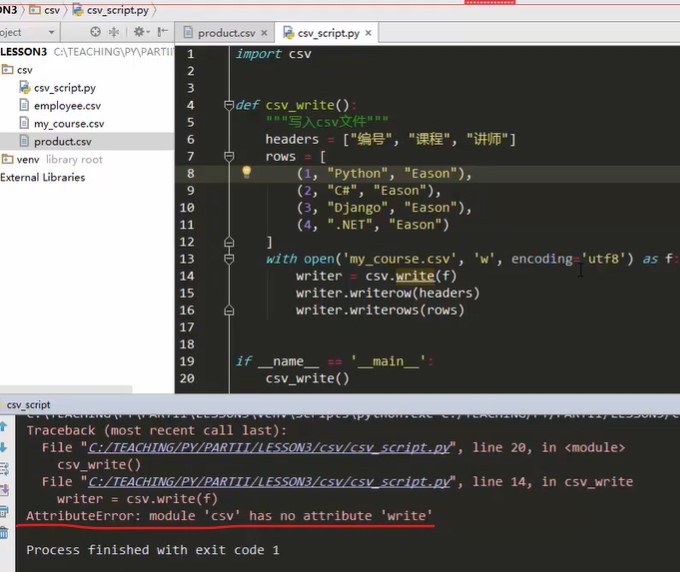
One less r,
Run results after changes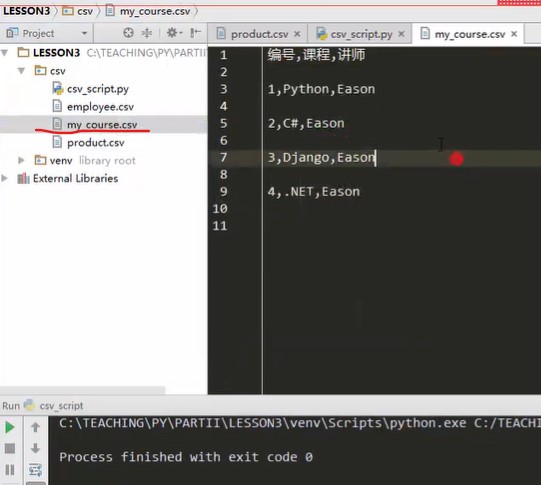 There is no change in the running result, but there is an extra my course.csv in the project file on the left, as shown in the right figure. A blank line is added between each line of text in the result.
There is no change in the running result, but there is an extra my course.csv in the project file on the left, as shown in the right figure. A blank line is added between each line of text in the result.
When creating a file just now, add newline = ', an empty character, and the default value after newline is / n. replace it.
with open('my_course.csv','w',encoding='utf8',newline=' ') as f
Operation result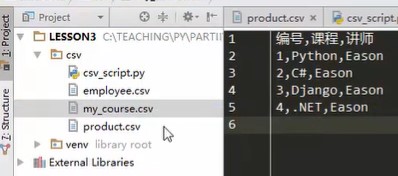
As a result, the comma in the text is not the comma in the tuple, but created by the wrapped csv.write.
Put reading and writing together
import csv def csv_reader() """read csv""" with open('my_course.csv',encoding='utf8') as f reader=csv.reader(f) headers = next(reader) print(headers) for row in reader print(row) def csv_write() """Write in csv""" headers = ['number'.'curriculum','lecturer'] rows = [(1,'Python','Eason'), (2,'C#','Eason'), (3,'Django','Eason'), (4,'.NET','Eason')] with open('my_course.csv','w',encoding='utf8') as f writer = csv.writer(f) writer.writerow(headers) writer.writerows(rows) if __name__ == '__main__' csv.write()
Operation result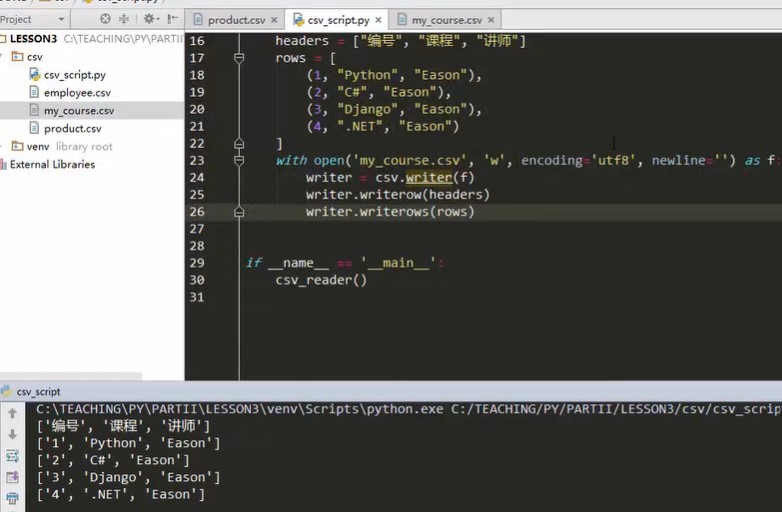
Dictionary table content writing
import csv def csv_reader() """read csv""" with open('my_course.csv',encoding='utf8') as f reader=csv.reader(f) headers = next(reader) print(headers) for row in reader print(row) def csv_write_dict() """with dict Form write csv""" #Prepare data as a dictionary headers = ['ID'.'Title','Org','Url']#In the list, the content in the bottom rows is still a list outside, and the content in the bottom rows is changed to dict. rows = [{'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'} {'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'} {'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'} {'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'} dict(ID:1,title:'Python',Org:'Youpinketang',Url:'http://uke.cc') dict(ID:1,title:'Python',Org:'Youpinketang',Url:'http://uke.cc')] #Dictionary table declaration method, directly write curly bracket / write dict function with open('my_course2.csv','w',encoding='utf8',newline=' ') as f writer = csv.DictWriter(f,headers) #Take headers as the second parameter of the function, and then construct the file with DictWriter to know that headers are headers. Just to know, not to write writer = csv.writer(f) writer.writeheader() #Writer method writeheader writer.writerows(rows) if __name__ == '__main__' csv.writer_dict() #The dictionary table only has this concept in the code. After writing to csv, the format is unified, separated by commas. There is no dictionary table
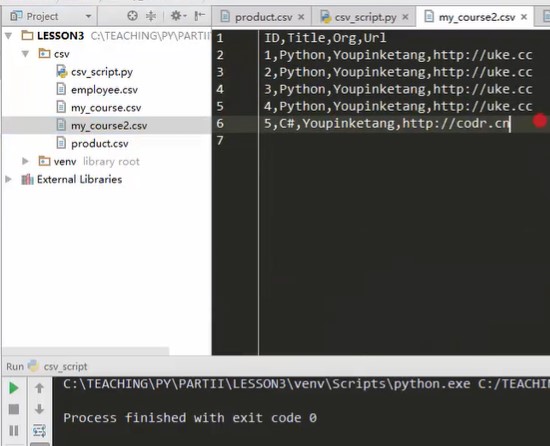
The existing one is being written once, and the original one will be overwritten.
JSON file processing
json introduction
JSON is also a standard format for exchanging data between different programs or framework languages. In essence, it is a text file, which is actually a document of comments described by javaScript.
JSON format, no matter what language of web development, will be used. Because their open API s return JSON,
XML is relatively complex in structure, a little trouble in parsing, and JSON is relatively lightweight.
json is an API interface for web development, which is to put it on the Internet and publish a public URL address. If someone requests it, they need to submit data / transmission parameters. After passing it to the URL address, a json document will be returned in the browser. This document is a string. The format looks very similar, but it is not the same.
If you want to convert the dictionary table in python to the object described in JSON format, you can: declare a string in JSON format, which comes from the data just now. Using the json.dump s method, dump (dump), adding an S is not a complex number, it is to change the content passed in brackets into a string form.
The format is similar to the dictionary table in python, but there are also some differences,
Give an example:
Open json.org for details
Dictionary table converted to json data
To convert the dictionary table in python to the object described in JSON format, you can: declare a string in JSON format, which comes from the data just now. Using the json.dump s method, dump (dump), adding an S is not a complex number, it is to change the content passed in brackets into a string form.
New working directory and file
import json def json_basic() data = {'ID':1, 'curriculum':'Python explain incisively', 'mechanism':'Superior class', 'Unit Price':98.00, 'Website':'http://codr.cn'} print('Raw data') print(data) print('-'*20)#Dividing line # To convert the dictionary table in python to the object described in JSON format, you can: declare a string in JSON format, which comes from the data just now. Using the json.dumps method, json_str = json.dumps(data) #The data in the data dictionary table has been changed to a string in json format, which has not been written to a file print(json_str) #If you want to make a comparison, you can print out the previous data
Operation result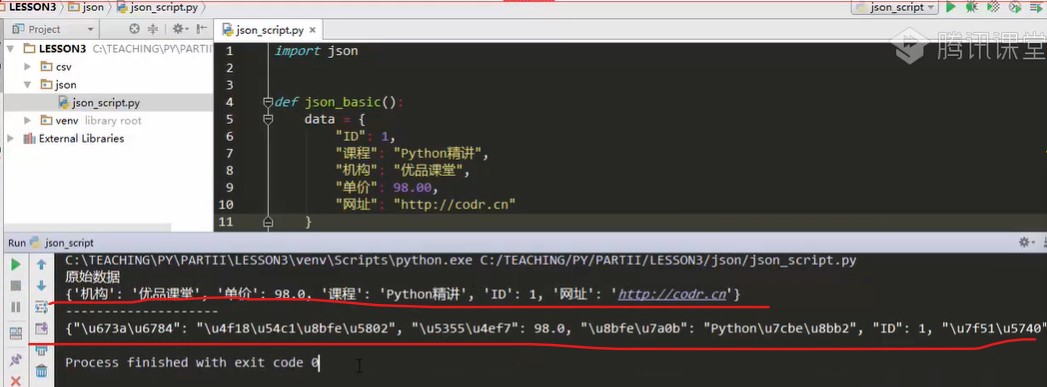
The upper line is the original data, the lower line is the string of json format data, and utf8 encoding is also done.
It can be seen from the figure that the structure of the dictionary table is the same as that of json, which is different in semantics. json belongs to the string of json, and the dictionary is the dictionary table of python.
Return json string as python's dictionary table
JSON data is converted to dict, json_data = json.loads, s is not the third person singular, but the meaning of string.
import json def json_basic() data = {'ID':1, 'curriculum':'Python explain incisively', 'mechanism':'Superior class', 'Unit Price':98.00, 'Website':'http://codr.cn'} print('Raw data') print(data) print('-'*20)#Dividing line # To convert the dictionary table in python to the object described in JSON format, you can: declare a string in JSON format, which comes from the data just now. Using the json.dumps method, json_str = json.dumps(data) #The data in the data dictionary table has been changed to a string in json format, which has not been written to a file print(json_str) #If you want to make a comparison, you can print out the previous data print('--'*20) # json data to dict json_data = json.loads(json_str) #Restore the result from the JSON STR string to the python dictionary table print(json_data)
Operation result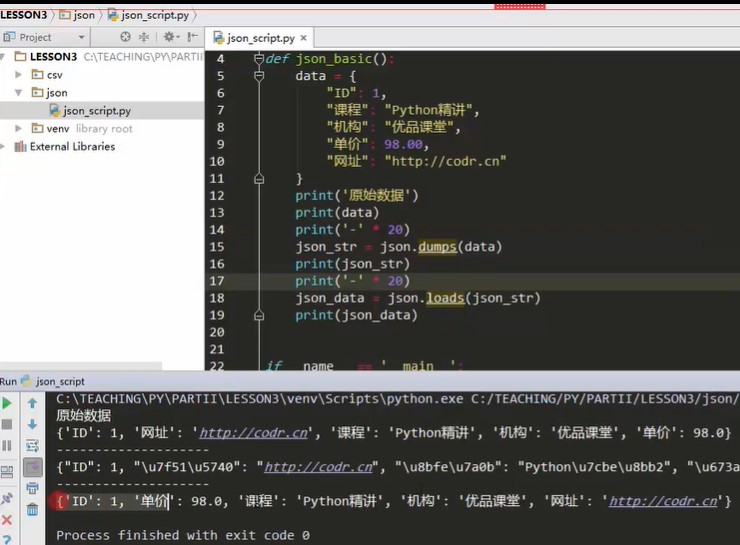
json document operation
Written by json document
json.dump(data,f)
Read from json document
json.load()
In the actual development, it is more to write it into a file. When doing web programming later, there is a request api. Here, a json document is returned to your browser for you to display, so it can be saved as a json document directly, or written to the web page this time.
Next, treat it as a file
import json def json_writer_file() """Write in json File""" data = {'ID':1, 'curriculum':'Python explain incisively', 'mechanism':'Superior class', 'Unit Price':98.00, 'Website':'http://codr.cn'} with open('data.json','w',encoding='utf8') as f json.dump(data,f) #dump does not add s because it is not written to a string, but directly to a document. Write the data in f. if __name__ == '__main__' json_writer_file()
Operation result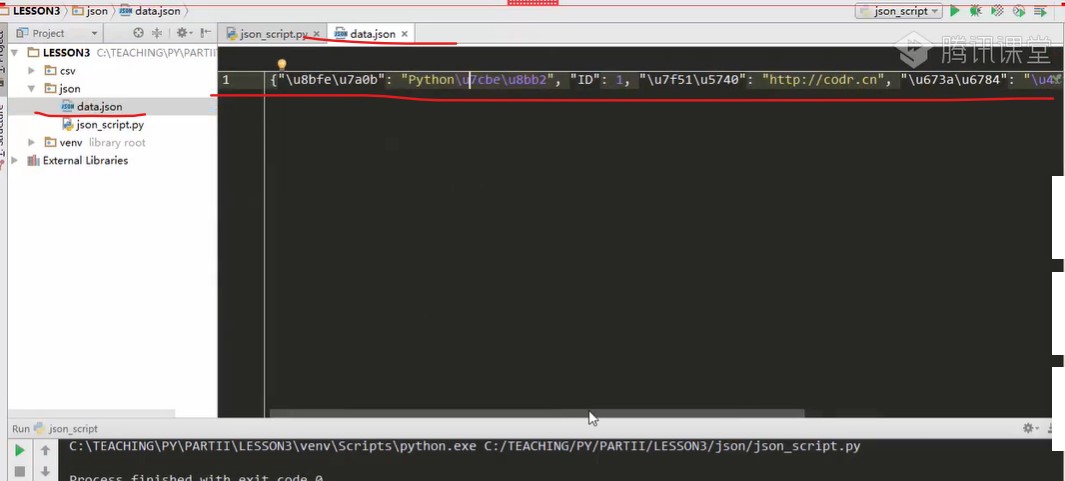
This result can be taken out and put on the Internet as an interface data for external publishing. To be a web api, you need to output it to html,
import json def json_writer_file() """Write in json File""" data = {'ID':1, 'curriculum':'Python explain incisively', 'mechanism':'Superior class', 'Unit Price':98.00, 'Website':'http://codr.cn'} with open('data.json','w',encoding='utf8') as f json.dump(data,f) #dump does not add s because it is not written to a string, but directly to a document. Write the data in f. def json_read_file() """read json file""" with open('data.json','r',encoding='utf8') as f data = json.load(f) print(data) if __name__ == '__main__' json_writer_file()
Operation result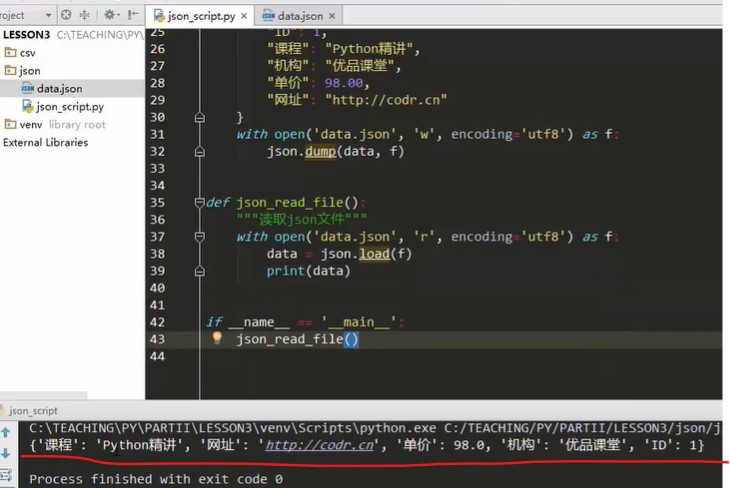
The dict of restoring data to python
Difference between dict and json types: true/false, different writing methods of null
import json def json_type_diff() """ Type difference""" print(json.dumps(False)) print(json.dumps(None)) data = {'Discontinued':False, 'Title':'iphone7s', 'Category':None, 'Price':5999.00} print(json.dumps(data)) if __name__ == '__main__' json_type_diff()
False in python, false in json
None----null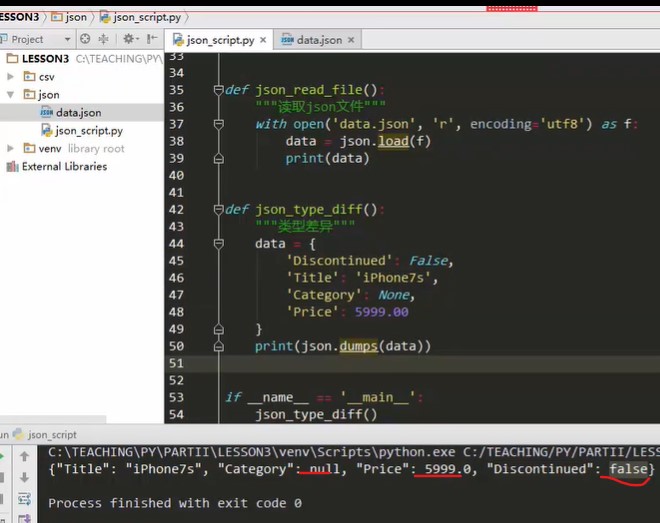
Other operations. For example, put the key value pair of json into the class and load it as a member of the class
Reading excel file
Install xlrd
excel files can also be exported through the database
python does not have a built-in module to deal with excel. It installs the third-party package. It uses pip to install under the command line. In pycharm, it installs directly on the interface. It searches for xlrd (read package), xlwr (written package), and more xlutils (tool kit)
Currently, only read package xlrd is used
read
- Form information
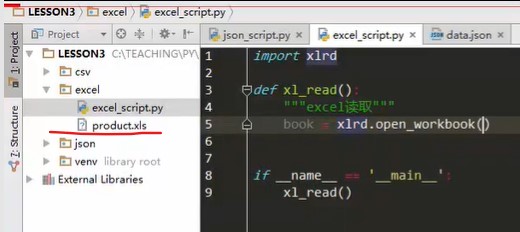
If there are many methods written in a script, different methods handle different documents, some handle json, some handle csv, and the import package is not put on the top of the import line, write it into the function
def xl_read() """excel read""" import xlrd #Import in function, valid only in current function, not outside book =xlrd.open_workbook('product.xls')#xlrd.openworkbook Method, open a table #Next, find the workbook sheet to operate on for sheet in book.sheets() #book.sheets method. It can be seen from the name that sheets are a collection. This method function can find all sheet labels and traverse sheets in the sheet, print(sheet.name) #Workbook, sheet, write properties to him in object-oriented form, print out the property name of sheet if __name__ == '__main__' xl_read()
As a result, the name of each workbook in the worksheet appears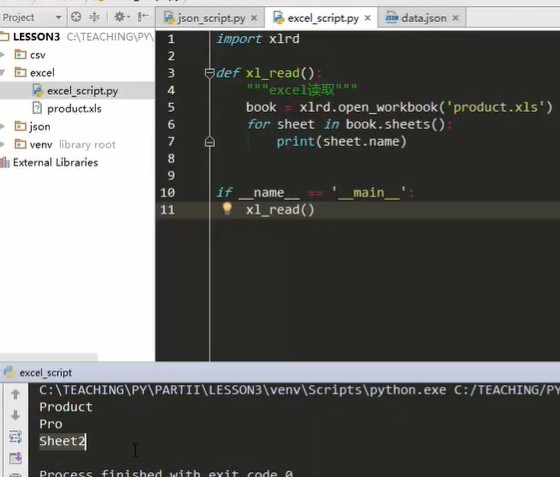
- print data
def xl_read() """excel read""" import xlrd #Import in function, valid only in current function, not outside book =xlrd.open_workbook('product.xls') for sheet in book.sheets() print(sheet.name) def xl_read_data() """data fetch""" book = xlrd.open_workbook('product.xls') sheet = book.sheet_by_name('Product') #Filter out which sheet I want to operate, the. Sheet by index method, the. Sheet by name method, and the name of the sheet print('workbook:{}'.format(sheet.name)) print('Data rows:{}'.format(sheet.nrows)) # Traversal, you can use for traversal, but the data in excel may be large, for one-time reading, low efficiency. After knowing the number of rows, you can cycle the specified number of times and only find the specified rows print('Product data') print('=' * 50) for i in range((sheet.nrows)) print(sheet.row_values(i)) #Gets the data row specified by the index. . row? Values method if __name__ == '__main__' xl_read()
Function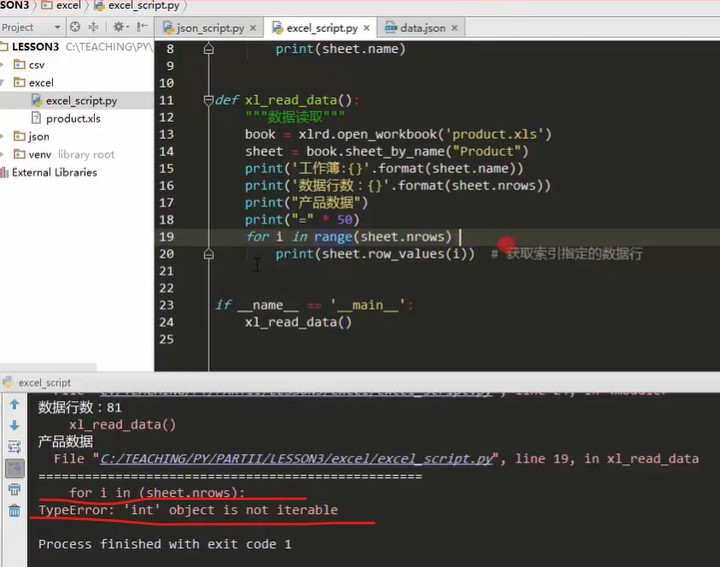
int cannot traverse. Use range, for i in range((sheet.nrows))
Print results: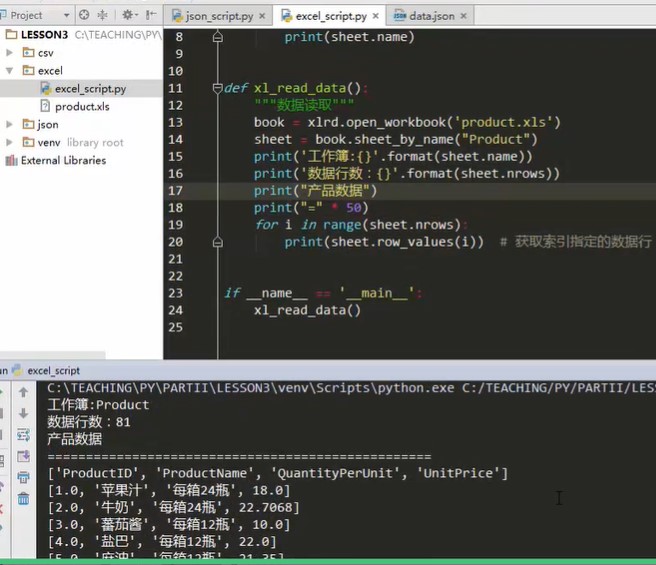
- As long as a specific row, you can further traverse, loop nesting, loop to this row, and recycle each column of this row. If a row is looped out, it is a list. Every column in this list can also be looped out

