Follow < buddy (anti fragment mechanism) of Linux kernel (4) > , if there is not enough memory in the migration type specified in the same zone, the fallback mechanism will be started to find suitable other types from the fallbacks array, obtain the steel page, and implement the core processing function of steel page as steel_ suitable_ fallback.
steal_suitable_fallback
steal_suitable_fallback is defined as follows:
void steal_suitable_fallback(struct zone *zone, struct page *page, unsigned int alloc_flags, int start_type, bool whole_block)
Function function:
- Implement the core function of steel page: whether to modify the page block migrate type attribute when implementing the steel page. When the order is large enough, the entire pageblock will be migrated at one time, and the page block migratetype will be modified at the same time. When only a part of the steel pageblock is in memory, the page block migratetype is not modified, which means that the current page block is in compatible migratetype, that is, part of it is used by other migratetypes. The logic is as follows:
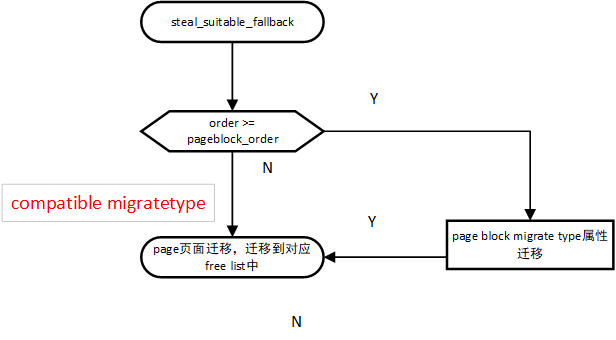
Parameters:
- struct zone *zone: the requested page is located in zone
- struct page *page: the physical page to start steel page.
- unsigned int alloc_flags: alloc flags for applying for memory usage.
- int start_type: the migration type specified in the memory request.
- bool whole_block: whether to steal the whole page block.
steal_suitable_fallback process
steal_ suitable_ The fallback processing flow is as follows:
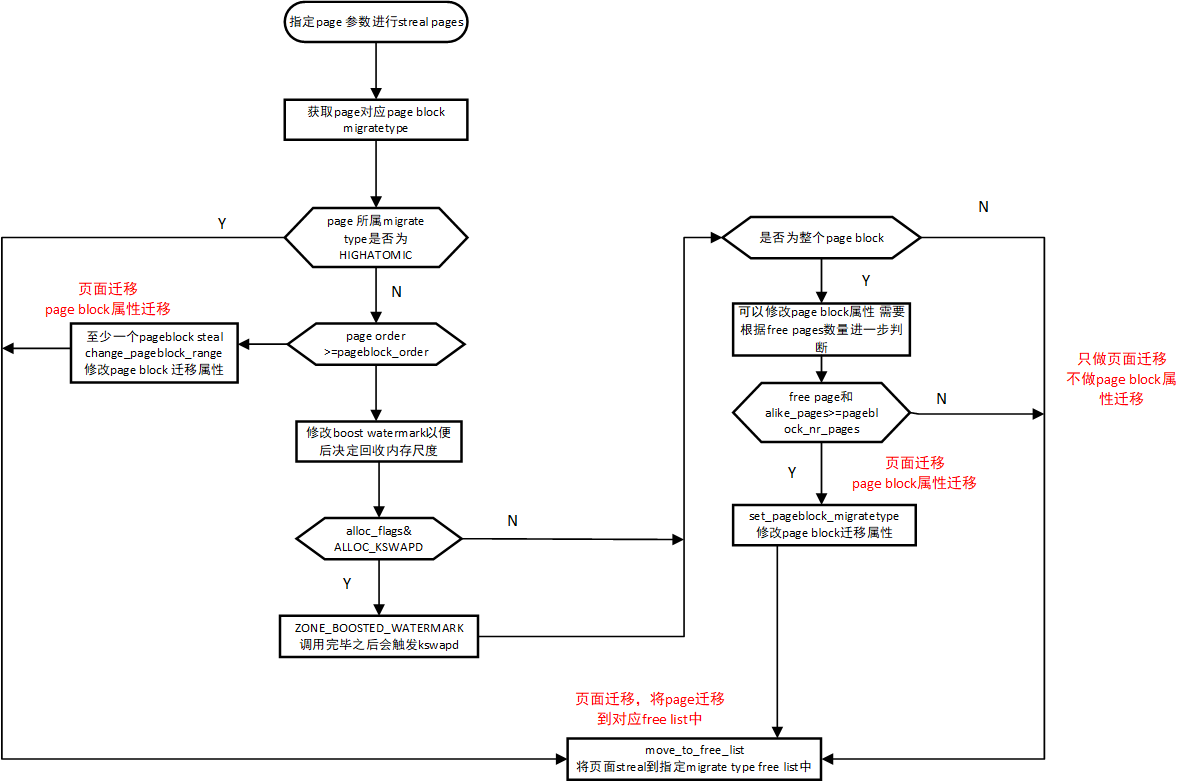
steal_suitable_fallback source code
Combined with steel_ suitable_ Fallback source code analysis:
/*
* This function implements actual steal behaviour. If order is large enough,
* we can steal whole pageblock. If not, we first move freepages in this
* pageblock to our migratetype and determine how many already-allocated pages
* are there in the pageblock with a compatible migratetype. If at least half
* of pages are free or compatible, we can change migratetype of the pageblock
* itself, so pages freed in the future will be put on the correct free list.
*/
static void steal_suitable_fallback(struct zone *zone, struct page *page,
unsigned int alloc_flags, int start_type, bool whole_block)
{
unsigned int current_order = page_order(page);
int free_pages, movable_pages, alike_pages;
int old_block_type;
old_block_type = get_pageblock_migratetype(page);
/*
* This can happen due to races and we want to prevent broken
* highatomic accounting.
*/
if (is_migrate_highatomic(old_block_type))
goto single_page;
/* Take ownership for orders >= pageblock_order */
if (current_order >= pageblock_order) {
change_pageblock_range(page, current_order, start_type);
goto single_page;
}
/*
* Boost watermarks to increase reclaim pressure to reduce the
* likelihood of future fallbacks. Wake kswapd now as the node
* may be balanced overall and kswapd will not wake naturally.
*/
boost_watermark(zone);
if (alloc_flags & ALLOC_KSWAPD)
set_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
/* We are not allowed to try stealing from the whole block */
if (!whole_block)
goto single_page;
free_pages = move_freepages_block(zone, page, start_type,
&movable_pages);
/*
* Determine how many pages are compatible with our allocation.
* For movable allocation, it's the number of movable pages which
* we just obtained. For other types it's a bit more tricky.
*/
if (start_type == MIGRATE_MOVABLE) {
alike_pages = movable_pages;
} else {
/*
* If we are falling back a RECLAIMABLE or UNMOVABLE allocation
* to MOVABLE pageblock, consider all non-movable pages as
* compatible. If it's UNMOVABLE falling back to RECLAIMABLE or
* vice versa, be conservative since we can't distinguish the
* exact migratetype of non-movable pages.
*/
if (old_block_type == MIGRATE_MOVABLE)
alike_pages = pageblock_nr_pages
- (free_pages + movable_pages);
else
alike_pages = 0;
}
/* moving whole block can fail due to zone boundary conditions */
if (!free_pages)
goto single_page;
/*
* If a sufficient number of pages in the block are either free or of
* comparable migratability as our allocation, claim the whole block.
*/
if (free_pages + alike_pages >= (1 << (pageblock_order-1)) ||
page_group_by_mobility_disabled)
set_pageblock_migratetype(page, start_type);
return;
single_page:
move_to_free_list(page, zone, current_order, start_type);
}
- Get the migration type (migration attribute) of the corresponding page block according to the page to steal (also known as migration).
- If the page migration attribute is migrate_ High atomic, it means that the order is 0. Instead of paga block migration attribute, call move directly_ to_ free_ List to migrate the page to the corresponding freelist.
- If current of steel page_ Order is greater than or equal to pageblock_order, it means that the page to be migrated must be greater than at least one page block. Call change directly_ pageblock_ Range, modify the migration attribute of the corresponding page block, and move the page to be migrated_ to_ free_ List migrates the page to the corresponding freelist.
- If none of the above is true, you need to further judge whether you can modify page block migrate type.
- First, modify the zone boost water mark to determine the memory recovery scale of kswapd.
- If alloc_flags setting ALLOC_KSWAPD, the memory is migrated. Because the memory is insufficient, the KSWAPD thread can be triggered in advance to perform memory regularization and other operations, so as to sort out the free physical memory in advance
How to trigger kswapd kernel thread:
/*
* This function implements actual steal behaviour. If order is large enough,
* we can steal whole pageblock. If not, we first move freepages in this
* pageblock to our migratetype and determine how many already-allocated pages
* are there in the pageblock with a compatible migratetype. If at least half
* of pages are free or compatible, we can change migratetype of the pageblock
* itself, so pages freed in the future will be put on the correct free list.
*/
static void steal_suitable_fallback(struct zone *zone, struct page *page,
unsigned int alloc_flags, int start_type, bool whole_block)
{
unsigned int current_order = page_order(page);
int free_pages, movable_pages, alike_pages;
int old_block_type;
old_block_type = get_pageblock_migratetype(page);
... ...
/*
* Boost watermarks to increase reclaim pressure to reduce the
* likelihood of future fallbacks. Wake kswapd now as the node
* may be balanced overall and kswapd will not wake naturally.
*/
boost_watermark(zone);
if (alloc_flags & ALLOC_KSWAPD)
set_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
... ...
}
- steal_ suitable_ The fallback function sets zone - > flags to ZONE_BOOSTED_WATERMARK, when the application is completed:
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
... ...
out:
/* Separate test+clear to avoid unnecessary atomics */
if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
}
... ...
}
- The rmqueue function checks whether zone - > flags is set to ZONE_BOOSTED_WATERMARK, if set, wakeup will be called_ Kswapd triggers kswapd to perform operations such as memory regularization and recycling.
- whole_ If block is false, it means that the entire page block migration attribute cannot be modified. Only page migration will be done, not attribute migration.
- move_freepages_block: the free pages will be specified for page migration. When the number of free pages migrated and like_ Pages > pageblock_ Order, which indicates that the entire page block needs to be modified during migration.
- move_to_free_list: page migration: migrate the page from the free list in the old migration type to the new migration type free list. There will be enough memory for this memory application in the subsequent new migration type.
Allow modifying / migrating page block migrate type criteria
By Steele_ suitable_ The fallback process can derive the criteria for allowing modification / migration of page block migrate type:
- The oder corresponding to page is directly greater than or equal to pageblock_order, page block migration attribute modification is allowed.
- When the page correspondence is less than pageblock_order, whole_ If the block is false, the page block migrate type cannot be modified.
- When the page correspondence is less than pageblock_order, whole_ If block is true, you need to judge that the original attribute of page block is migrate_ Mobile means that the page block can be migrated originally, and the page block migrate type can be modified directly
- When the page correspondence is less than pageblock_order, whole_ If block is true, the original attribute of page block is not migrate_ Mobile, you need to migrate free according to the page block_ Pages number of free pages and available use of like_ Pages, if (free_pages + like_pages) > pageblock_order, which allows you to modify page block migrate type
- page block migrate type cannot be modified under other circumstances.
Use set to modify page migration properties_ pageblock_ Migratetype() function.
Page migration
Page migration uses move_to_free_list interface, delete the page from the original free list and add it to the free list corresponding to the new migrate type:
/* Used for pages which are on another list */
static inline void move_to_free_list(struct page *page, struct zone *zone,
unsigned int order, int migratetype)
{
struct free_area *area = &zone->free_area[order];
list_move(&page->lru, &area->free_list[migratetype]);
}page_group_by_mobility_disabled
page block migrate type can be through page_group_by_mobility_disabled turns on and off. When the system initializes the zone during startup, it will be judged according to the actual situation of physical memory in the zone:
/*
* unless system_state == SYSTEM_BOOTING.
*
* __ref due to call of __init annotated helper build_all_zonelists_init
* [protected by SYSTEM_BOOTING].
*/
void __ref build_all_zonelists(pg_data_t *pgdat)
{
... ...
/*
* Disable grouping by mobility if the number of pages in the
* system is too low to allow the mechanism to work. It would be
* more accurate, but expensive to check per-zone. This check is
* made on memory-hotadd so a system can start with mobility
* disabled and enable it later
*/
if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))
page_group_by_mobility_disabled = 1;
else
page_group_by_mobility_disabled = 0;
pr_info("Built %u zonelists, mobility grouping %s. Total pages: %ld\n",
nr_online_nodes,
page_group_by_mobility_disabled ? "off" : "on",
vm_total_pages);
#ifdef CONFIG_NUMA
pr_info("Policy zone: %s\n", zone_names[policy_zone]);
#endif
}
- When the memory is less than pageblock_ nr_ pages * MIGRATE_ When the types physical page is, the migrate type attribute will be turned off.
move_freepages_block
move_ freepages_ The block() function is to migrate the page to the corresponding free page when the page block is specified to allow migration:
int move_freepages_block(struct zone *zone, struct page *page,
int migratetype, int *num_movable)
{
unsigned long start_pfn, end_pfn;
struct page *start_page, *end_page;
if (num_movable)
*num_movable = 0;
start_pfn = page_to_pfn(page);
start_pfn = start_pfn & ~(pageblock_nr_pages-1);
start_page = pfn_to_page(start_pfn);
end_page = start_page + pageblock_nr_pages - 1;
end_pfn = start_pfn + pageblock_nr_pages - 1;
/* Do not cross zone boundaries */
if (!zone_spans_pfn(zone, start_pfn))
start_page = page;
if (!zone_spans_pfn(zone, end_pfn))
return 0;
return move_freepages(zone, start_page, end_page, migratetype,
num_movable);
}
- start_pfn = page_to_pfn(page): get the PFN of the page to be migrated.
- start_ pfn = start_ PFN & ~ (pageblock_nr_pages-1): align the page frame number PFN with pagbe block.
- start_page = pfn_to_page(start_pfn);page block the starting physical page after alignment.
- end_page = start_page + pageblock_nr_pages - 1: end the physical page corresponding to page block
- end_pfn = start_pfn + pageblock_nr_pages - 1: end PFN:
- Start respectively_ PFN and end_pfn check
- move_freepages: migrate pages in batches according to the specified range.
move_freepages
move_freepages will migrate the pages in the specified range to the specified migrate type free list:
/*
* Move the free pages in a range to the free lists of the requested type.
* Note that start_page and end_pages are not aligned on a pageblock
* boundary. If alignment is required, use move_freepages_block()
*/
static int move_freepages(struct zone *zone,
struct page *start_page, struct page *end_page,
int migratetype, int *num_movable)
{
struct page *page;
unsigned int order;
int pages_moved = 0;
for (page = start_page; page <= end_page;) {
if (!pfn_valid_within(page_to_pfn(page))) {
page++;
continue;
}
if (!PageBuddy(page)) {
/*
* We assume that pages that could be isolated for
* migration are movable. But we don't actually try
* isolating, as that would be expensive.
*/
if (num_movable &&
(PageLRU(page) || __PageMovable(page)))
(*num_movable)++;
page++;
continue;
}
/* Make sure we are not inadvertently changing nodes */
VM_BUG_ON_PAGE(page_to_nid(page) != zone_to_nid(zone), page);
VM_BUG_ON_PAGE(page_zone(page) != zone, page);
order = page_order(page);
move_to_free_list(page, zone, order, migratetype);
page += 1 << order;
pages_moved += 1 << order;
}
return pages_moved;
}
- Migrate according to the specified range of pages, starting from the alignment start page of page block
- move_to_free_list: migrate the entire page block to the corresponding mix type.
- Cycle through the next page block.
can_steal_fallback
can_steal_fallback determines whether the entire page block is allowed to be migrated during the steal page according to the order and migrate type. If so, migrate the entire page block and modify the page block migrate type:
/*
* When we are falling back to another migratetype during allocation, try to
* steal extra free pages from the same pageblocks to satisfy further
* allocations, instead of polluting multiple pageblocks.
*
* If we are stealing a relatively large buddy page, it is likely there will
* be more free pages in the pageblock, so try to steal them all. For
* reclaimable and unmovable allocations, we steal regardless of page size,
* as fragmentation caused by those allocations polluting movable pageblocks
* is worse than movable allocations stealing from unmovable and reclaimable
* pageblocks.
*/
static bool can_steal_fallback(unsigned int order, int start_mt)
{
/*
* Leaving this order check is intended, although there is
* relaxed order check in next check. The reason is that
* we can actually steal whole pageblock if this condition met,
* but, below check doesn't guarantee it and that is just heuristic
* so could be changed anytime.
*/
if (order >= pageblock_order)
return true;
if (order >= pageblock_order / 2 ||
start_mt == MIGRATE_RECLAIMABLE ||
start_mt == MIGRATE_UNMOVABLE ||
page_group_by_mobility_disabled)
return true;
return false;
}
- order >= pageblock_ Order: if the oder is greater than or equal to pageblock, it indicates that at least one pageblock is required, allowing the entire pageblock to be migrated
- order >=pageblock_order / 2 also allows pageblock migration
- MIGRATE_ Recyclable: indicates that the pageblock can be recycled, or the entire pageblock can be migrated directly
- MIGRATE_UNMOVABLE: you can directly migrate the entire pageblock.