C + + basic syntax
C language is a structured language, which is not suitable for large-scale program development. Bjarne et al. Adapted to the object-oriented idea and invented a new language based on C language, called C + +. C + + is based on C language. It was originally called C with class. It added the concept of class, and then gradually updated and iterated to become more rich and perfect.
The most important versions are C++98 and C++11. C++98 is the first version of C + + standard. It rewrites the C + + standard library in the form of template and introduces STL. C++11 adds many practical features to it, such as regular expression, range based for loop, auto keyword, new container, list initialization, standard thread library and so on.
C + + adds 31 keywords to the 32 keywords of C, so c + + is compatible with most of the features of C. It also implies the basic syntax of C + +, which is also to make up for some defects of C language.
1. Namespace
The emergence of namespace is to solve the problem of naming conflicts that often occur in C language. The global variables and functions defined may have naming conflicts with the variables in C/C + + library files and files written by team members in the project.
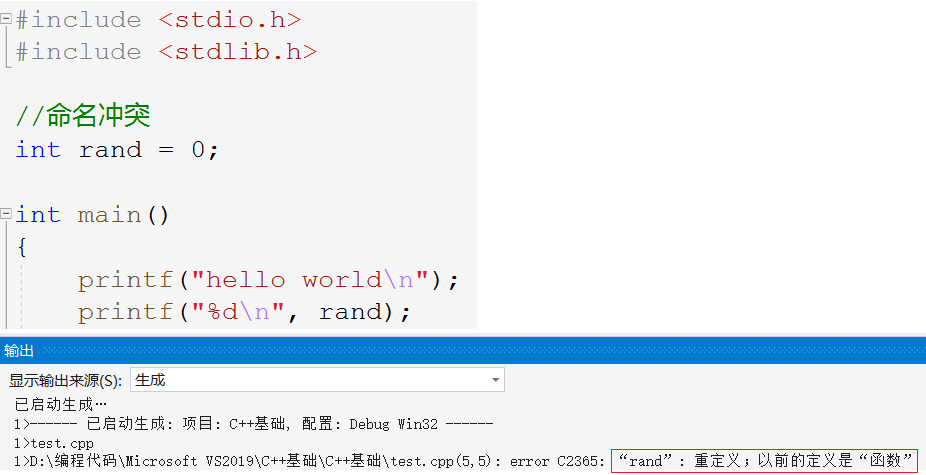
As shown in the figure, the defined global variable rand conflicts with the rand in the library. C language can't solve this problem. C + + puts forward a new syntax namespace.
1.1 definition of namespace
Namespace, that is, define a domain to define variables, functions or types. When using these variables, you need to add a specific identification before their names, and localize the names of the identifiers to avoid naming conflict or name pollution.
namespace test {
//1.
int rand = 0;
//2.
int Add(int a, int b) {
return a+b;
}
//3.
struct Node {
int data;
struct Node* next;
};
}
- Such a "domain" only adds a layer of lock to the variable and will not affect the attribute of the variable. It is still a global variable.
- Only variables or functions can be defined and initialized in the namespace. No other operations are allowed.
Nesting of namespaces
namespace N1 {
int a = 0;
int b = 0;
int Add(int a, int b) {
return a + b;
}
namespace N2 {
int c = 0;
int d = 0;
int Sub(int c, int d) {
return c - d;
}
}
}
In addition, when namespaces have the same name, two namespaces with the same name will be merged into one workspace.
1.2 use of namespace
Defining variables in a namespace is equivalent to blocking variables and can only be accessed in a specific way. There are three ways to use variables in a namespace.
Name plus scope qualifier:
namespace test
{
int rand = 0;
}
int main()
{
printf("%d", test::rand);
}
Adding the space name and:: before the variable name tells the compiler to use the variables in the namespace. Of course, the scope qualifier is not new to C + +. It can also be used in C language. For example, when the compiler looks for variables, it first looks in the local domain and then in the global domain.
int a = 0;
int main()
{
int a = 1;
printf("%d\n", ::a);
return 0;
}
: if the name of the space is not written before, it means that global variables are used.
Introduce the entire namespace
using namespace test;
int main()
{
rand = 1;
Add(1, 2);
struct Node n1;
return 0;
}
This method expands all variables or functions in the namespace. The advantage is very convenient, but the disadvantage is that it invalidates the entire namespace and may cause naming conflicts. It is equivalent to canceling isolation, so it should be used with caution.
Introducing members from a namespace
using test::rand; using test::Add; using test::Node;
Specify to introduce separate space members and expand only common members, which is relatively more secure and reliable.
The first way is to add a scope qualifier to the namespace name, which has the best isolation effect, but it is cumbersome to use. The second way is to open the entire namespace, which is the simplest and convenient, but the isolation effect is the worst, which is easy to lead to naming conflicts.
2. Input and output
#Include < iostream > / / C + + standard I / O stream file
using namespace std;
int main()
{
//1.
cout << "hello world" << endl;
//2.
std::cout << "hello world" << std::endl;
//3.
using std::cout;
using std::endl;
cout << "hello world" << endl;
return 0;
}
The implementation of C + + libraries is placed in a namespace called std, so the namespace is introduced above. Generally, you can directly expand the entire standard namespace during learning.
-
cout is actually a global variable, which is called an object in C + +. It is the standard output, that is, the console. cin is the standard input of C + +, that is, the keyboard.
-
< < stream insertion operator, > > stream extraction operator.
cout < < "hello" inserts or outputs a string into standard output. cout < < endl outputs the newline character to standard output. cout is equivalent to printf and cin is equivalent to scanf.
Cout and CIN can automatically identify the type without format controller, and can also automatically control the number of decimal places according to the value of the variable.
int i = 0; double d = 1.11; cin >> i >> d; cout << i << " " << d << endl;
You can choose both C and C + +, whichever is convenient. If you want to achieve control field width or scale, you'd better use prinf and scanf. Both cin and scanf have the problem of leaving carriage return characters \ n in the buffer.
3. Default parameters
Default means default. Just like the spare tire, you can use it if you have it. If not, you can use the default value.
3.1 definition of default parameters
The default parameter is to specify a default value for the function's parameters when declaring or defining the function. When calling this function, if no argument is passed in, the default value of the parameter is used; otherwise, the passed in value is used.
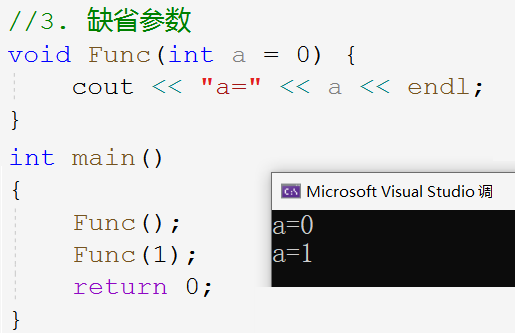
If func (1) calls the function to explicitly pass parameter 1, then a=0. Func(0) calls the function without passing parameter and uses the default value of 0.
void Func(int a = 10, int b = 20, int c = 30) {
cout << "a=" << a << endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl << endl;
}
int main()
{
Func(); // No parameter transmission
Func(1); // Pass a=1
Func(1, 2); // Pass a=1,b=2
Func(1, 2, 3); // Pass a=1,b=2,c=3
//Wrong writing
Func(,2,);
Func(,,3);
Func(1,,3);
return 0;
}
As shown in the above code, the parameters of a function with default parameters must also be passed continuously from left to right. It can be passed but not skipped. It is not allowed to specify a parameter.
3.2 classification of default parameters
-
All default parameters, that is, all parameters of the function are in the form of default values;
-
Semi default parameters, that is, only some parameters of the function take the form of default values.
//1. All default parameters
void Func(int a = 10, int b = 20, int c = 30) {
cout << "a=" << a << endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl << endl;
}
//2. Semi default parameters
void Func(int a, int b, int c = 30) {
cout << "a=" << a << endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl << endl;
}
be careful
- If the form of semi default parameter is adopted, the parameter list must default from right to left and must be continuous, which is opposite to the order of parameters passed during call. Therefore, the default parameters are usually placed on the right, as shown below:
//1.
void Func(int a = 10, int b = 20, int c = 30) {}
//2.
void Func(int a, int b = 20, int c = 30) {}
//3.
void Func(int a, int b, int c = 30) {}
//Wrong form
void Func(int a = 10, int b, int c = 30) {}
void Func(int a = 10, int b, int c) {}
- Default parameters cannot appear in function declarations and definitions at the same time. They are generally placed in declarations for easy observation.
When applying default parameters, such as stack initialization, the default parameter capacity is given to initialize the stack size. When the stack size is determined, it can be assigned directly.

4. Function overloading
Overloading means having multiple meanings, so function overloading means that a function has multiple functions, that is, different "interpretations" of the same function name.
4.1 definition of function overload
In order to meet the requirements, C + + has created a new syntax called function overloading. Function overloading is a special case of function. It is specified that several functions with the same name with similar functions are allowed in the same scope, which are generally used to adapt to different types of data. The parameter list of these functions with the same name must be different, that is, the number of parameters, parameter order and parameter type can be different.
Note that different return types are not overloaded. Because the return type alone cannot distinguish overloaded functions at call time.
//1.
int Add(int a, int b) {
return a + b;
}
//2.
int Add(int a, int b, int c) {
return a + b + c;
}
//3.
float Add(int a, float b) {
return a + b;
}
//4.
float Add(float a, int b) {
return a + b;
}
The number of the first and second parameters is different, the type of the first and third parameters is different, and the order of the third and fourth parameters is different. Discuss the number of parameters. The order type only depends on the type, which has nothing to do with the formal parameter name.
//1.
void f(int a) {
cout << "f(int a)" << endl;
}
void f(int a = 0) {
cout << "f(int a = 0)" << endl;
}
//2.
void f() {
cout << "f()" << endl;
}
void f(int a = 0) {
cout << "f(int a = 0)" << endl;
}
The first set of functions cannot be overloaded, and the parameters are independent of the default values. The second group has different number of function parameters, which constitutes an overload, but there is ambiguity when calling.
4.2 name modification
Why does C + + support function overloading and C language does not? The reason is that the search for functions is more strict when compiling links in C + +, as shown below.
C/C + + source files need to be preprocessed, compiled, assembled, linked, and finally generate executable programs. Like the source files of C, the source files are compiled separately to generate the target files, which are linked together to form an executable program.
The separation of function declaration and definition will make the compiler temporarily unable to find the address of the function when compiling the source file, and its rules for finding the function will be reflected during linking. Therefore, putting the declaration and implementation of functions into two files makes it easier to observe the differences between C + + and C in the modification rules of function names.
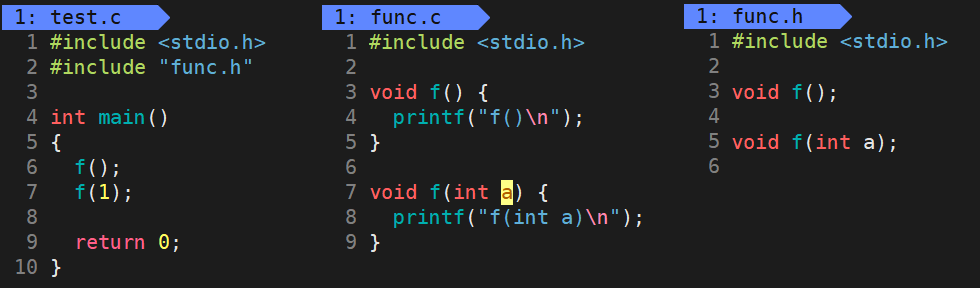
Write an example of function overloading, separate the declaration from the definition, and then write the test program. The compilation results using C language and C + + are shown in the figure below. C compilation shows function redefinition, while C + + compilation can run successfully. C language does not support function overloading.
Before delving into why C does not support and C + + supports function overloading, first review the process of compiling linked C/C + + programs.
| step | effect | Generate file |
|---|---|---|
| 1 pretreatment | Header file expansion, macro replacement, preprocessing instructions, delete comments | *. i file |
| 2 compilation | Various syntax analysis, symbol summary and generation of assembly code | *. s file |
| 3 compilation | Convert assembly code into machine instructions | *2.0 files |
| 4 links | Merge segment table, merge and relocation of symbol table | a.out |
After the whole compilation phase is completed, test O has only the function name, but no specific address of the function. After the link process, you can use func O to find the real address of the function and merge it into the symbol table.

-
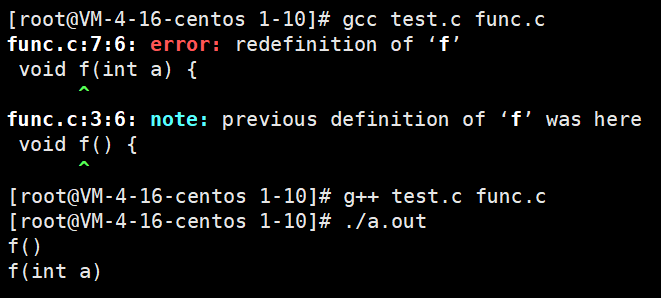
Compile func in C C, the symbol tables of two functions with the same name conflict, so the compilation fails and the link step cannot be reached. Secondly, there will be ambiguity when linking, because C language only uses function name to find function address.
-
C + + introduces function name modification rules to support function overloading, and the rules are different in different environments. It can be seen that the function search rules of C + + are more strict, and the overloaded functions have no ambiguity. Therefore, C + + does not directly use the function name to find the function address. In order to better show the comparison rules, use the following code to check in the Linux environment.
int Add(int a, int b) {
return a + b;
}
void func(int a, double b, int* p) {
;
}
int main()
{
Add(1, 2);
func(1, 2, 0);
return 0;
}
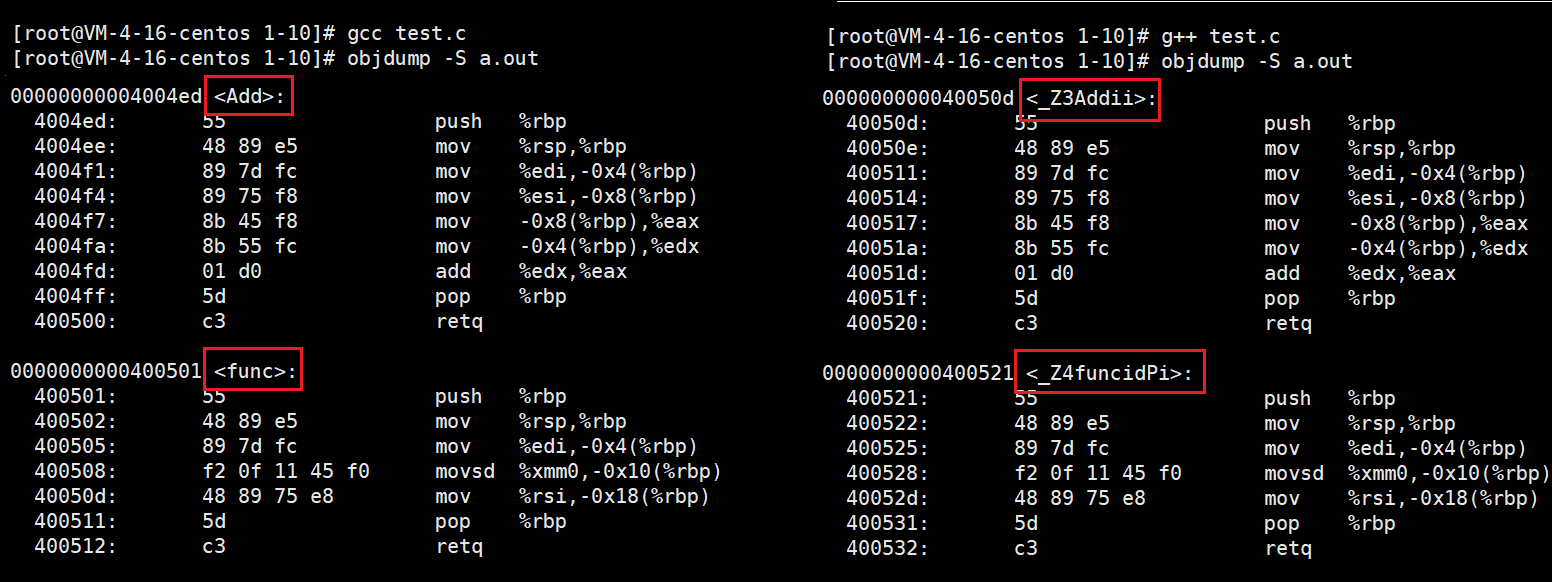
As shown on the right_ Z represents the prefix of the function, numbers 3 and 4 represent the length of the function name character, add and func represent the function name, I, D and PI take the initial letter of the parameter type to represent the parameter. From this, we can also observe the requirements of function overloading.
4.3 extern "C"
When we use C language programs to call libraries written in C + + or use C + + programs to call libraries written in C, we must introduce extern "C" into C + + files so that C + + programs can call functions in C.
It can be The location of the lib library file and header file into the project file. You can also note the file location to configure relevant settings in the calling project. The following only introduces the configuration method in vs environment, which is similar to other platforms.
Since there is no library file in the project, the location and file name of the library file should be filled in the link setting in the property setting of the project. As shown in the figure below:
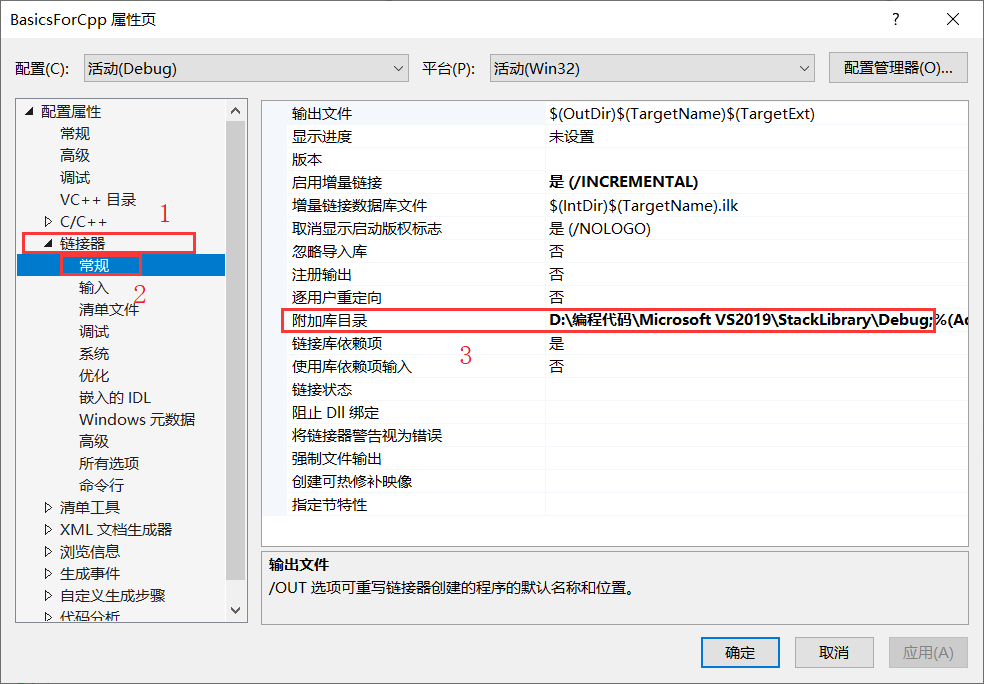
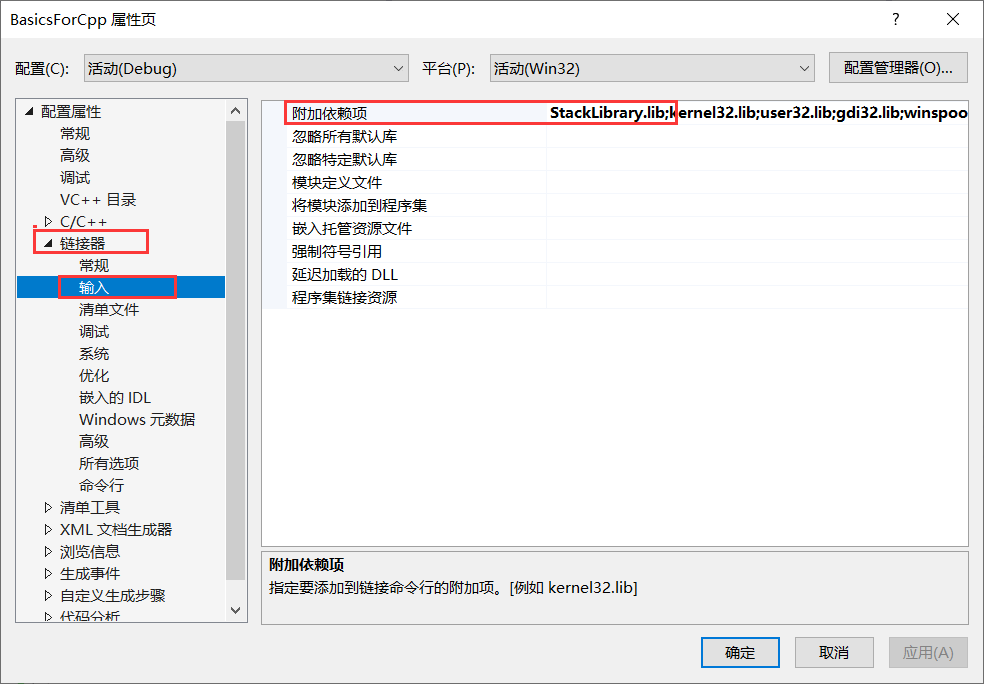
After the above steps, the project can find the library file. Next, solve the call problem. The call reports an error and cannot find the function address. This is caused by different modification rules for function names in C/C + +. So use extern"C" in C + + files. The extern"C" command is to make the file use the name modification rules of C language, so as not to find the function when the C program calls.
C + + program calls C library
To call the library written in C language for a C + + project, you only need to add such a statement to the project package header file.
extern "C"
{
#include "../../StackLibrary/StackLibrary/Stack.h"
}
C program calls C + + Library
C program calling C + + library is relatively cumbersome, because the header file must be expanded in both C and C + + files. You must add conditional compilation instructions to the header file in the C + + project to avoid encountering extern"C" when calling the C language. The basic method is as follows:
There are two ways. One is to use #ifdef__ Cplusplus adds the code of extern"C" {} to the header file. Now compile it in the C + + project to generate the code that can be called by the C language program lib file.
#define FRISTSOLUTION 1
//The first scheme
#ifdef FRISTSOLUTION
#ifdef __cplusplus
extern "C" {
#endif
void StackInit(ST* ps);
void StackPush(ST* ps, STDataType data);
void StackPop(ST* ps);
STDataType StackTop(ST* ps);
int StackSize(ST* ps);
bool StackEmpty(ST* ps);
void StackDestroy(ST* ps);
#ifdef __cplusplus
}
#endif
//The second scheme
#else
#ifdef __cplusplus
#define EXTERN_C extern "C"
#else
#define EXTERN_C
#endif
EXTERN_C void StackInit(ST* ps);
EXTERN_C void StackPush(ST* ps, STDataType data);
EXTERN_C void StackPop(ST* ps);
EXTERN_C STDataType StackTop(ST* ps);
EXTERN_C int StackSize(ST* ps);
EXTERN_C bool StackEmpty(ST* ps);
EXTERN_C void StackDestroy(ST* ps);
#endif
5. Reference
Reference is an important syntax in C + +, which is widely used in the later stage. It is more convenient and better understood than pointers.
5.1 definitions of references
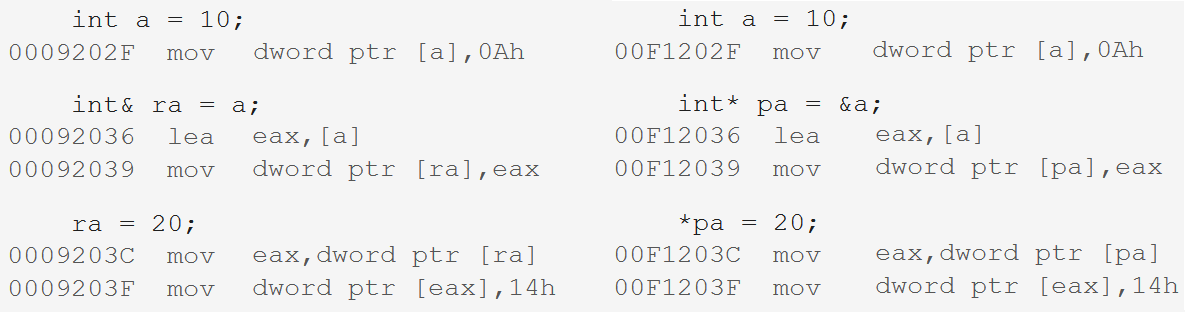
Reference is to give an alias to an existing variable, not to define a new variable. At the syntactic level, the reference variable does not open up space. It uses a space together with the variable it references.
Taking an alias is equivalent to taking a nickname, which is equivalent to taking two names for a space.
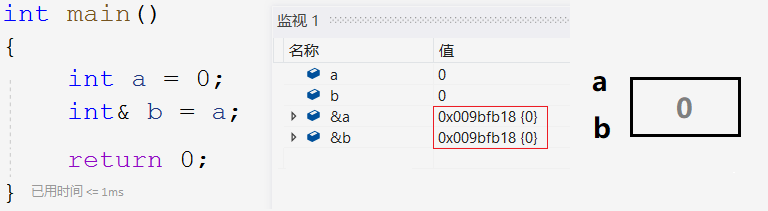
//Type & + reference variable name = reference entity int a = 0; int& b = a;
b is a reference to a, which is equivalent to giving a a new name b. b and a point to the same space. Changing b is equivalent to changing a.
5.2 referenced characteristics
- It must be initialized when defining a reference;
- A variable can have multiple references;
- The reference entity cannot be changed after reference initialization.
//1. int a = 10; int& b;//Err //2. int& b = a; int& c = b; int& d = c; //3. int e = 1; int& f = a; f = e;//Assign e to the variable a referenced by f
When defining a reference, it must be initialized, otherwise the alias will be meaningless. A variable can take multiple aliases, but after an alias is used, it can not refer to other variables, but can only be assignment operation. Reference also has certain limitations, which is more used with pointers.
5.3 frequently cited
If a constant variable is a variable with a constant attribute, a constant reference is a reference with a constant attribute. Frequent references may involve permission issues, such as:
//Permission amplification const int a = 0; int& ra = a;//Err //Permission reduction int b = 0; const int rb = b; //Same permissions const int c = 0; const int& rc = c;
When referring to const modified constants, if const is not added to the reference, the permission expansion is obviously not allowed. Permission cannot be expanded, but it can be unchanged and reduced. When using references as parameters, const can be added to prevent the arguments from being modified.
double d = 1.11; int i = d; double d = 1.11; const int& i = d;

When the floating-point variable d is assigned to the integer variable i, implicit type conversion will occur, and a temporary variable will be generated in the middle. Truncate the data of d into the temporary variable, and then assign the temporary variable to i. This is similar to the fact that when comparing different integer data, integer promotion will occur. In fact, the temporary variables generated by them will be integer promoted and then compared. This is also the reason why their values will not change.
Such a temporary variable is an R-value with a constant attribute, so only constant references can reference such a temporary variable. This allows the reference type of const type & to reference variables of any type.
5.4 application of references
The reference in the above example is only learning the characteristics of reference and has no practical significance. In actual use, there are usually two uses, as a parameter and a return value.
Function parameters
void Swap(int x, int y) { //Value transmission
int tmp = x;
x = y;
y = tmp;
}
void Swap(int* px, int* py) { //Byref
int tmp = *px;
*px = *py;
*py = tmp;
}
void Swap(int& rx, int& ry) { //Pass reference
int tmp = rx;
rx = ry;
ry = tmp;
}
int main() {
int x = 0, y = 1;
Swap(&x, &y);
cout << x << " " << y << endl;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}
The first kind of value passing call is obviously not good. The difference between address passing call and reference passing is that the former accesses the arguments X and Y through the address, and the latter avoids the temporary copy of the arguments by referencing the arguments. The three parameter lists are integer type, pointer type and reference type respectively, which constitute function overloading, but there will still be ambiguity when calling.
Example 1

As shown in the figure, in the single linked list, the method of using the secondary pointer to pass parameters because the header pointer plist may be modified can be replaced by the reference of the primary pointer. Phead is the reference of plist. Changing phead is changing plist.
Example 2
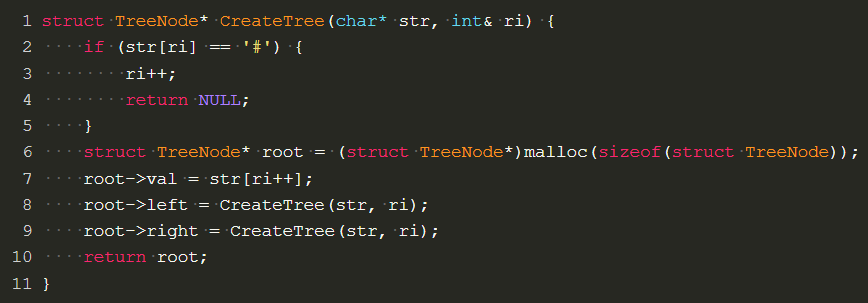
In the code for practicing using the preamble sequence string to establish a binary tree, you can change the number of nodes into reference variables in the process of recursion, which is obviously more convenient than pointers.
As return type
Reference as return type is also a difficult point to understand. Let's look at the following example:
int& Add(int a, int b) {
int c = a + b;
return c;
}
int main()
{
int ret = Add(1, 2);
Add(10, 20);
cout << ret << endl;
return 0;
}
After the Add function stack frame is destroyed, the function returns the reference of c, and then executes ret=Add(1,2), which is equivalent to taking the value of c and assigning it to ret, while the memory space of c has been returned to the operating system, resulting in illegal access.
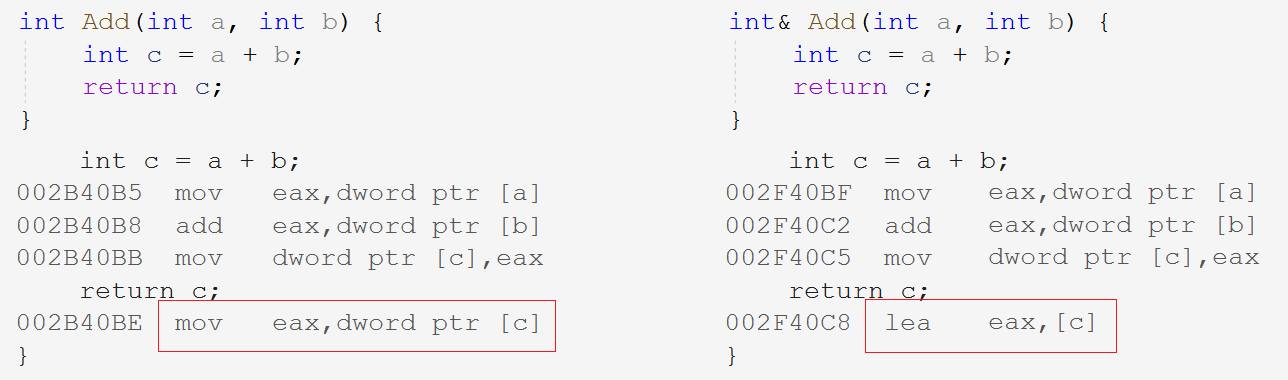
mov eax, dword ptr [c] //Put the value of variable c into register eax lea eax, [c] //Put the address of variable c into register eax
The difference between return value and return reference is that a temporary variable stores the value of c and returns the copy object. A reference accesses the memory space of the original c and reads the value of c and returns the return value object itself. The reason why the address is brought back to the register is that the underlying implementation of the reference is a pointer, which will access the memory space of c through the address later.
int& Add(int a, int b) {
int c = a + b;
return c;
}
int main() {
int& ret = Add(1, 2);
cout << ret << endl;
Add(10, 20);
cout << ret << endl;
return 0;
}
Print ret twice, 3 once and 30 once. It can be seen from this example that the reference brings back the address of c, and ret is also initialized as the reference of c. The Add stack frame is destroyed and created. Each time the c variable is in the same space, ret also refers to this space, so the value of this space is modified to 30 the next time the Add function is called.

Reference as return value may cause illegal access, so do not return a reference to a local variable. Reference as return value has its own application scenario, which will be encountered in subsequent learning.
int& At(int i) {
static int a[N];
return a[i];
}
int main() {
for (int i = 0; i < N; i++) {
cout << "a[" << i << "]=" << (At(i) = i) << endl;
}
return 0;
}
5.5 comparison of value transfer and reference transfer efficiency
#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestTransferRefAndValue() {
A a;
size_t begin1 = clock();
for (size_t i = 0; i < 1000000; i++)
TestFunc1(a);
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < 1000000; i++)
TestFunc2(a);
size_t end2 = clock();
cout << "TestFunc1(A a):" << end1 - begin1 << endl;
cout << "TestFunc2(A& a):" << end2 - begin2 << endl;
}
int main() {
TestTransferRefAndValue();
return 0;
}
Reference passing is similar to pointer passing. Each call accesses the same space, and each call of value passing will open up the same space. Therefore, the efficiency of reference passing is much higher than that of value passing. The larger the data, the greater the performance improvement. Reference can be used as output parameter or output return value, which is to change the external argument of formal parameter.
5.6 difference between reference and pointer
| Differences between references and pointers |
|---|
| Reference is an alias of a variable, so there is no space. Pointer is the address of a variable to store variables |
| References must be initialized when defined, and pointers are not required |
| After the reference definition, the reference entity cannot be changed, and the pointer can change the pointing object at will |
| No null references, only null pointers |
| sizeof(Type &) indicates the type size of the reference object, and sizeof(Type *) indicates the current platform address size |
| Reference self increment and self decrement change the size of the reference entity. Pointer self increment and self decrement represent the forward and backward movement of the address position |
| There are multi-level pointers and no multi-level references The pointer needs to be explicitly dereferenced, which is handled by the reference compiler References are safer than pointers |
6. Inline function
Function stack pressing requires a series of operations, so some small frequently called functions with only a few lines, such as swap and add, do not meet the requirements of high cohesion and low coupling in the call layer, and go out independently and waste performance. To solve this problem, in addition to using the syntax macro of C language, C + + has a new syntax called inline function.
6.1 definition of inline function
The function modified with inline is called inline function. During compilation, the compiler will automatically expand it at the call, which will not produce a series of overhead of function stack, and improve the efficiency of the program.
The inline function only works in release mode. If you want to view in Debug mode, you need to configure the item properties.
6.2 characteristics of inline functions
- Inline function is a kind of space for time, which saves the cost of calling function. Therefore, it is generally inappropriate to use inline function for functions with more than ten lines or recursive iteration.
- Inline function is only a suggestion to the compiler. The compiler will optimize automatically. If it does not meet the above requirements, the compiler will give up the optimization.
- The separation of declaration and definition is not recommended for inline functions. If inline functions are not called, there is no function address separation, which will lead to link failure.
Space for time is because each call is expanded, resulting in more instructions and larger programs. The more memory is loaded each time, but the time to call the function is saved.
The advantage of macro is that it can enhance the reusability of code and improve performance. The disadvantage is that it can not be debugged, poor maintainability and no type check. The introduction of inline functions in C + + is the recommended use of inline functions.
The following syntax is the syntax in C++11. You can understand it.
7. auto keyword
7.1 definition of Auto
When using auto to define a variable, the type of the variable is determined by the compiler according to its initialization content, so the variable modified by auto must be initialized. Auto is not a declaration of a type, but a "placeholder" for a type. The compiler will replace Auto with the actual type at compile time.
int a = 10; auto b = a; auto c = 10; auto d = 'A'; auto f = 11.11; auto e = "aaaa";
The significance of auto is that when the type in front of the variable is very long, the abbreviation of auto can be used to make it easier and use it with the range for of C++11.
7.2 use of Auto
auto declare pointers and references
int a = 10; //Define pointer auto pa = &a; auto* pa = &a; //Define reference auto& ra = a;
Use Auto to define the pointer. You can add * or not after auto. The type of pointer can be determined through the initialization content. But the reference must add &, otherwise it cannot be determined.
auto defines multiple variables in one line
auto a = 1, b = 2; auto c = 3, d = 4.0;//Err
When defining multiple variables in auto, the types of variables must be the same, because the compiler only deduces the type of the first variable to define the variables after the derived type.
auto cannot deduce
In addition, auto cannot be used as a function parameter type, even if a default value is given, and auto cannot be used to declare an array.
int Add(auto a);//Err
auto arr[] = { 10,20 };//Err
The most common advantage of auto in practice is to use it in combination with the new for loop provided by C++11 and lambda expression, which will be mentioned later.
8. Range based for loop
8.1 syntax of scope for
For a set with a range, its range still needs to be explained, which is undoubtedly redundant. Therefore, C++11 introduces the range for loop. As shown in the following code, the first is the loop variable, followed by the loop range. Note that the range for is similar to a normal loop, and you can also use continue and break.
//C
for (int i = 0; i < sz; i++) {
cout << arr[i] << endl;
}
//C++
for (auto e : arr) {
cout << e << endl;
}
The object returned by the range for loop is a copy of the value of the array element, so you need to use a reference to write the array element.
for (int i = 0; i < sz; i++) {
arr[i] *= 2;
}
for (auto& e : arr) {
e *= 2;
}
8.2 scope and service conditions
- The scope of the scope for must be determined.
void TestFor(int arr[]) {
for (auto e : arr) {
cout << e << endl;
}
}
Array parameter passing is essentially a pointer, so the specific range of the array is not known, so it is wrong.
- The iterated object should implement the operations of + + and = =.
9. Null pointer nullptr
The definition of NULL in traditional C language can be defined in stddef H, as shown in the figure below:

It can be found that NULL is a macro and is treated as an integer number 0 in C + + files, which may lead to hidden dangers in some cases. Therefore, C + + recommends us to use nullptr, which is introduced by C++11 as a keyword.