The initial learning of C++ includes the following aspects
1.C++ keywords
We know that there are 32 keywords in C and 63 in c++.
They are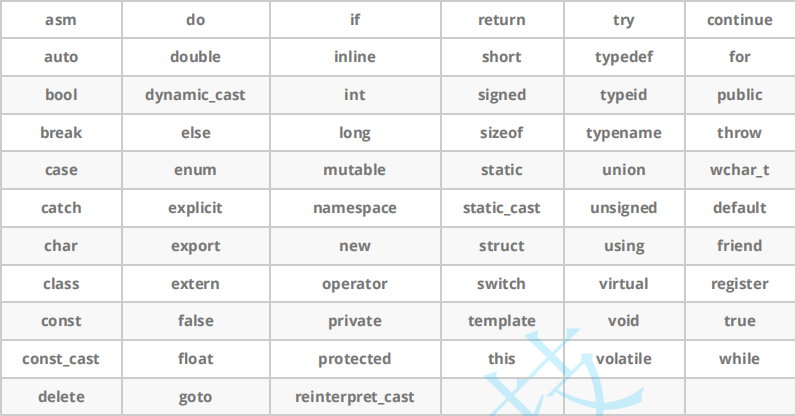
2. Namespaces
Why is there a namespace and what does it do?
In a large project, there are many variables and functions to be defined. If these variables and functions are defined in the global scope, they may be redefined inadvertently.Therefore, the concept of namespaces was introduced to localize identifier names to avoid naming or name conflicts.
What is a namespace?
A namespace defines a new scope within which everything in the namespace is restricted.Namespaces can contain variables, functions, structs, another namespace, and so on, which are common in globally defined namespaces.You can use a variable name in different namespaces.Later, you can use a variable in a namespace to introduce it.When you define a variable this way, you don't have to consider whether the name was used before, just that it doesn't exist in the namespace.
Definition of namespace
To define a namespace, you need to use the namespace keyword followed by the name of the namespace, followed by a pair of {}, which is a member of the namespace.Namespaces are defined in three ways:
//1. General Definition
namespace N1 // N1 is the name of the namespace
{
int a;
int Add(int left, int right)
{
return left + right;
}
}
//2. Nested Definitions
namespace N2
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N3
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
//3. Duplicate Definitions
namespace N1{int a};
namespace N1{int b};
//At compile time, the compiler will automatically merge it into a namespace, and it can also be defined as the same namespace, so do not use the same variable for namespaces with the same nameUse of namespaces
Content defined in a namespace is not directly usable.
Referencing an operator'::'Scope qualifier is used to refer to content in a scope outside the scope
Reference to a keyword: Use using in one scope to pull out what you want in another namespace for ease of use below
There are three ways to use it:
//1. Add namespace name and scope qualifier
namespace N
{
int a;
int b;
}
int main{
printf("%d\n", N::a); Print N In a
return 0;
}
//2. Use using to introduce members in a namespace
using N::b;
int main()
{
printf("%d\n", N::a); //a was not introduced
printf("%d\n", b); //b here is ready to be used directly
return 0;
}
// 3. Introduce using namespace namespace name
using namespce N; //Introduce all of N
int main()
{
printf("%d\n", a);
printf("%d\n", b);
return 0;
}
3.C++ Input-Output
Output function: cout standard output (console) is similar to printf
Input function: cin standard input (keyboard) is similar to scanf
Two functions belong to the standard library iostream and reintroduce the namespace std
Usage: Their usage is more flexible than printf and scanf, and the output does not need to be added%d..To illustrate what type of values are output/input and to connect various types of values
For example, the following code
#include <iostream>
using namespace std;
int main()
{
int a;
double b;
char c;
cin>>a;
cin>>b>>c;
cout<<a<<endl;
cout<<b<<" "<<c<<endl;
return 0;
}4. Default parameters
Concept: The default parameter is to specify a default value for the parameters of a function when it is declared or defined.When the function is called, the default value is used if no argument is specified, otherwise the specified argument is used.For example:
void TestFunc(int a = 0)
{
cout<<a<<endl;
}
int main()
{
TestFunc(); // When no arguments are passed, use the default value of 0 for the parameter
TestFunc(10); // When passing parameters, use the specified argument
}In the parameter list of a function, we can give some or all of the parameter defaults.Therefore, there are semi-default and full default parameters, and the usage and requirements are as follows
Full default parameters: each parameter has a default value
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout<<"a = "<<a<<endl;
cout<<"b = "<<b<<endl;
cout<<"c = "<<c<<endl;
}
int main()
{
TestFunc(); //10 20 30
TestFunc(1); //1 20 30
TestFunc(1,2); // 1 2 30
//Why give one to a?We find the answer from the semidefault parameter usage
}Semi-default parameters: Not all parameters are assigned default values, but there are rules for assigning semi-default parameters: semi-default parameters must be given in right-to-left order, not in intervals, or can be omitted from the front, but once given, all subsequent parameters must be given values.therefore
void TestFunc(int a, int b = 10, int c = 20)√ void TestFunc(int a=10, int b , int c = 20) × void TestFunc(int a=10, int b=20 , int c ) ×
With the rules for semi-default parameters, we can answer why all default parameters give values from the forward to the backward: semi-default parameters can be omitted, so an argument is assigned from the first parameter without knowing if the function is a semi-default parameter or not.
5. Function overload
Definition: Declare several functions with the same name in the same scope, and the list of parameters (number of parameters or type or order) of these functions with the same name must be different. They are often used to deal with problems that implements functions similar to data types.
As follows:
int Add(int left, int right)
{
return left+right;
}
double Add(double left, double right)
{
return left+right;
}
long Add(long left, long right)
{
return left+right;
}
int main()
{
Add(10, 20);
Add(10.0, 20.0);
Add(10L, 20L); //Finding a function by argument type
return 0;
}Note: Functions cannot be overloaded by return value types alone
short Add(short left, short right)
{
return left+right;
}
int Add(short left, short right)
{
return left+right;
}
//These two functions cannot be overloaded- Note:
Default and parameterless functions do not form overloads, for example:void TestFunc(int a = 10); void TestFunc( ); //These two functions do not form an overload. TestFunc() is called in another function, and the compiler does not know which one to call.
Default functions do not overload normal functions, for example:
void TestFunc(int a = 10); void TestFunc(int a ); //These two functions do not form an overload. TestFunc(num) is called in another function, and the compiler does not know which one to call.
Thus: to form a function overload, make sure that the two functions do not conflict when called, and that when a value is passed, both functions can be adjusted.
We know that function overloading is not possible in C language, why is it possible in c++?Since each function name is named by the compiler at program compilation time, let's introduce the concept of named modifiers
Name Modifiers
When compiling a c++ program, the compiler changes the function and variable names to distinguish each function, making each function name globally unique, and including the parameter type in the final name, so that functions with the same name can be distinguished by different parameter lists, thus ensuring that names are globally unique at the bottom levelSex.
So what exactly did c++ change the name to look like?
There are the following codes:
int Add(int left, int right);
double Add(double left, double right);
int main()
{
Add(1, 2);
Add(1.0, 2.0);
return 0;
}
//Under vs, compile the above code and link it, and the compiler eventually errors:
//error LNK2019: Unresolvable external symbol "double cdecl Add(double,double)" (?Add@@YANNN@Z)
// error LNK2019: Unresolvable external symbol "int u cdecl Add (int, int)" (?Add@@YAHH@Z)From the above errors, it can be seen that the compiler is not actually using the Add name at the bottom level, but a more complex name that has been re-modified to include the name of the function and the parameter type.
Modification rules for c++ under visual stdio:
Naming can be inferred from the above signatures and modified names:
The modified name begins with'?', followed by the function name ending with'@'sign: followed by the class name'@' and the namespace'@'followed by'@', followed by'@' to indicate the end of the function's namespace: the first'@'indicates the function call type is' cdecl', followed by the function's parameter type and returnReturn value, end by'@'and end by'Z'.After A, the first is the return value type, followed by the type of the parameter until @, H is int, M is float
Why can't functions with the same name constitute an overload in c?
Since name modifiers in c only precede function names with an underscore, the list of formal parameters does not participate in name modifiers, so it is not possible to distinguish functions with the same name by the list of formal parameters.
Adding extern "C" before a function compiles some functions in c++ projects in a C-style
6. References
Concepts: Variables are given an alias and share a memory space with them. Variables can be changed by reference.
Definition: Type & Reference Variable Name = Reference Entity
Note: The reference type must be the same as the reference entity type.
For example:
int a = 10;
int& ra = a;//Define Reference Types
printf("%p\n", &a);
printf("%p\n", &ra); //The results are the sameReference characteristics:
1>References must be initialized at definition time, no empty references can exist
int& ra ;//Errors will occur //A nickname has been given. This nickname is not owned by anyone. What is the meaning of this nickname?
2>A variable can have multiple references (a person can have many aliases)
3>Once a reference refers to an entity, it cannot refer to another entity
int a=0;
int b=1;
int& ra=a;
ra=b; //ra does not change the reference, but assigns the value of b to ra
printf("%d",a); //->1Frequently cited
const int a = 10; int& ra = a; // The statement compiles with an error, a being a constant //Const modifies a variable by adding const before reference. If not, you can modify the value of the variable by reference. const int& ra = a;//Correct Writing int& b = 10; // The statement compiles with an error, 10 being a constant //References cannot be const references. To precede them with const, familiar ones cannot be modified. const int& b = 10; double d = 12.34; int& rd = d; // The statement compiles with errors of different types const int& rd = d;//This is correct, but rd is not an alias for d //Rather, A is used to form a temporary variable that holds the integer portion of a, and then RA references the temporary variable.However, the temporary variable does not know the name or address, and therefore cannot be modified. It has a certain degree of const and must be preceded by ra.
Reference usage scenarios
1>Make parameters: set the function parameter to the reference type
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}Description: If you want to change an argument by a parameter, you can set the parameter to a normal type. If you don't want to change the argument by a parameter, you can set the parameter to a const type.
Efficiency comparison of value, address and reference:
Efficiency: Value is less efficient than address and reference.Pass-by address and referral time are the same.Because the process of passing a reference and a pointer changes in memory exactly the same, the process of passing a reference changes to the form of a pointer when compiling. During compiling, a reference is implemented as a pointer.
#include <time.h>
struct A
{
int a[10000];
};
void TestFunc1(A a)
{}
void TestFunc2(A& a)
{}
void TestRefAndValue()
{
A a;
// Use value as function parameter
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// Use reference as function parameter
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// Calculate the end time of two functions
cout << "TestFunc1(int*)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(int&)-time:" << end2 - begin2 << endl;
}
// Run multiple times to detect differences in the efficiency of passing values and references
//The results are small and nearly identical
//After disassembly, you can see that the process of passing a reference is the same as that of a pointer.
int main()
{
for (int i = 0; i < 10; ++i)
{
TestRefAndValue();
}
return 0;
}2>Make a return value: Set the return value type to the reference type
int& TestRefReturn(int& a)
{
a += 10;
return a;
}Note: If a function returns, the space on its stack is returned to the system after it leaves the scope of the function, so it cannot be returned as a reference type using the space on the stack.Therefore, as a return value, the return variable should not be controlled by the function, that is, the end of the function and the life cycle of the variable exists.Examples include global variables, static-modified local variables, user unreleased heaps, reference type parameters
The error occurred with the following code:
int& Add(int a, int b)
{
int c = a + b;
return c;
}
//After the function call, the space occupied by c on the stack is freed (overridable), so it makes no sense.
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
//->7, Add (3, 4) covers up that space of c again
return 0;
}
Performance comparison of values and references as return value types
By comparison, it is found that the pass-by and pointer are very inefficient as parameters and return value types, so you can use a reference where the reference is a return value unless you want to return a variable defined in a function whose space becomes invalid as the function is called.Can be returned by reference.
#include <time.h>
struct A
{
int a[10000];
};
A a;
A TestFunc1()
{
return a;
}
A& TestFunc2()
{
return a;
}
void TestReturnByRefOrValue()
{
// Return value type with value as function
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// Return value type with reference as function
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// Calculates the time after the completion of two function operations
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
// Test run 10 times, difference in efficiency between value and reference as return value
int main()
{
for (int i = 0; i < 10; ++i)
TestReturnByRefOrValue();
return 0;
}
References and Pointers
A grammatical reference is an alias that has no separate space and shares the same space as its reference entity, but is actually spatial in the underlying implementation because references are implemented as pointers.
int main()
{
int x = 10;
int& rx = x;
rx = 20;
int* px = &x;
*px = 20;
return 0;
}For this code, let's look at disassembly code:
You can find that both are used the same way in memory at the bottom level, and references are implemented as pointers.
So what's the difference between the two?
1>References must be initialized at definition time, pointers are not required.Thus, the pointer needs to be null and the reference needs to be referenced, since the reference definition is initialized
2>After a reference refers to an entity at initialization, it can no longer refer to other entities, and the pointer can point to any entity of the same type at any time
3>There are no NULL references, but there are NULL pointers
4>In sizeof, the meaning is different: the reference result is the size of the reference type, but the pointer is always the number of bytes occupied by the address space (4 bytes under 32-bit platform)
5>Increase by 1 the entity that references self-adding, that is, the pointer adds itself, that is, the pointer offsets a type of size backwards in continuous space
6>There are multiple pointers, but no multilevel references
7>Different ways of accessing entities, pointers need to be explicitly de-referenced, referencing compilers themselves
8>References are relatively safer to use than pointers.
7. Inline Functions
Concepts: Functions decorated with inline are called inline functions. The C++ compiler expands where inline functions are called at compile time, without the overhead of the function stack. Inline functions improve the efficiency of the program.
Common functions stack to form stack frames, and so on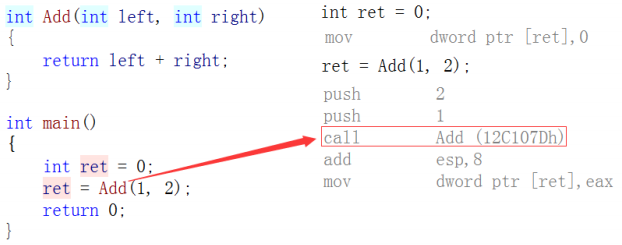
Inline functions compile directly by replacing the calling function with an operation inside the function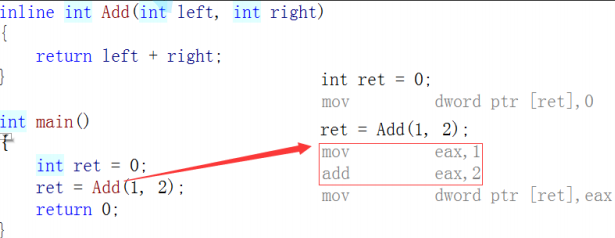
View mode: 1. In release mode, check whether call Add2 exists in the assembly code generated by the compiler. In debug mode, the compiler needs to be set, otherwise it will not expand (because in debug mode, the compiler will not optimize the code by default, giving the way vs2013 is set): Function->Properties->Configuration->c/C++->Change the general debugging information format to a program database, and then change the inline function extension in optimization to apply only to _inline
Characteristic
1> Inline is a space-for-time alternative.So long code or looping/recursive functions are not suitable as inline functions.
2>Inline is only a suggestion to the compiler, which will optimize automatically. If there are loops/recursions inside functions defined as inline, etc., inline will be ignored in compiler optimization.
3>Inline does not recommend declaration and definition separation, which can lead to link errors.Because the inline is expanded, there is no function address and the link cannot be found.Therefore, inline functions have file scope and are only useful in this file, other files are not available.
// F.h
#include <iostream>
using namespace std;
inline void f(int i);
// F.cpp
#include "F.h"
void f(int i)
{
cout << i << endl;
}
// main.cpp
#include "F.h"
int main()
{
f(10);
return 0;
}
// Link error: main.obj: error LNK2019: unresolved external symbol "void u cdecl f(int)" (?
f@@YAXH@Z),The symbol is in the function _main Is referencedInline function and const, macro
In c++, const-modified variables have the properties of constants and macros, substitution and detection occur at compile time, and even pointer modification does not change variable values.There are the following codes
const int a=1;
int *pa=(int *)a;
*pa=2;
printf("%d,%d",*pa,a);
//Result 2,1a is still unmodifiedThis is possible in c because c is undetectable and the const variable is modified through the pointer
Macros are replaced during preprocessing and do not participate in compilation or debugging.
Advantages of macros: Enhance code reuse.Improve performance.
Disadvantages:
1>Not easy to debug macros.(because the preprocessing phase was replaced)
2>Causes poor readability, maintainability and misuse of code.
3>There is no type safety check.
So in c++, const can be used instead of macro-to-constant definition and inline function can be used instead of macro-to-function definition.
8. auto keyword
Concepts: In C++, auto defines a variable as a new type indicator. Variables declared by auto are derived by the compiler at compile time. What type of variable is assigned depends on the initialization value.
Characteristic:
1>Variables must be initialized when auto is used to define them, and the compiler needs to derive the actual type of auto from the initialization expression at the compilation stage.
2>auto is not a declaration of a type, but a placeholder for a type declaration, and the compiler will replace Auto with the actual type of the variable at compile time
int TestAuto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = TestAuto();
cout << typeid(b).name() << endl; //int
cout << typeid(c).name() << endl; //char
cout << typeid(d).name() << endl; //int
//auto e; cannot be compiled and must be initialized when using auto to define variables
return 0;
}Usage method
1>Auto combines pointer and reference: when declaring pointer types with auto, there is no difference between auto and auto*, but when declaring reference types with auto, you must add &.
int x = 1;
auto px = &x;
auto *ppx = &x;
auto& rx = x;
auto rrx = x;
cout << typeid(px).name() << endl;
cout << typeid(ppx).name() << endl;
cout << typeid(rx).name() << endl;
cout << typeid(rrx).name() << endl;
rx = 3;
cout << x << endl; //x has changed indicating that it is a reference
rrx = 2;
cout << x << endl; //x unchanged, not a reference2>auto defines multiple variables on the same line. When multiple variables are declared on the same line, they must be of the same type, or the compiler will error because the compiler actually deduces only the first type and then defines other variables with the deduced type.
auto f = 1, g = 2;
//auto h = 1, i = 2.3; //compilation errors, h and i types are different3>auto cannot be used directly to declare arrays
int h[] = { 1, 2, 3 };
//Auto t[] = {4, 5, 6}; //Errors occur during compilation9. Scope-based for loops
Why introduce this concept?
It is redundant and sometimes error prone for a programmer to explain the scope of a loop to a scoped collection.Therefore, a range-based for loop was introduced in C++11.
Usage: Parentheses after a for loop are divided into two parts by the colon':': The first part is the variable used for iteration within the scope, and the second part represents the scope to be iterated.
int arr[] = { 1, 2, 3, 4, 5 };
for (auto& e : arr) //=>for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
e *= 2;
for (auto e : arr) //To change an element's value, add & before the variable, do not change it, just a normal variable
cout << e << " ";For arrays, this is the range of the first and last elements in the array; for classes, you should provide methods for begin and end, which are the range of for loop iterations.
10. Pointer null value--nullptr
Concept: nullptr pointer null constant, indicating that nullptr is used for pointer null values.
Why nullptr? Why can't NULL be used to represent null pointers?
When a pointer is defined, it is initialized (otherwise a wild pointer will appear) and NULL is used in C to give a pointer without a pointer, but NULL is actually a macro. In a traditional C header file (stddef.h), you can see the following code
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif #endif
You can see that NULL may be defined as a literal constant of 0, or as a constant of a pointer of no type (void*), so when you pass a null pointer, you will get some unsatisfactory errors, as follows:
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(int*)
{
cout<<"f(int*)"<<endl;
}
int main()
{
f(0);
f(NULL); //0, into the first function, but we want NULL to indicate that the pointer was meant to go into the second function
f((int*)NULL);
return 0;
}Thus, nullptr is used instead of NULL in C in the pointer.
Nullptr is also typed, which is nullptr_t and can only be implicitly converted to a pointer type. Nullptr_t is defined in the header file: typedef decltype(nullptr) nullptr_t;
Be careful:
- When nullptr is used to represent null pointer values, it is not necessary to include a header file, because nullptr was introduced as a new keyword in C++11.
- In C++11, sizeof(nullptr) and sizeof((void*)0) account for the same number of bytes, all 4.
- To improve the robustness of your code, nullptr is recommended when subsequently representing null pointer values.