Atomic operation
Example
Atomic operation is an indivisible operation. Of all the threads in the system, you can't see that the atomic operation is half completed; it's either done or not. There are only two possibilities.
Do not use atomic operation:
#include <iostream> #include <thread> #include <atomic> using namespace std; long num = 0; void addnum() { for(int i=0; i<100000; i++) num++;//No exclusive access to global variables } int main() { int nthreads = 2; thread t[nthreads]; for(int i=0; i<nthreads; i++) t[i] = thread(addnum); for(auto& th : t) th.join(); cout << num << endl; return 0; }
Output results:
The final result is 109515, which is less than 200000, indicating that the following situation occurs when writing global variables: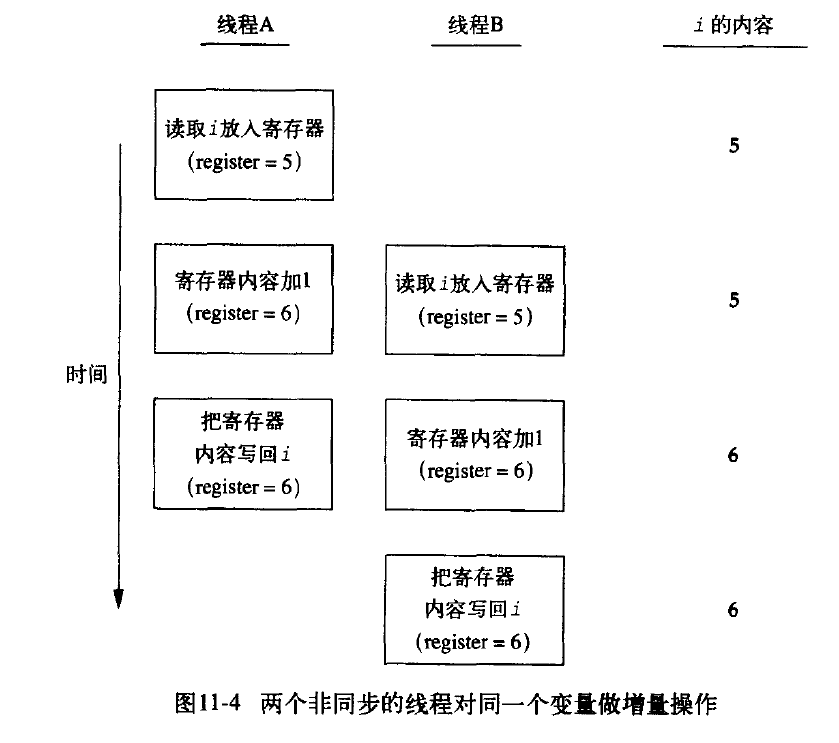
This causes the actual value to be small.
This can be avoided by using atomic manipulation. Atomic operation makes the accumulation operation of global variable num indivisible.
#include <iostream> #include <thread> #include <atomic> using namespace std; atomic<long> num(0); void addnum() { for(int i=0; i<100000; i++) num++; } int main() { int nthreads = 2; thread t[nthreads]; for(int i=0; i<nthreads; i++) t[i] = thread(addnum); for(auto& th : t) th.join(); cout << num << endl; return 0; }
Output results:
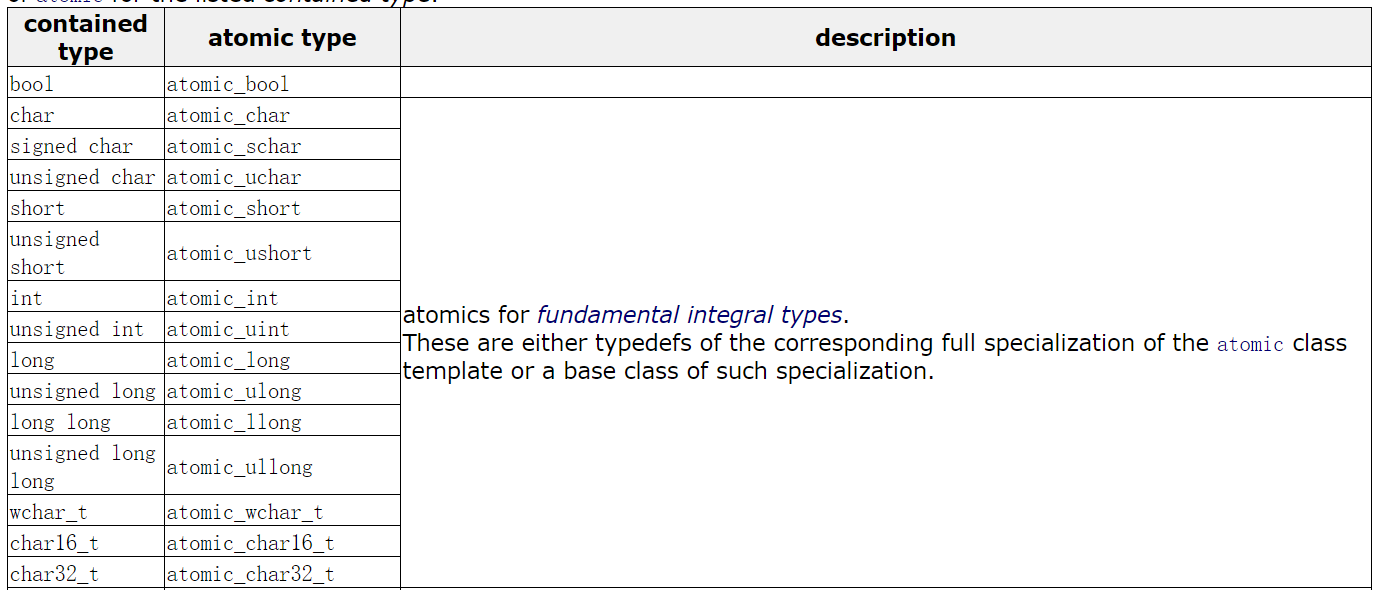
Correspondence between atomic type and built-in type
Construction mode:
store, load, exchange operations
-
store

store receives two parameters, one is T val, the other is sync. store will write val. the operation is atomic. There are three memory sequences for Sync: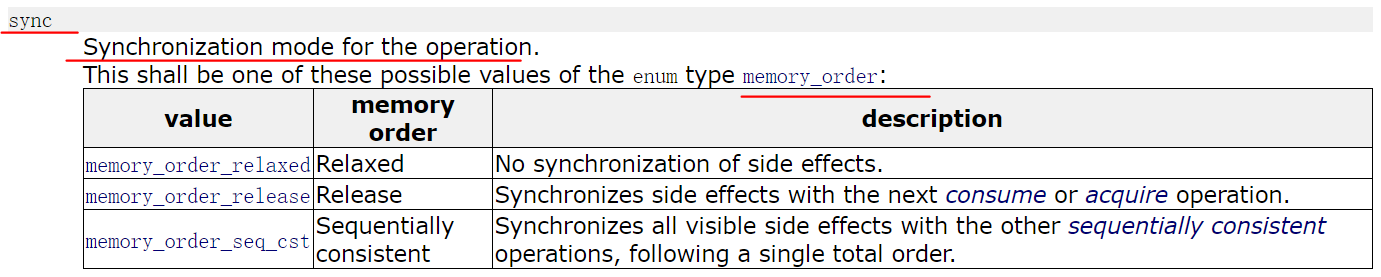
-
load

load returns an object of type T.
The supported memory order is:
-
exchange

There are two parameters, the first is the changed value, and the second is the memory model.
The return value is the value before exchange is called.
Examples of use of store and load:
#include <iostream> #include <atomic> #include <thread> using namespace std; atomic<int> foo(0); void set_foo(int x) { foo.store(x, memory_order_relaxed); } void print_foo() { int x; do { x = foo.load(memory_order_relaxed); } while (x == 0); cout << "foo: " << x << endl; } int main() { thread t1(set_foo, 1); thread t2(print_foo); t1.join(); t2.join(); return 0; }
Example used by exchange:
#include <iostream> #include <atomic> #include <thread> #include <vector> std::atomic<bool> ready(false); std::atomic<bool> winner(false); void count1m(int n) { while(!ready) {} //wait for ready for(int i=0; i<1000000; i++){} //count to 1M if(!winner.exchange(true)) { //Only the first thread executing exchange will return false and output the following statement. The other threads will return true and cannot enter if std::cout << "thread #" << n << " won!\n"; } } int main() { std::vector<std::thread> threads; for(int i=0; i<10; i++){ threads.push_back(std::thread(count1m, i+1));//Create 10 threads } ready.store(true);//start for(auto& th : threads) th.join(); return 0; }
This example is to generate 10 threads at the same time, and let them start to execute the for loop. Whoever executes first will be able to call exchange for the first time, so as to enter the if statement to print information. The rest will not enter the if, because the first one has set the winner to true, and exchange will return true when other threads access again.
atomic_flag
Unlike other atomic types, atomic flag is lock free, that is, threads do not need to lock its access, while other atomic types are not necessarily lock free.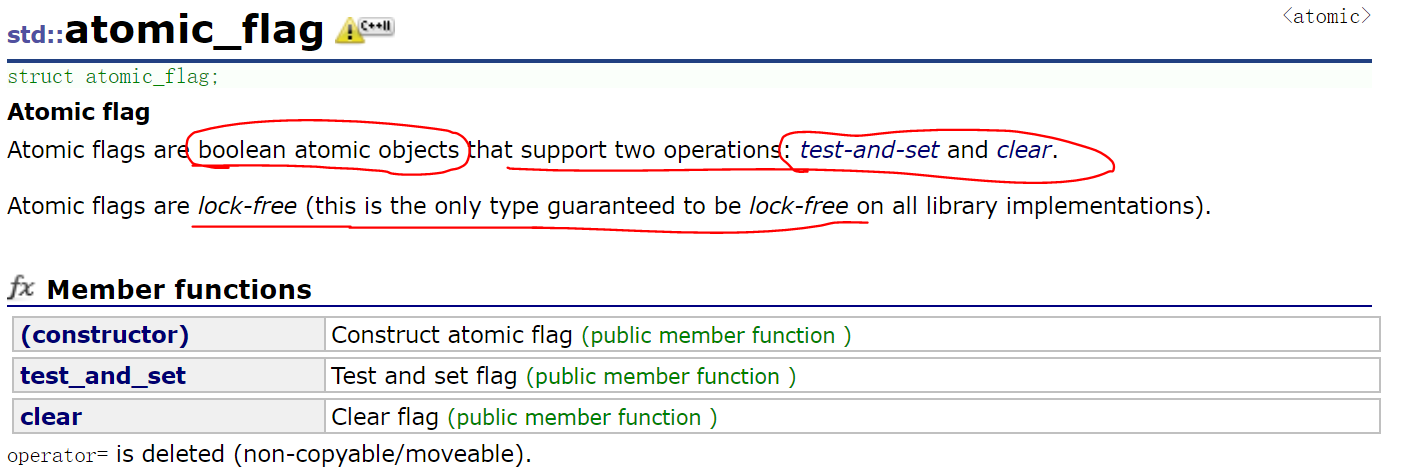
Because atomic < T > does not guarantee that type T is unlocked. In addition, different platforms have different processing methods and cannot guarantee that it must be unlocked. Therefore, other types will have the is ﹐ lock ﹐ free() member function to determine whether it is unlocked.
Atomic flag only supports test and set() and clear() member functions.
The test and set() function checks the STD:: atomic flag flag. If the STD:: atomic flag has not been set before, set the flag of STD:: atomic flag. If the previous STD:: atomic flag has been set, return true, otherwise return false.
The clear() function clears the STD:: atomic flag flag so that the next call to STD:: atomic flag:: Test and set() returns false. A spin lock can be implemented by using the test and set() and clear() functions of the atomic flag
/* ** Implementation of spin lock by using atomic flag */ #include <iostream> #include <atomic> #include <thread> #include <unistd.h> using namespace std; atomic_flag lock = ATOMIC_FLAG_INIT;//Initialize to false void fun1(int n) { while(lock.test_and_set(memory_order_acquire)){ //Since lock is set in the main function, the loop needs to wait for thread 2 to lock clear cout << "waiting for thread " << n << endl; } cout << "thread " << n << " starts working!" << endl; } void fun2(int n) { cout << "thread " << n << " is going to start\n"; lock.clear(); cout << "thread " << n << " starts working!" << endl; } int main() { lock.test_and_set();//set lock thread t1(fun1, 1); thread t2(fun2, 2); t1.join(); usleep(1000); t2.join(); return 0; }
Output results: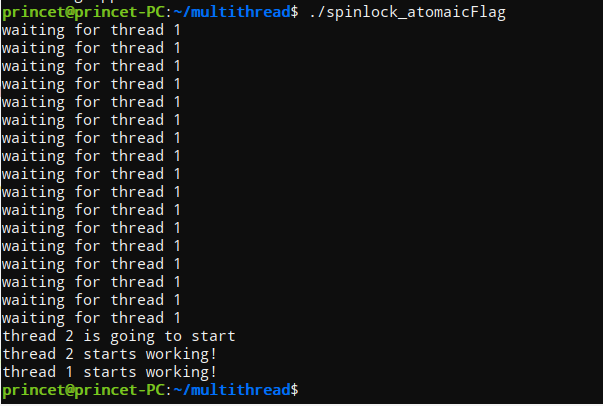
It can be seen that thread 1 is executing while until thread 2 locks clear.
Another example of using atomic flag to realize spin lock:
#include <iostream> #include <atomic> #include <thread> #include <vector> using namespace std; atomic_flag lock = ATOMIC_FLAG_INIT; void appendnum(int x) { while (lock.test_and_set()){ //Get lock } cout << "thread #" << x << endl; lock.clear();//release } int main() { vector<thread> v; for(int i=0; i<10; i++){ v.push_back(thread(appendnum, i+1)); } for(auto& th : v){ th.join(); } return 0; }
Operation result: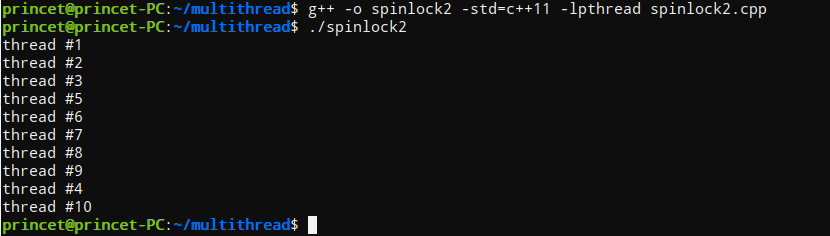
Memory model
Notice that the above store, load, test_and_set and clear functions all have a parameter of type memory_order. What does this parameter mean?
Let's start with an example:
#include <iostream> #include <atomic> #include <thread> using namespace std; atomic<int> a(0); atomic<int> b(0); void valueSet() { int t = 1; a = t; b = 2; } void observer() { cout << "a = " << a << "," << "b = " << b << endl; } int main() { thread t1(valueSet); thread t2(observer); t1.join(); t2.join(); cout << "in main: " << "a = " << a << ", " << "b = " << b << endl; return 0; }
The running result of this example may be (0,0) (1,0) (1,2), or (0,2). It is impossible for (0,2) to occur according to the execution order in the valueSet. In fact, this is related to the memory model.
The memory model is usually a hardware concept, which represents the order in which machine instructions are executed by processors. Modern processors do not process machine instructions one by one
1: Load reg3, 1; // Put immediate 1 in register reg3
2: Move reg4,reg3; // Put the data of reg3 into reg4
3: Store reg4, a; // Store reg4 data in memory address a
4: Load reg5, 2; // Put immediate 2 in register reg5
5: Store reg5, b; // Save reg5 data to memory address b
Pseudo assembly code represents t = 1; a = t; b = 2. Generally, instructions are executed in the order of 1 to 5. This memory model is called strong ordered. However, it can be seen that the running order of instructions (1 23) and (4 5) does not affect the results. Some processors may disrupt the order of instructions, such as executing in the order of 1-4-2-5-3. This memory model is called weak ordered. In the weak sequential memory model, instruction 5 (assignment of B) is likely to be completed before instruction 3 (assignment of a).
In reality, x86 ʄ and SPARC (TSO mode) are platforms with strong sequential memory model. In multithreaded programs, strong order type means that the order of instruction execution seen by each thread is the same. For processors, the order in which data in memory is changed is the same as in machine instructions. On the contrary, the weak order is that the order in which the memory data seen by each thread is changed is inconsistent with that declared in the machine instructions. Weak sequential memory model may cause program problems. Why do some platforms, such as Alpha, PowerPC, Itanium and ArmV7, use this model? Simply put, this model can make the processor have better parallelism and improve the efficiency of instruction execution. In addition, in order to ensure the order of instruction execution, it is usually necessary to add a memory barrier instruction into the assembly instruction, but it will affect the processor performance. For example, on PowerPC, there is a memory fence instruction called sync. This instruction forces the processor to execute the instructions after sync only after all the instructions that have entered the pipeline are completed.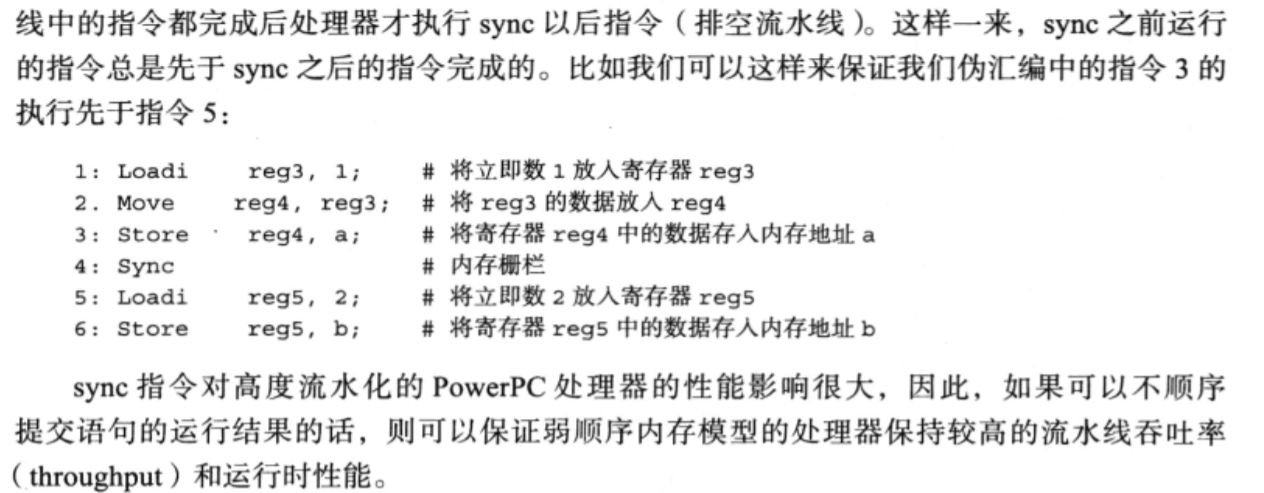
C++11 allows programmers to specify the so-called memory order for atomic operations, which is implemented by using memory ﹣ order, which is of enumeration type:
typedef enum memory_order { memory_order_relaxed, // relaxed memory_order_consume, // consume memory_order_acquire, // acquire memory_order_release, // release memory_order_acq_rel, // acquire/release memory_order_seq_cst // sequentially consistent } memory_order;

Generally, the default is memory order SEQ CST, which is executed in order.

